Den här artikeln ger en steg-för-steg-guide för hur du använder maskininlärningsfunktioner med 2UDA. I artikeln kommer vi att använda ett exempel på djur för att förutsäga om de är däggdjur, fåglar, fiskar eller insekter.
Programversioner
Vi kommer att använda 2UDA version 11.6-1 för att implementera Machine Learning-modellen. 2UDA version 11.6-1 kombinerar:
- PostgreSQL 11.6
- Orange 3.23.0
Du hittar den senaste versionen av 2UDA här.
Steg 1:Ladda träningsdatauppsättning till PostgreSQL
Exempeldataset som används för att träna vår modell finns tillgängligt på det officiella Orange GitHub-förrådet här.
Följ dessa steg för att ladda träningsdata till PostgreSQL-tabeller:
- Anslut till PostgreSQL via psql, OmniDB eller något annat verktyg som du är bekant med.
- Skapa en tabell för att lagra vår utbildningsdata . Här heter det träningsdata.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Infoga träningsdata i tabellen via COPY-fråga. Innan du kör COPY-frågan, se till att PostgreSQL har krävt läsbehörigheter för datafilen, annars kommer COPY-operationen att misslyckas.
OBS: Se till att du skriver en flik mellanrum mellan enstaka citattecken efter avgränsaren nyckelord.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Se skärmdumpen av träningsdatauppsättningen nedan
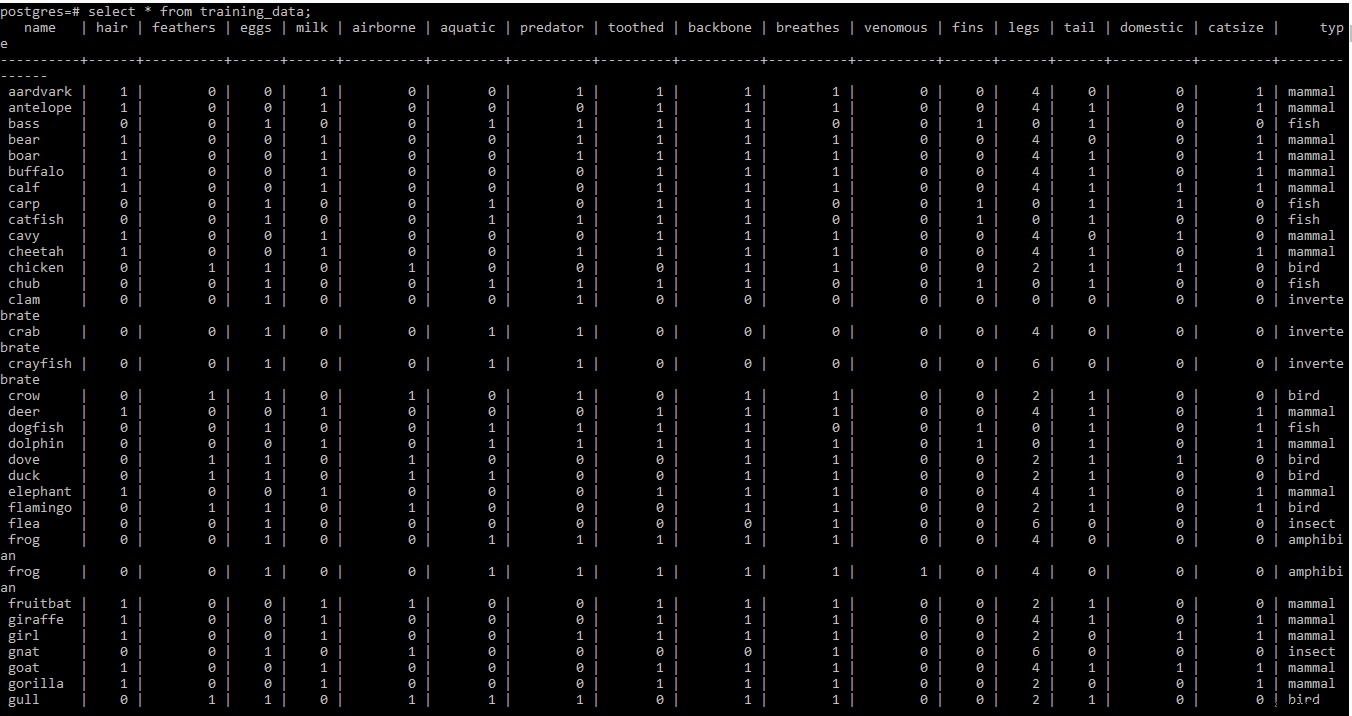
OBS: Rad två och tre i träningsdatauppsättningen på .fliken filen innehåller lite metainformation. Eftersom det inte behövs vid det här laget har det tagits bort från filen.
Steg 2:Skapa arbetsflöde med Orange
- Gå till skrivbordet och dubbelklicka på den orange ikonen.
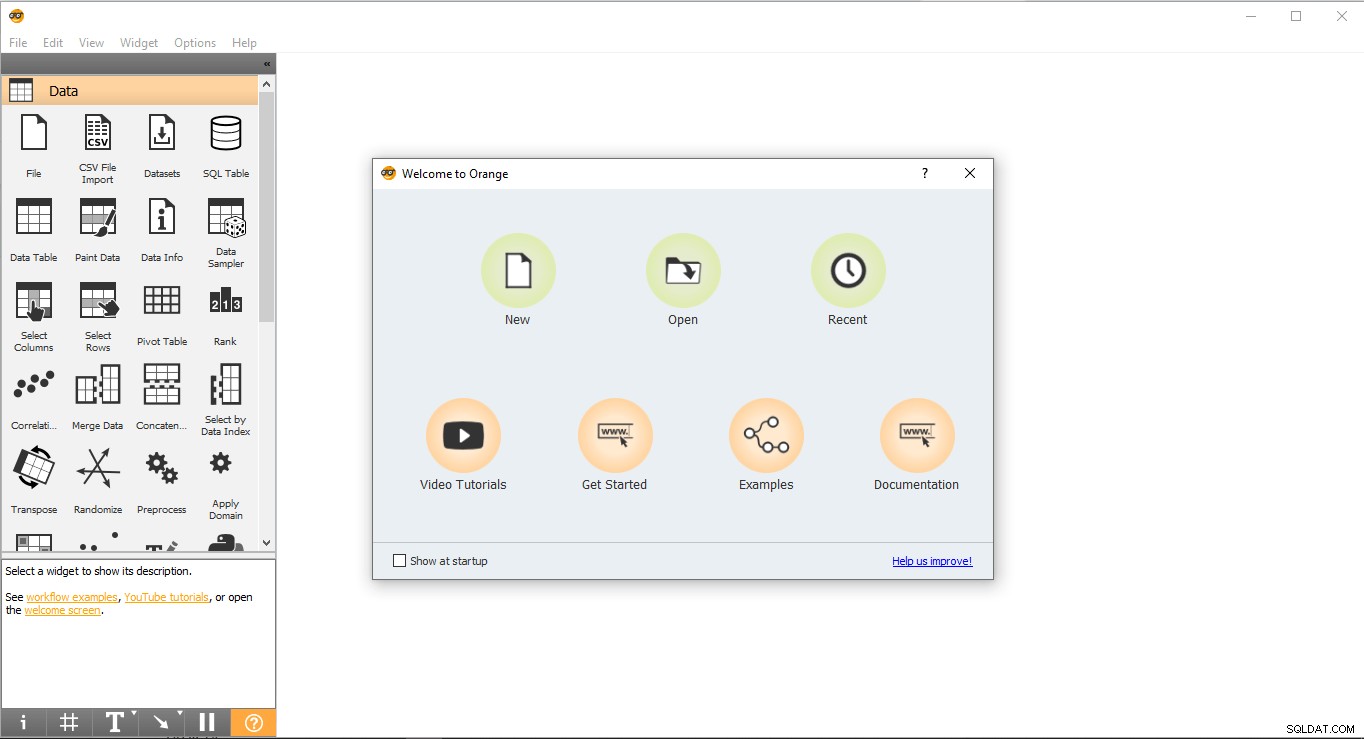
- Så här ser startsidan ut. Välj Ny alternativet och det skapar ett tomt projekt.

Nu är du redo att tillämpa Machine Learning-modellen på datamängden.
Steg 3:Välj maskininlärningsmodell för att träna upp data
För den här artikeln, k-närmaste grannar (KNN) Machine Learning-modellen används för att träna upp data. När dataträningsprocessen är klar, i nästa steg skickas testdata till Prognos widget för att kontrollera noggrannheten av förutsägelser.
Steg 4:Importera träningsdata från PostgreSQL till Orange
Denna utbildningsdatauppsättning kommer att användas för att träna Machine Learning-modellen.
- Dra och släpp SQL-tabell widget från Data meny.
- Byt namn på widget (valfritt)
- Högerklicka på SQL-tabellen widget.
- Välj Byt namn .
- Anslut till PostgreSQL för att ladda träningsdatauppsättningen:
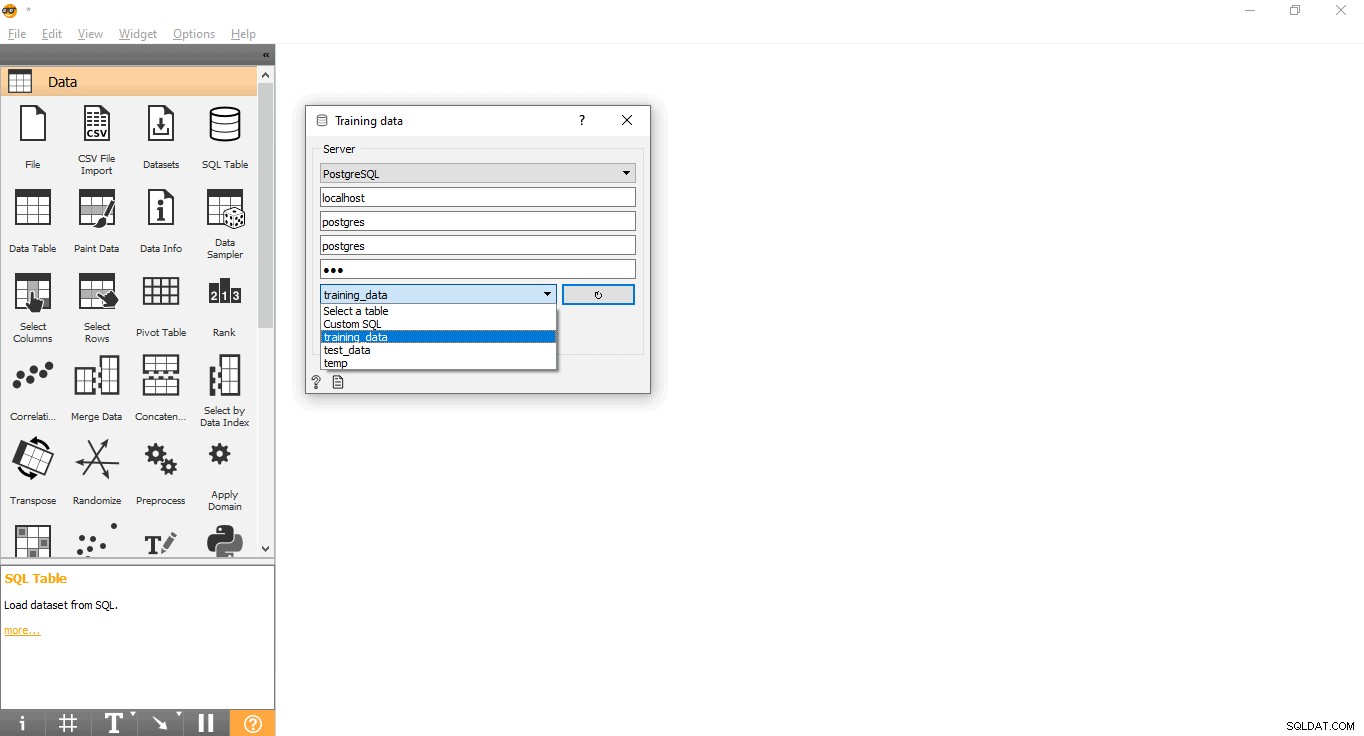
- Dubbelklicka på Utbildningsdata widget.
- Ange referenser för att ansluta till PostgreSQL-databasen.
- Tryck på omladdningsknappen för att ladda alla tillgängliga tabeller från den givna databasen.
- Välj träningsdatatabell från rullgardinsmenyn och stäng popup-fönstret.
Steg 5:Lägg till målkolumn
Det här steget är viktigt eftersom Machine Learning-modellen kommer att försöka förutsäga data för denna målvariabel/-kolumn:
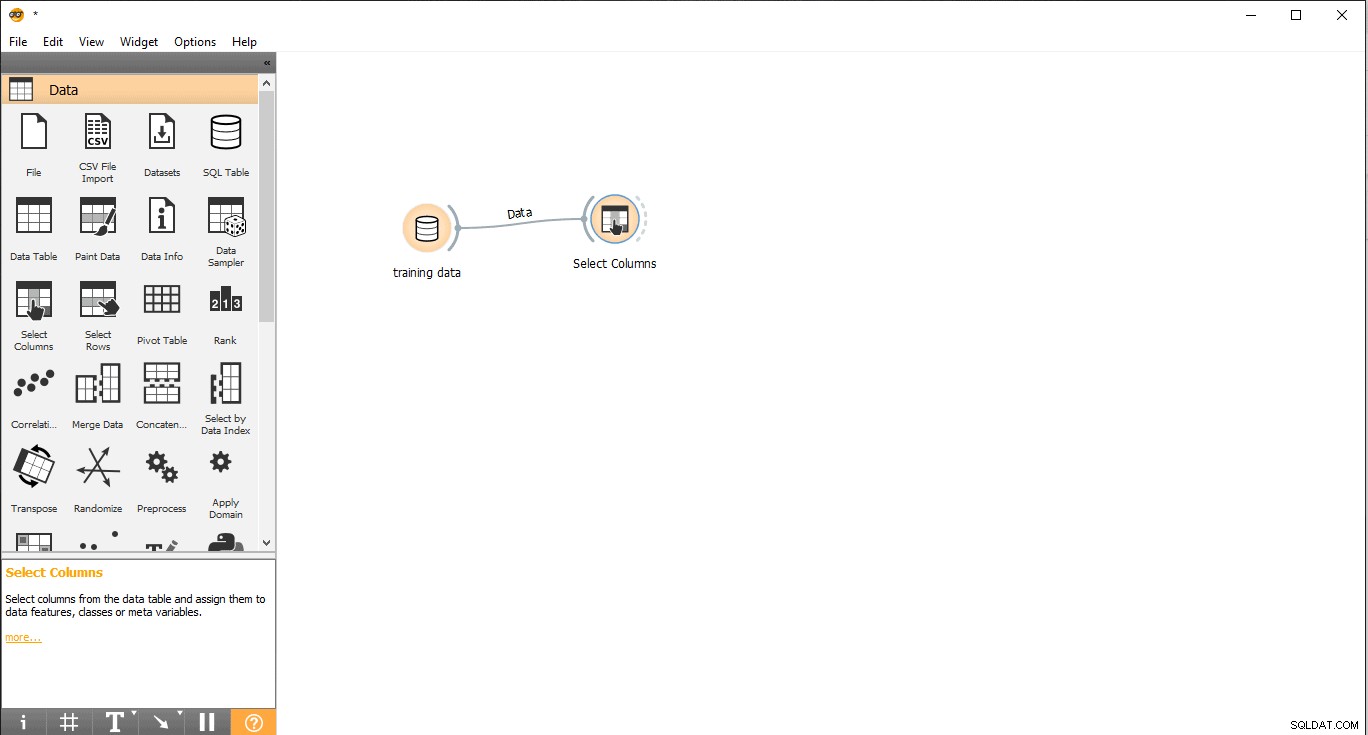
- Dra och släpp Välj kolumner widget från data meny.
- Dubbelklicka på Välj kolumner widget.
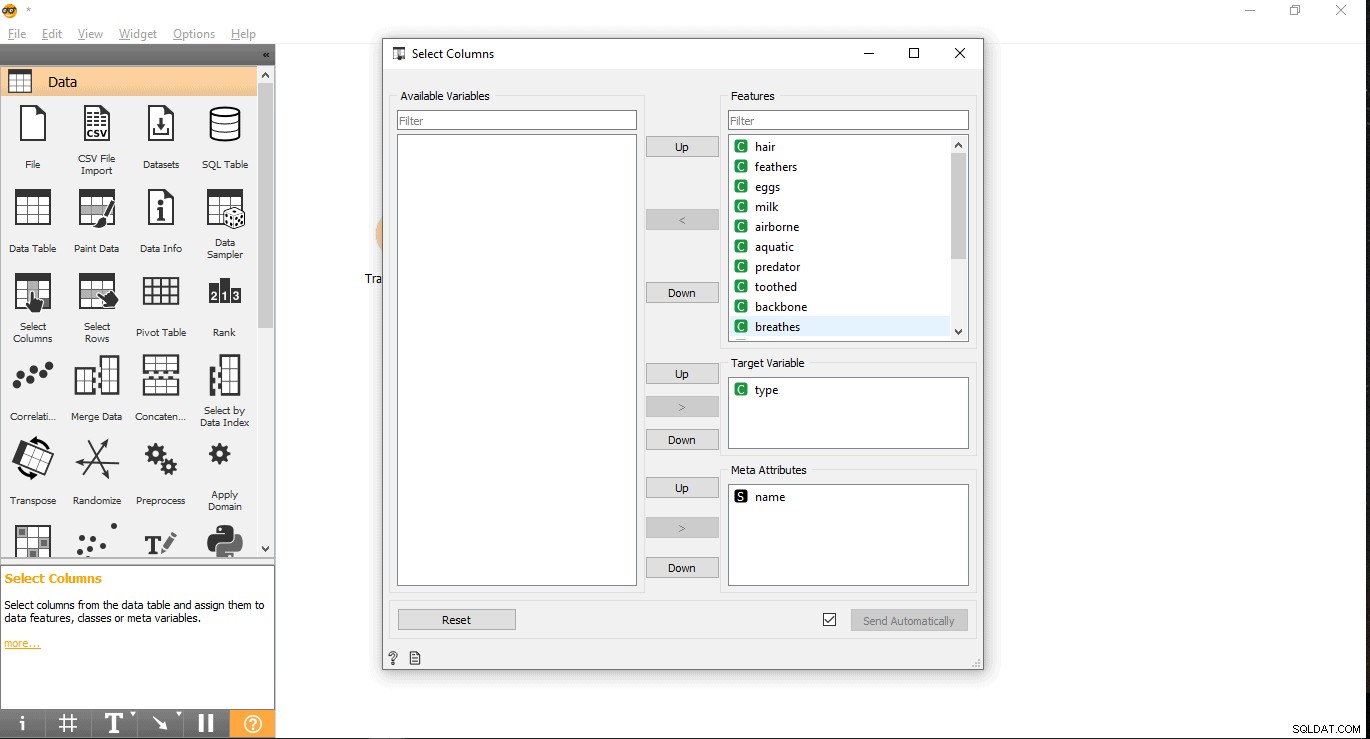
- Sök i målkolumnen under etiketten Funktioner. Här används typ som målvariabel eftersom vi behöver se vilken typ ett givet djur är.
- Dra och släpp det under Målvariabel och stäng popup-fönstret.
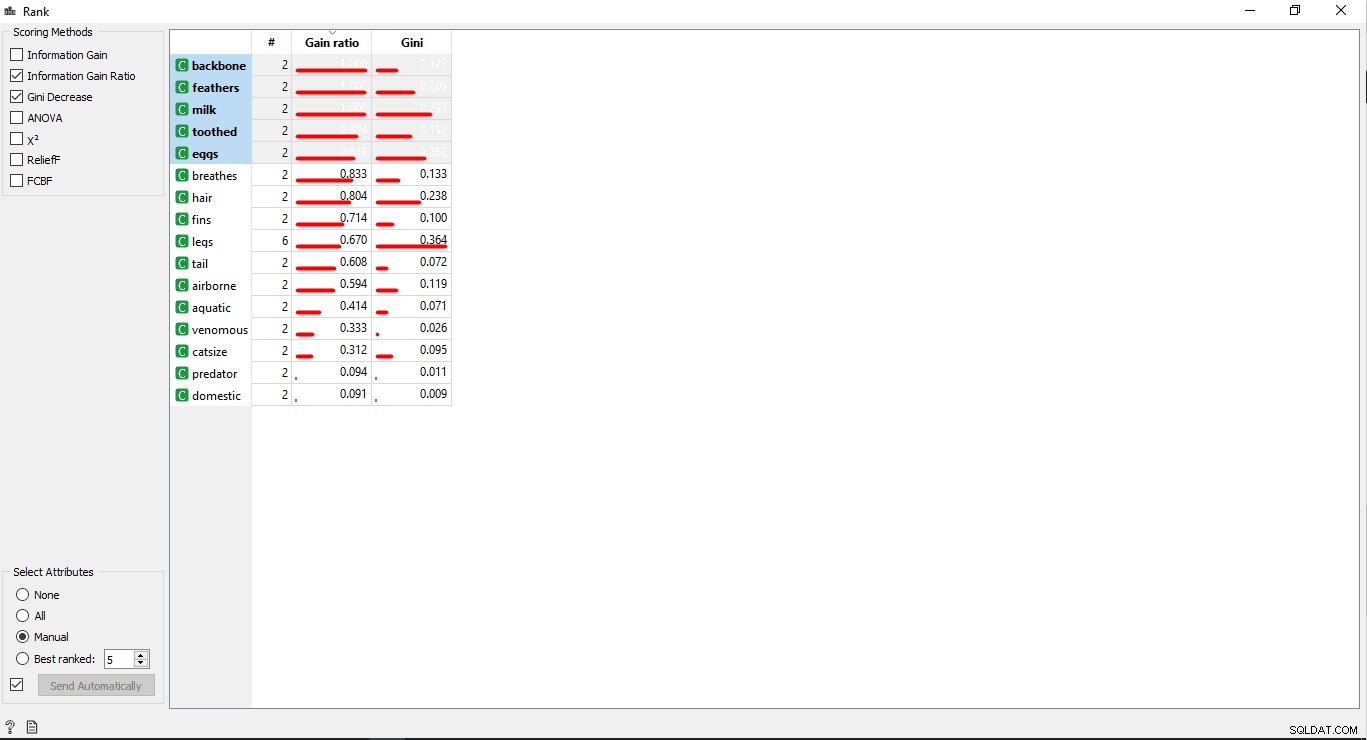
Steg 6:Kolumnrankning
Du kan rangordna eller poängsätta träningsvariabeln/-kolumnerna enligt deras korrelation med målkolumnen.
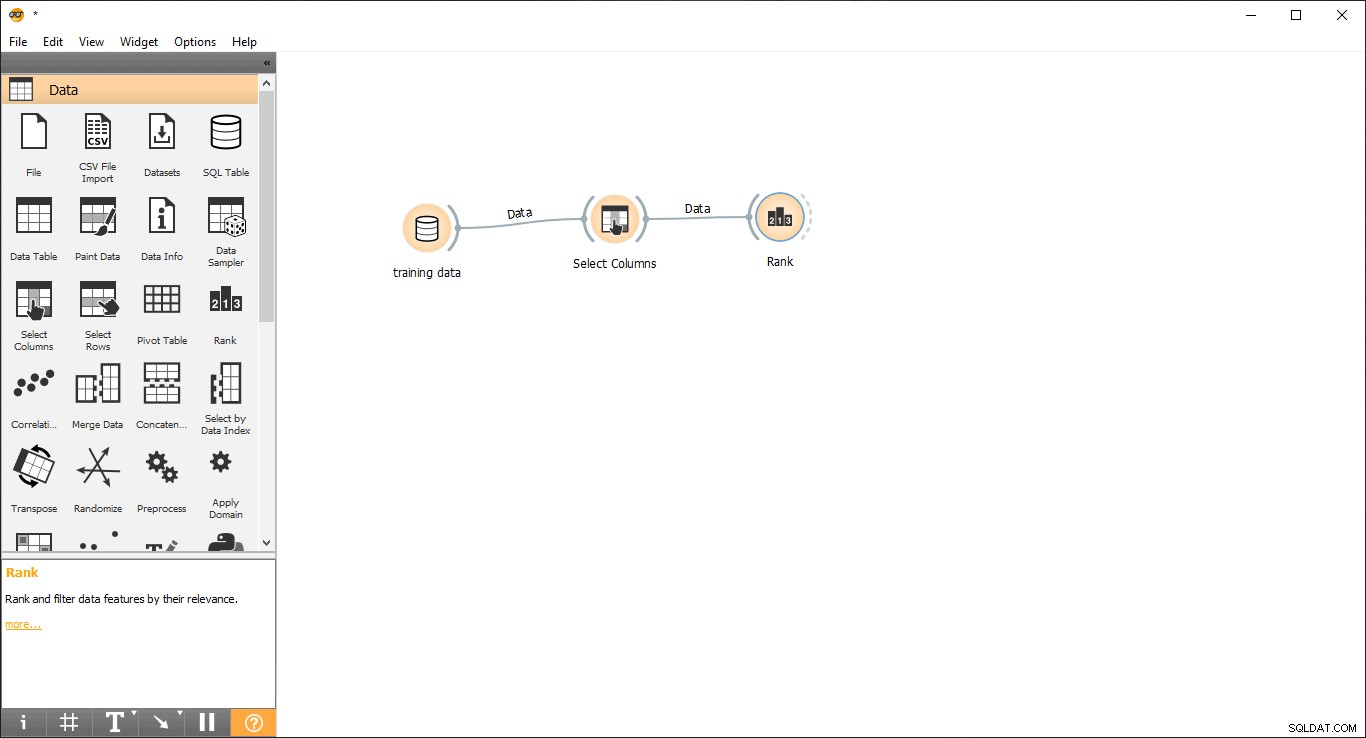
- Dra och släpp Rank widget från data meny.
- Rita en länklinje från Välj kolumner widget för att ranka widget .
- Dubbelklicka på Rank widget för att se de mest relaterade kolumnerna i träningsdatatabellen. Den kommer att välja de fem översta kolumnerna som standard.
Steg 7:Dataträning
I detta steg kommer Machine Learning Model (KNN) att tränas med träningsdatauppsättningen. Följ följande steg:
- Dra och släpp KNN widget från modellen meny.
- Rita en länklinje från Rank widget till KNN widget.
Steg 8:Ladda testdatauppsättning till PostgreSQL
En separat testdatauppsättning skapas för att utföra förutsägelser. Följ stegen för att ladda testdatauppsättningen i PostgreSQL-tabellen.
- Skapa en tabell för att lagra våra testdata . Här heter det test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Infoga testdata i testtabellen via COPY fråga. Innan du kör COPY fråga, se till att PostgreSQL har krävt läsbehörigheter för datafilen, annars misslyckas COPY-operationen.
OBS: Se till att du skriver en flik mellanrum mellan enstaka citattecken efter avgränsaren nyckelord. Ett frågetecken placeras avsiktligt i typen kolumn i testdatauppsättningen eftersom vi måste ta reda på typen av ett givet djur med vår maskininlärningsmodell.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Se skärmdumpen av testdatauppsättningen nedan

Steg 9:Importera testdata från PostgreSQL till Orange
Följ följande steg för att tillämpa förutsägelserna.
- Dra och släpp SQL-tabell widget från data meny.
- Byt namn på widget (valfritt)
- Högerklicka på SQL-tabellen widget.
- Välj Byt namn .
- Anslut till PostgreSQL för att ladda testdata.
- Dubbelklicka på Testdata widget.
- Anslut den till Testdata tabell från PostgreSQL.
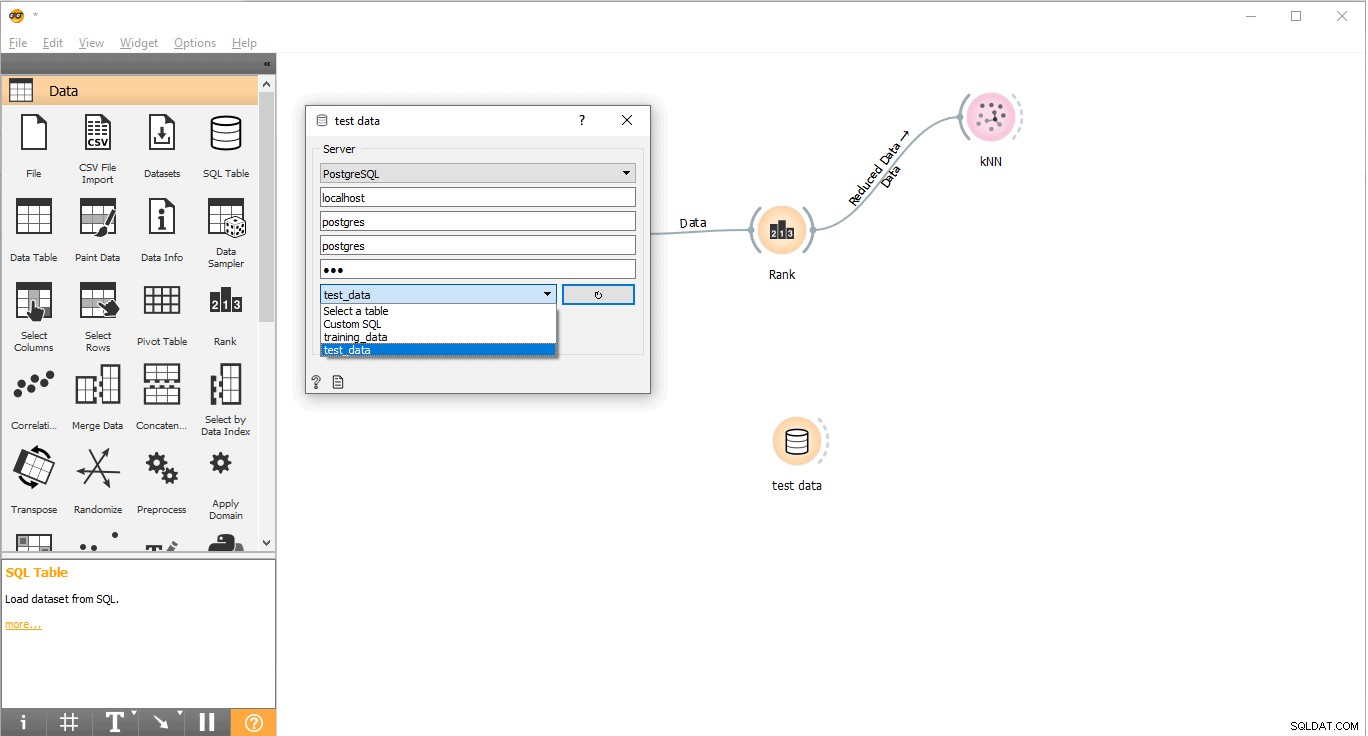
Nu är vi redo att utföra förutsägelser.
Steg 10:Förutsägelser
Prognos widget kommer att försöka förutsäga testdata baserat på träningsdata från KNN .
- Dra och släpp förutsägelse widget från Utvärdera meny.
- Rita en länkrad från Testdata widget till Prognos widget.
- Rita en länklinje från KNN widget till Prognos widget.
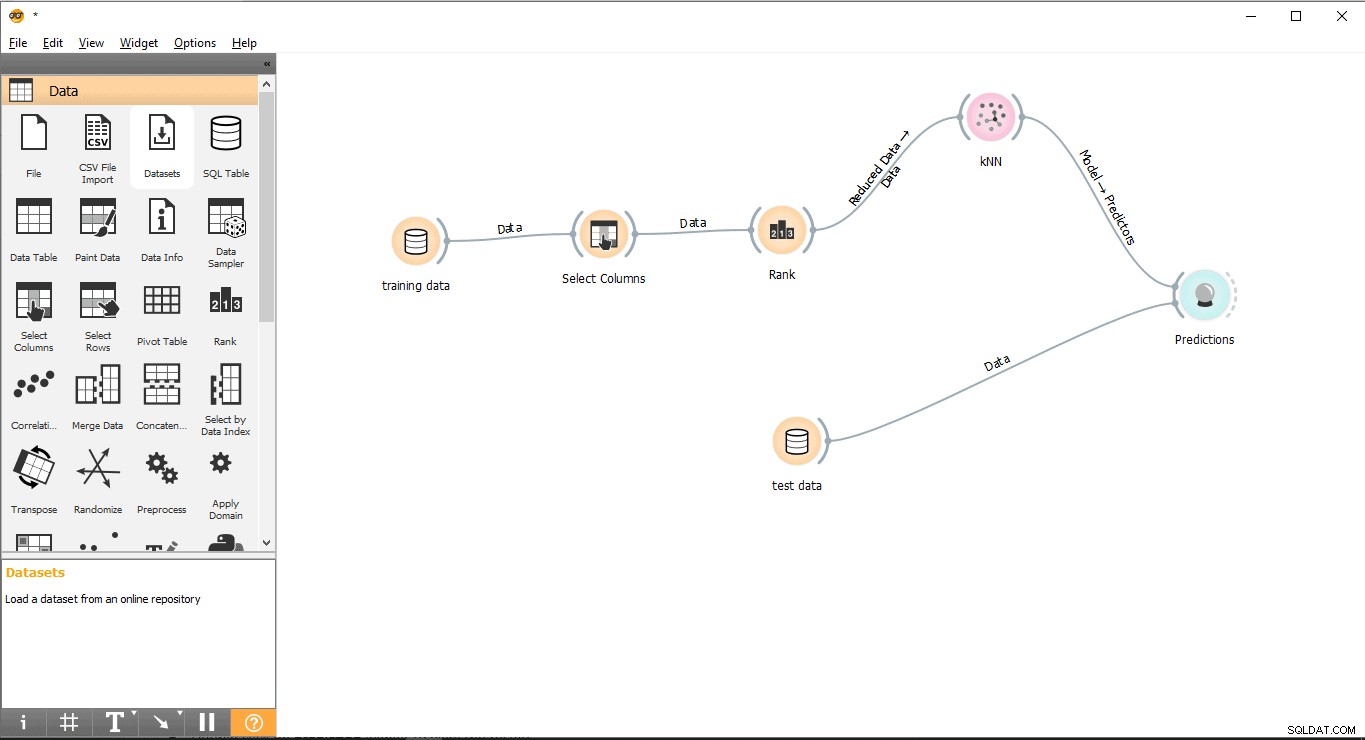
Steg 11:Resultat
Dubbelklicka på Prognos widget för att se resultaten.
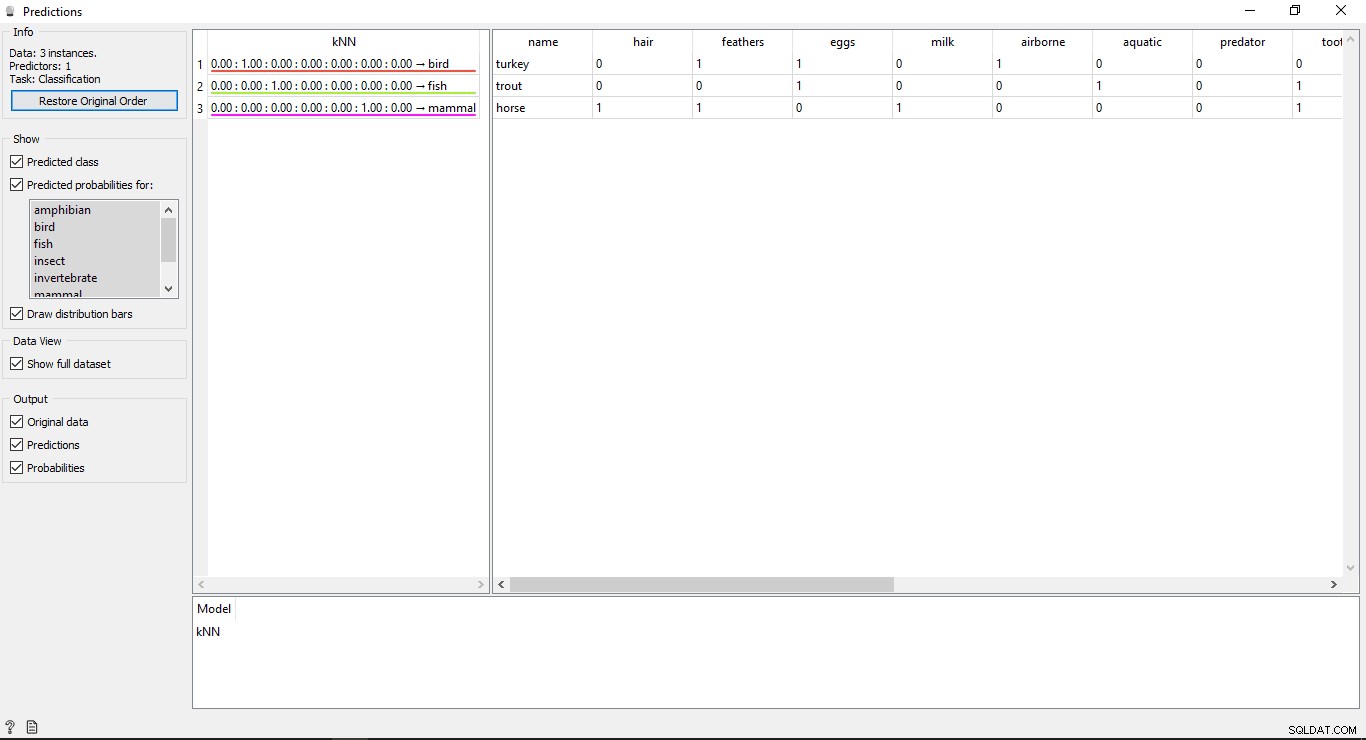
Förstå resultaten
Du kommer att se 2 huvudtabeller i prediktionsfönstret. Tabellen till vänster visar de förutspådda resultaten, medan tabellen till höger visar de ursprungliga testdata, som tillhandahölls för förutsägelser.
Sedan KNN modellen användes för att träna data så att du kommer att se en kolumn med namnet KNN som listar resultaten.
Som vi vet:
- Häst är ett däggdjur
- Öring är en fisk
- Turkiet är en fågel
Så KNN kan bestämma alla typer korrekt.
Predictions Noggrannhet
Om du ser tabellen på vänster sida i förutsägelsewidgetens utdata, har den några siffror före den förutsagda typen, dvs 1,00. 0,00 Dessa siffror visar noggrannheten hos den förutsagda typen.
Vi har använt 7 typer av djur i träningsdataset, så det visar totalt 7 kolumner med noggrannhetsvärden varje kolumn kommer att representera 1 typ av djur. Du kan kontrollera vilken kolumn som representerar vilken typ av djur genom att titta på listan på vänster sida av skärmen under Förutspådda sannolikheter för märka. Om du tittar på den första raden som säger Turkiet är en fågel . Vi kan se att dess noggrannhet är 1,00 (100 % från 2:a kolumnen). Detsamma gäller andra exempel på öring är en fisk och dess noggrannhet är 1,00 (100 % från 3:e kolumnen).
I den här artikeln har vi använt k-närmaste grannars algoritm (KNN) för att implementera Machine Learning-modellen. I nästa blogg kommer vi att använda Support Vector Machine (SVM)-modell.
För frågor eller kommentarer, vänligen kontakta oss genom att använda kontaktformuläret här.