Detta är den andra delen av en serie i två delar om 2ndQuadrants repmgr, ett högtillgänglighetsverktyg med öppen källkod för PostgreSQL.
I den första delen satte vi upp ett PostgreSQL 12-kluster med tre noder tillsammans med en "vittne"-nod. Klustret bestod av en primär nod och två standbynoder. Klustret och vittnesnoden var värd i ett Amazon Web Service Virtual Private Cloud (VPC). EC2-servrarna som är värd för Postgres-instanserna placerades i subnät i olika tillgänglighetszoner (AZ), som visas nedan:
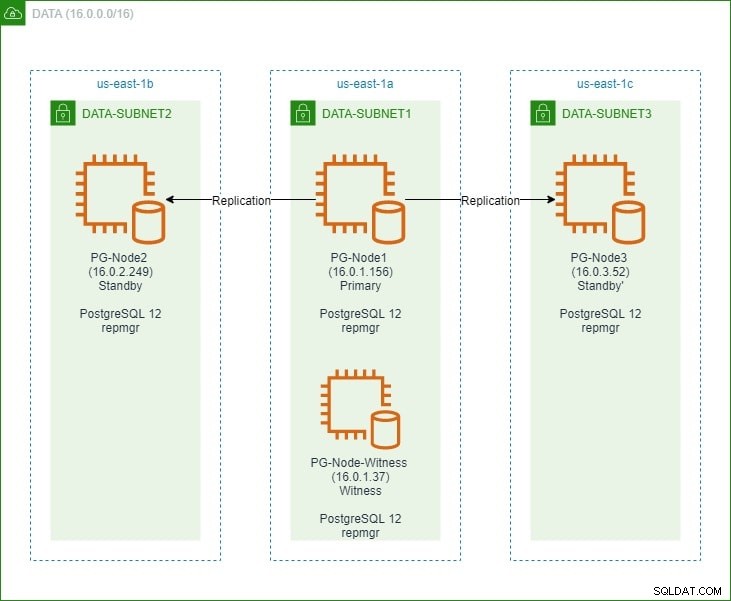
Vi kommer att göra omfattande referenser till nodnamnen och deras IP-adresser, så här är tabellen igen med nodernas detaljer:
| Nodnamn | IP-adress | Roll | Appar som körs |
| PG-nod1 | 16.0.1.156 | Primär | PostgreSQL 12 och repmgr |
| PG-nod2 | 16.0.2.249 | Vänteläge 1 | PostgreSQL 12 och repmgr |
| PG-Node3 | 16.0.3.52 | Vänteläge 2 | PostgreSQL 12 och repmgr |
| PG-Node-Vitne | 16.0.1.37 | Vittne | PostgreSQL 12 och repmgr |
Vi installerade repmgr i de primära och standby-noderna och registrerade sedan den primära noden med repmgr. Vi klonade sedan båda standbynoderna från den primära och startade dem. Båda standbynoderna registrerades också med repmgr. Kommandot "repmgr cluster show" visade att allt fungerade som förväntat:

Aktuellt problem
Att ställa in strömmande replikering med repmgr är mycket enkelt. Vad vi behöver göra härnäst är att säkerställa att klustret fungerar även när det primära blir otillgängligt. Detta är vad vi kommer att ta upp i den här artikeln.
I PostgreSQL-replikering kan en primär bli otillgänglig av flera anledningar. Till exempel:
- Operativsystemet för den primära noden kan krascha eller sluta svara
- Den primära noden kan förlora sin nätverksanslutning
- PostgreSQL-tjänsten i den primära noden kan krascha, stoppa eller oväntat bli otillgänglig
- PostgreSQL-tjänsten i den primära noden kan stoppas avsiktligt eller oavsiktligt
Närhelst en primär blir otillgänglig, gör en standby det inte befordra sig automatiskt till den primära rollen. Ett standby-läge fortsätter fortfarande att betjäna skrivskyddade frågor – även om data kommer att vara aktuella upp till det senaste LSN som tas emot från den primära. Alla försök till en skrivoperation kommer att misslyckas.
Det finns två sätt att lindra detta:
- Vänteläget är manuellt uppgraderas till en primär roll. Detta är vanligtvis fallet för en planerad failover eller "switchover"
- Vänteläget är automatiskt befordras till en primär roll. Detta är fallet med icke-inbyggda verktyg som kontinuerligt övervakar replikering och vidtar återställningsåtgärder när det primära inte är tillgängligt. repmgr är ett sådant verktyg.
Vi kommer att överväga det andra scenariot här. Denna situation har dock några extra utmaningar:
- Om det finns mer än en standby, hur avgör verktyget (eller standbyarna) vilken som ska marknadsföras som primär? Hur fungerar kvorumet och befordransprocessen?
- För flera standbylägen, om en görs till primär, hur börjar de andra noderna "följa den" som den nya primära?
- Vad händer om den primära fungerar, men av någon anledning tillfälligt kopplas bort från nätverket? Om en av standbyarna flyttas upp till primär och sedan den ursprungliga primära kommer tillbaka online, hur kan en "split brain"-situation undvikas?
remgrs svar:Witness Node och repmgr-demonen
För att svara på dessa frågor använder repmgr något som kallas en vittnesnod . När den primära är otillgänglig – är det vittnesnodens uppgift att hjälpa beredskapsvakterna att nå ett beslutfört om en av dem skulle befordras till en primär roll. Väntelägena når detta kvorum genom att avgöra om den primära noden faktiskt är offline eller endast tillfälligt otillgänglig. Vittnesnoden ska vara placerad i samma datacenter/nätverkssegment/subnät som den primära noden, men får ALDRIG köras på samma fysiska värd som den primära noden.
Kom ihåg att i den första delen av den här serien rullade vi ut en vittnesnod i samma tillgänglighetszon och subnät som den primära noden. Vi döpte den till PG-Node-Witness och installerade en PostgreSQL 12-instans där. I det här inlägget kommer vi att installera repmgr där också, men mer om det senare.
Den andra komponenten i lösningen är repmgr-demonen (repmgrd) körs i alla noder i klustret och vittnesnoden. Återigen, vi startade inte denna demon i den första delen av den här serien, men vi kommer att göra det här. Demonen kommer som en del av repmgr-paketet – när den är aktiverad kör den som en vanlig tjänst och övervakar kontinuerligt klustrets hälsa. Det initierar en failover när ett kvorum nås om att primären är offline. Det kan inte bara automatiskt främja ett standbyläge, det kan också återinitiera andra standbylägen i ett multinodkluster för att följa den nya primära .
Kvorumsprocessen
När en beredskapstjänst inser att den inte kan se den primära, samråder den med andra beredskapsenheter. Alla väntelägen som körs i klustret når ett kvorum för att välja en ny primär med hjälp av en serie kontroller:
- Varje standby frågar andra standbyar om den tid den senast "såg" den primära. Om en standbys senaste replikerade LSN eller tidpunkten för senaste kommunikation med den primära är nyare än den nuvarande nodens senaste replikerade LSN eller tiden för senaste kommunikation, gör noden ingenting och väntar på att kommunikationen med den primära ska återställas
- Om ingen av standbyarna kan se den primära kontrollerar de om vittnesnoden är tillgänglig. Om vittnesnoden inte heller kan nås, antar beredskapsfunktionerna att det är ett nätverksavbrott på primärsidan och fortsätter inte att välja en ny primär
- Om vittnet kan nås antar beredskapsvakterna att primärvalet är nere och fortsätter med att välja primär
- Noden som konfigurerades som den "föredragna" primära kommer sedan att främjas. Varje standby kommer att få sin replikering återinitierad för att följa den nya primära.
Konfigurera klustret för automatisk failover
Vi kommer nu att konfigurera klustret och vittnesnoden för automatisk failover.
Steg 1:Installera och konfigurera repmgr i Witness
Vi såg redan hur man installerar repmgr-paketet i vår senaste artikel. Vi gör detta i vittnesnoden också:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
Och sedan:
# yum install repmgr12 -y
Därefter lägger vi till följande rader i vittnesnodens postgresql.conf-fil:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
Vi lägger också till följande rader i filen pg_hba.conf i vittnesnoden. Notera hur vi använder CIDR-intervallet för klustret istället för att ange individuella IP-adresser.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Obs
[Stegen som beskrivs här är endast för demonstrationsändamål. Vårt exempel här är att använda externt nåbara IP-adresser för noderna. Att använda listen_address ='*' tillsammans med pg_hbas "trust"-säkerhetsmekanism utgör därför en säkerhetsrisk och bör INTE användas i produktionsscenarier. I ett produktionssystem kommer alla noderna att finnas i ett eller flera privata undernät, nåbara via privata IP-adresser från jumphosts.]
Med postgresql.conf och pg_hba.conf ändringar gjorda skapar vi repmgr-användaren och repmgr-databasen i vittnet och ändrar repmgr-användarens standardsökväg:
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Slutligen lägger vi till följande rader i filen repmgr.conf, som finns under /etc/repmgr/12/
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
När konfigurationsparametrarna är inställda startar vi om PostgreSQL-tjänsten i vittnesnoden:
# systemctl restart postgresql-12.service
För att testa anslutningen för att bevittna noden repmgr, kan vi köra det här kommandot från den primära noden:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Därefter registrerar vi vittnesnoden med repmgr genom att köra kommandot "repmgr witness register" som postgres-användare. Notera hur vi använder adressen till den primära nod, och INTE vittnesnoden i kommandot nedan:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Detta beror på att kommandot "repmgr witness register" lägger till vittnesnodens metadata till primärnodens repmgr-databas och, om nödvändigt, initierar vittnesnoden genom att installera repmgr-tillägget och kopiera repmgr-metadatan till vittnesnoden.
Utdatan kommer att se ut så här:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Slutligen kontrollerar vi statusen för den övergripande inställningen från valfri nod:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Utdatan ser ut så här:

Steg 2:Ändra sudoers-filen
Med klustret och vittnet igång lägger vi till följande rader i sudoers-filen i varje nod i klustret och vittnesnoden:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Steg 3:Konfigurera repmgrd-parametrar
Vi har redan lagt till fyra parametrar i filen repmgr.conf i varje nod. Parametrarna som läggs till är de grundläggande som behövs för repmgr-drift. För att aktivera repmgr-demonen och automatisk failover, måste ett antal andra parametrar aktiveras/läggas till. I följande underavsnitt kommer vi att beskriva varje parameter och värdet de kommer att ställas in på i varje nod.
failover
Parametern för failover är en av de obligatoriska parametrarna för repmgr-demonen. Den här parametern talar om för demonen om den ska initiera en automatisk failover när en failover-situation upptäcks. Den kan ha något av två värden:"manuell" eller "automatisk". Vi kommer att ställa in detta på automatiskt i varje nod:
failover='automatic'
promote_command
Detta är en annan obligatorisk parameter för repmgr-demonen. Den här parametern talar om för repmgr-demonen vilket kommando den ska köra för att främja standby. Värdet på den här parametern är vanligtvis kommandot "repmgr standby promote", eller sökvägen till ett skalskript som anropar kommandot. För vårt användningsfall ställer vi in detta på följande i varje nod:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
följ_kommando
Detta är den tredje obligatoriska parametern för repmgr-demonen. Denna parameter säger åt en standby-nod att följa den nya primära. Repmgr-demonen ersätter platshållaren %n med nod-ID:t för den nya primära vid körning:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
prioritet
Prioritetsparametern lägger vikt till en nods behörighet att bli primär. Att ställa in denna parameter till ett högre värde ger en nod större behörighet att bli den primära noden. Om du ställer in detta värde till noll för en nod säkerställer du att noden aldrig marknadsförs som primär.
I vårt användningsfall har vi två standbylägen:PG-Node2 och PG-Node3. Vi vill marknadsföra PG-Node2 som den nya primära när PG-Node1 går offline, och PG-Node3 att följa PG-Node2 som dess nya primära. Vi ställer in parametern på följande värden i de två standbynoderna:
| Nodnamn | Parameterinställning |
| PG-nod2 | prioritet =60 |
| PG-Node3 | prioritet =40 |
monitor_interval_secs
Den här parametern talar om för repmgr-demonen hur ofta (i antal sekunder) den ska kontrollera tillgängligheten för uppströmsnoden. I vårt fall finns det bara en uppströmsnod:den primära noden. Standardvärdet är 2 sekunder, men vi kommer uttryckligen att ställa in detta i varje nod:
monitor_interval_secs=2
connection_check_type
Parametern connection_check_type dikterar protokollet som repmgr-demonen kommer att använda för att nå uppströmsnoden. Denna parameter kan ha tre värden:
- ping :repmgr använder metoden PQPing()
- anslutning :repmgr försöker skapa en ny anslutning till uppströmsnoden
- fråga :repmgr försöker köra en SQL-fråga på uppströmsnoden med den befintliga anslutningen
Återigen kommer vi att ställa in denna parameter till standardvärdet för ping i varje nod:
connection_check_type='ping'
reconnect_attempts och reconnect_interval
När den primära blir otillgänglig kommer repmgr-demonen i standbynoderna att försöka återansluta till den primära under reconnect_attempts-tider. Standardvärdet för denna parameter är 6. Mellan varje återanslutningsförsök väntar den i reconnect_interval sekunder, vilket har ett standardvärde på 10. För demonstrationsändamål kommer vi att använda ett kort intervall och färre återanslutningsförsök. Vi ställer in denna parameter i varje nod:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
När den primära blir otillgänglig i ett kluster med flera noder, kan beredskapsfunktionerna rådfråga varandra för att bygga ett kvorum om en failover. Detta görs genom att fråga varje standby om den tid den senast såg den primära. Om en nods senaste kommunikation var mycket nyligen och senare än den tidpunkt då den lokala noden såg den primära, antar den lokala noden att den primära fortfarande är tillgänglig och går inte vidare med ett failover-beslut.
För att aktivera denna konsensusmodell måste parametern primary_visibility_consensus ställas in på "true" i varje nod – inklusive vittnet:
primary_visibility_consensus=true
standby_disconnect_on_failover
När parametern standby_disconnect_on_failover är inställd på "true" i en standby-nod, kommer repmgr-demonen att säkerställa att dess WAL-mottagare är frånkopplad från den primära och inte tar emot några WAL-segment. Den kommer också att vänta på att WAL-mottagarna för andra standbynoder slutar innan man fattar ett failover-beslut. Denna parameter bör ställas in på samma värde i varje nod. Vi ställer in detta på "true".
standby_disconnect_on_failover=true
Om du ställer in den här parametern till true betyder det att varje standby-nod har slutat ta emot data från den primära när failover inträffar. Processen kommer att ha en fördröjning på 5 sekunder plus den tid det tar för WAL-mottagaren att stoppa innan ett failover-beslut fattas. Som standard kommer repmgr-demonen att vänta i 30 sekunder för att bekräfta att alla syskonnoder har slutat ta emot WAL-segment innan övergången sker.
repmgrd_service_start_command och repmgrd_service_stop_command
Dessa två parametrar anger hur man startar och stoppar repmgr-demonen med hjälp av kommandona "repmgr daemon start" och "repmgr daemon stop".
I grund och botten är dessa två kommandon omslag runt operativsystemkommandon för att starta/stoppa tjänsten. De två parametervärdena mappar dessa kommandon till deras OS-specifika versioner. Vi ställer in dessa parametrar till följande värden i varje nod:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
PostgreSQL Service Start/Stop/Restart Kommandon
Som en del av sin operation kommer repmgr-demonen ofta behöva stoppa, starta eller starta om PostgreSQL-tjänsten. För att säkerställa att detta sker smidigt är det bäst att ange motsvarande operativsystemkommandon som parametervärden i filen repmgr.conf. Vi kommer att ställa in fyra parametrar i varje nod för detta ändamål:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
monitoring_history
Om du ställer in parametern monitoring_history till "yes" säkerställer du att repmgr sparar sina klusterövervakningsdata. Vi ställer in detta på "ja" i varje nod:
monitoring_history=yes
log_status_interval
Vi ställer in parametern i varje nod för att specificera hur ofta repmgr-demonen ska logga ett statusmeddelande. I det här fallet ställer vi in detta till var 60:e sekund:
log_status_interval=60
Steg 4:Starta repmgr Daemon
Med parametrarna nu inställda i klustret och vittnesnoden, kör vi en torrkörning av kommandot för att starta repmgr-demonen. Vi testar detta i den primära noden först, och sedan de två standbynoderna, följt av vittnesnoden. Kommandot måste köras som postgres-användaren:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Utdata ska se ut så här:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
Därefter startar vi demonen i alla fyra noderna:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Utdata i varje nod bör visa att demonen har startat:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
Vi kan också kontrollera tjänstens starthändelse från de primära noderna eller standbynoderna:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
Utdata ska visa att demonen övervakar anslutningarna:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Slutligen kan vi kontrollera demonutmatningen från sysloggen i något av standbylägena:
# cat /var/log/messages | grep repmgr | less
Här är utdata från PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Att kontrollera sysloggen i den primära noden visar en annan typ av utdata:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Steg 5:Simulera en misslyckad primärgrupp
Nu kommer vi att simulera en misslyckad primär genom att stoppa den primära noden (PG-Node1). Från nodens skalprompt kör vi följande kommando:
# systemctl stop postgresql-12.service
Failover-processen
När processen slutar väntar vi i ungefär en minut eller två och kontrollerar sedan syslog-filen för PG-Node2. Följande meddelanden visas. För klarhet och enkelhet har vi färgkodade grupper av meddelanden och lagt till blanksteg mellan raderna:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
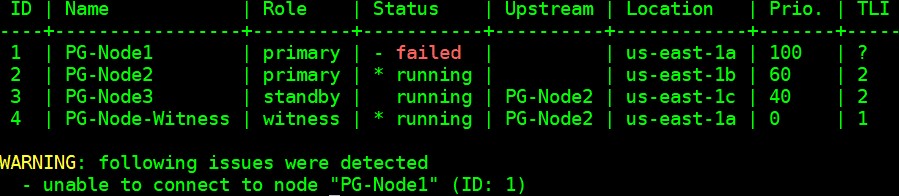
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Slutsats
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1