Jag har börjat skriva om verktyget (pglupgrade) som jag utvecklade för att utföra automatiserade uppgraderingar av PostgreSQL-kluster nära noll. I det här inlägget kommer jag att prata om verktyget och diskutera dess designdetaljer.
Du kan kolla den första delen av serien här: Near-Zero Downtime Automated Upgrades of PostgreSQL Clusters in Cloud (Del I).

Verktyget är skrivet i Ansible. Jag har tidigare erfarenhet av att arbeta med Ansible, och jag arbetar för närvarande med det i 2ndQuadrant också, vilket är anledningen till att det var ett bekvämt alternativ för mig. Med detta sagt kan du implementera den minimala uppgraderingslogiken för driftstopp, som kommer att förklaras senare i det här inlägget, med ditt favoritautomatiseringsverktyg.
Mer läsning:Blogginlägg Ansible älskar PostgreSQL , PostgreSQL Planet i Ansible Galaxy och presentation hantera PostgreSQL med Ansible.
Pglupgrade Playbook
I Ansible, playbooks är de huvudsakliga skripten som utvecklas för att automatisera processer såsom provisionering av molninstanser och uppgradering av databaskluster. Playbooks kan innehålla en eller flera pjäser . Playbooks kan också innehålla variabler , roller och hanterare om definierat.
Verktyget består av två huvudspelböcker. Den första spelboken är provision.yml som automatiserar processen för att skapa Linux-maskiner i molnet, enligt specifikationerna (Detta är en valfri spelbok skriven endast för att tillhandahålla molninstanser och inte direkt relaterad till uppgraderingen ). Den andra (och huvud) spelboken är pglupgrade.yml som automatiserar uppgraderingsprocessen för databaskluster.
Pglupgrade playbook har åtta pjäser för att orkestrera uppgraderingen. Varje pjäs, använd en konfigurationsfil (config.yml ), utför vissa uppgifter på värdarna eller värdgrupperna som är definierade i värd inventeringsfilen (host.ini ).
Inventeringsfil
En inventeringsfil låter Ansible veta vilka servrar den behöver för att ansluta med SSH, vilken anslutningsinformation den kräver och eventuellt vilka variabler som är associerade med dessa servrar. Nedan kan du se ett exempel på en inventeringsfil som har använts för att utföra automatiserade klusteruppgraderingar för en av fallstudierna som utformats för verktyget. Vi kommer att diskutera dessa fallstudier i kommande inlägg i den här serien.
[old-primary]54.171.211.188[new-primary]54.246.183.100[old-standbys]54.77.249.8154.154.49.180[new-standbys:children]old-standbys[pgbouncer].54.154.4.>Inventeringsfil (
host.ini)Exempelinventeringsfilen innehåller fem värdar under fem värdgrupper som inkluderar
old-primary,new-primary,old-standbys,new-standbysochpgbouncer. En server kan tillhöra mer än en grupp. Till exempel,old-standbysär en grupp som innehållernew-standbysgrupp, vilket betyder värdarna som är definierade underold-standbysgruppen (54.77.249.81 och 54.154.49.180) tillhör ocksånew-standbysgrupp. Med andra ord,new-standbysgruppen ärvs från (barn till)old-standbysgrupp. Detta uppnås genom att använda den speciella:childrensuffix.När inventeringsfilen är klar kan Ansible playbook köras via
ansible-playbookkommandot genom att peka på inventeringsfilen (om inventeringsfilen inte finns på standardplatsen annars kommer den att använda standardinventeringsfilen) som visas nedan:$ ansible-playbook -i hosts.ini pglupgrade.ymlKöra en Ansible-spelbok
Konfigurationsfil
Pglupgrade playbook använder en konfigurationsfil (
config.yml) som tillåter användare att ange värden för de logiska uppgraderingsvariablerna.Som visas nedan,
config.ymllagrar huvudsakligen PostgreSQL-specifika variabler som krävs för att konfigurera ett PostgreSQL-kluster sompostgres_old_datadirochpostgres_new_datadiratt lagra sökvägen till PostgreSQL-datakatalogen för de gamla och nya PostgreSQL-versionerna;postgres_new_confdiratt lagra sökvägen till PostgreSQL-konfigurationskatalogen för den nya PostgreSQL-versionen;postgres_old_dsnochpostgres_new_dsnför att lagra anslutningssträngen förpglupgrade_userför att kunna ansluta tillpglupgrade_databaseav de nya och gamla primära servrarna. Själva anslutningssträngen består av de konfigurerbara variablerna så att användaren (pglupgrade_user) och databasen (pglupgrade_database) information kan ändras för de olika användningsfallen.ansible_user:adminpglupgrade_user:pglupgradepglupgrade_pass:pglupgrade123pglupgrade_database:postgresreplica_user:postgresreplica_pass:""pgbouncer_user:pgbouncerpostgres_old_version:9.5postgres_new_version:9.6subscription_name:upgradereplication_set:upgradeinitial_standbys:1postgres_old_dsn:"dbname={{pglupgrade_database}} host={{groups['old- primär'][0]}} användare {{pglupgrade_user}}"postgres_new_dsn:"dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} användare={{pglupgrade_user}}" postgres_old_datadir:"/var/lib/postgresql/{{postgres_old_version}}/main" postgres_new_datadir:"/var/lib/postgresql/{{postgres_new_version}}/main"postgres_new_confdir:"/etc/postgresql/_new{_postgres}} main"Konfigurationsfil (
config.yml)Som ett nyckelsteg för varje uppgradering kan PostgreSQL-versionsinformationen anges för den aktuella versionen (
postgres_old_version) och versionen som kommer att uppgraderas till (postgres_new_version). Till skillnad från fysisk replikering där replikeringen är en kopia av systemet på byte-/blocknivå, tillåter logisk replikering selektiv replikering där replikeringen kan kopiera den logiska datan inkluderar specificerade databaser och tabellerna i dessa databaser. Av denna anledning,config.ymlgör det möjligt att konfigurera vilken databas som ska replikeras viapglupgrade_databasevariabel. Dessutom måste logisk replikeringsanvändare ha replikeringsprivilegier, vilket är anledningen till attpglupgrade_uservariabeln ska anges i konfigurationsfilen. Det finns andra variabler som är relaterade till fungerande internals av pglogical, såsomsubscription_nameochreplication_setsom används i den pglogiska rollen.Högtillgänglighetsdesign av Pglupgrade-verktyget
Pglupgrade-verktyget är utformat för att ge användaren flexibilitet vad gäller High Availability (HA) egenskaper för de olika systemkraven.
initial_standbysvariabel (seconfig.yml) är nyckeln för att ange HA-egenskaper för klustret medan uppgraderingen pågår.Till exempel om
initial_standbysär satt till 1 (kan ställas in på vilket nummer som helst som klusterkapaciteten tillåter), det betyder att det kommer att skapas 1 standby i det uppgraderade klustret tillsammans med mastern innan replikeringen startar. Med andra ord, om du har 4 servrar och du ställer initial_standbys till 1, kommer du att ha 1 primär och 1 standby-server i den uppgraderade nya versionen, samt 1 primär och 1 standby-server i den gamla versionen.Detta alternativ gör det möjligt att återanvända befintliga servrar medan uppgraderingen fortfarande pågår. I exemplet med fyra servrar kan de gamla primära och standby-servrarna byggas om till två nya standby-servrar efter att replikeringen är klar.
När
initial_standbysvariabeln är inställd på 0, kommer det inte att skapas några initiala standby-servrar i det nya klustret innan replikeringen startar.Om
initial_standbyskonfigurationen låter förvirrande, oroa dig inte. Detta kommer att förklaras bättre i nästa blogginlägg när vi diskuterar två olika fallstudier.Slutligen tillåter konfigurationsfilen att ange gamla och nya servergrupper. Detta kan tillhandahållas på två sätt. För det första, om det finns ett befintligt kluster kan servrarnas IP-adresser (kan vara antingen bare-metal eller virtuella servrar ) ska anges i
hosts.inifil genom att överväga önskade HA-egenskaper under uppgraderingen.Det andra sättet är att köra
provision.ymlplaybook (detta är hur jag provisionerade molninstanserna men du kan använda dina egna provisioneringsskript eller manuellt provisioneringsinstanser ) för att tillhandahålla tomma Linux-servrar i molnet (AWS EC2-instanser) och hämta servrarnas IP-adresser tillhosts.inifil. Hur som helst,config.ymlkommer att få värdinformation viahosts.inifil.Arbetsflöde för uppgraderingsprocessen
Efter att ha förklarat konfigurationsfilen (
config.yml) som används av pglupgrade playbook, kan vi förklara arbetsflödet för uppgraderingsprocessen.
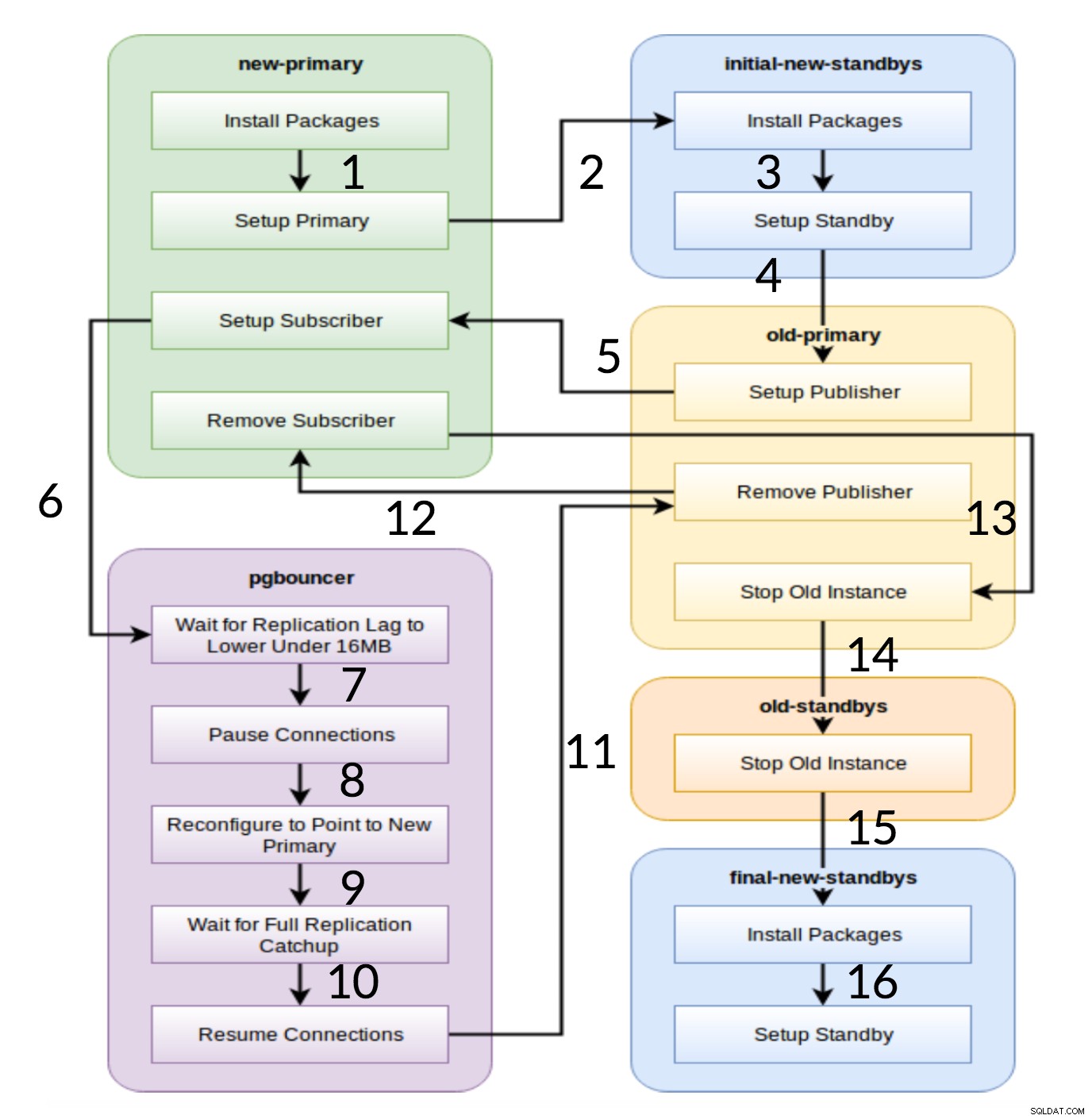
Pglupgrade Workflow
Som det framgår av diagrammet ovan finns det sex servergrupper som genereras i början baserat på konfigurationen (båda
hosts.iniochconfig.yml).new-primaryochold-primarygrupper kommer alltid att ha en server,pgbouncergrupp kan ha en eller flera servrar och alla standbygrupper kan ha noll eller flera servrar i sig. Implementeringsmässigt är hela processen uppdelad i åtta steg. Varje steg motsvarar ett spel i pglupgrade-spelboken, som utför de nödvändiga uppgifterna på de tilldelade värdgrupperna. Uppgraderingsprocessen förklaras genom följande spelningar:
- Bygg värdar baserat på konfiguration: Förberedelsespel som bygger interna grupper av servrar baserat på konfigurationen. Resultatet av detta spel (i kombination med
hosts.ini). innehåll) är de sex servergrupperna (illustrerade med olika färger i arbetsflödesdiagrammet) som kommer att användas av följande sju spelningar.- Konfigurera ett nytt kluster med första vänteläge: Konfigurerar ett tomt PostgreSQL-kluster med de nya primära och initiala standby-lägena (om det finns några definierade). Det säkerställer att det inte finns några kvar från PostgreSQL-installationer från den tidigare användningen.
- Ändra den gamla primära för att stödja logisk replikering: Installerar pglogical tillägg. Ställer sedan in utgivaren genom att lägga till alla tabeller och sekvenser i replikeringen.
- Replicera till den nya primära: Ställer in abonnenten på den nya mastern som fungerar som en trigger för att starta logisk replikering. Den här uppspelningen avslutar replikeringen av befintlig data och börjar fånga upp vad som har förändrats sedan den startade replikeringen.
- Byt pgbouncer (och applikationer) till ny primär: När replikeringsfördröjningen konvergerar till noll, pausar pgbouncern för att gradvis byta applikation. Sedan pekar den pgbouncer config till den nya primära och väntar tills replikeringsskillnaden blir noll. Slutligen återupptas pgbouncer och alla väntande transaktioner förs vidare till den nya primära och börjar bearbetas där. Inledande väntelägen används redan och svarar på läsbegäranden.
- Rensa upp replikeringsinställningarna mellan gammal primär och ny primär: Avbryter anslutningen mellan den gamla och den nya primära servrarna. Eftersom alla applikationer flyttas till den nya primära servern och uppgraderingen är gjord, behövs inte längre logisk replikering. Replikering mellan primära och standby-servrar fortsätter med fysisk replikering.
- Stoppa det gamla klustret: Postgres-tjänsten stoppas i gamla värdar för att säkerställa att ingen applikation längre kan ansluta till den.
- Konfigurera om resten av standbylägena för den nya primära: Bygger om andra standbylägen om det finns några kvarvarande värdar förutom initiala standbylägen. I den andra fallstudien finns det inga kvarvarande standbyservrar att bygga om. Det här steget ger chansen att bygga om den gamla primära servern som en ny standby om den pekas i gruppen för nya standbys på hosts.ini. Återanvändbarheten av befintliga servrar (även den gamla primära) uppnås genom att använda tvåstegs standby-konfigurationsdesignen för pglupgrade-verktyget. Användaren kan ange vilka servrar som ska bli standbys för det nya klustret före uppgraderingen, och vilka som ska bli standbys efter uppgraderingen.
Slutsats
I det här inlägget diskuterade vi implementeringsdetaljerna och designen med hög tillgänglighet för pglupgrade-verktyget. När vi gjorde det nämnde vi också några nyckelbegrepp för Ansible-utveckling (dvs. playbook, inventering och konfigurationsfiler) med hjälp av verktyget som exempel. Vi illustrerade arbetsflödet för uppgraderingsprocessen och sammanfattade hur varje steg fungerar med en motsvarande lek. Vi kommer att fortsätta att förklara pglupgrade genom att visa fallstudier i kommande inlägg i den här serien.
Tack för att du läste!