Under de senaste månaderna har vi på 2ndQuadrant arbetat med att slå samman PostgreSQL 9.6 till Postgres-XL, vilket visade sig vara ganska utmanande av olika anledningar, och tog mer tid än planerat från början på grund av flera invasiva uppströmsförändringar. Om du är intresserad, titta på det officiella arkivet här (titta på "master"-grenen för nu).
Det återstår fortfarande en hel del arbete att göra – slå ihop några återstående bitar från uppströms, åtgärda kända buggar och regressionsfel, testa, etc. Om du funderar på att bidra till Postgres-XL är detta en idealisk möjlighet (skicka mig en e-post så hjälper jag dig med de första stegen).
Men totalt sett är Postgres-XL 9.6 helt klart ett stort steg framåt på ett antal viktiga områden.
Nya funktioner i Postgres-XL 9.6
Så, vilka nya funktioner får Postgres-XL från PostgreSQL 9.6 sammanslagning? Jag skulle helt enkelt kunna hänvisa dig till uppströms release notes – de flesta av förbättringarna gäller direkt för XL 9.6, med undantag för de som är relaterade till funktioner som inte stöds på XL.
Den huvudsakliga användarsynliga förbättringen i PostgreSQL 9.6 var helt klart parallella frågor, och det gäller även Postgres-XL 9.6.
Intra-nod parallellism
Innan PostgreSQL 9.6 var Postgres-XL ett av sätten att få parallella frågor (genom att placera flera Postgres-XL-noder på samma maskin). Eftersom PostgreSQL 9.6 är det inte längre nödvändigt, men det betyder också att Postgres-XL får parallellitet inom nod.
Som jämförelse är detta vad Postgres-XL 9.5 tillät dig att göra – distribuera en fråga till flera datanoder, men varje datanod var fortfarande föremål för gränsen för "en backend per fråga", precis som vanlig PostgreSQL.
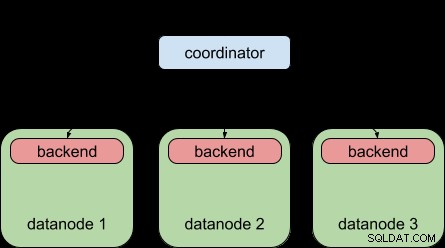
Tack vare PostgreSQL 9.6 parallella frågefunktion kan Postgres-XL 9.6 nu göra detta:
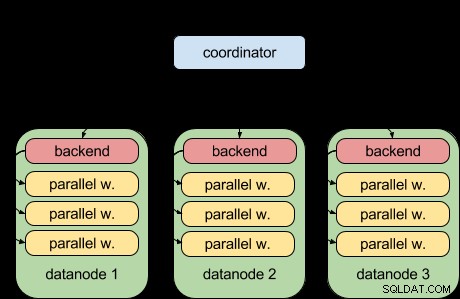
Det vill säga att varje datanod nu kan köra sin del av frågan parallellt med hjälp av den uppströms parallella frågeinfrastrukturen. Det är bra och gör Postgres-XL mycket kraftfullare när det kommer till analytiska arbetsbelastningar.
Underhålla en gaffel
Jag nämnde att denna sammanslagning visade sig vara mer utmanande än vi först förväntade oss, av flera anledningar.
För det första är det svårt att underhålla gafflar i allmänhet, särskilt när uppströmsprojektet går lika snabbt som PostgreSQL. Du måste utveckla funktioner som är specifika för din gaffel, vilket är anledningen till att gafflar finns i första hand. Men man vill också hänga med uppströms, annars hamnar man hopplöst efter. Vilket är anledningen till att några av de befintliga gafflarna fortfarande har fastnat på PostgreSQL 8.x och saknar alla godbitar som har begåtts sedan dess.
För det andra gjordes sammanslagningen i en stor klump, precis som alla tidigare (9,5, 9,2, …). Det vill säga, alla uppströms commits slogs samman i ett enda git merge-kommando. Det är ganska garanterat att orsaka många sammanslagningskonflikter, i den mån koden inte ens kompileras, för att inte tala om att köra regressionstester eller något liknande.
Så den första satsen med korrigeringar handlar om att få den till ett kompilerbart tillstånd, nästa sats handlar om att få den att faktiskt köras utan omedelbara segfel, och sedan börjar den "vanliga" korrigeringen (kör regressionstester, fixa problem, skölj och upprepa) .
Dessa komplexiteter är inneboende i gaffelunderhåll (och en anledning till att du förmodligen borde ompröva att starta ytterligare en gaffel och istället bidra direkt antingen till Postgres och/eller Postgres-XL).
Men det finns sätt att avsevärt minska effekten – till exempel planerar vi att göra nästa sammanslagning (med PostgreSQL 10) i mindre bitar. Det borde minimera omfattningen av sammanslagningskonflikter och göra det möjligt för oss att lösa felen mycket snabbare.
Närmare PostgreSQL
Intressant nog tillät antagandet av parallellism från uppströms också oss att bli av med mycket kod från XL-kodbasen – ett utmärkt exempel på detta är den parallella aggregerade koden, som enkelt ersatte den XL-specifika koden.
Ett annat exempel på en uppströmsändring som avsevärt påverkade XL-koden är "pathification" för övre planerare, som skjuts fram sent i 9.6-utvecklingscykeln. Detta visade sig vara en mycket invasiv förändring (i själva verket är ett antal av de öppna buggarna sannolikt relaterade till det), men i slutändan tillät det oss att förenkla planeringskoden (konstruera i huvudsak korrekta vägar istället för att justera den resulterande planen).
När jag säger att sammanslagningen tillät oss att förenkla XL-koden och göra den närmare PostgreSQL, vad menar jag med det? Det enklaste sättet att kvantifiera förändringen är att göra "git diff -stat" mot den matchande uppströmsgrenen och jämföra siffrorna. För grenarna 9.5 och 9.6 ser resultaten ut så här:
| version | filer ändrade | tillägg | raderingar |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4,3%) | -33351 (-14,2%) | -709 (-3,8%) |
Uppenbarligen minskar 9.6-sammanslagningen avsevärt delta mot uppströms (med ~14% totalt). Var kommer denna skillnad ifrån?
För det första beror en del av den minskningen på en äkta kodförenkling. Ett utmärkt exempel på detta är parallella aggregat, som i stort sett är en 1:1-ersättning av den ursprungliga Postgres-XL-implementeringen. Så vi har precis tagit bort det och använder uppströmsimplementeringen istället. Vi hoppas kunna hitta fler sådana platser i framtiden och använda uppströmsimplementering istället för att behålla vår egen.
För det andra kommer mycket av minskningen från att ta bort död kod. Vi har inte bara minskat några döda/oåtkomliga kodbitar, vi har också upptäckt en hel del källfiler som inte ens kompilerades, och så vidare.
Vad händer härnäst?
Vid det här laget har vi slagit samman ändringar upp till b5bce6c1, vilket är platsen där PostgreSQL 9.6 delas från master. Så för att komma ikapp med PostgreSQL 9.6.2 måste vi slå samman de återstående ändringarna i 9.6-grenen. Med tanke på att det mestadels bara borde finnas buggfixar, borde det vara ett (förhoppningsvis) ganska enkelt arbete jämfört med den fullständiga sammanslagningen.
Naturligtvis kommer det att finnas buggar. Faktum är att det fortfarande finns några misslyckade regressionstester vid denna tidpunkt. Det måste fixas innan du gör en officiell version av XL 9.6. Och vi måste göra fler tester, så om du är intresserad av att hjälpa Postgres-XL skulle detta vara oerhört fördelaktigt.
Ett irritationsmoment vi hela tiden hör om är paket, eller brist på dem. Du kanske har märkt att de sista tillgängliga paketen är ganska gamla, och det finns bara .rpm, inget annat. Vi planerar att ta itu med detta och börja erbjuda uppdaterade paket i flera smaker (t.ex. .rpm och .deb).
Vi planerar också att göra några förändringar i hur utvecklingsprocessen är organiserad, för att göra det lättare att bidra och delta i utvecklingsprocessen. Det är verkligen ett separat ämne som inte är relaterat till 9.6-grenen, så jag kommer att publicera mer information om det om några dagar.