PostgreSQL är ett fantastiskt projekt och det utvecklas i en otrolig hastighet. Vi kommer att fokusera på utvecklingen av feltoleransfunktioner i PostgreSQL genom hela dess versioner med en serie blogginlägg. Detta är det andra inlägget i serien och vi kommer att prata om replikering och dess betydelse för feltolerans och pålitlighet hos PostgreSQL.
Om du vill se utvecklingens framsteg från början, vänligen kolla det första blogginlägget i serien:Evolution of Fault Tolerance in PostgreSQL
PostgreSQL-replikering
Databasreplikering är termen vi använder för att beskriva tekniken som används för att underhålla en kopia av en uppsättning data på en fjärrkontroll systemet. Att behålla en pålitlig kopia av ett körande system är en av de största problemen med redundans och vi gillar alla underhållbara, lättanvända och stabila kopior av vår data.
Låt oss titta på den grundläggande arkitekturen. Vanligtvis kallas individuella databasservrar som noder . Hela gruppen av databasservrar som är involverade i replikering är känd som ett kluster . En databasserver som låter en användare göra ändringar är känd som en master eller primär , eller kan beskrivas som en källa till förändringar. En databasserver som endast tillåter skrivskyddad åtkomst kallas Hot Standby . (Begreppet Hot Standby förklaras i detalj under rubriken Standby Modes. )
Nyckelaspekten med replikering är att dataändringar fångas upp på en master och sedan överförs till andra noder. I vissa fall kan en nod skicka dataändringar till andra noder, vilket är en process som kallas kaskadkoppling eller relä . Således är mastern en sändnod men inte alla sändande noder behöver vara masters. Replikering kategoriseras ofta efter om mer än en huvudnod är tillåten, i vilket fall den kommer att kallas multimasterreplikering .
Låt oss se hur PostgreSQL hanterar replikering över tid och vad som är den senaste tekniken för feltolerans enligt replikeringsvillkoren.
PostgreSQL-replikeringshistorik
Historiskt (runt år 2000-2005) koncentrerade sig Postgres endast till feltolerans/återställning av en nod, vilket mestadels uppnås av WAL, transaktionsloggen. Feltolerans hanteras delvis av MVCC (multi-version concurrency system), men det är främst en optimering.
Write-ahead-loggning var och är fortfarande den största feltoleransmetoden i PostgreSQL. I grund och botten, bara att ha WAL-filer där du skriver allt och kan återhämta dig i form av misslyckande genom att spela upp dem. Detta räckte för enstaka nodarkitekturer och replikering anses vara den bästa lösningen för att uppnå feltolerans med flera noder.
Postgres-gemenskapen trodde länge att replikering är något som Postgres inte borde tillhandahålla och borde hanteras av externa verktyg, det var därför verktyg som Slony och Londiste blev existerande. (Vi kommer att ta upp triggerbaserade replikeringslösningar vid nästa blogginlägg i serien.)
Så småningom stod det klart att det inte räcker med en servertolerans och fler krävde ordentlig feltolerans på hårdvaran och rätt sätt att växla, något inbyggt i Postgres. Det var då fysisk (då fysisk streaming) replikering kom till liv.
Vi kommer att gå igenom alla replikeringsmetoder senare i inlägget men låt oss se de kronologiska händelserna i PostgreSQL-replikeringshistoriken efter större utgåvor:
- PostgreSQL 7.x (~2000)
- Replikering bör inte vara en del av kärnan i Postgres
- Londiste – Slony (triggerbaserad logisk replikering)
- PostgreSQL 8.0 (2005)
- Point-in-Time Recovery (WAL)
- PostgreSQL 9.0 (2010)
- Strömmande replikering (fysisk)
- PostgreSQL 9.4 (2014)
- Logisk avkodning (extraktion av ändringsuppsättningar)
Fysisk replikering
PostgreSQL löste kärnreplikeringsbehovet med vad de flesta relationsdatabaser gör; tog WAL och gjorde det möjligt att skicka den över nätverket. Sedan appliceras dessa WAL-filer i en separat Postgres-instans som körs skrivskyddad.
Den skrivskyddade standby-instansen tillämpar bara ändringarna (genom WAL) och de enda skrivoperationerna kommer igen från samma WAL-logg. Det är i princip hur strömmande replikering mekanismen fungerar. I början var replikering ursprungligen att skicka alla filer –loggfrakt- , men senare utvecklades det till streaming.
Vid loggsändning skickade vi hela filer via archive_command . Logiken är ganska enkel där:du bara skicka arkivet och loggen den till någonstans – som hela 16 MB WAL-filen – och sedan ansöker den till någonstans, och sedan hämtar du nästa och ansök den där och det går sådär. Senare blev det streaming över nätverk genom att använda libpq-protokollet i PostgreSQL version 9.0.
Den befintliga replikeringen är mer korrekt känd som Physical Streaming Replication, eftersom vi streamar en serie fysiska förändringar från en nod till en annan. Det betyder att när vi infogar en rad i en tabell genererar vi ändringsposter för inlägget plus alla indexposter .
När vi VACUUM en tabell som vi också genererar ändringsposter.
Dessutom registrerar Physical Streaming Replication alla ändringar på byte/blocknivå , vilket gör det väldigt svårt att göra något annat än att bara spela upp allt
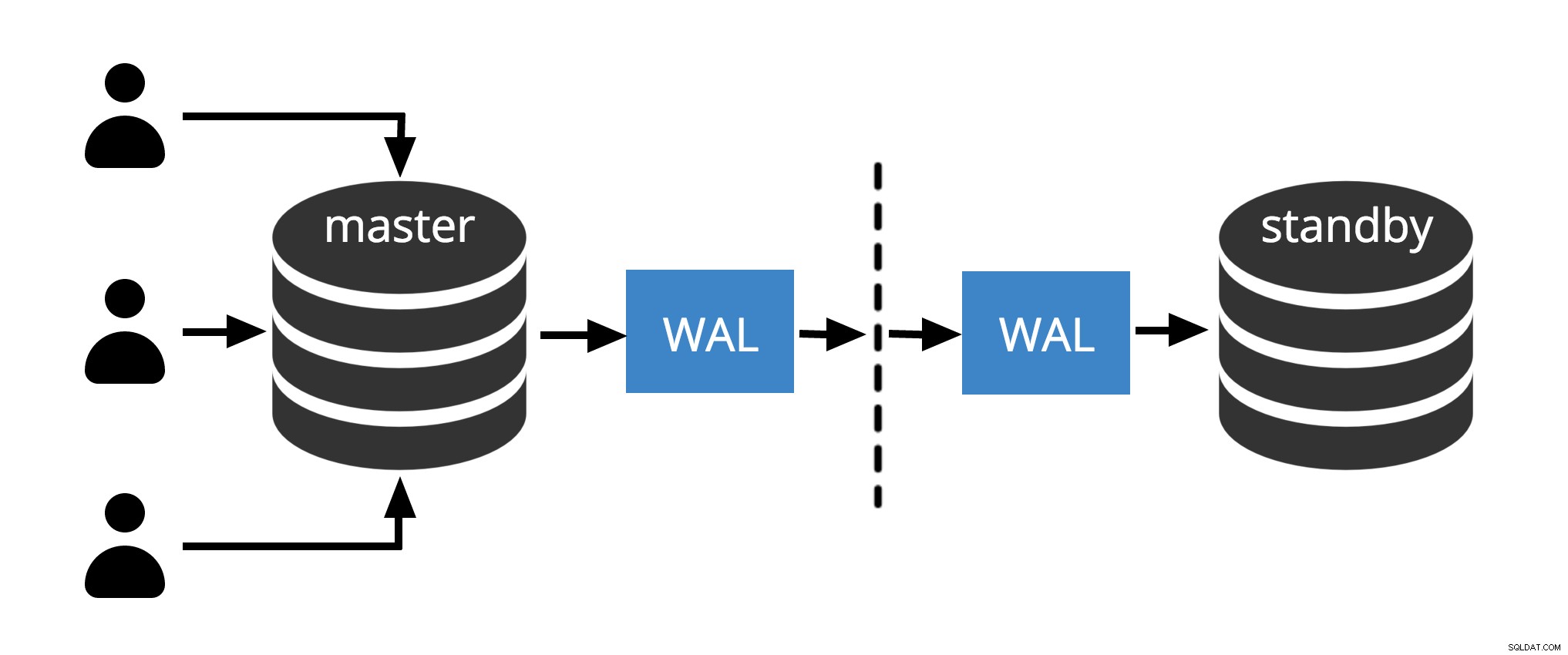
Fig.1 Fysisk replikering
Fig. 1 visar hur fysisk replikering fungerar med bara två noder. Klientförfrågningar på masternoden, ändringarna skrivs till en transaktionslogg (WAL) och kopieras över nätverket till WAL på standbynoden. Återställningsprocessen på standbynoden läser sedan ändringarna från WAL och applicerar dem på datafilerna precis som under kraschåterställning. Om vänteläget är i hot standby läget kan klienter utfärda skrivskyddade frågor på noden medan detta händer.
Obs! Fysisk replikering avser helt enkelt att skicka WAL-filer över nätverket från master till standby-nod. Filer kan skickas med olika protokoll som scp, rsync, ftp... skillnaden mellan Fysisk replikering och Physical Streaming Replication is Streaming Replication använder ett internt protokoll för att skicka WAL-filer (avsändare och mottagarprocesser )
Väntelägen
Flera noder ger hög tillgänglighet. Av den anledningen har moderna arkitekturer vanligtvis standby-noder. Det finns olika lägen för standbynoder (varmt och varmt standby). Listan nedan förklarar de grundläggande skillnaderna mellan olika standby-lägen och visar även fallet med multimasterarkitektur.
Varm standby
Kan aktiveras omedelbart, men kan inte utföra användbart arbete förrän den är aktiverad. Om vi kontinuerligt matar serien av WAL-filer till en annan maskin som har laddats med samma bas backup-fil, har vi ett varmt standby-system:när som helst kan vi ta fram den andra maskinen och den kommer att ha en nästan aktuell kopia av databasen. Varmt vänteläge tillåter inte skrivskyddade frågor, Fig. 2 representerar helt enkelt detta faktum.
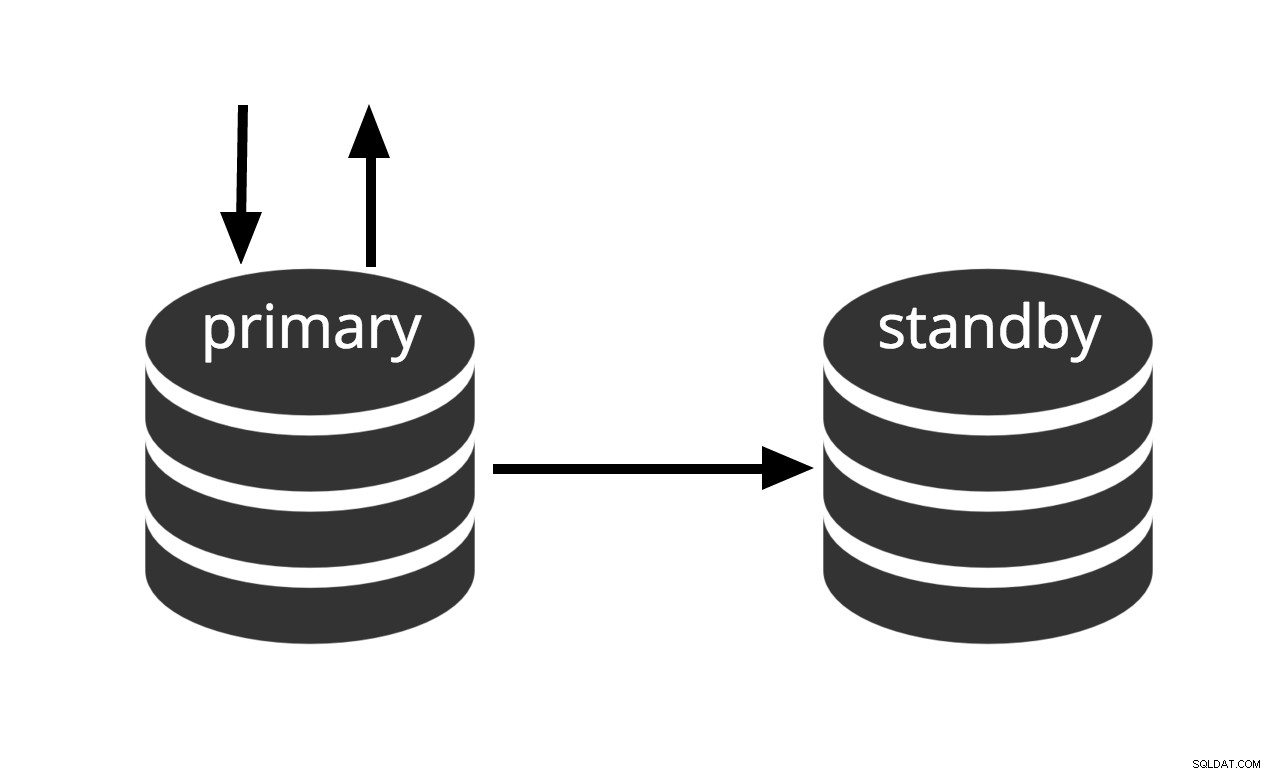
Fig. 2 Varm standby
Återställningsprestanda för ett varmt standbyläge är tillräckligt bra för att standbyläget normalt bara är några ögonblick från full tillgänglighet när det väl har aktiverats. Som ett resultat kallas detta en varm standby-konfiguration som erbjuder hög tillgänglighet.
Hot Standby
Hot standby är termen som används för att beskriva möjligheten att ansluta till servern och köra skrivskyddade frågor medan servern är i arkivåterställning eller standbyläge. Detta är användbart både för replikeringsändamål och för att återställa en säkerhetskopia till önskat tillstånd med stor precision.
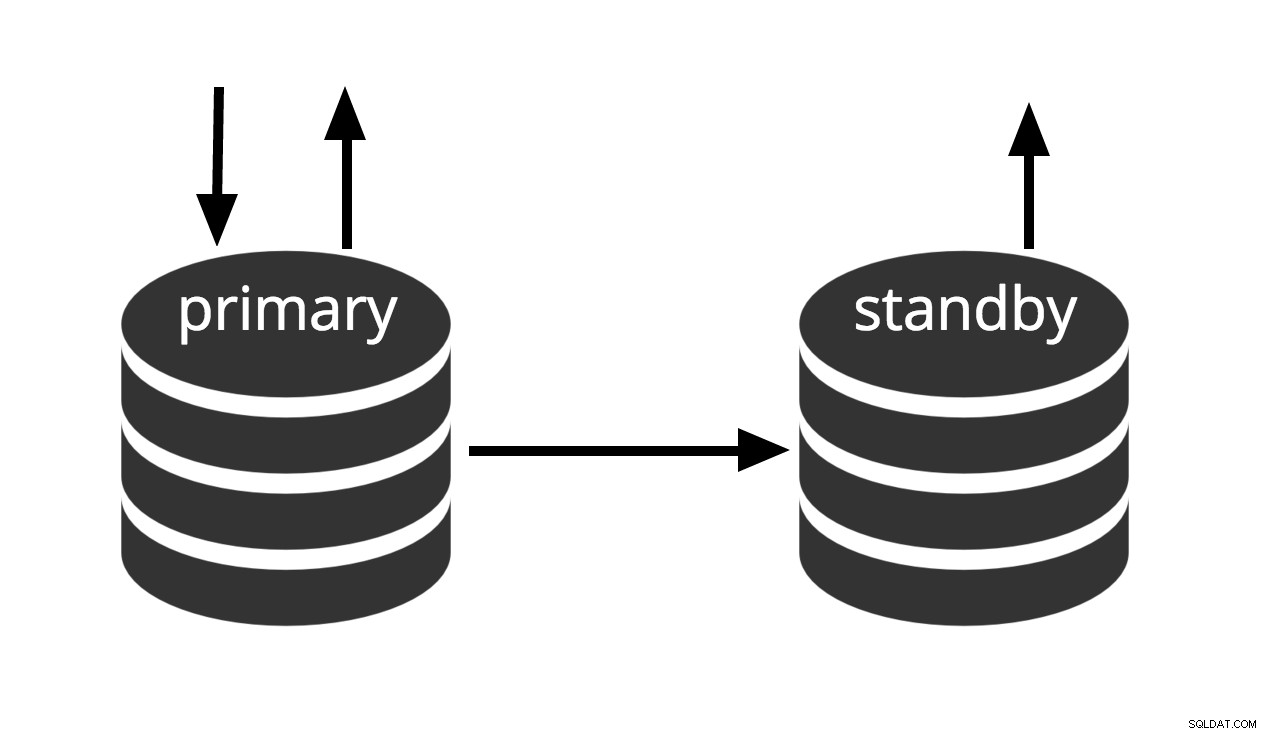 Fig.3 Hot Standby
Fig.3 Hot Standby
Termen hot standby hänvisar också till serverns förmåga att gå från återställning till normal drift medan användare fortsätter att köra frågor och/eller hålla sina anslutningar öppna. Fig. 3 visar att standby-läge tillåter skrivskyddade frågor.
Multi-Master
Alla noder kan utföra läs-/skrivarbete. (Vi kommer att ta upp flermasterarkitekturer vid nästa blogginlägg i serien.)
WAL-nivåparameter
Det finns ett samband mellan att ställa in wal_level parametern i postgresql.conf filen och vad är denna inställning lämplig för. Jag skapade en tabell för att visa relationen för PostgreSQL version 9.6.

Failover och Switchover
I enkelmasterreplikering, om mastern dör, måste ett av standbylägena ta dess plats (promotion ). Annars kommer vi inte att kunna acceptera nya skrivtransaktioner. Termen beteckningar, master och standby, är alltså bara roller som vilken nod som helst kan ta någon gång. För att flytta masterrollen till en annan nod utför vi en procedur som heter Switchover .
Om befälhavaren dör och inte återhämtar sig, är det allvarligare rollbytet känt som en failover . På många sätt kan dessa likna varandra, men det hjälper att använda olika termer för varje evenemang. (Att känna till villkoren för failover och switchover kommer att hjälpa oss med förståelsen av tidslinjeproblemen i nästa blogginlägg.)
Slutsats
I det här blogginlägget diskuterade vi PostgreSQL-replikering och dess betydelse för att ge feltolerans och pålitlighet. Vi täckte fysisk strömningsreplikering och pratade om standbylägen för PostgreSQL. Vi nämnde Failover och Switchover. Vi fortsätter med PostgreSQL-tidslinjer vid nästa blogginlägg.
Referenser
PostgreSQL-dokumentation
Logisk replikering i PostgreSQL 5432…MeetUs-presentation av Petr Jelinek
PostgreSQL 9 Administration Cookbook – Andra upplagan