I förra blogginlägget förklarade jag kort hur vi fick prestationssiffrorna publicerade i det pglogiska tillkännagivandet. I det här blogginlägget skulle jag vilja diskutera prestandagränserna för logiska replikeringslösningar i allmänhet, och även hur de tillämpas på pglogical.
fysisk replikering
Låt oss först se hur fysisk replikering (inbyggd i PostgreSQL sedan version 9.0) fungerar. En något förenklad figur med två bara två noder ser ut så här:
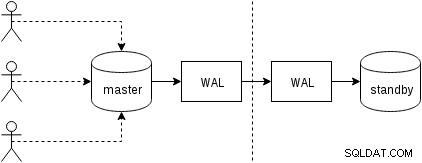
Klienter exekverar frågor på masternoden, ändringarna skrivs till en transaktionslogg (WAL) och kopieras över nätverket till WAL på standbynoden. Återställningen i standby-processen i standby-läge läser sedan ändringarna från WAL och tillämpar dem på datafilerna precis som under återställningen. Om vänteläget är i "hot_standby"-läge kan klienter utfärda skrivskyddade frågor på noden medan detta händer.
Detta är mycket effektivt eftersom det finns väldigt lite ytterligare bearbetning – ändringar överförs och skrivs till standby som en ogenomskinlig binär blob. Naturligtvis är återställningen inte gratis (både när det gäller CPU och I/O), men det är svårt att bli effektivare än så här.
De uppenbara potentiella flaskhalsarna med fysisk replikering är nätverkets bandbredd (överföring av WAL från master till standby) och även I/O i standby, som kan vara mättad av återställningsprocessen som ofta utfärdar en mängd slumpmässiga I/O-förfrågningar ( i vissa fall mer än befälhavaren, men låt oss inte gå in på det).
logisk replikering
Logisk replikering är lite mer komplicerad, eftersom den inte hanterar ogenomskinlig binär WAL-ström, utan en ström av "logiska" ändringar (föreställ dig INSERT-, UPDATE- eller DELETE-satser, även om det inte är helt korrekt eftersom vi har att göra med strukturerad representation av uppgifterna). Att ha de logiska ändringarna gör det möjligt att göra intressanta saker som konfliktlösning, replikera endast valda tabeller, till ett annat schema eller mellan olika versioner (eller till och med olika databaser).
Det finns olika sätt att få ändringarna – det traditionella tillvägagångssättet är att använda triggers som registrerar ändringarna i en tabell och låter en anpassad process kontinuerligt läsa dessa ändringar och tillämpa dem i vänteläge genom att köra SQL-frågor. Och allt detta drivs av en extern demonprocess (eller möjligen flera processer, som körs på båda noderna), som illustreras i nästa bild

Det är vad slony eller londiste gör, och även om det fungerade ganska bra, betyder det en hel del omkostnader – till exempel kräver det att dataförändringarna samlas in och att data skrivits flera gånger (till den ursprungliga tabellen och till en "logg"-tabell, och även till WAL för båda dessa tabeller). Vi kommer att diskutera andra källor till omkostnader senare. Även om pglogical behöver uppnå samma mål, uppnår den dem på olika sätt, tack vare flera funktioner som lagts till i de senaste PostgreSQL-versionerna (därmed inte tillgängliga sedan de andra verktygen implementerades):

Det vill säga, istället för att upprätthålla en separat logg över förändringar, förlitar sig pglogical på WAL – detta är möjligt tack vare en logisk avkodning tillgänglig i PostgreSQL 9.4, som gör det möjligt att extrahera logiska ändringar från WAL-loggen. Tack vare detta behöver pglogical inga dyra triggers och kan vanligtvis undvika att skriva data två gånger på mastern (förutom för stora transaktioner som kan spilla till disken).
Efter avkodning av varje transaktion överförs den till standby-läge och appliceringsprocessen tillämpar sina ändringar på standby-databasen. pglogical tillämpar inte ändringarna genom att köra vanliga SQL-frågor, utan på en lägre nivå, och kringgår de overhead som är associerade med att analysera och planera SQL-frågor. Detta ger pglogical en betydande fördel jämfört med de befintliga lösningarna som alla går igenom SQL-lagret (därmed betalar analysen och planeringen).
potentiella flaskhalsar
Uppenbarligen är logisk replikering mottaglig för samma flaskhalsar som fysisk replikering, det vill säga det är möjligt att mätta nätverket när ändringarna överförs och I/O i vänteläge när de tillämpas i vänteläge. Det finns också en hel del omkostnader på grund av ytterligare steg som inte finns i en fysisk replikering.
Vi måste på något sätt samla in de logiska förändringarna, medan fysisk replikering helt enkelt vidarebefordrar WAL som ström av byte. Som redan nämnts förlitar sig befintliga lösningar vanligtvis på triggers som skriver ändringarna till en "logg"-tabell. pglogical förlitar sig istället på WAL (Write-ahead-loggen) och logisk avkodning för att uppnå samma sak, vilket är billigare än triggers och inte heller behöver skriva data två gånger i de flesta fall (med den extra bonusen att vi automatiskt tillämpar ändringarna i commit-ordning).
Därmed inte sagt att det inte finns några möjligheter till ytterligare förbättringar – till exempel sker avkodningen för närvarande bara när transaktionen har genomförts, så med stora transaktioner kan detta öka replikeringsfördröjningen. Fysisk replikering strömmar helt enkelt WAL-ändringarna till den andra noden och har således inte denna begränsning. Stora transaktioner kan också spilla till disken, vilket orsakar dubbla skrivningar, eftersom uppströmskällan måste lagra dem tills de begår och de kan skickas till nedströms.
Framtida arbete är planerat för att göra det möjligt för pglogical att börja streama stora transaktioner medan de fortfarande pågår i uppströms, vilket minskar latensen mellan uppströms commit och nedströms commit och minskar uppströms skrivförstärkning.
Efter att ändringarna har överförts till vänteläget måste tillämpningsprocessen verkligen tillämpa dem på något sätt. Som nämnts i föregående avsnitt gjorde de befintliga lösningarna det genom att konstruera och köra SQL-kommandon, medan pglogical helt förbigår SQL-lagret och den associerade overheaden.
Ändå gör det inte applikationen helt gratis eftersom den fortfarande behöver utföra saker som primärnyckelsökningar, uppdatera index, exekvera triggers och utföra olika andra kontroller. Men det är betydligt billigare än den SQL-baserade metoden. På sätt och vis fungerar det mycket som COPY och är särskilt snabbt på enkla bord utan triggers, främmande nycklar, etc.
I alla logiska replikeringslösningar sker vart och ett av dessa steg (avkodning och applicering) i en enda process, så det finns en ganska begränsad mängd CPU-tid. Detta är förmodligen den mest pressande flaskhalsen i alla befintliga lösningar, eftersom du kanske har en ganska biffig maskin med tiotals eller till och med hundratals klienter som kör frågor parallellt, men allt detta måste gå igenom en enda process som avkodar dessa ändringar (på master) och en process som tillämpar dessa ändringar (i vänteläge).
Begränsningen "en enda process" kan lättas upp något genom att använda separata databaser, eftersom varje databas hanteras av en separat process. När det gäller en enda databas, planeras framtida arbete för att parallellisera tillämpningen via en pool av bakgrundsarbetare för att lindra denna flaskhals.