Skärmbild #1 visar några punkter för att skilja mellan Merge Join transformation och Lookup transformation .
Angående uppslag:
Om du vill hitta matchande rader i källa 2 baserat på indata från källa 1 och om du vet att det bara kommer att finnas en matchning för varje inmatningsrad, skulle jag föreslå att du använder Lookup-operationen. Ett exempel skulle vara dig OrderDetails tabell och du vill hitta det matchande Order Id och Customer Number , då är Lookup ett bättre alternativ.
Angående Merge Join:
Om du vill utföra kopplingar som att hämta alla adresser (hem, arbete, annat) från Address tabell för en given kund i Customer tabell, då måste du gå med Merge Join eftersom kunden kan ha 1 eller flera adresser kopplade till sig.
Ett exempel att jämföra:
Här är ett scenario för att visa prestandaskillnaderna mellan Merge Join och Lookup . Datan som används här är en en-till-en-koppling, vilket är det enda scenariot som är vanligt mellan dem att jämföra.
-
Jag har tre tabeller som heter
dbo.ItemPriceInfo,dbo.ItemDiscountInfoochdbo.ItemAmount. Skapa skript för dessa tabeller finns under avsnittet SQL-skript. -
Tabeller
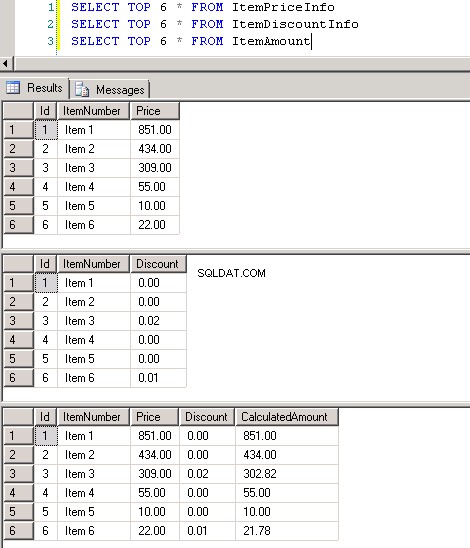
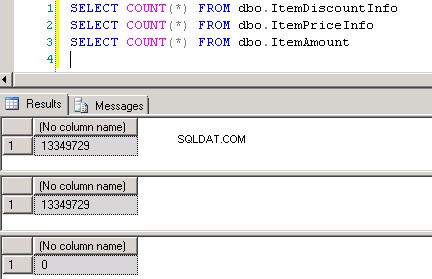
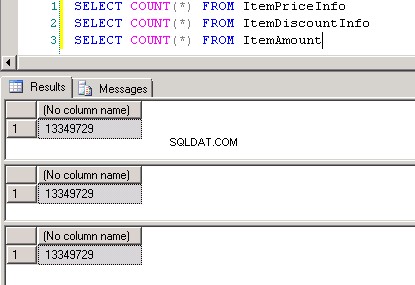
dbo.ItemPriceInfoochdbo.ItemDiscountInfobåda har 13 349 729 rader. Båda tabellerna har ItemNumber som den gemensamma kolumnen. ItemPriceInfo har prisinformation och ItemDiscountInfo har rabattinformation. Skärmbild #2 visar radantalet i var och en av dessa tabeller. Skärmbild #3 visar de sex översta raderna för att ge en uppfattning om data som finns i tabellerna. -
Jag skapade två SSIS-paket för att jämföra prestandan för Merge Join- och Lookup-transformationer. Båda paketen måste ta informationen från tabellerna
dbo.ItemPriceInfoochdbo.ItemDiscountInfo, beräkna det totala beloppet och spara det i tabellendbo.ItemAmount. -
Första paketet som användes
Merge Jointransformation och inuti den använde den INNER JOIN för att kombinera data. Skärmbilder #4 och #5 visa exekveringen av paketet och körtiden. Det tog05minuter14sekunder719millisekunder för att exekvera det Merge Join-transformationsbaserade paketet. -
Andra paketet använde
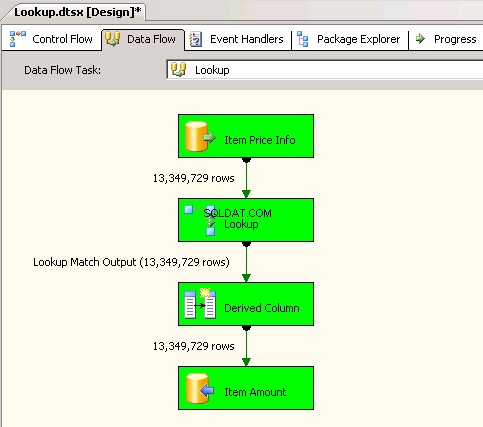
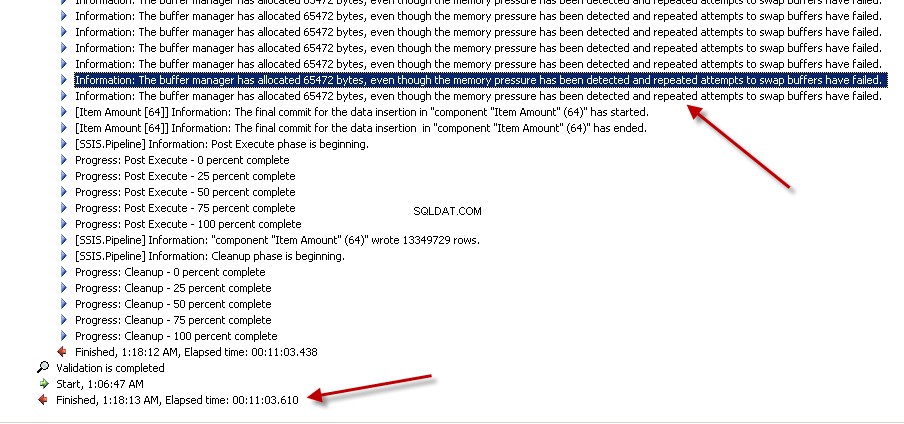
Lookuptransformation med Full cache (vilket är standardinställningen). creenshots #6 och #7 visa exekveringen av paketet och körtiden. Det tog11minuter03sekunder610millisekunder för att exekvera det Lookup-transformationsbaserade paketet. Du kan stöta på varningsmeddelandet Information:The buffer manager has allocated nnnnn bytes, even though the memory pressure has been detected and repeated attempts to swap buffers have failed.Här är en länk som talar om hur man beräknar uppslagscachestorlek. Även om uppgiften för dataflödet slutfördes snabbare under det här paketet tog rensningen av pipeline mycket tid. -
Detta gör det inte mena Lookup transformation är dålig. Det är bara det att det måste användas klokt. Jag använder det ganska ofta i mina projekt men återigen, jag hanterar inte 10+ miljoner rader för uppslag varje dag. Vanligtvis hanterar mina jobb mellan 2 och 3 miljoner rader och för det är prestandan riktigt bra. Upp till 10 miljoner rader, båda presterade lika bra. För det mesta har jag lagt märke till att flaskhalsen visar sig vara destinationskomponenten snarare än transformationerna. Du kan övervinna det genom att ha flera destinationer. Här är ett exempel som visar implementeringen av flera destinationer.
-
Skärmbild #8 visar rekordantalet i alla tre tabellerna. Skärmbild #9 visar topp 6 poster i var och en av tabellerna.
Hoppas det hjälper.
SQL-skript:
CREATE TABLE [dbo].[ItemAmount](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
[CalculatedAmount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemAmount] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemDiscountInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Discount] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemDiscountInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
CREATE TABLE [dbo].[ItemPriceInfo](
[Id] [int] IDENTITY(1,1) NOT NULL,
[ItemNumber] [nvarchar](30) NOT NULL,
[Price] [numeric](18, 2) NOT NULL,
CONSTRAINT [PK_ItemPriceInfo] PRIMARY KEY CLUSTERED ([Id] ASC)) ON [PRIMARY]
GO
Skärmdump #1:

Skärmdump #2:
Skärmdump #3:
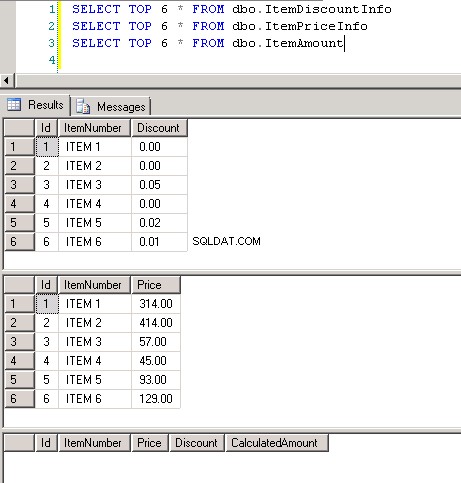
Skärmdump #4:
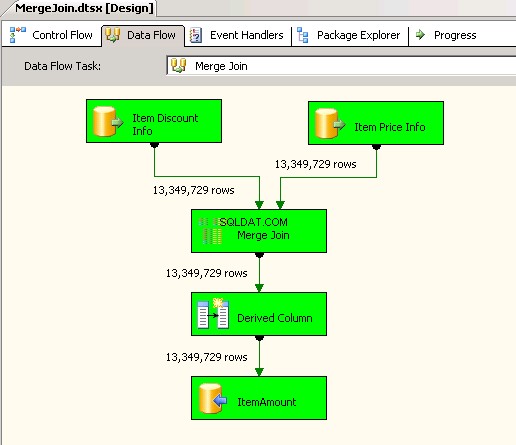
Skärmdump #5:

Skärmdump #6:
Skärmdump #7:
Skärmdump #8:
Skärmdump #9: