Skalbarhet är egenskapen hos ett system för att hantera en växande mängd krav genom att lägga till resurser. Orsakerna till denna mängd krav kan vara tillfälliga, till exempel om du lanserar en rabatt på en rea, eller permanent, för en ökning av kunder eller anställda. I vilket fall som helst bör du kunna lägga till eller ta bort resurser för att hantera dessa förändringar på krav eller ökad trafik.
Det finns olika metoder tillgängliga för att skala din databas. I den här bloggen kommer vi att titta på vad dessa tillvägagångssätt är och hur du skalar din PostgreSQL-databas med Connection Poolers och Load Balancers.
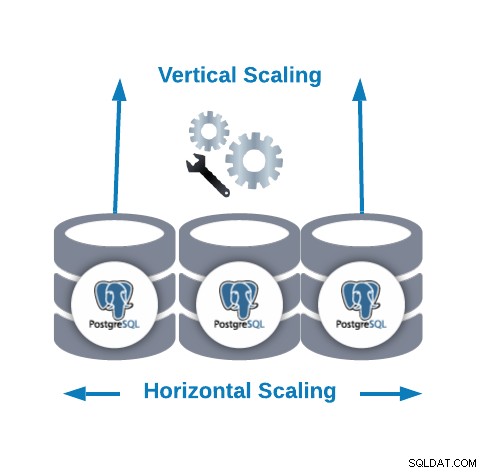
Horisontell och vertikal skalning
Det finns två huvudsakliga sätt att skala din databas.
- Horisontell skalning (utskalning):Det utförs genom att lägga till fler databasnoder som skapar eller ökar ett databaskluster. Det kan hjälpa dig att förbättra läsprestandan och balansera trafiken mellan noderna.
- Vertikal skalning (skala upp):Det utförs genom att lägga till fler hårdvaruresurser (CPU, minne, disk) till en befintlig databasnod. Det kan behövas ändra någon konfigurationsparameter för att tillåta PostgreSQL att använda en ny eller bättre hårdvarururs.
Anslutningspoolare och lastbalanserare
I både horisontell och vertikal skalning kan det vara användbart att lägga till ett externt verktyg för att minska belastningen på din databas vilket kommer att förbättra prestandan. Det kanske inte räcker, men det är en bra utgångspunkt. För detta är det en bra idé att implementera en anslutningspooler och en lastbalanserare. Jag sa "och" eftersom de är designade för olika roller.
En anslutningspoolning är en metod för att skapa en pool av anslutningar och återanvända dem för att undvika att öppna nya anslutningar till databasen hela tiden, vilket kommer att öka prestandan för dina applikationer avsevärt. PgBouncer är en populär anslutningspoolare designad för PostgreSQL.
Att använda en lastbalanserare är ett sätt att ha hög tillgänglighet i din databastopologi och det är också användbart att öka prestandan genom att balansera trafiken mellan de tillgängliga noderna. För detta är HAProxy ett bra alternativ för PostgreSQL, eftersom det är en proxy med öppen källkod som kan användas för att implementera hög tillgänglighet, lastbalansering och proxy för TCP- och HTTP-baserade applikationer.
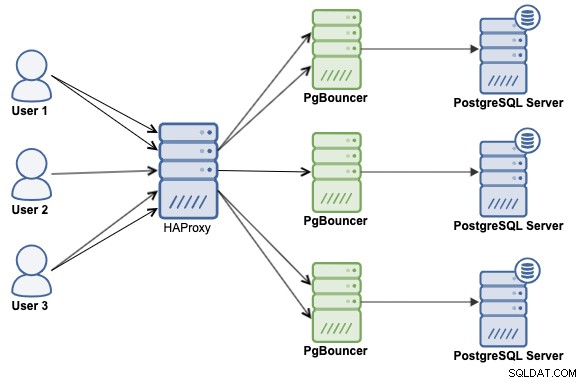
Hur man implementerar en kombination av HAProxy, PgBouncer och PostgreSQL
En kombination av båda teknologierna, HAProxy och PgBouncer, är förmodligen det bästa sättet att skala och förbättra prestanda i din PostgreSQL-miljö. Så vi kommer att se hur man implementerar det med hjälp av följande arkitektur:
Vi antar att du har ClusterControl installerat, om inte kan du gå till den officiella webbplatsen, eller till och med hänvisa till den officiella dokumentationen för att installera den.
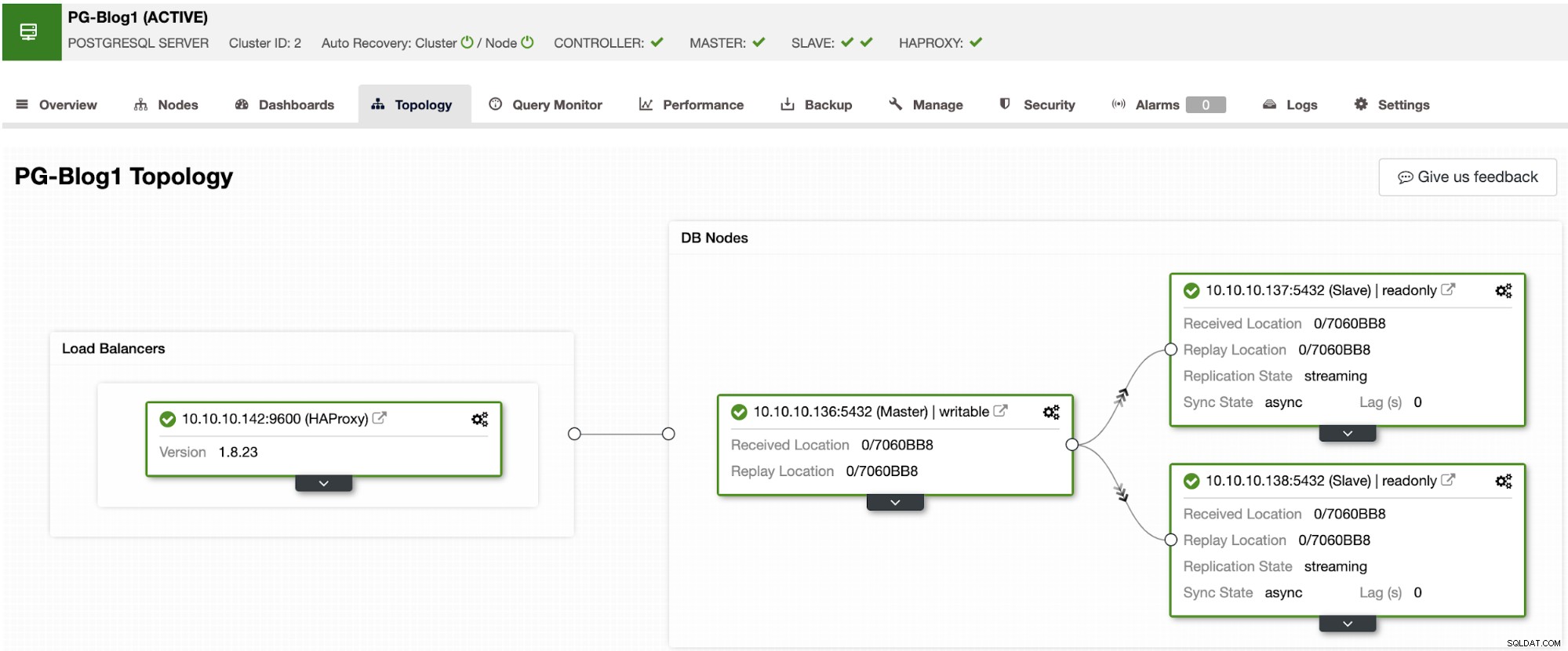
Först måste du distribuera ditt PostgreSQL-kluster med HAProxy framför sig. För detta, följ stegen i det här blogginlägget för att distribuera både PostgreSQL och HAProxy med ClusterControl.
Vid det här laget kommer du att ha något sånt här:
Nu kan du installera PgBouncer på varje databasnod eller på en extern maskin .
För att skaffa PgBouncer-mjukvaran kan du gå till nedladdningssektionen för PgBouncer eller använda RPM- eller DEB-förråden. I det här exemplet kommer vi att använda CentOS 8 och installera det från det officiella PostgreSQL-förrådet.
Hämta först och installera motsvarande arkiv från PostgreSQL-webbplatsen (om du inte har det på plats ännu):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpmInstallera sedan PgBouncer-paketet:
$ yum install pgbouncerNär den är klar kommer du att ha en ny konfigurationsfil i /etc/pgbouncer/pgbouncer.ini. Som standardkonfigurationsfil kan du använda följande exempel:
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbOch autentiseringsfilen:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"Detta är bara ett grundläggande exempel. För att få alla tillgängliga parametrar kan du kontrollera den officiella dokumentationen.
Så, i det här fallet har jag installerat PgBouncer i samma databasnod, lyssnar på alla IP-adresser, och den ansluter till en PostgreSQL-databas som heter "världen". Jag hanterar också de tillåtna användarna i filen userlist.txt med ett lösenord i vanlig text som kan krypteras vid behov.
För att starta PgBouncer-tjänsten behöver du bara köra följande kommando:
$ pgbouncer -d /etc/pgbouncer/pgbouncer.iniKör nu följande kommando med din lokala information (port, värd, användarnamn och databasnamn) för att komma åt PostgreSQL-databasen:
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#Detta är en grundläggande topologi. Du kan förbättra det, till exempel genom att lägga till två eller flera belastningsbalanseringsnoder för att undvika en enda felpunkt och använda något verktyg som "Keepalived", för att säkerställa tillgängligheten. Det kan också göras med ClusterControl.
För mer information om PgBouncer och hur man använder den, kan du se det här blogginlägget.
Slutsats
Om du behöver skala ditt PostgreSQL-kluster är att lägga till HAProxy och PgBouncer ett bra sätt att skala ut och skala upp samtidigt, eftersom du kan lägga till fler heta standby-noder för att balansera trafiken och du kommer att förbättra prestandan genom att återanvända öppnade anslutningar.
ClusterControl tillhandahåller en hel rad funktioner, från övervakning, varning, automatisk failover, säkerhetskopiering, punkt-i-tid återställning, säkerhetskopieringsverifiering, till skalning av läsrepliker. Detta kan hjälpa dig att skala din PostgreSQL-databas på ett horisontellt eller vertikalt sätt från ett vänligt och intuitivt användargränssnitt.