Ämnet cachning dök upp i PostgreSQL så långt tillbaka som för 22 år sedan, och då låg fokus på databastillförlitlighet.
Snabbspola fram till 2020, diskplattorna är gömda ännu djupare i virtualiserade miljöer, hypervisorer och tillhörande lagringsenheter. Dessutom skriker sammankopplade, distribuerade applikationer som arbetar i global skala efter anslutningar med låg latens och plötsligt tuning av servercacher, och SQL-frågor konkurrerar med att säkerställa att resultaten returneras till klienter inom millisekunder. Applikationsnivå och cacher i minnet skapas, och läsfrågor sparas nu nära applikationsservrarna. Som ett resultat reduceras I/O-operationer till att endast skriva och nätverkslatens förbättras dramatiskt. Med en hake. Implementeringar ansvarar för sin egen cachehantering vilket ibland leder till prestandaförsämring.
Caching av skrivningar är en mycket mer komplicerad fråga, som förklaras i PostgreSQL-wikin.
Den här bloggen är en översikt över frågecachar i minnet och belastningsbalanserare som används med PostgreSQL.
PostgreSQL-belastningsbalansering
Idén om lastbalansering togs upp samtidigt som cachelagring, 1999, när Bruce Momjiam skrev:
[...] det är möjligt att vi kan bli _mycket_ populära inom en snar framtid.
Grunden för att implementera lastbalansering i PostgreSQL tillhandahålls av den inbyggda Hot Standby-funktionen. Det enda kravet är att applikationen ska hantera failover och det är här tredjepartslösningar kommer in. Vi kommer att titta på några av dessa lösningar i nästa avsnitt.
Belastningsbalanserade frågor kan bara returnera konsekventa resultat så länge den synkrona replikeringsfördröjningen hålls låg. I praktiken kan till och med toppmodern nätverksinfrastruktur som AWS uppvisa tiotals millisekunders förseningar:
Vi observerar vanligtvis fördröjningstider på tiotals millisekunder. [...] Under typiska förhållanden är replikeringsfördröjning under en minut vanligt. [...]
Repliker över regioner som använder logisk replikering kommer att påverkas av ändrings-/tillämpningshastigheten och förseningar i nätverkskommunikation mellan de specifika regionerna som valts. Repliker över regioner som använder Aurora Global Database kommer att ha en typisk fördröjning på under en sekund.
Som tidigare nämnts förlitar sig tredjepartslösningarna på centrala PostgreSQL-funktioner. Till exempel uppnås lastbalansering av läsfrågor med hjälp av flera synkrona väntelägen.
Lösningar
pgpool-II
pgpool-II är en funktionsrik produkt som ger både belastningsbalansering och cachelagring av frågor i minnet. Det är en drop-in-ersättning, inga ändringar på applikationssidan krävs.
Som belastningsutjämnare undersöker pgpool-II varje SQL-fråga — för att vara belastningsbalanserad måste SELECT-frågor uppfylla flera villkor.
Inställningen kan vara så enkel som en nod, nedan visas ett kluster med dubbla noder:
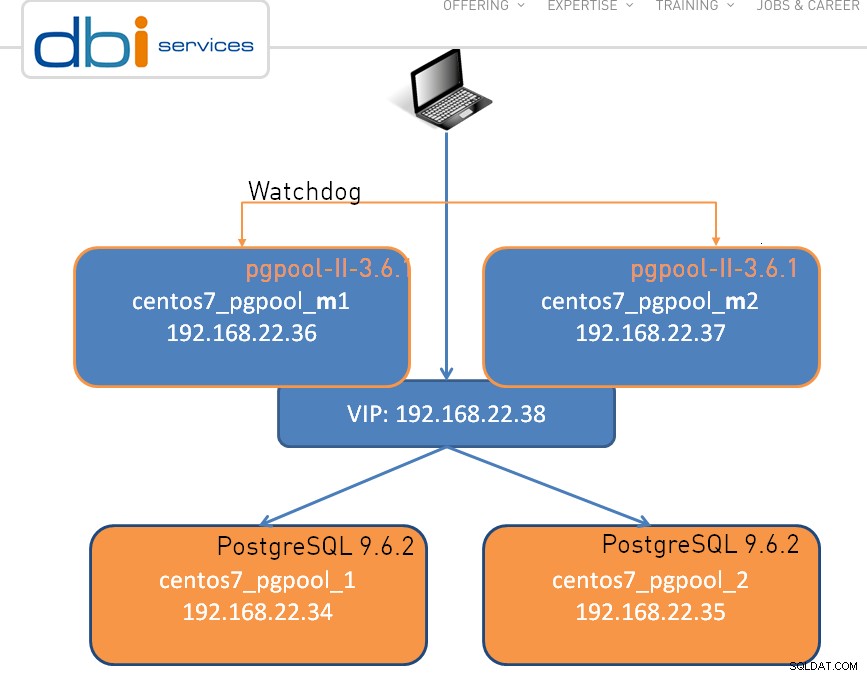
Som det är fallet med vilken bra programvara som helst, finns det vissa begränsningar , och pgpool-II gör inget undantag:
- Den hanterar inte frågor med flera påståenden.
- SELECT-frågor på temporära tabeller kräver /*NO LOAD BALANCE*/ SQL-kommentaren.
Applikationer som körs i högpresterande miljöer kommer att dra nytta av en blandad konfiguration där pgBouncer är anslutningspoolaren och pgpool-II hanterar lastbalansering och cachning. Resultatet är en imponerande 4 gånger genomströmningsökning och 40 procents latensminskning:
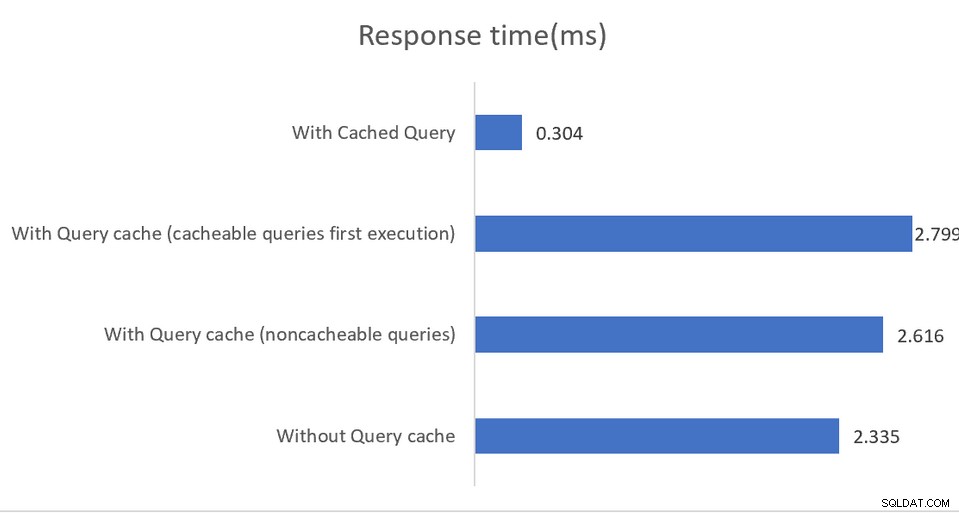
Caching i minnet fungerar, återigen, endast på läsfrågor, med cachad data sparas antingen i det delade minnet eller i en extern memcachad installation. Även om dokumentationen är ganska bra på att förklara de olika konfigurationsalternativen, föreslår den indirekt att implementeringar måste övervaka SHOW POOL CACHE-utdata för att varna om träffförhållanden som faller under 70 %-märket, då prestandavinsten som tillhandahålls av cachning går förlorad.
Bucardo
Bucardo är ett PostgreSQL-replikeringsverktyg skrivet i Perl och PL/Perl.
Jag har nämnt Bucardo, eftersom lastbalansering är en av dess funktioner, enligt PostgreSQL-wikin kommer dock en internetsökning inte upp med några relevanta resultat. För att förtydliga gick jag över till den officiella dokumentationen som går in på detaljerna om hur programvaran faktiskt fungerar:

Det gör det ganska tydligt att Bucardo inte är en lastbalanserare, precis som påpekades av folket på Database Soup.
HAProxy
HAProxy är en allmän lastbalanserare som fungerar på TCP-nivå (för databasanslutningar). Hälsokontroller säkerställer att frågor endast skickas till levande noder.
Jämfört med pgpool-II måste applikationer som använder HAProxy som belastningsutjämnare göras medvetna om förfrågningar om slutpunktsutskick till läsarnoder.
Apache Ignite
Apache Ignite är en cache på andra nivån som förstår ANSI-99 SQL och ger stöd för ACID-transaktioner. Apache Ignite förstår inte PostgreSQL Frontend/Backend Protocol och därför måste applikationer använda antingen ett beständighetslager som Hibernate ORM. Som ett alternativ till att modifiera applikationer tillhandahåller Apache Ignite 'memcached integration'_ som kräver den memcachade PostgreSQL-tillägget. Tyvärr är det senare alternativet inte kompatibelt med de senaste versionerna av PostgreSQL, eftersom pgmemcache-tillägget senast uppdaterades 2017.
Heimdall Data
Som en kommersiell produkt markerar Heimdall Data båda rutorna:lastbalansering och cachning. Det är en mogen produkt, som har visats på PostgreSQL-konferenser så långt tillbaka som PGCon 2017:

Mer information och en produktdemo finns på Azure for PostgreSQL-bloggen .
Slutsats
I dagens distribuerade datoranvändning är Query Caching och Load Balancing lika viktiga för PostgreSQL-prestandajustering som de välkända GUC:erna, OS-kärnan, lagringen och frågeoptimeringen. Medan pgpool-II och Heimdall Data är öppen källkod och de kommersiellt föredragna lösningarna, finns det fall där avsiktligt framställda verktyg kan användas som byggstenar för att uppnå liknande resultat.