Att läsa från minnet kommer alltid att vara mer prestanda än att gå till disk, så för alla databastekniker skulle du vilja använda så mycket minne som möjligt. Om du inte är säker på konfigurationen, eller om du har ett fel, kan detta generera högt minnesanvändning eller till och med ett problem med att minnet är slut.
I den här bloggen kommer vi att titta på hur du kontrollerar din PostgreSQL-minnesanvändning och vilken parameter du bör ta hänsyn till för att justera den. För detta, låt oss börja med att se en översikt över PostgreSQL:s arkitektur.
PostgreSQL-arkitektur
PostgreSQL:s arkitektur är baserad på tre grundläggande delar:processer, minne och disk.
Minnet kan klassificeras i två kategorier:
- Lokalt minne :Den laddas av varje backend-process för egen användning för frågebehandling. Den är indelad i underområden:
- Arbetsminne:Arbetsminnet används för att sortera tuplar efter operationer ORDER BY och DISTINCT, och för att sammanfoga tabeller.
- Underhållsarbete mem:Vissa typer av underhållsoperationer använder detta område. Till exempel, VACUUM, om du inte anger autovacuum_work_mem.
- Temporiska buffertar:Den används för att lagra temporära tabeller.
- Delat minne :Den tilldelas av PostgreSQL-servern när den startas, och den används av alla processer. Den är indelad i underområden:
- Delad buffertpool:Där PostgreSQL laddar sidor med tabeller och index från disken för att arbeta direkt från minnet, vilket minskar diskåtkomsten.
- WAL-buffert:WAL-data är transaktionsloggen i PostgreSQL och innehåller ändringarna i databasen. WAL-buffert är det område där WAL-data lagras tillfälligt innan de skrivs till disken till WAL-filerna. Detta görs varje fördefinierad tid som kallas kontrollpunkt. Detta är mycket viktigt för att undvika förlust av information i händelse av ett serverfel.
- Bekräftelselogg:Den sparar status för alla transaktioner för samtidighetskontroll.
Hur man vet vad som händer
Om du har hög minnesanvändning bör du först bekräfta vilken process som genererar förbrukningen.
Använda "Top" Linux-kommandot
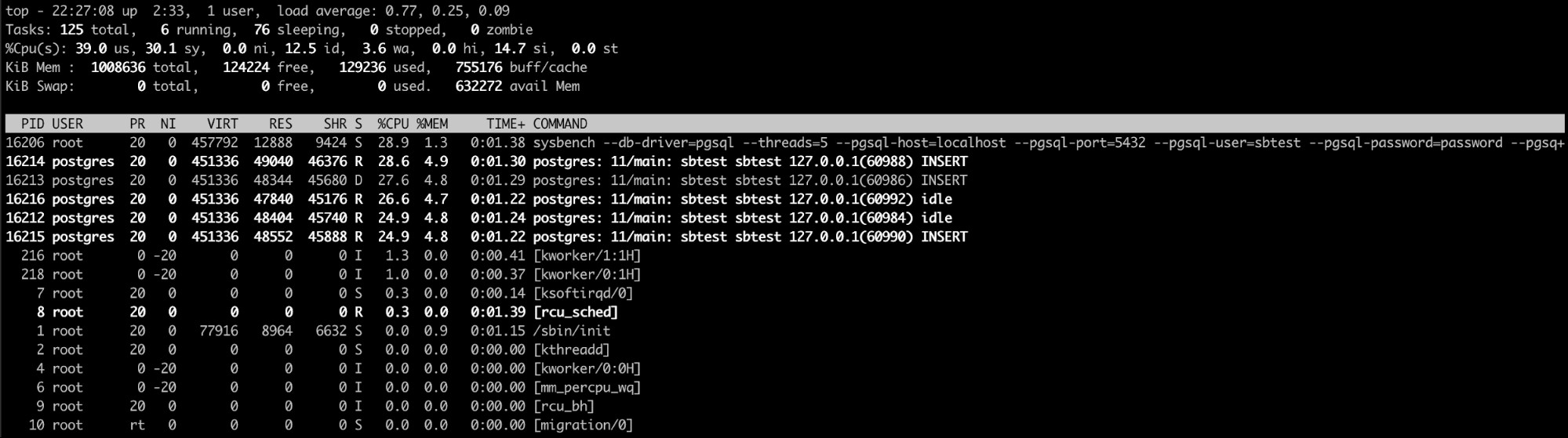
Det översta linuxkommandot är förmodligen det bästa alternativet här (eller till och med ett liknande en som htop). Med detta kommando kan du se processen/processerna som tar för mycket minne.
När du bekräftar att PostgreSQL är ansvarig för det här problemet är nästa steg att kontrollera varför.
Använda PostgreSQL-loggen
Att kontrollera både PostgreSQL- och systemloggarna är definitivt ett bra sätt att få mer information om vad som händer i din databas/ditt system. Du kan se meddelanden som:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childOm du inte har tillräckligt med ledigt minne.
Eller till och med flera databasmeddelandefel som:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedNär du har något oväntat beteende på databassidan. Så loggarna är användbara för att upptäcka den här typen av problem och ännu mer. Du kan automatisera denna övervakning genom att analysera loggfilerna och leta efter verk som "FATAL", "ERROR" eller "Kill", så att du får en varning när det händer.
Använda Pg_top
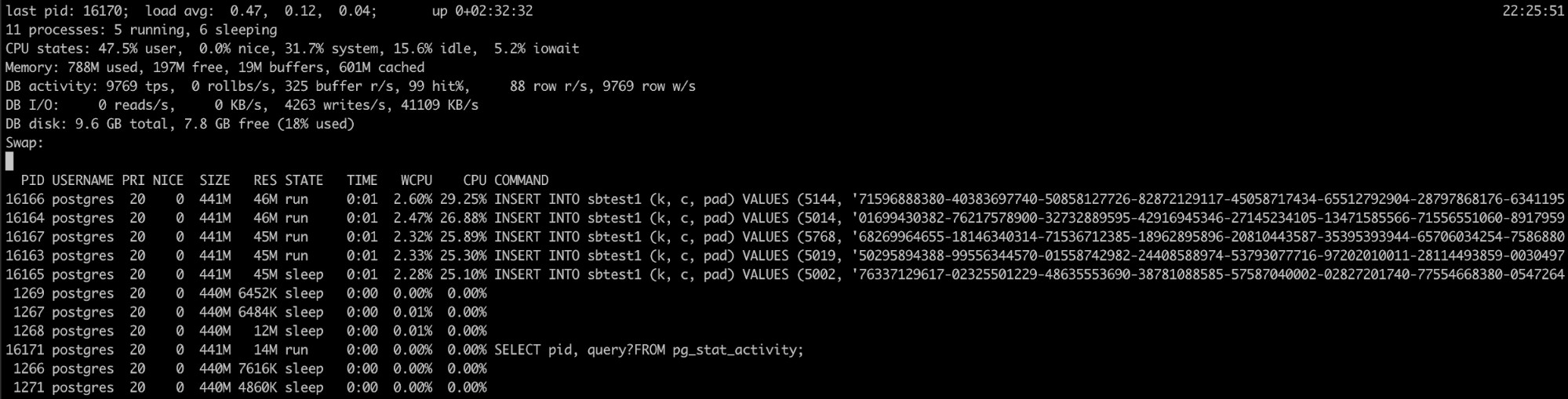
Om du vet att PostgreSQL-processen har hög minnesanvändning, men loggarna hjälpte inte, du har ett annat verktyg som kan vara användbart här, pg_top.
Detta verktyg liknar det översta linuxverktyget, men det är specifikt för PostgreSQL. Så när du använder den kommer du att ha mer detaljerad information om vad som kör din databas, och du kan till och med döda frågor eller köra ett förklara-jobb om du upptäcker något fel. Du kan hitta mer information om detta verktyg här.
Men vad händer om du inte kan upptäcka något fel och databasen fortfarande använder mycket RAM. Så du kommer förmodligen att behöva kontrollera databaskonfigurationen.
Vilka konfigurationsparametrar att ta hänsyn till
Om allt ser bra ut men du fortfarande har problemet med högt utnyttjande bör du kontrollera konfigurationen för att bekräfta om den är korrekt. Så följande är parametrar som du bör ta hänsyn till i det här fallet.
delade_buffertar
Detta är mängden minne som databasservern använder för delade minnesbuffertar. Om det här värdet är för lågt skulle databasen använda mer disk, vilket skulle orsaka mer långsamhet, men om det är för högt kan det generera högt minnesanvändning. Enligt dokumentationen, om du har en dedikerad databasserver med 1 GB eller mer RAM, är ett rimligt startvärde för shared_buffers 25 % av minnet i ditt system.
work_mem
Det specificerar mängden minne som kommer att användas av ORDER BY, DISTINCT och JOIN innan du skriver till de temporära filerna på disken. Precis som med shared_buffers, om vi konfigurerar den här parametern för lågt, kan vi ha fler operationer på disken, men för högt är farligt för minnesanvändningen. Standardvärdet är 4 MB.
max_anslutningar
Work_mem går också hand i hand med max_connections-värdet, eftersom varje anslutning kommer att utföra dessa operationer samtidigt, och varje operation kommer att tillåtas använda så mycket minne som anges av detta värde innan den börjar skriva data i temporära filer. Den här parametern bestämmer det maximala antalet samtidiga anslutningar till vår databas, om vi konfigurerar ett stort antal anslutningar och inte tar hänsyn till detta kan du börja få resursproblem. Standardvärdet är 100.
temp_buffertar
De temporära buffertarna används för att lagra de temporära tabellerna som används i varje session. Denna parameter ställer in den maximala mängden minne för denna uppgift. Standardvärdet är 8 MB.
maintenance_work_mem
Detta är det maximala minnet som en operation som dammsugning, lägga till index eller främmande nycklar kan förbruka. Det som är bra är att endast en operation av denna typ kan köras i en session, och det är inte det vanligaste att man kör flera av dessa samtidigt i systemet. Standardvärdet är 64 MB.
autovacuum_work_mem
Vakuumet använder maintenance_work_mem som standard, men vi kan separera det med den här parametern. Vi kan specificera den maximala mängden minne som ska användas av varje autovakuumarbetare här.
wal_buffertar
Mängden delat minne som används för WAL-data som ännu inte har skrivits till disken. Standardinställningen är 3 % av shared_buffers, men inte mindre än 64 kB eller mer än storleken på ett WAL-segment, vanligtvis 16 MB.
Slutsats
Det finns olika anledningar till att ha en hög minnesanvändning, och att upptäcka rotproblemet kan vara en tidskrävande uppgift. I den här bloggen nämnde vi olika sätt att kontrollera ditt PostgreSQL-minnesanvändning och vilken parameter du bör ta hänsyn till för att ställa in den, för att undvika överdriven minnesanvändning.