När du behöver implementera ett analyssystem för ett företag är det ofta frågan om var data ska lagras. Det finns inte alltid ett perfekt alternativ för alla krav och det beror på budgeten, mängden data och företagets behov.
PostgreSQL, som den mest avancerade databasen med öppen källkod, är så flexibel att den kan fungera som en enkel relationsdatabas, en tidsseriedatabas och till och med som en effektiv, lågkostnadslösning för datalager. Du kan också integrera den med flera analysverktyg.
Om du letar efter ett allmänt kompatibelt, lågkostnads- och prestandalager kan det bästa databasalternativet vara PostgreSQL, men varför? I den här bloggen kommer vi att se vad ett datalager är, varför behövs det och varför PostgreSQL kan vara det bästa alternativet här.
Vad är ett datalager
Ett datalager är ett system av standardiserat, konsekvent och integrerat som innehåller aktuella eller historiska data från en eller flera källor som används för rapportering och dataanalys. Det anses vara en kärnkomponent i business intelligence, vilket är den strategi och teknik som används av ett företag för en bättre förståelse av dess kommersiella sammanhang.
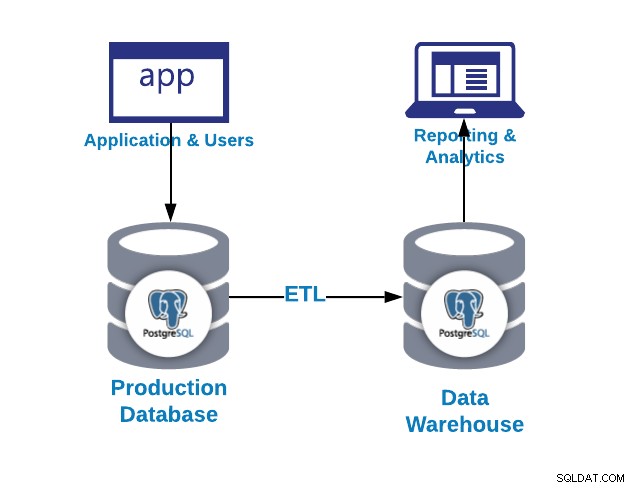
Den första frågan du kan ställa är varför behöver jag ett datalager?
- Integration:Integrera/centralisera data från flera system/databaser
- Standardisera:Standardisera all data i samma format
- Analytik:Analysera data i ett historiskt sammanhang
Några av fördelarna med ett datalager kan vara...
- Integrera data från flera källor i en enda databas
- Undvik produktionslåsning eller belastning på grund av långvariga frågor
- Lagra historisk information
- Omstrukturera data för att passa analyskraven
Som vi kunde se i föregående bild kan vi använda PostgreSQL för både OLAP- och OLTP-förslag. Låt oss se skillnaden.
- OLTP:Transaktionsbearbetning online. I allmänhet har den ett stort antal korta onlinetransaktioner (INSERT, UPDATE, DELETE) genererade av användaraktivitet. Dessa system betonar mycket snabb frågebehandling och bibehållande av dataintegritet i miljöer med flera åtkomster. Här mäts effektiviteten genom antalet transaktioner per sekund. OLTP-databaser innehåller detaljerade och aktuella data.
- OLAP:Analytisk bearbetning online. I allmänhet har den en låg volym av komplexa transaktioner som genereras av stora rapporter. Svarstiden är ett effektivitetsmått. Dessa databaser lagrar aggregerade, historiska data i flerdimensionella scheman. OLAP-databaser används för att analysera flerdimensionell data från flera källor och perspektiv.
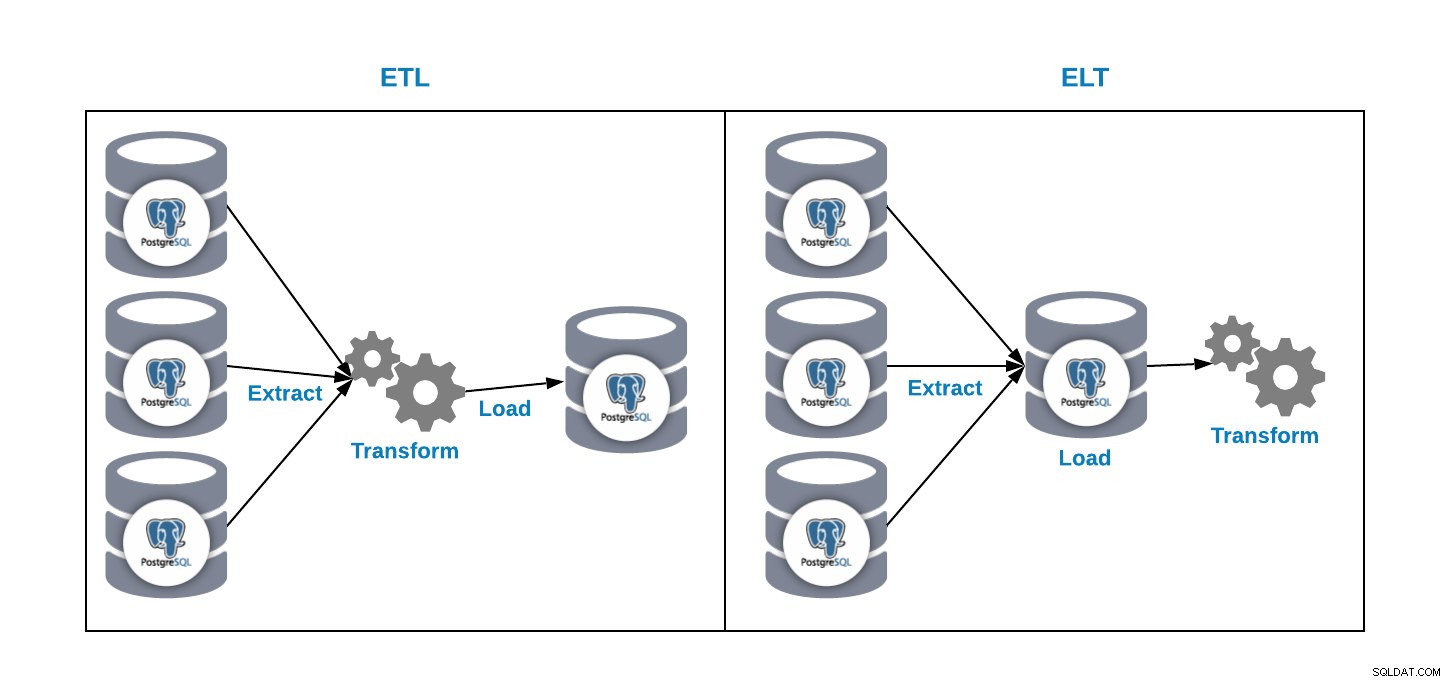
Vi har två sätt att ladda data till vår analysdatabas:
- ETL:Extrahera, transformera och ladda. Detta är sättet att skapa vårt datalager. Extrahera först data från produktionsdatabasen, transformera data enligt våra krav och ladda sedan in data i vårt datalager.
- ELT:Extrahera, ladda och transformera. Extrahera först data från produktionsdatabasen, ladda in den i databasen och transformera sedan data. Det här sättet kallas Data Lake och det är ett nytt koncept för att hantera vår stora data.
Och nu, den andra frågan jag, varför ska jag använda PostgreSQL för mitt datalager?
Fördelar med PostgreSQL som ett datalager
Låt oss titta på några av fördelarna med att använda PostgreSQL som ett datalager...
- Kostnad:Om du använder en lokal miljö blir kostnaden för själva produkten 0 USD, även om du använder någon produkt i molnet, kommer kostnaden för en PostgreSQL-baserad produkt troligen att vara mindre än resten av produkterna.
- Skala:Du kan skala läser den på ett enkelt sätt genom att lägga till så många replikanoder du vill.
- Prestanda:Med en korrekt konfiguration har PostgreSQL en riktigt bra prestanda på olika scenarier.
- Kompatibilitet:Du kan integrera PostgreSQL med externa verktyg eller applikationer för datautvinning, OLAP och rapportering.
- Utökbarhet:PostgreSQL har användardefinierade datatyper och funktioner.
Det finns också några PostgreSQL-funktioner som kan hjälpa oss att hantera vår datalagerinformation...
- Tillfälliga tabeller:Det är en kortlivad tabell som existerar under en databassession. PostgreSQL släpper automatiskt de tillfälliga tabellerna i slutet av en session eller en transaktion.
- Lagrade procedurer:Du kan använda den för att skapa procedurer eller fungera på flera språk (PL/pgSQL, PL/Perl, PL/Python, etc).
- Partitionering:Detta är verkligen användbart för databasunderhåll, frågor med partitionsnyckel och INSERT-prestanda.
- Materialiserad vy:Frågeresultaten visas som en tabell.
- Tabellutrymmen:Du kan ändra dataplatsen till en annan disk. På detta sätt får du parallell diskåtkomst.
- PITR-kompatibel:Du kan skapa säkerhetskopior som är kompatibla med punkt-i-tid-återställning, så i händelse av fel kan du återställa databastillståndet under en viss tidsperiod.
- Enormt community:Och sist men inte minst, PostgreSQL har en enorm community där du kan hitta stöd i många olika frågor.
Konfigurera PostgreSQL för Data Warehouse-användning
Det finns ingen bästa konfiguration att använda i alla fall och i alla databastekniker. Det beror på många faktorer som hårdvara, användning och systemkrav. Nedan finns några tips för att konfigurera din PostgreSQL-databas för att fungera som ett datalager på rätt sätt.
Minnesbaserat
- max_connections:Som en datalagerdatabas behöver du inte en stor mängd anslutningar eftersom detta kommer att användas för rapportering och analysarbete, så du kan begränsa antalet maxanslutningar med den här parametern.
- shared_buffers:Anger mängden minne som databasservern använder för delade minnesbuffertar. Ett rimligt värde kan vara från 15 % till 25 % av RAM-minnet.
- effective_cache_size:Detta värde används av frågeplaneraren för att ta hänsyn till planer som kanske inte får plats i minnet. Detta beaktas i kostnadsuppskattningarna för att använda ett index; ett högt värde gör det mer sannolikt att indexskanningar används och ett lågt värde gör det mer sannolikt att sekventiella skanningar kommer att användas. Ett rimligt värde skulle vara cirka 75 % av RAM-minnet.
- arbetsminne:Anger mängden minne som kommer att användas av de interna operationerna för ORDER BY, DISTINCT, JOIN och hashtabeller innan skrivning till de temporära filerna på disken. När vi konfigurerar detta värde måste vi ta hänsyn till att flera sessioner utför dessa operationer samtidigt och varje operation kommer att tillåtas använda så mycket minne som specificerats av detta värde innan den börjar skriva data i temporära filer. Ett rimligt värde kan vara cirka 2 % av RAM-minnet.
- maintenance_work_mem:Anger den maximala mängden minne som underhållsoperationer kommer att använda, såsom VACUUM, CREATE INDEX och ALTER TABLE ADD FOREIGN KEY. Ett rimligt värde kan vara cirka 15 % av RAM-minnet.
CPU-baserad
- Max_worker_processes:Anger det maximala antalet bakgrundsprocesser som systemet kan stödja. Ett rimligt värde kan vara antalet processorer.
- Max_parallel_workers_per_gather:Ställer in det maximala antalet arbetare som kan startas av en enda Samla eller Samla Merge-nod. Ett rimligt värde kan vara 50 % av antalet CPU.
- Max_parallel_workers:Anger det maximala antalet arbetare som systemet kan stödja för parallella frågor. Ett rimligt värde kan vara antalet processorer.
Eftersom data som laddas in i vårt datalager inte bör ändras, kan vi också ställa in Autovacuum för att undvika en extra belastning på din PostgreSQL-databas. Vakuum- och analysprocesserna kan vara en del av batchladdningsprocessen.
Slutsats
Om du letar efter allmänt kompatibel, låg kostnad och högpresterande datalager bör du definitivt överväga PostgreSQL som ett alternativ för din datalagerdatabas. PostgreSQL har många fördelar och funktioner användbara för att hantera vårt datalager som partitionering eller lagrade procedurer och ännu mer.