I den här tredje delen av Benchmarking Managed PostgreSQL Cloud Solutions , drog jag fördel av Googles gratisnivåerbjudande för GCP. Det har varit en givande upplevelse och som systemadministratör som spenderar större delen av sin tid vid konsolen kunde jag inte missa möjligheten att testa cloud shell, en av konsolfunktionerna som skiljer Google från molnleverantören jag är mer bekant med , Amazon Web Services.
För att snabbt sammanfatta tittade jag i del 1 på de tillgängliga benchmarkverktygen och förklarade varför jag valde AWS Benchmark Procedure för Aurora. Jag jämförde även Amazon Aurora för PostgreSQL version 10.6. I del 2 granskade jag AWS RDS för PostgreSQL version 11.1.
Under denna omgång kommer testerna baserade på AWS Benchmark Procedure för Aurora att köras mot Google Cloud SQL för PostgreSQL 9.6 eftersom version 11.1 fortfarande är i beta.
Molninstanser
Förutsättningar
Som nämnts i de två föregående artiklarna valde jag att lämna PostgreSQL-inställningarna på deras moln GUC-standarder, om de inte hindrar tester från att köras (se längre ner nedan). Minns från tidigare artiklar att antagandet har varit att molnleverantören direkt borde ha databasinstansen konfigurerad för att ge en rimlig prestanda.
AWS pgbench timing patch för PostgreSQL 9.6.5 tillämpades rent på Google Cloud-versionen av PostgreSQL 9.6.10.
Med hjälp av informationen som Google lade ut i sin blogg Google Cloud for AWS Professionals matchade jag specifikationerna för klienten och målinstanserna med avseende på komponenterna Compute, Storage och Networking. Till exempel uppnås Google Cloud-motsvarigheten till AWS Enhanced Networking genom att dimensionera beräkningsnoden baserat på formeln:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)När det gäller att ställa in måldatabasinstansen, på samma sätt som AWS, tillåter Google Cloud inga repliker, men lagringen är krypterad i vila och det finns inget alternativ att inaktivera den.
Slutligen, för att uppnå bästa nätverksprestanda måste klienten och målinstanserna vara placerade i samma tillgänglighetszon.
Kund
Klientinstansspecifikationerna som matchar den närmaste AWS-instansen är:
- vCPU:32 (16 kärnor x 2 trådar/kärna)
- RAM:208 GiB (maximalt för 32 vCPU-instansen)
- Lagring:Compute Engine persistent disk
- Nätverk:16 Gbps (max [32 vCPUs x 2 Gbps/vCPU] och 16 Gbps)
Instansdetaljer efter initiering:
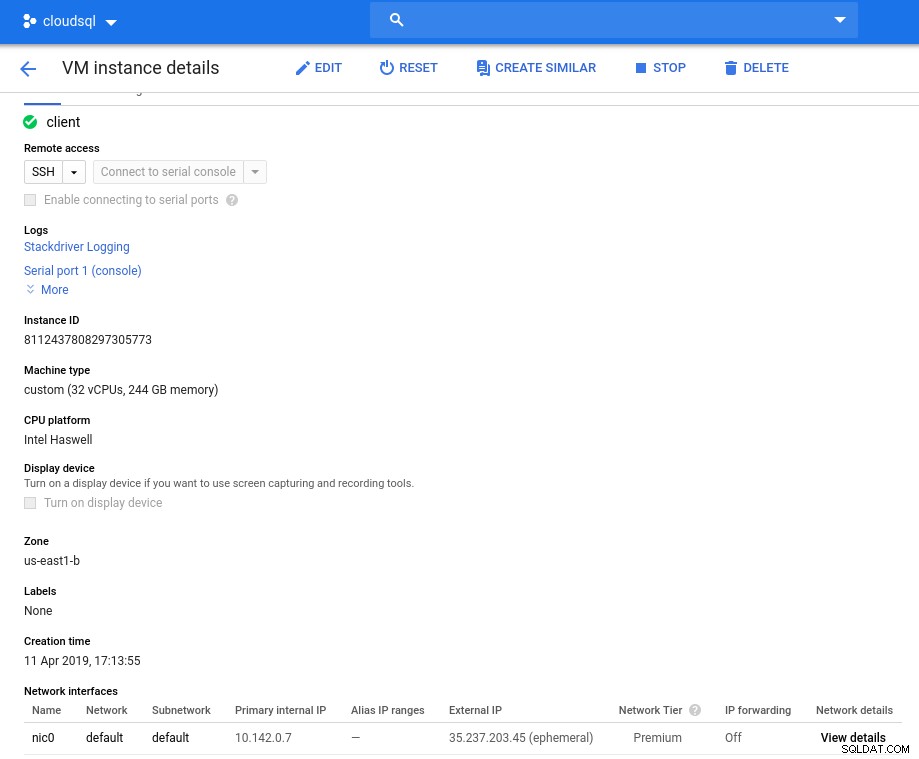 Klientinstans:Compute and Network
Klientinstans:Compute and Network Obs! Instanser är som standard begränsade till 24 vCPU:er. Googles tekniska support måste godkänna kvotökningen till 32 vCPU:er per instans.

Även om sådana förfrågningar vanligtvis hanteras inom två arbetsdagar, måste jag ge Googles supporttjänster en tumme upp för att jag slutförde min förfrågan på bara två timmar.
För den nyfikna är formeln för nätverkshastighet baserad på beräkningsmotordokumentationen som refereras till i den här GCP-bloggen.
DB-kluster
Nedan är databasinstansspecifikationerna:
- vCPU:8
- RAM:52 GiB (max)
- Lagring:144 MB/s, 9 000 IOPS
- Nätverk:2 000 MB/s
Observera att det maximala tillgängliga minnet för en 8 vCPU-instans är 52 GiB. Mer minne kan tilldelas genom att välja en större instans (fler vCPU:er):
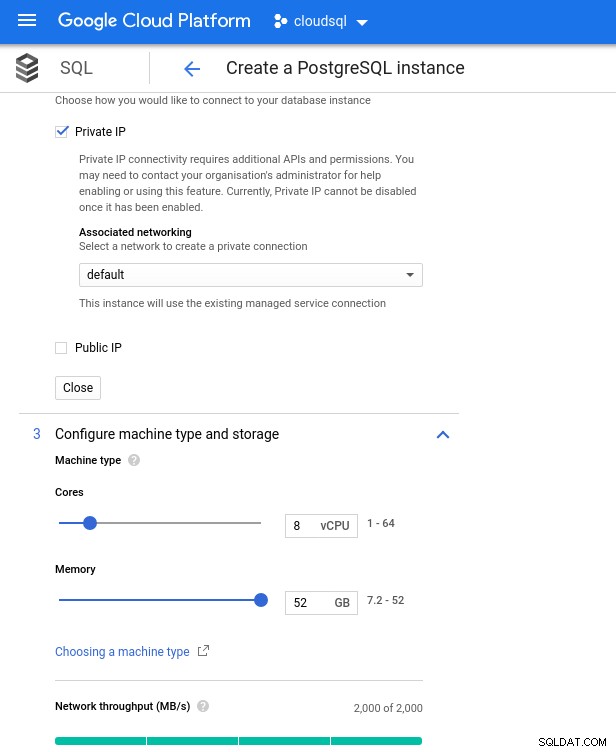 Databas CPU och minnesstorlek
Databas CPU och minnesstorlek Medan Google SQL automatiskt kan utöka den underliggande lagringen, vilket för övrigt är en riktigt cool funktion, valde jag att inaktivera alternativet för att vara konsekvent med AWS-funktionsuppsättningen och undvika en potentiell I/O-påverkan under storleksändringsoperationen. ("potential", eftersom det inte borde ha någon negativ inverkan alls, men enligt min erfarenhet ökar storleken på någon typ av underliggande lagring I/O, även om det är för några sekunder).
Kom ihåg att AWS-databasinstansen säkerhetskopierades av en optimerad EBS-lagring som gav maximalt:
- 1 700 Mbps bandbredd
- 212,5 MB/s genomströmning
- 12 000 IOPS
Med Google Cloud uppnår vi en liknande konfiguration genom att justera antalet vCPU:er (se ovan) och lagringskapacitet:
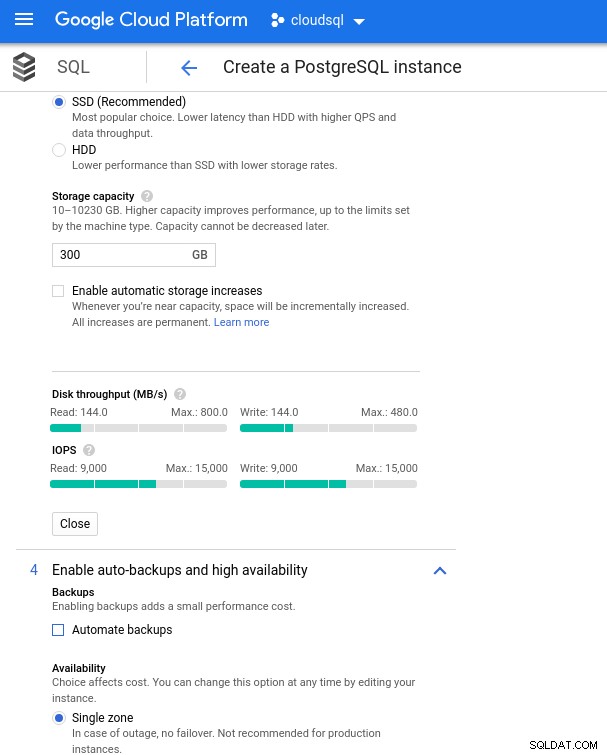 Inställningar för databaslagring och säkerhetskopiering
Inställningar för databaslagring och säkerhetskopiering Köra benchmarks
Inställningar
Installera sedan benchmark-verktygen, pgbench och sysbench genom att följa instruktionerna i Amazon-guiden anpassad till PostgreSQL version 9.6.10.
Initiera PostgreSQL-miljövariablerna i .bashrc och ställ in sökvägarna till PostgreSQL-binärer och bibliotek:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libPreflight checklista:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)Och vi är redo för start:
pgbench
Initiera pgbench-databasen.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…och flera minuter senare:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Som vi nu är vana vid måste databasstorleken vara 160GB. Låt oss verifiera att:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)När alla förberedelser är klara, starta läs-/skrivtestet:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionshoppsan! Vad är maxvärdet?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Så medan AWS ställer in ett tillräckligt stort antal max_connections eftersom jag inte stötte på det problemet, kräver Google Cloud en liten justering...Tillbaka till molnkonsolen, uppdatera databasparametern, vänta några minuter och kontrollera sedan:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Om du startar om testet verkar allt fungera bra:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...men det finns en annan hake. Jag fick en överraskning när jag försökte öppna en ny psql-session för att räkna antalet anslutningar:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsKan det vara så att superuser_reserved_connections inte är standard?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Det är standard, vad kan det annars vara?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! En annan bump av max_connections tar hand om det, dock krävde det att jag startade om pgbench-testet. Och det är folks historien bakom den uppenbara dubblettkörningen i graferna nedan.
Och slutligen, resultaten finns i:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sysbench
Fyll i databasen:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareUtdata:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...Och kör nu testet:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runOch resultatet:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Riktvärde
PostgreSQL-pluginet för Stackdriver har fasats ut den 28 februari 2019. Även om Google rekommenderar Blue Medora, valde jag för den här artikeln att avskaffa att skapa ett konto och förlita mig på tillgängliga Stackdriver-statistik.
- CPU-användning:
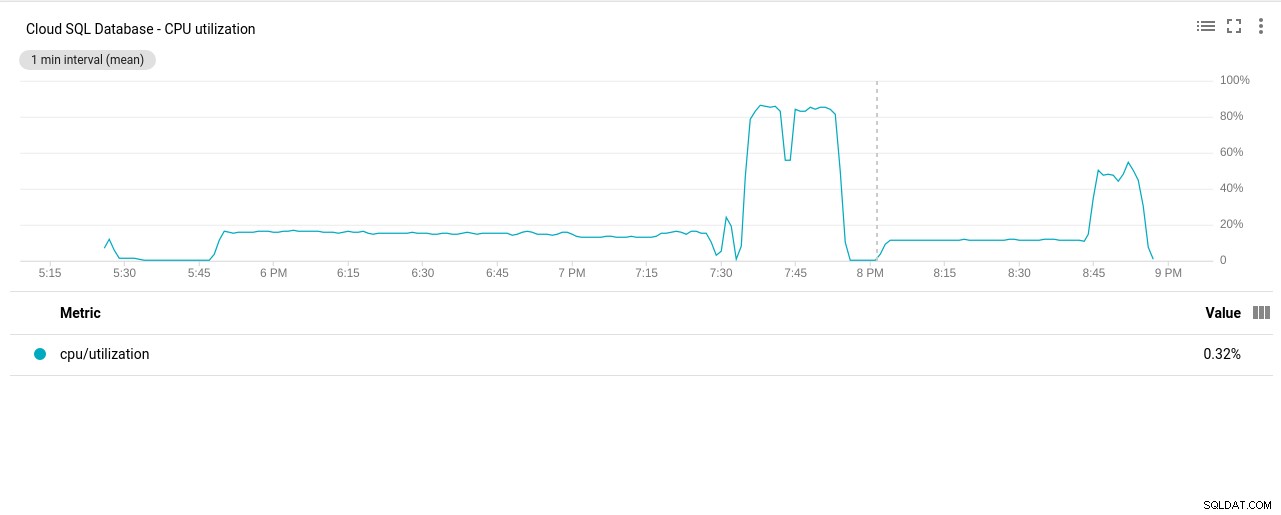 Fotoförfattare Google Cloud SQL:PostgreSQL CPU-användning
Fotoförfattare Google Cloud SQL:PostgreSQL CPU-användning - Läs-/skrivfunktioner för disk:
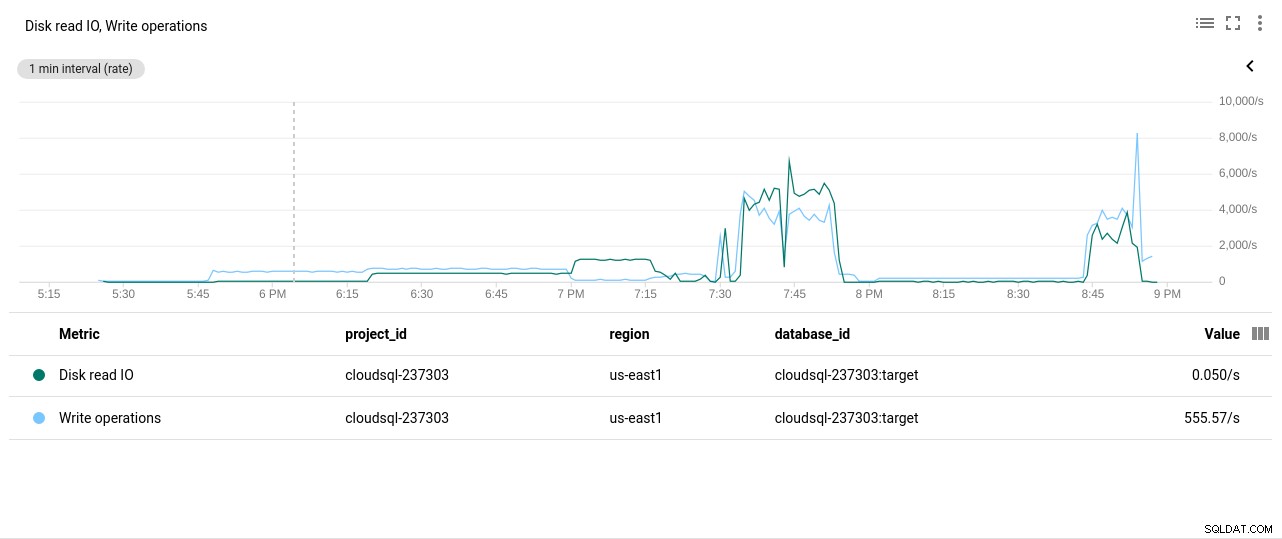 Fotoförfattare Google Cloud SQL:PostgreSQL Disk Read/Write operationer
Fotoförfattare Google Cloud SQL:PostgreSQL Disk Read/Write operationer - Sända/mottagna nätverksbytes:
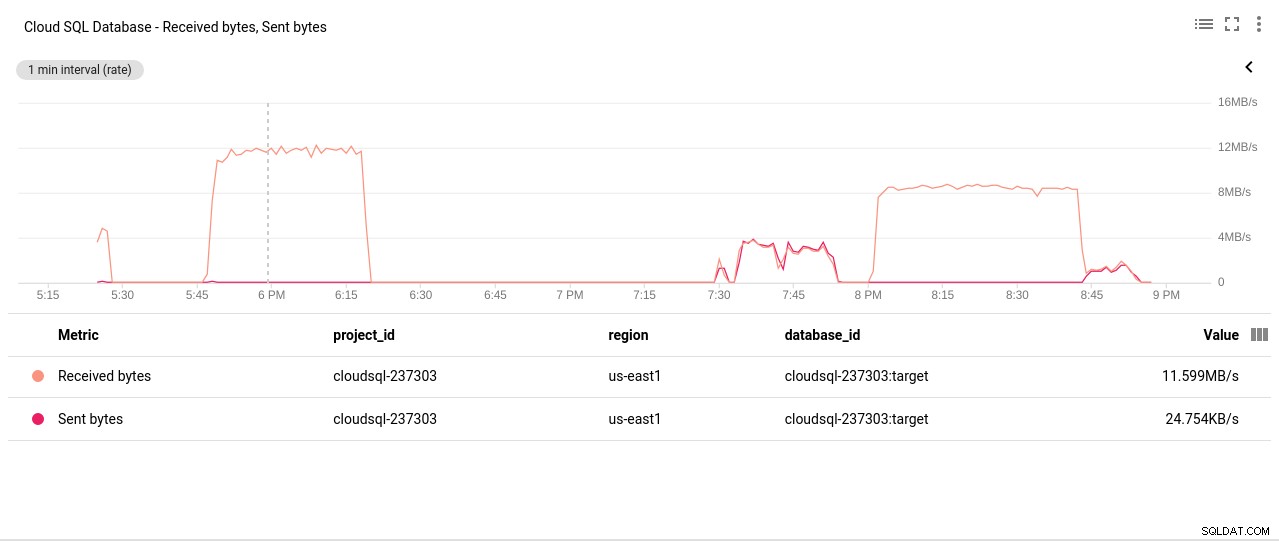 Fotoförfattare Google Cloud SQL:PostgreSQL Network Sent/Received bytes
Fotoförfattare Google Cloud SQL:PostgreSQL Network Sent/Received bytes - Antal PostgreSQL-anslutningar:
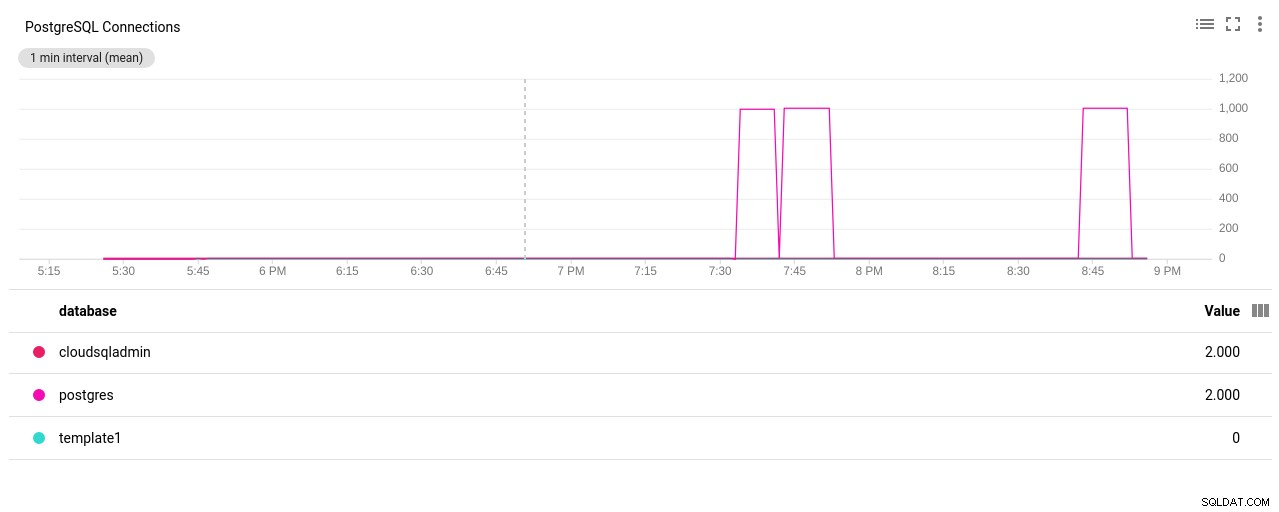 Fotoförfattare Google Cloud SQL:Antal PostgreSQL-anslutningar
Fotoförfattare Google Cloud SQL:Antal PostgreSQL-anslutningar
Benchmark-resultat
pgbench-initiering
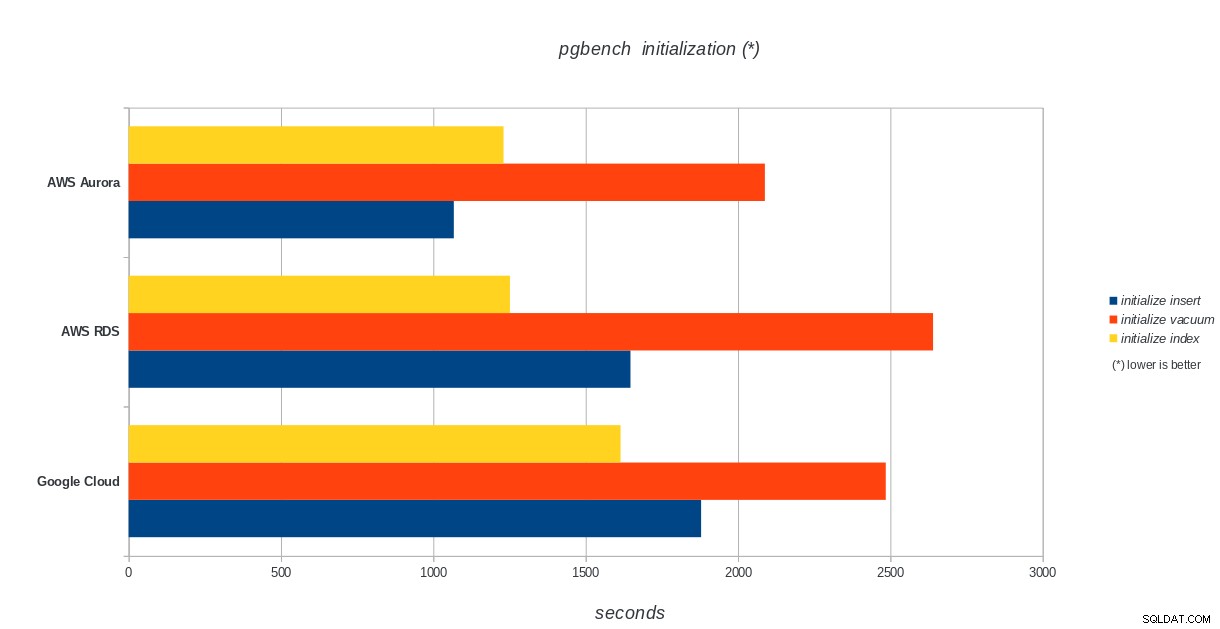 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench-initieringsresultat
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench-initieringsresultat pgbench run
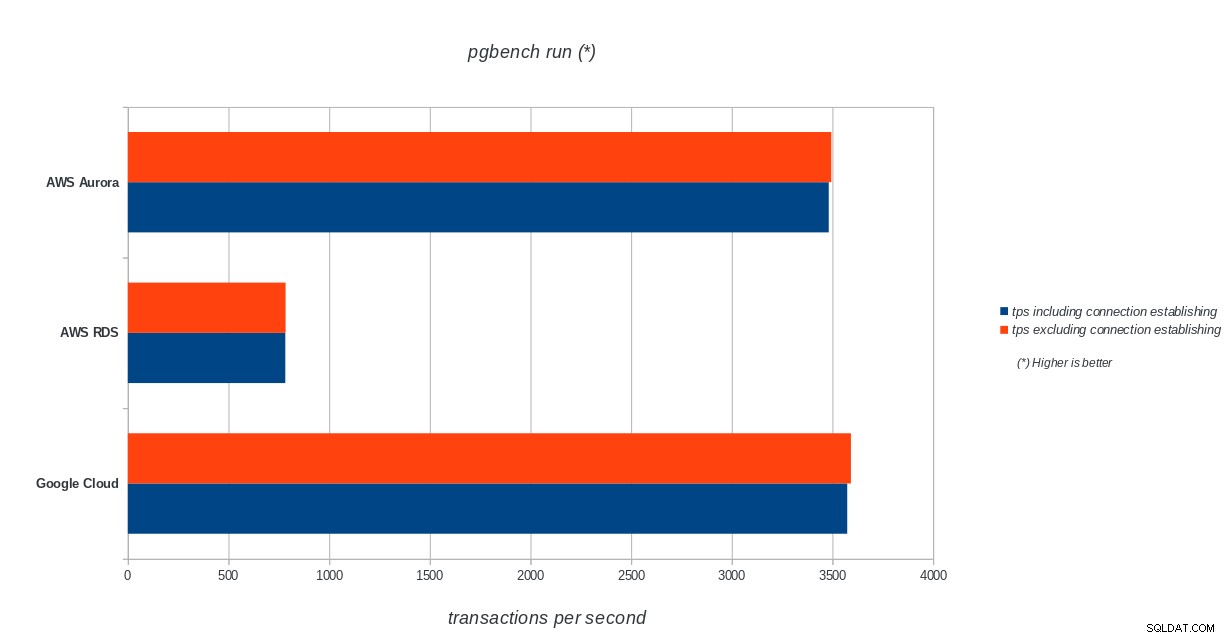 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench run resultat
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL pgbench run resultat sysbench
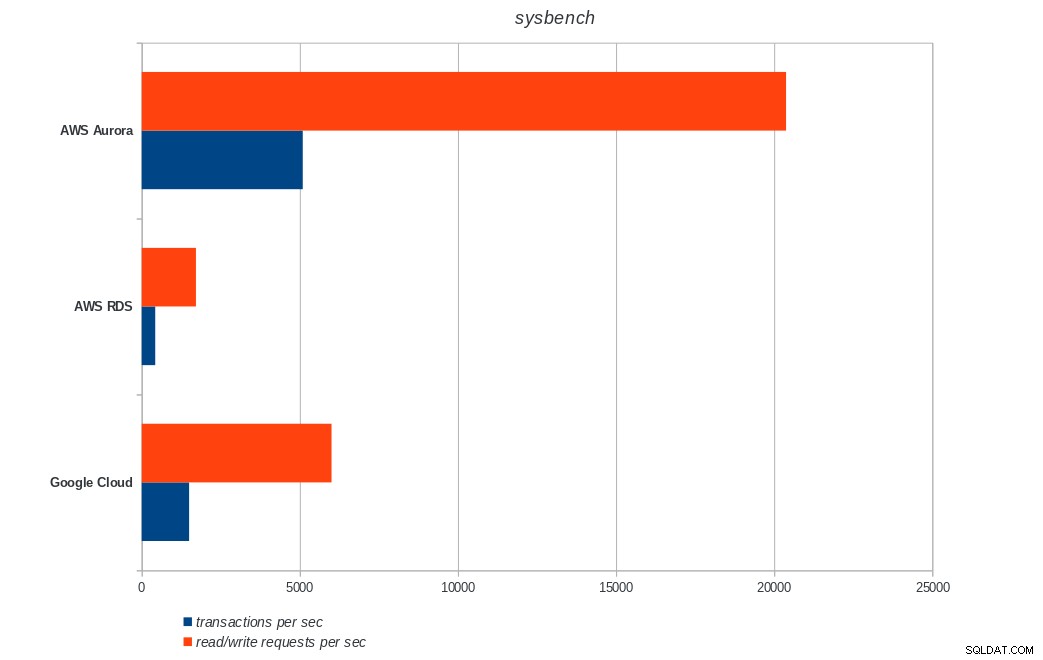 AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench resultat
AWS Aurora, AWS RDS, Google Cloud SQL:PostgreSQL sysbench resultat Slutsats
Amazon Aurora kommer överlägset först i skrivtunga (sysbench) tester, samtidigt som de är i paritet med Google Cloud SQL i pgbench läs/skrivtester. Lasttestet (pgbench-initiering) sätter Google Cloud SQL i första hand, följt av Amazon RDS. Baserat på en översiktlig titt på prismodellerna för AWS Aurora och Google Cloud SQL, skulle jag riskera att säga att Google Cloud är ett bättre val för den genomsnittliga användaren, medan AWS Aurora är bättre lämpad för högpresterande miljöer. Mer analys kommer att följa efter att alla riktmärken har slutförts.
Nästa och sista del av denna benchmark-serie kommer att vara på Microsoft Azure PostgreSQL.
Tack för att du läser och kommentera nedan om du har feedback.