Ett av de primära kraven för en databas är att uppnå skalbarhet. Det kan bara uppnås om konflikten (låsningen) minimeras så mycket som möjligt, om den inte tas bort tillsammans. Eftersom läs/skriv/uppdatera/ta bort är några av de vanligaste operationerna som sker i databasen så är det mycket viktigt att dessa operationer fortsätter samtidigt utan att blockeras. För att uppnå detta använder de flesta av de stora databaserna en samtidighetsmodell som kallas Multi-Version Concurrency Control, vilket reducerar tvister till en absolut miniminivå.
Vad är MVCC
Multi Version Concurrency Control (här och framåt MVCC) är en algoritm för att ge fin samtidighetskontroll genom att bibehålla flera versioner av samma objekt så att LÄS- och SKRIV-operationerna inte kommer i konflikt. Här betyder SKRIV UPPDATERA och DELETE, eftersom nyinlagd post ändå kommer att skyddas enligt isoleringsnivå. Varje WRITE-operation producerar en ny version av objektet och varje samtidig läsoperation läser en annan version av objektet beroende på isoleringsnivån. Eftersom både läs och skriv fungerar på olika versioner av samma objekt så krävs ingen av dessa operationer för att helt låsa och därmed båda kan fungera samtidigt. Det enda fallet där tvisten fortfarande kan existera är när två samtidiga transaktioner försöker SKRIVA samma post.
De flesta av den nuvarande stora databasen stöder MVCC. Avsikten med denna algoritm är att underhålla flera versioner av samma objekt så implementeringen av MVCC skiljer sig från databas till databas endast när det gäller hur flera versioner skapas och underhålls. Följaktligen ändras motsvarande databasdrift och lagring av data.
Mest erkänd metod för att implementera MVCC är den som används av PostgreSQL och Firebird/Interbase och en annan används av InnoDB och Oracle. I efterföljande avsnitt kommer vi att diskutera i detalj hur det har implementerats i PostgreSQL och InnoDB.
MVCC i PostgreSQL
För att stödja flera versioner underhåller PostgreSQL ytterligare fält för varje objekt (Tuple i PostgreSQL-terminologi) enligt nedan:
- xmin – Transaktions-ID för transaktionen som infogade eller uppdaterade tupeln. I händelse av UPPDATERING tilldelas en nyare version av tuplen detta transaktions-ID.
- xmax – Transaktions-ID för transaktionen som tog bort eller uppdaterade tupeln. I händelse av UPPDATERING tilldelas en för närvarande befintlig version av tuple detta transaktions-ID. På en nyskapad tuppel är standardvärdet för detta fält null.
PostgreSQL lagrar all data i ett primärt minne som heter HEAP (sidan är som standardstorlek 8KB). Alla nya tuple får xmin som en transaktion som skapade den och och äldre version tuple (som har uppdaterats eller raderats) tilldelas xmax. Det finns alltid en länk från den äldre versionen till den nya versionen. Den äldre versionen tuple kan användas för att återskapa tuplen i händelse av rollback och för att läsa en äldre version av en tuple by READ-sats beroende på isoleringsnivån.
Tänk på att det finns två tuplar, T1 (med värde 1) och T2 (med värde 2) för en tabell, skapandet av nya rader kan demonstreras i nedanstående 3 steg:
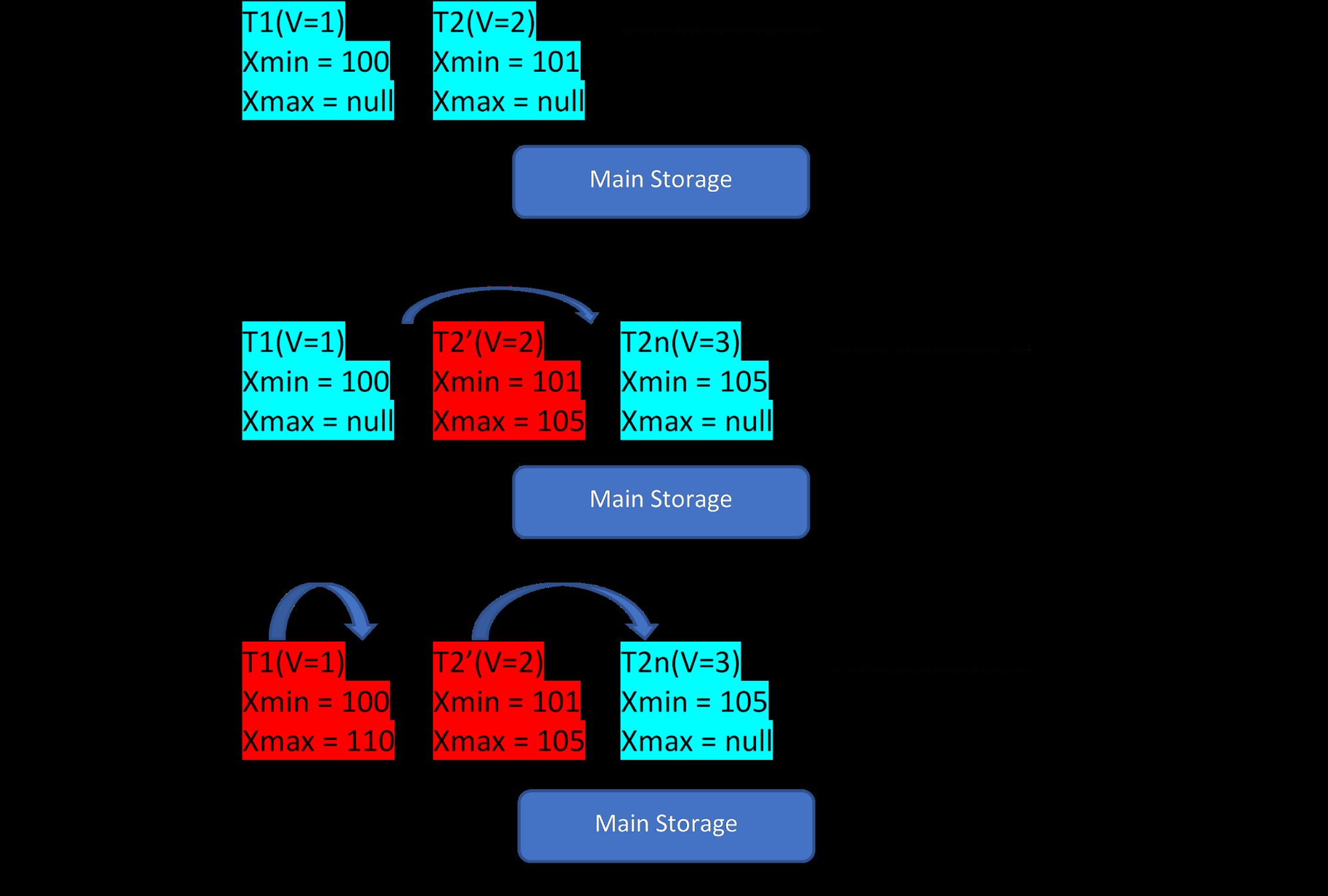 MVCC:Lagring av flera versioner i PostgreSQL
MVCC:Lagring av flera versioner i PostgreSQL Som framgår av bilden finns det initialt två tuplar i databasen med värdena 1 och 2.
Sedan, i ett andra steg, uppdateras raden T2 med värde 2 med värdet 3. Vid denna tidpunkt skapas en ny version med det nya värdet och den lagras bara bredvid den befintliga tupeln i samma lagringsområde . Innan dess tilldelas den äldre versionen xmax och pekar på senaste versionen tuple.
På liknande sätt, i det tredje steget, när raden T1 med värde 1 raderas, raderas den befintliga raden praktiskt taget (dvs. den har precis tilldelats xmax med den aktuella transaktionen) på samma plats. Ingen ny version skapas för detta.
Låt oss sedan se hur varje operation skapar flera versioner och hur transaktionsisoleringsnivån bibehålls utan att låsa med några verkliga exempel. I alla exemplen nedan används som standard "READ COMMITTED" isolering.
INSTÄLL
Varje gång en post infogas kommer den att skapa en ny tupel, som läggs till på en av sidorna som hör till motsvarande tabell.
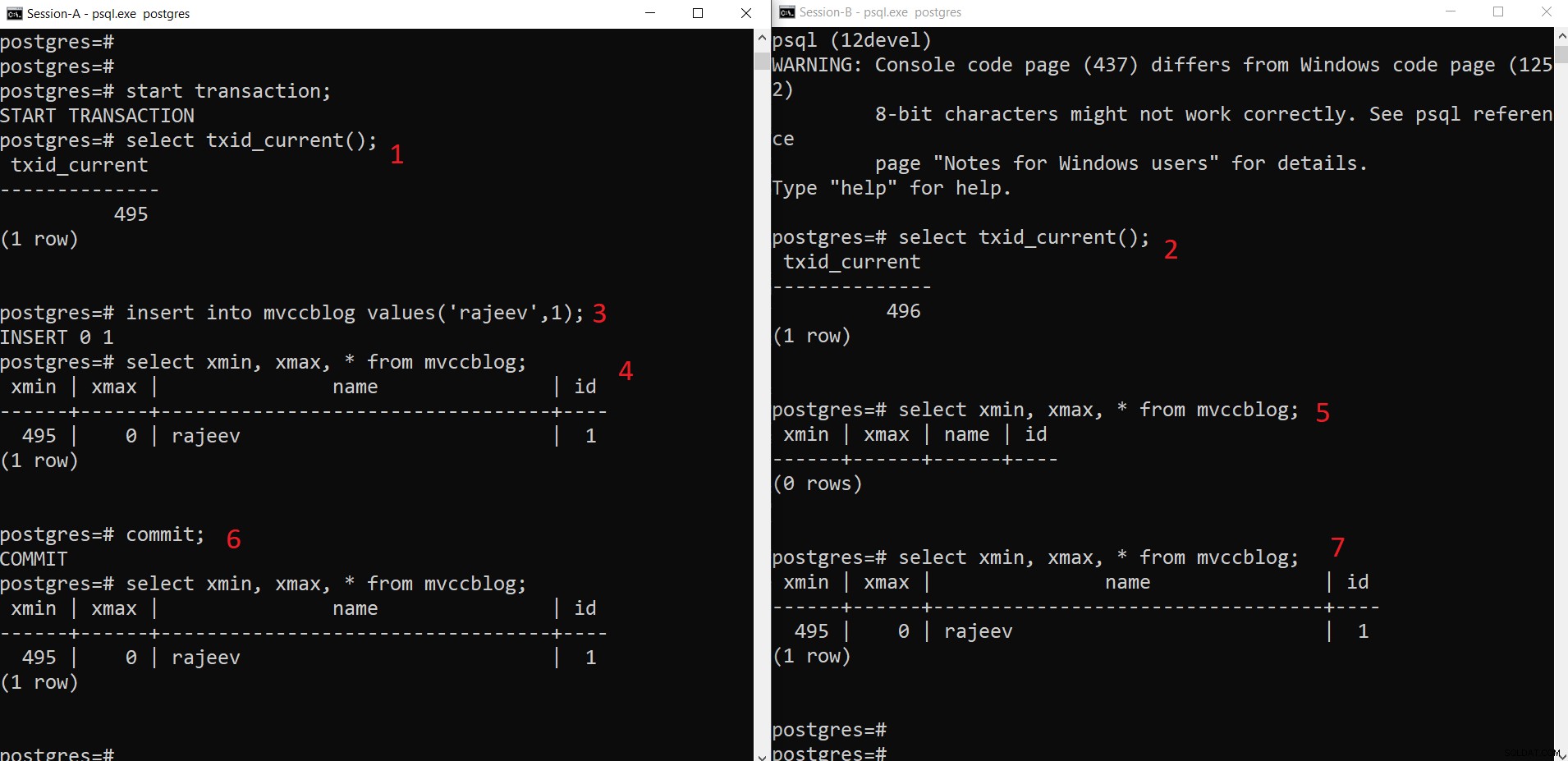 PostgreSQL samtidig INSERT-operation
PostgreSQL samtidig INSERT-operation Som vi kan se här stegvis:
- Session-A startar en transaktion och får transaktions-ID 495.
- Session-B startar en transaktion och får transaktions-ID 496.
- Session-A infoga en ny tuppel (lagras i HEAP)
- Nu läggs den nya tuplen med xmin in på nuvarande transaktions-ID 495.
- Men samma är inte synligt från Session-B som xmin (dvs. 495) fortfarande inte har begåtts.
- När du har begått.
- Data är synlig för båda sessionerna.
UPPDATERA
PostgreSQL UPDATE är inte "IN-PLACE"-uppdatering, dvs den ändrar inte det befintliga objektet med det nya värdet som krävs. Istället skapar den en ny version av objektet. Så UPPDATERING omfattar i stort sett stegen nedan:
- Det markerar det aktuella objektet som borttaget.
- Då lägger den till en ny version av objektet.
- Omdirigera den äldre versionen av objektet till en ny version.
Så även om ett antal poster förblir desamma tar HEAP plats som om ytterligare en post infogats.
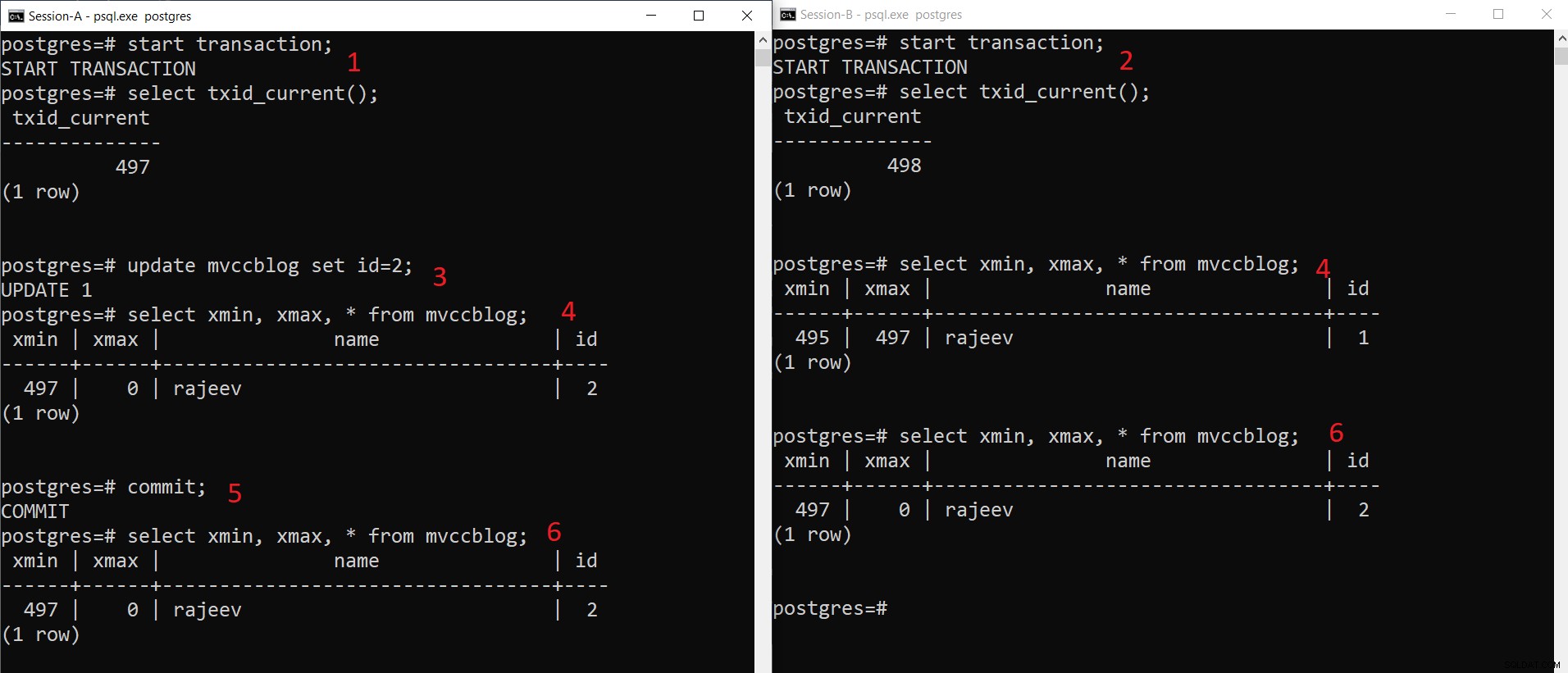 PostgreSQL samtidig INSERT-operation
PostgreSQL samtidig INSERT-operation Som vi kan se här stegvis:
- Session-A startar en transaktion och får transaktions-ID 497.
- Session-B startar en transaktion och får transaktions-ID 498.
- Session-A uppdaterar den befintliga posten.
- Här ser Session-A en version av tuppeln (uppdaterad tuppel) medan Session-B ser en annan version (äldre tuppel men xmax satt till 497). Båda tupelversionerna lagras i HEAP-lagringen (även på samma sida beroende på tillgängligt utrymme)
- När Session-A genomför transaktionen, förfaller den äldre tuppeln eftersom xmax av den äldre tuppeln har begåtts.
- Nu ser båda sessionerna samma version av posten.
RADERA
Ta bort är nästan som UPDATE-operationen förutom att det inte behöver lägga till en ny version. Det markerar bara det aktuella objektet som RADERAT som förklarat i UPDATE-fallet.
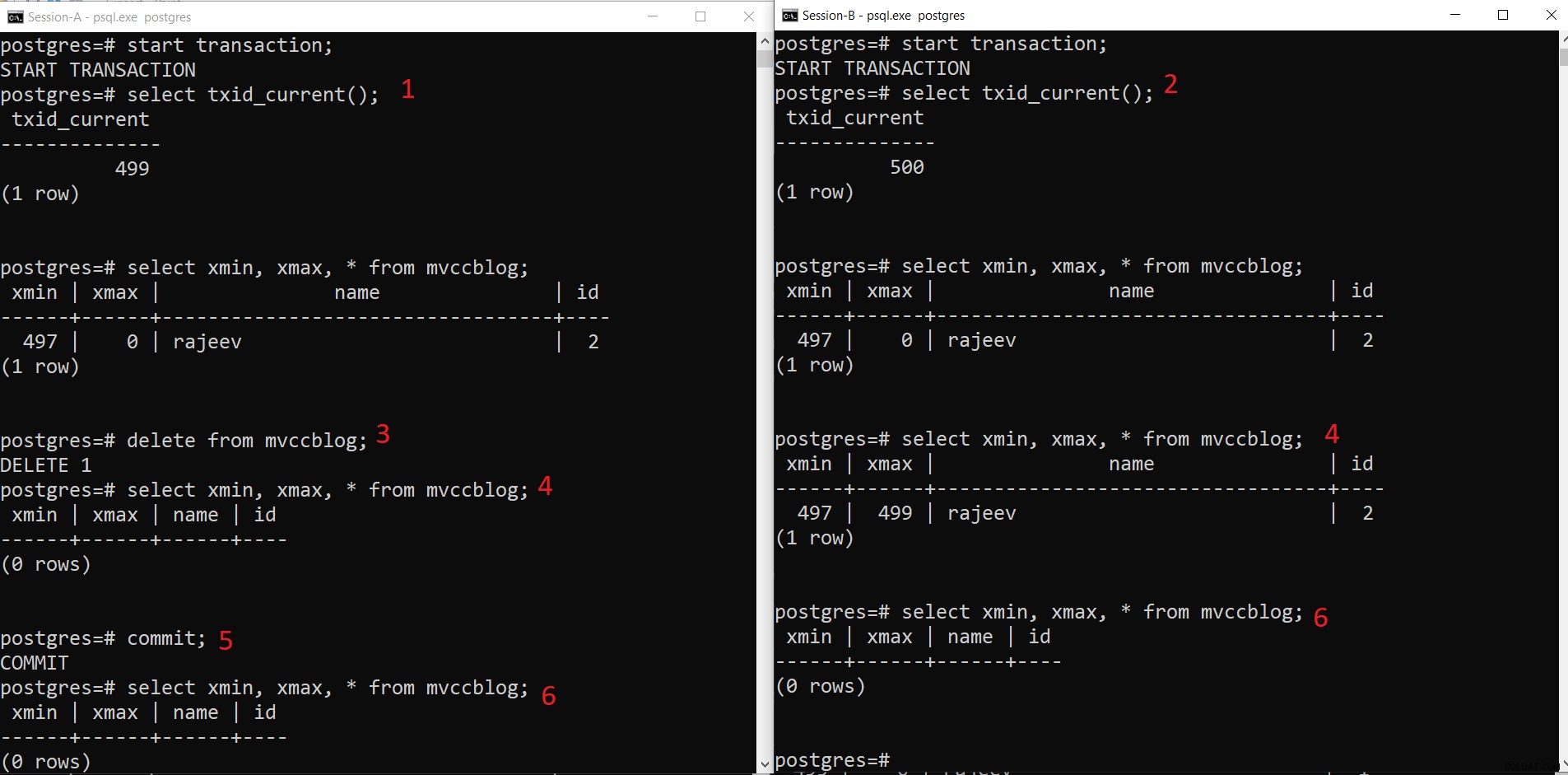 PostgreSQL samtidig DELETE-operation
PostgreSQL samtidig DELETE-operation - Session-A startar en transaktion och får transaktions-ID 499.
- Session-B startar en transaktion och får transaktions-ID 500.
- Session-A tar bort den befintliga posten.
- Här ser inte session-A någon tuppel som raderad från den aktuella transaktionen. Medan Session-B ser en äldre version av tupeln (med xmax som 499; transaktionen som raderade denna post).
- När Session-A genomför transaktionen, förfaller den äldre tuppeln eftersom xmax av den äldre tuppeln har begåtts.
- Nu ser båda sessionerna inte borttagna tupel.
Som vi kan se tar ingen av operationerna bort den befintliga versionen av objektet direkt och där det behövs läggs en extra version av objektet till.
Låt oss nu se hur SELECT-frågan exekveras på en tupel som har flera versioner:SELECT måste läsa alla versioner av tuple tills den hittar rätt tuple enligt isoleringsnivå. Anta att det fanns tupel T1, som uppdaterades och skapade en ny version T1' och som i sin tur skapade T1'' vid uppdatering:
- SELECT-operationen går igenom heap-lagring för denna tabell och kontrollerar först T1. Om T1 xmax-transaktionen har begåtts, flyttas den till nästa version av denna tuppel.
- Anta nu att T1’ tuple xmax också har begåtts, då flyttas den igen till nästa version av denna tuppel.
- Slutligen hittar den T1'' och ser att xmax inte är committed (eller null) och T1'' xmin är synlig för den aktuella transaktionen enligt isoleringsnivå. Slutligen kommer den att läsa T1’’ tuple.
Som vi kan se måste den gå igenom alla tre versionerna av tupeln för att hitta rätt synlig tuppel tills utgången tuppel raderas av sophämtaren (VAKUUM).
MVCC i InnoDB
För att stödja flera versioner underhåller InnoDB ytterligare fält för varje rad enligt nedan:
- DB_TRX_ID:Transaktions-ID för transaktionen som infogade eller uppdaterade raden.
- DB_ROLL_PTR:Den kallas även roll-pekaren och den pekar på att ångra loggpost som skrivits till återställningssegmentet (mer om detta härnäst).
Liksom PostgreSQL skapar InnoDB också flera versioner av raden som en del av all operation, men lagringen av den äldre versionen är annorlunda.
I fallet med InnoDB hålls den gamla versionen av den ändrade raden i ett separat tabellutrymme/lagring (kallat ångra segment). Så till skillnad från PostgreSQL behåller InnoDB endast den senaste versionen av rader i huvudlagringsområdet och den äldre versionen behålls i ångra-segmentet. Radversioner från ångra-segmentet används för att ångra operation vid återställning och för att läsa en äldre version av rader med READ-sats beroende på isoleringsnivån.
Tänk på att det finns två rader, T1 (med värde 1) och T2 (med värde 2) för en tabell, skapandet av nya rader kan demonstreras i nedanstående 3 steg:
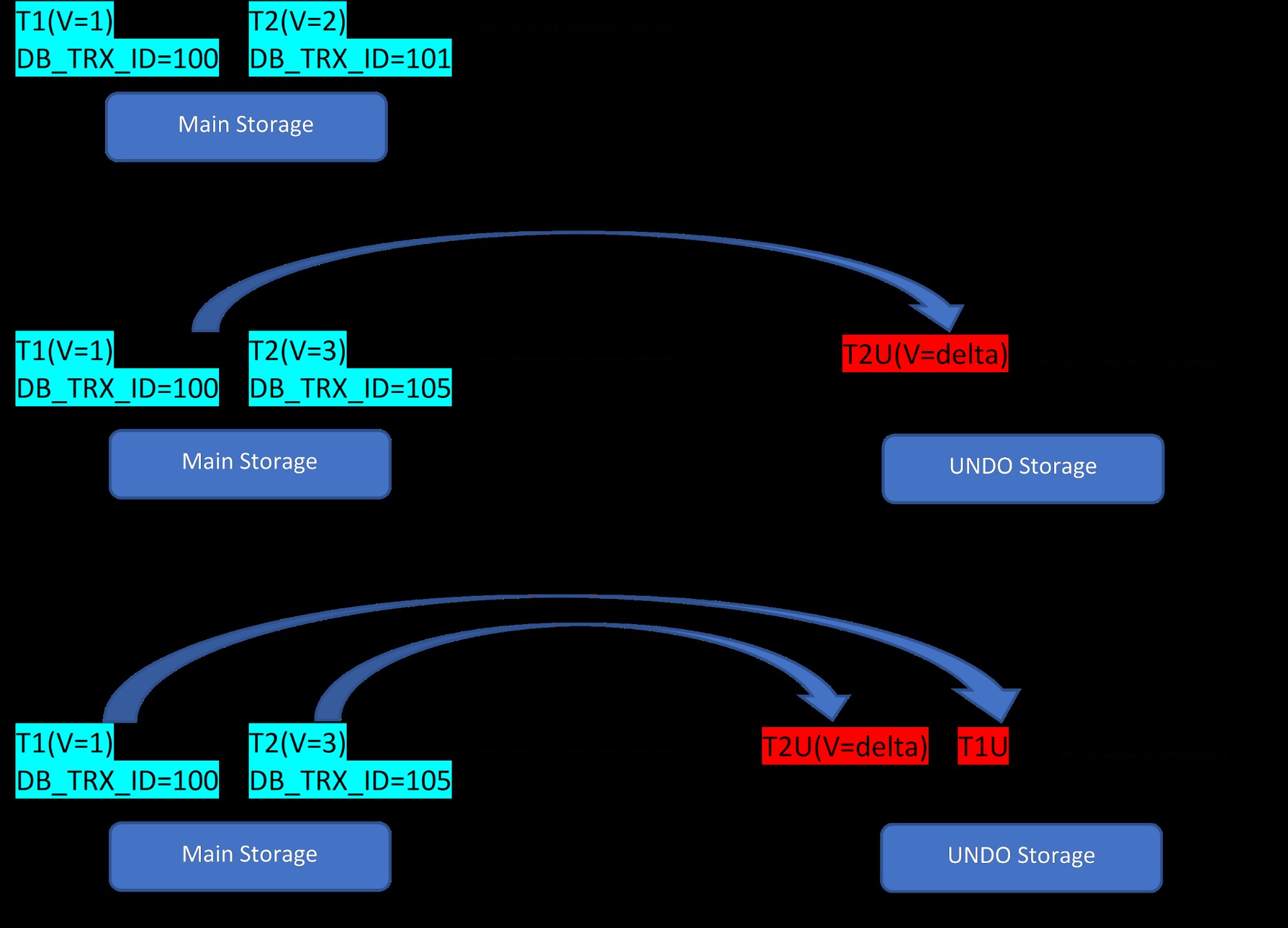 MVCC:Lagring av flera versioner i InnoDB
MVCC:Lagring av flera versioner i InnoDB Som framgår av figuren finns det initialt två rader i databasen med värdena 1 och 2.
Sedan i det andra steget uppdateras raden T2 med värde 2 med värdet 3. Vid denna tidpunkt skapas en ny version med det nya värdet och den ersätter den äldre versionen. Innan dess lagras den äldre versionen i ångra-segmentet (notera att UNDO-segmentversionen endast har ett deltavärde). Observera också att det finns en pekare från den nya versionen till den äldre versionen i återställningssegmentet. Så till skillnad från PostgreSQL är InnoDB-uppdateringen "PÅ PLATS".
På liknande sätt, i det tredje steget, när rad T1 med värde 1 raderas, raderas den befintliga raden praktiskt taget (dvs. den markerar bara en speciell bit i raden) i huvudlagringsområdet och en ny version motsvarande detta läggs till i segmentet Ångra. Återigen finns det en rullningspekare från huvudminnet till ångra segmentet.
Alla operationer beter sig på samma sätt som i fallet med PostgreSQL sett utifrån. Bara intern lagring av flera versioner skiljer sig åt.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperMVCC:PostgreSQL vs InnoDB
Låt oss nu analysera vad som är de största skillnaderna mellan PostgreSQL och InnoDB när det gäller deras MVCC-implementering:
-
Storleken på en äldre version
PostgreSQL uppdaterar bara xmax på den äldre versionen av tupeln, så storleken på den äldre versionen förblir densamma till motsvarande infogade post. Detta innebär att om du har 3 versioner av en äldre tuppel kommer alla att ha samma storlek (förutom skillnaden i faktisk datastorlek om någon vid varje uppdatering).
Medan i fallet med InnoDB är objektversionen som lagras i Undo-segmentet vanligtvis mindre än motsvarande infogade post. Detta beror på att endast de ändrade värdena (d.v.s. differential) skrivs till UNDO-loggen.
-
INSERT operation
InnoDB behöver skriva ytterligare en post i UNDO-segmentet även för INSERT medan PostgreSQL bara skapar ny version vid UPPDATERING.
-
Återställer en äldre version vid återställning
PostgreSQL behöver inte göra något specifikt för att återställa en äldre version i händelse av återställning. Kom ihåg att den äldre versionen har xmax lika med transaktionen som uppdaterade denna tupel. Så tills det här transaktions-id:t har begåtts, anses det vara levande tupel för en samtidig ögonblicksbild. När transaktionen har återställts kommer motsvarande transaktion automatiskt att anses levande för alla transaktioner eftersom det kommer att vara en avbruten transaktion.
Medan det i fallet med InnoDB är uttryckligen nödvändigt att bygga om den äldre versionen av objektet när återställningen sker.
-
Ta tillbaka utrymme som upptas av en äldre version
I fallet med PostgreSQL kan utrymmet som upptas av en äldre version betraktas som död endast när det inte finns någon parallell ögonblicksbild för att läsa denna version. När den äldre versionen är död kan VACUUM-operationen återta utrymmet som de upptar. VAKUUM kan utlösas manuellt eller som en bakgrundsuppgift beroende på konfigurationen.
InnoDB UNDO-loggar är primärt uppdelade i INSERT UNDO och UPDATE UNDO. Den första kasseras så snart motsvarande transaktion genomförs. Den andra måste bevaras tills den är parallell med någon annan ögonblicksbild. InnoDB har ingen explicit VACUUM-drift men på en liknande linje har den asynkron PURGE för att kassera UNDO-loggar som körs som en bakgrundsuppgift.
-
Påverkan av fördröjt vakuum
Som diskuterats i en tidigare punkt är det en enorm inverkan av fördröjt vakuum i fallet med PostgreSQL. Det gör att tabellen börjar svälla och gör att lagringsutrymmet ökar trots att poster ständigt raderas. Det kan också nå en punkt där VAKUUM FULL måste göras, vilket är mycket kostsamma operationer.
-
Sekventiell skanning vid uppblåst bord
PostgreSQL sekventiell skanning måste gå igenom alla äldre versioner av ett objekt även om alla är döda (tills de tas bort med vakuum). Detta är det typiska och mest omtalade problemet i PostgreSQL. Kom ihåg att PostgreSQL lagrar alla versioner av en tupel i samma lagring.
Medan i fallet med InnoDB behöver den inte läsa Ångra post om det inte krävs. Om alla ångraposter är döda räcker det bara att läsa igenom alla de senaste versionerna av objekten.
-
Index
PostgreSQL lagrar index i en separat lagring som håller en länk till faktiska data i HEAP. Så PostgreSQL måste uppdatera INDEX-delen även om det inte var någon förändring i INDEX. Även om det här problemet senare åtgärdades genom att implementera HOT (Heap Only Tuple)-uppdatering, men det har fortfarande begränsningen att om en ny heap-tupel inte kan rymmas på samma sida, så faller den tillbaka till normal UPPDATERING.
InnoDB har inte detta problem eftersom de använder klustrade index.
Slutsats
PostgreSQL MVCC har få nackdelar, särskilt när det gäller uppsvälld lagring om din arbetsbelastning ofta har UPPDATERING/DELETE. Så om du bestämmer dig för att använda PostgreSQL bör du vara mycket noga med att konfigurera VACUUM klokt.
PostgreSQL-communityt har också erkänt detta som ett stort problem och de har redan börjat arbeta med UNDO-baserad MVCC-metod (preliminärt namn som ZHEAP) och vi kan se detsamma i en framtida release.