Här är vi. Nästan två decennier in på 2000-talet och behovet av mer datorkraft är fortfarande ett problem. Teknikföretag dunkar på trottoaren för att ta itu med detta enorma problem direkt. Hårdvaruingenjörer har hittat en lösning genom att ändra hur de designar och tillverkar en dators centrala processorenhet (CPU). De innehåller nu flera kärnor, vilket gör att samtidighet kan ske. I sin tur har mjukvaruutvecklare anpassat sättet de skriver program för att anpassa sig till denna förändring i hårdvaran.
PostgreSQL-communityt har utnyttjat dessa flerkärniga CPU:er för att förbättra frågeprestanda. Genom att bara uppdatera till version 9.6 eller högre kan du använda en funktion som kallas frågeparallellism för att utföra olika operationer. Den delar upp uppgifter i mindre delar och sprider varje uppgift över flera CPU-kärnor. Varje kärna kan bearbeta uppgifterna samtidigt. På grund av hårdvarubegränsningar är detta det enda sättet att förbättra datorns prestanda när vi går in i framtiden.
Innan du använder parallellitetsfunktionen i PostgreSQL-databasen är det viktigt att känna igen hur den gör en fråga parallell. Du kommer att kunna felsöka och lösa eventuella problem som uppstår.
Hur fungerar frågeparallellism?
För att få en bättre förståelse för hur parallellism utförs är det en bra idé att börja på kundnivå. För att komma åt PostgreSQL måste en klient skicka en anslutningsbegäran till databasservern som kallas postmaster. Postmastern kommer att slutföra autentiseringen och sedan skapa en ny serverprocess för varje anslutning. Det är också ansvarigt för att skapa ett område med delat minne som innehåller en buffertpool. Buffertpoolen övervakar överföringen av data mellan det delade minnet och lagringen. Därför, i samma ögonblick som en anslutning upprättas, kommer buffertpoolen att överföra data och tillåta att frågeparallellism kan ske.
Det är inte nödvändigt att alla frågor är parallella. Det finns tillfällen där endast en liten mängd data behövs, och den kan snabbt bearbetas av endast en kärna. Den här funktionen används endast när en fråga kommer att ta avsevärd tid att slutföra. Databasoptimeraren bestämmer om parallellism ska exekveras. Om det är nödvändigt kommer databasen att använda ytterligare en del av minnet som kallas dynamiskt delat minne (DSM). Detta gör det möjligt för ledarprocessen och de parallella medvetna arbetsprocesserna att dela upp frågan mellan flera kärnor och samla in relevant data.
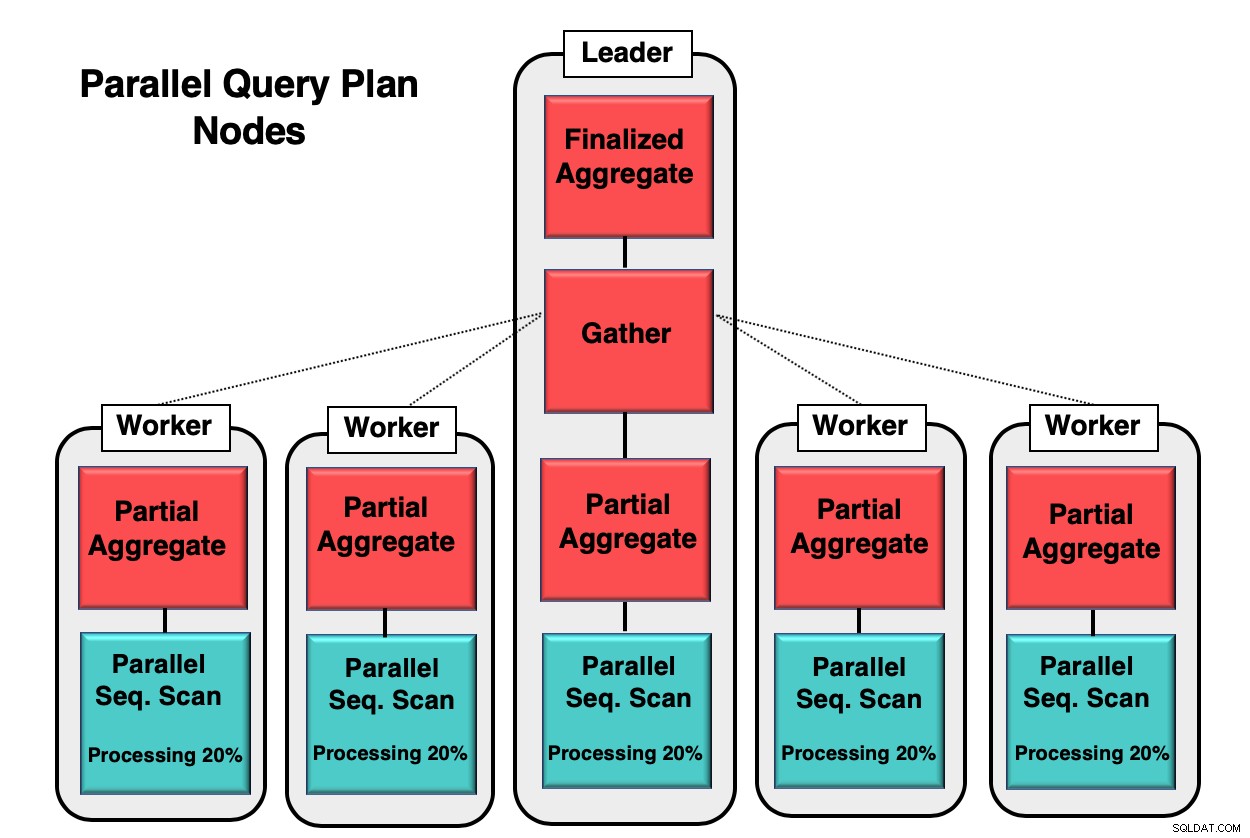
Figur 1 ger dig ett exempel på hur parallellism sker inuti databasen. Ledarprocessen kör den första frågan, medan de enskilda arbetsprocesserna initierar en kopia av samma process. Den partiella aggregerade noden, eller CPU-kärnan, är ansvarig för att implementera den parallella sekventiella genomsökningen av databastabellen.
I det här fallet bearbetar varje sekventiell skanningsnod 20 % av data i 8kb-block. Samma noder kan koordinera sin aktivitet genom att använda en teknik som kallas parallell medveten. Varje nod har full kunskap om vilken data som redan har bearbetats och vilken data som behöver skannas i tabellen för att slutföra frågan. När tuplarna har samlats in i sin helhet skickas de till insamlingsnoden för att kompileras och slutföras.
Parallella operationer
Olika typer av frågor kan användas för att hämta data från en databas för att producera resultatuppsättningar. Här är specifika operationer som ger dig möjligheten att effektivt utnyttja användningen av flera kärnor.
Sekventiell genomsökning
Denna operation läser data i en tabell från början till slutet för att samla in data. Den fördelar arbetsbelastningen jämnt mellan flera kärnor för att öka bearbetningshastigheten för frågor. Den är medveten om varje kärnaktivitet, vilket gör det lättare att avgöra om hela frågan har slutförts. Insamlingsnoden tar sedan emot data som extraherats baserat på frågan.
Aggregation
En standardoperation som tar en stor mängd data och kondenserar den till ett mindre antal rader. Detta händer under den parallella bearbetningen genom att endast extrahera från en tabell eller index, lämplig information baserad på frågan. Att utföra ett genomsnitt av specifik data är ett utmärkt exempel på aggregering.
Hash Join
En teknik som används för att sammanfoga data mellan två tabeller. Det är den snabbaste anslutningsalgoritmen, som vanligtvis utförs med en liten tabell och en stor. Du skapar först en hashtabell och laddar in all data från en tabell där. Sedan kan du skanna all data från hash- och andratabellen med hjälp av parallell sekventiell skanning. Varje tuppel som extraheras från skanningen jämförs med hashtabellen för att se om det finns en matchning. Om en matchning identifieras sammanfogas data. Med lanseringen av PostgreSQL 11 tar det ungefär en tredjedel av dess tidigare behandlingstid att använda parallellism för att slutföra en hash-join.
Slå samman gå med
Om optimeraren bestämmer att en hash-join kommer att överskrida minneskapaciteten, kommer den att utföra en merge-join istället. Processen går ut på att skanna igenom två sorterade listor samtidigt och sammanfoga samma element. Om objekten inte är lika, kommer data inte att sammanfogas.
Nested Loop Join
Denna operation används när du var tvungen att sammanfoga två tabeller som innehåller olika programmeringsspråk, såsom Quick Basic, Python, etc. Varje tabell skannas och bearbetas med hjälp av flera kärnor. Om data matchar skickas den till insamlingsnoden för att anslutas. Indexen skannas också, vilket är anledningen till att denna process innehåller flera loopar för att hämta data. I genomsnitt tar det bara en tredjedel av tiden att slutföra anslutningen genom att använda den parallella processen.
B-tree Index Scan
Denna operation skannar genom ett träd med sorterade data för att hitta specifik information. Denna process tar längre tid än den typiska sekventiella skanningen eftersom det är mycket väntan när man letar efter poster. Men arbetet med att skanna efter lämplig data är uppdelat mellan flera processorer.
Bitmap Heap Scan
Du kan slå samman flera index genom att använda denna operation. Du vill först skapa motsvarande antal bitmappar, eftersom du har index. Om du till exempel har tre index måste du först skapa tre bitmappar. Varje bitmapp hämtar och kompilerar tupler baserat på frågan.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperPartitionsparallellism
Det finns en annan form av parallellism som kan ske inom PostgreSQL-databasen. Det kommer dock inte från att skanna tabeller och dela upp uppgifterna. Du kan partitionera eller dela upp data med specifika värden. Till exempel kan du ta värdeköparna och låta en enda kärna bearbeta data endast inom det värdet. På så sätt vet du exakt vad varje kärna bearbetar vid varje given tidpunkt.
Hash-partitionering
Denna operation används genom att sprida tabellrader i undertabeller. Återigen bestäms klyftan i allmänhet av ett distinkt värde eller värdelista från en tabell. Detta är en utmärkt metod att använda om du inte har effektiv lagringshanteringsteknik på alla dina enheter. Du skulle vilja använda partitionering för att slumpmässigt distribuera data för att förhindra I/O-flaskhalsar.
Gå med partitionsmässigt
En teknik som används för att dela upp tabeller efter partitioner och sammanfoga dem genom att matcha liknande partitioner. Till exempel kan du ha en stor tabell med köpare från hela USA. Du kan först dela upp tabellen efter olika städer och sedan slå ihop några städer baserat på regionen i varje stat. Partitionsmässig koppling förenklar dina data och gör det möjligt att manipulera tabeller.
Parallellt osäkert
PostgreSQL 11 kör automatiskt frågeparallellism om optimeraren bestämmer att detta är det snabbaste sättet att slutföra frågan. Ju högre PostgreSQL-version du använder, desto mer parallell kapacitet kommer din databas att ha. Tyvärr bör inte alla frågor exekveras på ett parallellt sätt, även om det har möjlighet. Den typ av fråga du utför kan ha specifika begränsningar och det kommer att kräva att endast en kärna slutför hela bearbetningen. Detta kommer att sakta ner ditt systems prestanda, men det kommer att garantera att mottagna data är hela.
För att säkerställa att dina frågor aldrig utsätts för risker har utvecklare skapat en funktion som kallas parallell osäker. Du kan manuellt åsidosätta databasoptimeraren och begära att frågan aldrig ska vara parallell. Processen med parallellitet kommer inte att utföras.
Parallellism inom PostgreSQL-databasen är en funktion som bara blir bättre för varje databasversion. Även om teknikens framtid är osäker, verkar det som om användningen av denna funktion är här för att stanna.
För mer information kan du kolla in följande...
- https://www.postgresql.org/docs/10/parallel-query.html
- https://www.postgresql.org/docs/10/how-parallel-query-works.html
- https://www.bbc.com/news/business-42797846
- https://www.technologyreview.com/s/421186/why-cpus-arent-getting-any-faster/
- https://www.percona.com/blog/2019/02/21/parallel-queries-in-postgresql/
- https://malisper.me/postgres-merge-joins/
- https://www.enterprisedb.com/blog/partition-wise-joins-“divide-and-conquer-joins-between-partitioned-table