PostgreSQL 11 släpptes den 10 oktober 2018 och enligt schemat, vilket markerar 23-årsjubileet för den alltmer populära databasen med öppen källkod.
Även om en komplett lista med ändringar finns tillgänglig i de vanliga utgåvorna, är det värt att kolla in den förnyade Feature Matrix-sidan som precis som den officiella dokumentationen har fått en makeover sedan den första versionen, vilket gör det lättare att upptäcka ändringar innan du dyker in i detaljerna .
Till exempel på sidan Release Notes är "Kanalbindning för SCAM-autentisering" begravd under källkoden medan matrisen har den under Säkerhetssektionen. För den nyfikna här är en skärmdump av gränssnittet:
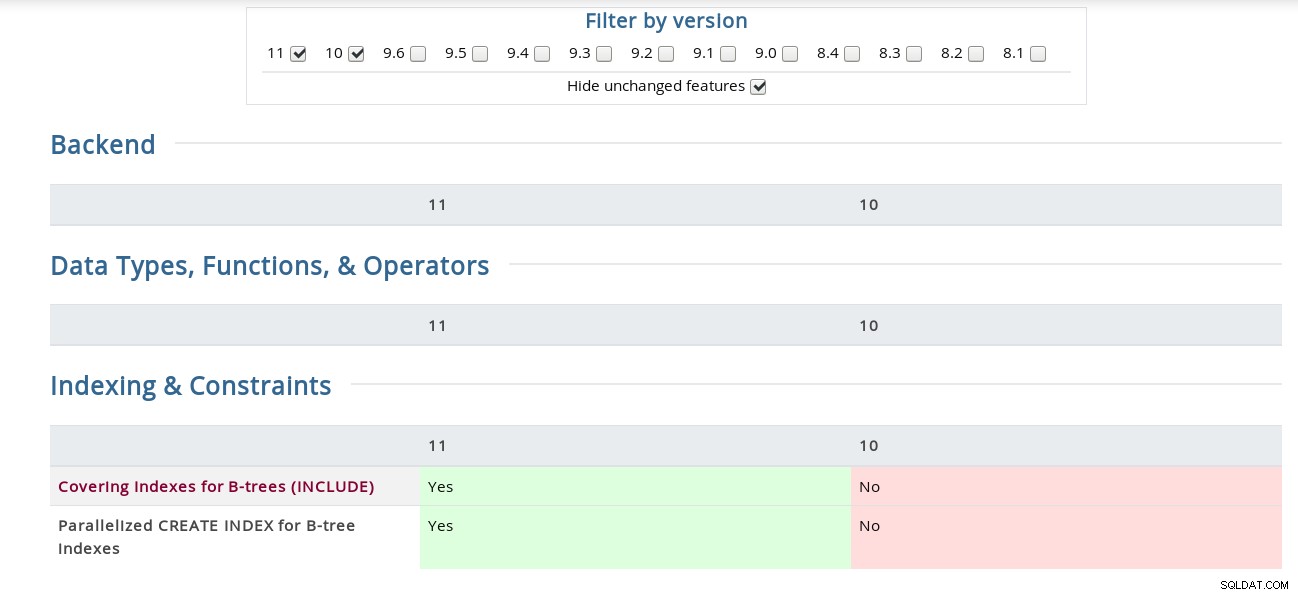 PostgreSQL Feature Matrix
PostgreSQL Feature Matrix Dessutom är Bucardo Postgres Release Notes-sida som länkas ovan, praktisk på sitt sätt, vilket gör det enkelt att söka efter ett nyckelord i alla versioner.
Vad är nytt? Med bokstavligen hundratals ändringar kommer jag att gå igenom skillnaderna som anges i funktionsmatrisen.
Täckande index för B-träd (INKLUDERA)
CREATE INDEX fick INCLUDE-satsen som tillåter index att inkludera icke-nyckelkolumner . Dess användningsfall för frekventa identiska frågor är väl beskrivet i Tom Lanes commit från den 22 november, som uppdaterar utvecklingsdokumentationen (vilket betyder att den nuvarande PostgreSQL 11-dokumentationen inte har den ännu), så för den fullständiga texten, se avsnitt 11.9. Index-Endast skannar och täcker index i utvecklingsversionen.
Parallelliserat CREATE INDEX för B-trädindex
Som antytts i namnet är den här funktionen endast implementerad för B-tree-indexen, och från Robert Haas commit-logg får vi veta att implementeringen kan förfinas i framtiden. Som noterats från CREATE INDEX-dokumentationen, medan metoder för att skapa både parallella och samtidiga index drar fördel av flera CPU:er, i fallet med CONCURRENT kommer endast den första tabellsökningen att utföras parallellt.
Relaterade till denna nya funktion är konfigurationsparametrarna maintenance_work_mem och maintenance_parallel_maintenance_workers .
Slutligen kan antalet parallella arbetare ställas in per tabell med kommandot ALTER TABLE och ange ett värde för parallel_arbetare .
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperJust-In-Time (JIT) kompilering för uttrycksutvärdering och tuppeldeformering
Med sitt eget JIT-kapitel i dokumentationen förlitar sig denna nya funktion på att PostgreSQL kompileras med LLVM-stöd (använd pg_config för att verifiera).
Ämnet JIT i PostgreSQL är tillräckligt komplext (se JIT README-referensen i dokumentationen) för att kräva en dedikerad blogg, under tiden är CitusData-bloggen om JIT en mycket bra läsning för dem som är intresserade att dyka djupare in i ämnet.
Parallelliserade Hash-anslutningar
Denna prestandaförbättring för parallella frågor är resultatet av att lägga till en delad hashtabell, som, som Thomas Munro förklarar i sin Parallel Hash for PostgreSQL-blogg, undviker att partitionera hashtabellen förutsatt att den passar i work_mem , som hittills för PostgreSQL verkar vara en bättre lösning än algoritmen för partition-först. Samma blogg beskriver PostgreSQL-arkitekturens hinder som författaren var tvungen att övervinna i sin strävan efter att lägga till parallellisering till hash-kopplingar som talar om komplexiteten i arbetet som krävdes för att implementera denna funktion.
Standardpartition
Detta är en catch all-partition för att lagra rader som inte matchar någon annan definierad partition. I de fall där en ny partition läggs till rekommenderas en CHECK-begränsning för att undvika en genomsökning av standardpartitionen som kan vara långsam när standardpartitionen innehåller ett stort antal rader.
Standardpartitionsbeteendet förklaras i dokumentationen för ALTER TABLE och CREATE TABLE.
Partitionering med en Hash-nyckel
Kallas även hash-partitionering, och som påpekats i commit-meddelandet tillåter funktionen partitionering av tabeller på ett sådant sätt att partitioner kommer att hålla ett liknande antal rader. Detta uppnås genom att tillhandahålla en modul, som i det enklare scenariot rekommenderas att vara lika med antalet partitioner, och resten bör vara olika för varje partition.
För mer information och ett exempel se dokumentationssidan CREATE TABLE.
Stöd för PRIMARY KEY, FOREIGN KEY, index och triggers på partitionerade tabeller
Tabellpartitionering är redan ett stort steg för att förbättra prestanda för stora tabeller, och tillägget av dessa funktioner tar itu med de begränsningar som partitionerade tabeller har haft sedan PostgreSQL 10 när den moderna "deklarativa partitioneringen" introducerades.
Arbete av Alvaro Herrera pågår för att tillåta främmande nycklar att referera till primärnycklar, och är planerat till nästa PostgreSQL major version 12.
UPPDATERA på en partitionsnyckel
Som förklaras i patch commit-loggen förhindrar denna uppdatering PostgreSQL från att skicka ett fel när en uppdatering av partitionsnyckeln ogiltigförklarar en rad, och istället kommer raden att flyttas till en lämplig partition.
Kanalbindning för SCRAM-autentisering
Detta är en säkerhetsåtgärd som syftar till att förhindra man-in-the-middle-attacker i SASL-autentisering och är noggrant detaljerad i författarens blogg. Funktionen kräver minst OpenSSL 1.0.2.
SKAPA PROCEDUR och CALL-syntax för lagrade SQL-procedurer
PostgreSQL har haft CREATE FUNCTION sedan 1996, med version 1.0.1 funktioner kan dock inte hantera transaktioner. Som nämnts i dokumentationen är kommandot CREATE PROCEDURE inte helt kompatibelt med SQL-standarden.
Obs! Håll utkik efter en kommande blogg som fördjupar sig i den här funktionen
Slutsats
PostgreSQL 11 stora uppdateringar fokuserar på prestandaförbättringar genom parallell exekvering, partitionering och Just-In-Time-kompilering. Lagrade procedurer möjliggör full transaktionskontroll och kan skrivas på en mängd olika PL-språk.