Att köra databaser på molninfrastruktur blir allt mer populärt nu för tiden. Även om en moln-VM kanske inte är lika pålitlig som en server i företagsklass, erbjuder de största molnleverantörerna en mängd olika verktyg för att öka tjänsternas tillgänglighet. I det här blogginlägget visar vi dig hur du skapar din MySQL- eller MariaDB-databas för hög tillgänglighet i molnet. Vi kommer att titta specifikt på Amazon Web Services och Google Cloud Platform, men de flesta av tipsen kan också användas med andra molnleverantörer.
Både AWS och Google erbjuder databastjänster på sina moln, och dessa tjänster kan konfigureras för hög tillgänglighet. Det är möjligt att ha kopior i olika tillgänglighetszoner (eller zoner i GCP), för att öka dina chanser att överleva delvis misslyckande med tjänster inom en region. Även om en värdtjänst är ett mycket bekvämt sätt att köra en databas, notera att tjänsten är designad för att fungera på ett specifikt sätt och som kanske inte passar dina krav. Så till exempel har AWS RDS för MySQL en ganska begränsad lista med alternativ när det kommer till failover-hantering. Multi-AZ-distributioner kommer med 60-120 sekunders failover-tid enligt dokumentationen. Med tanke på att "skuggan" MySQL-instansen måste starta från en "skadad" datauppsättning, kan detta ta ännu längre tid eftersom mer arbete kan krävas för att applicera eller återställa transaktioner från InnoDB redo loggar. Det finns ett alternativ att befordra en slav till att bli en mästare, men det är inte genomförbart eftersom du inte kan återslava befintliga slavar från den nya mästaren. När det gäller en hanterad tjänst är det också mer komplext och svårare att spåra prestandaproblem. Mer insikter om RDS för MySQL och dess begränsningar i det här blogginlägget.
Å andra sidan, om du bestämmer dig för att hantera databaserna är du i en annan värld av möjligheter. Ett antal saker som du kan göra på ren metall är också möjliga på EC2- eller Compute Engine-instanser. Du har inte överkostnaderna för att hantera den underliggande hårdvaran, och ändå behåller du kontrollen över hur du ska bygga systemet. Det finns två huvudalternativ när du designar för MySQL-tillgänglighet - MySQL-replikering och Galera Cluster. Låt oss diskutera dem.
MySQL-replikering
MySQL-replikering är ett vanligt sätt att skala MySQL med flera kopior av data. Asynkron eller semi-synkron, den gör det möjligt att sprida ändringar som exekveras på en enda skrivare, mastern, till repliker/slavar - som var och en skulle innehålla hela datamängden och kan befordras till att bli den nya mastern. Replikering kan också användas för att skala läsningar, genom att dirigera lästrafik till repliker och avlasta mastern på detta sätt. Den största fördelen med replikering är användarvänligheten - det är så allmänt känt och populärt (det är också lätt att konfigurera) att det finns många resurser och verktyg som hjälper dig att hantera och konfigurera det. Vår egen ClusterControl är en av dem - du kan använda den för att enkelt distribuera en MySQL-replikeringsinställning med integrerade belastningsutjämnare, hantera topologiändringar, failover/återställning och så vidare.
Ett stort problem med MySQL-replikering är att den inte är designad för att hantera nätverksdelningar eller masters fel. Om en master går ner måste du marknadsföra en av replikerna. Detta är en manuell process, även om den kan automatiseras med externa verktyg (t.ex. ClusterControl). Det finns inte heller någon kvorummekanism och det finns inget stöd för fencering av misslyckade masterinstanser i MySQL-replikering. Tyvärr kan detta leda till allvarliga problem i distribuerade miljöer - om du marknadsför en ny master medan din gamla kommer tillbaka online kan du sluta skriva till två noder, skapa datadrift och orsaka allvarliga datakonsistensproblem.
Vi kommer att titta på några exempel senare i det här inlägget, som visar hur du upptäcker nätverksdelningar och implementerar STONITH eller någon annan stängselmekanism för din MySQL-replikeringsinställning.
Galera-kluster
Vi såg i föregående avsnitt att MySQL-replikering saknar fäktning och kvorumstöd – det är här Galera Cluster lyser. Den har ett inbyggt kvorumstöd, den har också en stängselmekanism som förhindrar partitionerade noder från att acceptera skrivningar. Detta gör Galera Cluster mer lämpligt än replikering i multi-datacenter-konfigurationer. Galera Cluster stöder också flera skribenter och kan lösa skrivkonflikter. Du är därför inte begränsad till en enda skrivare i en multidatacenteruppsättning, det är möjligt att ha en skrivare i varje datacenter vilket minskar latensen mellan din applikation och databasnivå. Det påskyndar inte skrivningarna eftersom varje skrivning fortfarande måste skickas till varje Galera-nod för certifiering, men det är fortfarande enklare än att skicka skrivningar från alla applikationsservrar över WAN till en enda fjärrmaster.
Så bra som Galera är, det är inte alltid det bästa valet för alla arbetsbelastningar. Galera är inte en drop-in ersättning för MySQL/InnoDB. Den delar gemensamma funktioner med "normal" MySQL - den använder InnoDB som lagringsmotor, den innehåller hela datasetet på varje nod, vilket gör JOINs möjliga. Ändå skiljer sig några av prestandaegenskaperna hos Galera (som prestandan för skrivningar som påverkas av nätverkslatens) från vad du kan förvänta dig av replikeringsinställningar. Underhåll ser också annorlunda ut:hantering av schemaändringar fungerar något annorlunda. Vissa schemadesigner är inte optimala:om du har hotspots i dina tabeller, som ofta uppdaterade räknare, kan detta leda till prestandaproblem. Det finns också en skillnad i bästa praxis relaterade till batchbearbetning - istället för att utföra frågor i stora transaktioner vill du att dina transaktioner ska vara små.
Proxynivå
Det är väldigt svårt och krångligt att bygga en högtillgänglig installation utan proxyservrar. Visst, du kan skriva kod i din applikation för att hålla reda på databasinstanser, svartlista ohälsosamma sådana, hålla reda på skrivbara master(s) och så vidare. Men det här är mycket mer komplext än att bara skicka trafik till en enda slutpunkt - det är där en proxy kommer in. ClusterControl låter dig distribuera ProxySQL, HAProxy och MaxScale. Vi kommer att ge några exempel på att använda ProxySQL, eftersom det ger oss god flexibilitet i att kontrollera databastrafik.
ProxySQL kan distribueras på ett par sätt. Till att börja med kan den distribueras på separata värdar och Keepalived kan användas för att tillhandahålla virtuell IP. Den virtuella IP:n kommer att flyttas runt om en av ProxySQL-instanserna misslyckas. I molnet kan den här installationen vara problematisk eftersom det vanligtvis inte räcker att lägga till en IP i gränssnittet. Du skulle behöva modifiera Keepalved-konfigurationen och skripten för att fungera med elastisk IP (eller statisk - men det kan kallas av din molnleverantör). Då skulle man använda moln-API eller CLI för att flytta denna IP-adress till en annan värd. Av denna anledning föreslår vi att du samlokaliserar ProxySQL med applikationen. Varje applikationsserver skulle konfigureras för att ansluta till den lokala ProxySQL, med hjälp av Unix-sockets. Eftersom ProxySQL använder en ängelprocess kan ProxySQL-krascher upptäckas/startas om inom en sekund. I händelse av hårdvarukrasch kommer den specifika applikationsservern att gå ner tillsammans med ProxySQL. De återstående applikationsservrarna kan fortfarande komma åt sina respektive lokala ProxySQL-instanser. Denna speciella installation har ytterligare funktioner. Säkerhet - ProxySQL, från och med version 1.4.8, har inte stöd för SSL på klientsidan. Den kan bara ställa in SSL-anslutning mellan ProxySQL och backend. Att samlokalisera ProxySQL på applikationsvärden och använda Unix-sockets är en bra lösning. ProxySQL har även möjlighet att cache-förfrågningar och om du ska använda den här funktionen är det vettigt att hålla den så nära applikationen som möjligt för att minska latensen. Vi föreslår att du använder det här mönstret för att distribuera ProxySQL.
Typiska inställningar
Låt oss ta en titt på exempel på mycket tillgängliga inställningar.
Enstaka datacenter, MySQL-replikering
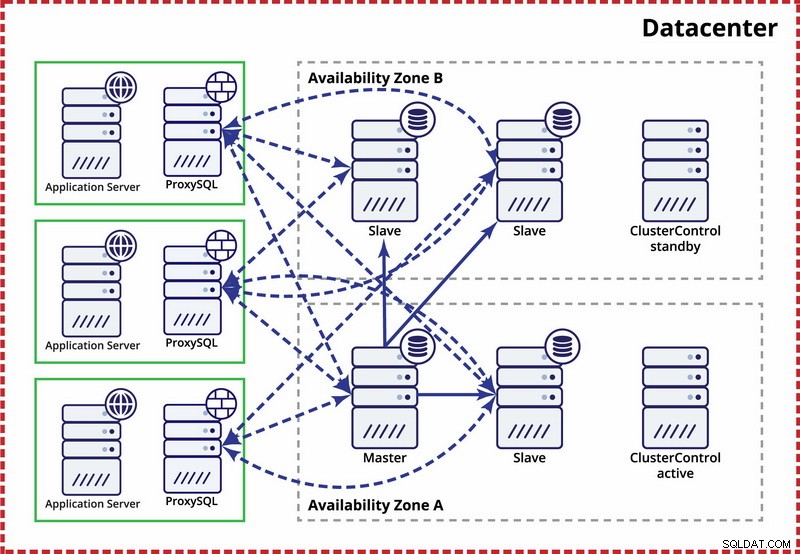
Antagandet här är att det finns två separata zoner inom datacentret. Varje zon har redundant och separat ström, nätverk och anslutning för att minska sannolikheten för att två zoner misslyckas samtidigt. Det är möjligt att ställa in en replikeringstopologi som spänner över båda zonerna.
Här använder vi ClusterControl för att hantera failover. För att lösa scenariot med split-brain mellan tillgänglighetszoner samlokaliserar vi den aktiva ClusterControl med mastern. Vi svartlistar även slavar i den andra tillgänglighetszonen för att säkerställa att automatisk failover inte kommer att resultera i att två masters är tillgängliga.
Flera datacenter, MySQL-replikering
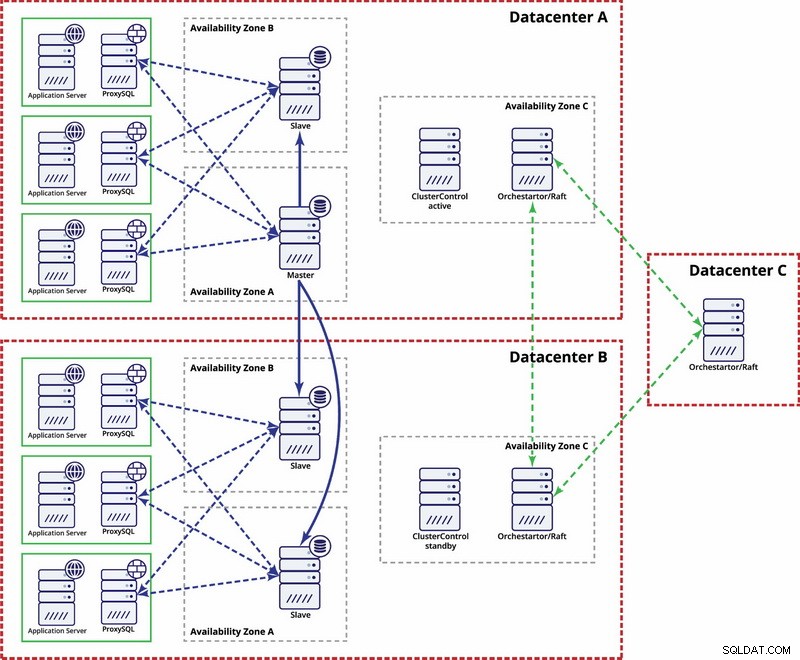
I det här exemplet använder vi tre datacenter och Orchestrator/Flotte för kvorumberäkning. Du kanske måste skriva dina egna skript för att implementera STONITH om master är i det partitionerade segmentet av infrastrukturen. ClusterControl används för nodåterställning och hanteringsfunktioner.
Flera datacenter, Galera Cluster
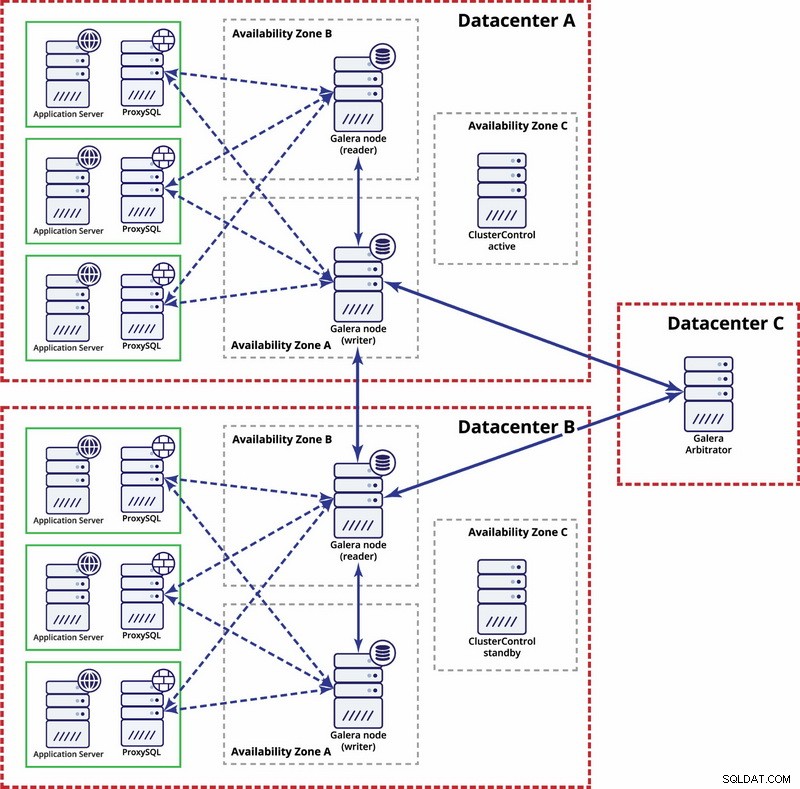
I det här fallet använder vi tre datacenter med en Galera-arbitrator i det tredje - detta gör det möjligt att hantera hela datacenterfel och minskar risken för nätverkspartitionering eftersom det tredje datacentret kan användas som ett relä.
För ytterligare läsning, ta en titt på vitboken "Hur man designar högtillgängliga databasmiljöer med öppen källkod" och titta på webbseminariets repris "Designing Open Source Databases for High Availability".