Undrar du vad Postgresql-scheman är och varför de är viktiga och hur du kan använda scheman för att göra dina databasimplementeringar mer robusta och underhållbara? Den här artikeln kommer att introducera grunderna för scheman i Postgresql och visa dig hur du skapar dem med några grundläggande exempel. Framtida artiklar kommer att fördjupa sig i exempel på hur man säkrar och använder scheman för riktiga applikationer.
För det första, för att rensa upp potentiell terminologiförvirring, låt oss förstå att i Postgresql-världen är termen "schema" kanske något tyvärr överbelastad. I det bredare sammanhanget av relationsdatabashanteringssystem (RDBMS), kan termen "schema" förstås som hänvisar till den övergripande logiska eller fysiska designen av databasen, dvs. definitionen av alla tabeller, kolumner, vyer och andra objekt som utgör databasdefinitionen. I det bredare sammanhanget kan ett schema uttryckas i ett entity-relationship-diagram (ER) eller ett skript med datadefinitionsspråk (DDL)-satser som används för att instansiera applikationsdatabasen.
I Postgresql-världen kan termen "schema" bättre förstås som ett "namnutrymme". Faktum är att i Postgresql-systemtabellerna registreras scheman i tabellkolumner som kallas "namnutrymme", vilket, IMHO, är mer exakt terminologi. Som en praktisk sak, när jag ser "schema" i kontexten av Postgresql, omtolkar jag det tyst som att jag säger "namnutrymme".
Men du kanske frågar:"Vad är ett namnutrymme?" I allmänhet är ett namnutrymme ett ganska flexibelt sätt att organisera och identifiera information med namn. Föreställ dig till exempel två närliggande hushåll, smedarna, Alice och Bob, och makarna Jones, Bob och Cathy (jfr figur 1). Om vi bara använde förnamn kan det bli förvirrande om vilken person vi menade när vi pratade om Bob. Men genom att lägga till efternamnet, Smith eller Jones, identifierar vi unikt vilken person vi menar.
Ofta är namnutrymmen organiserade i en kapslad hierarki. Detta möjliggör en effektiv klassificering av stora mängder information i mycket finkorniga strukturer, som till exempel internetdomännamnssystemet. På toppnivån definierar ".com", ".net", ".org", ".edu" och etc. breda namnutrymmen inom vilka det finns registrerade namn för specifika enheter, till exempel "severalnines.com" och "postgresql.org" är unikt definierade. Men under var och en av dessa finns ett antal vanliga underdomäner som till exempel "www", "mail" och "ftp", som ensamma är duplicerade, men inom respektive namnutrymmen är unika.
Postgresql-scheman tjänar samma syfte att organisera och identifiera, men till skillnad från det andra exemplet ovan kan Postgresql-scheman inte kapslas i en hierarki. Även om en databas kan innehålla många scheman, finns det alltid bara en nivå, så inom en databas måste schemanamnen vara unika. Dessutom måste varje databas innehålla minst ett schema. Närhelst en ny databas instansieras skapas ett standardschema med namnet "public". Innehållet i ett schema inkluderar alla andra databasobjekt såsom tabeller, vyer, lagrade procedurer, triggers och etc. För att visualisera, se figur 2, som visar en matryoshka-docka-liknande kapsel som visar var scheman passar in i strukturen av en Postgresql-databas.
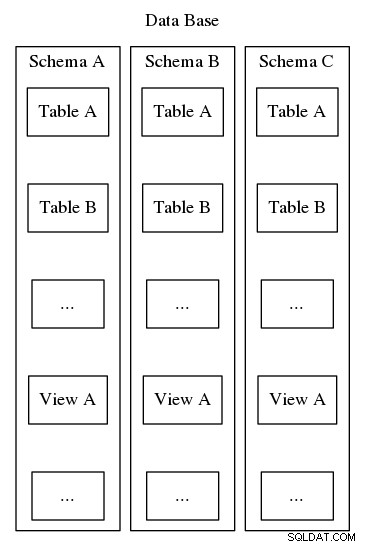
Förutom att helt enkelt organisera databasobjekt i logiska grupper för att göra dem mer hanterbara, tjänar scheman det praktiska syftet att undvika namnkollision. Ett operativt paradigm involverar att definiera ett schema för varje databasanvändare för att ge en viss grad av isolering, ett utrymme där användare kan definiera sina egna tabeller och vyer utan att störa varandra. Ett annat tillvägagångssätt är att installera tredjepartsverktyg eller databastillägg i individuella scheman för att hålla alla relaterade komponenter logiskt samman. En senare artikel i den här serien kommer att beskriva ett nytt tillvägagångssätt för robust applikationsdesign, som använder scheman som ett sätt att indirekta för att begränsa exponeringen av databasens fysiska design och istället presentera ett användargränssnitt som löser syntetiska nycklar och underlättar långsiktigt underhåll och konfigurationshantering allt eftersom systemkraven utvecklas.
Låt oss göra lite kod!
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperDet enklaste kommandot för att skapa ett schema i en databas är
CREATE SCHEMA hollywood;Detta kommando kräver skapa privilegier i databasen, och det nyskapade schemat "hollywood" kommer att ägas av användaren som anropar kommandot. En mer komplex anrop kan inkludera valfria element som anger en annan ägare, och kan till och med inkludera DDL-satser som instansierar databasobjekt inom schemat, allt i ett kommando!
Det allmänna formatet är
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]där "användarnamn" är vem som kommer att äga schemat och "schema_element" kan vara ett av vissa DDL-kommandon (se Postgresql-dokumentationen för detaljer). Superanvändarbehörigheter krävs för att använda AUTHORISATION-alternativet.
Så för att till exempel skapa ett schema med namnet "hollywood" som innehåller en tabell med namnet "filmer" och visa namngivna "vinnare" i ett kommando, kan du göra
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Ytterligare databasobjekt kan sedan skapas direkt, till exempel skulle en extra tabell läggas till i schemat med
CREATE TABLE hollywood.actors (name text, dob date, gender text);Notera i exemplet ovan prefixet för tabellnamnet med schemanamnet. Detta krävs eftersom som standard, det vill säga utan explicit schemaspecifikation, skapas nya databasobjekt inom vad som än är det aktuella schemat, vilket vi kommer att täcka härnäst.
Kom ihåg hur vi i exemplet för förnamnsutrymmet ovan hade två personer som hette Bob, och vi beskrev hur man kan dekonfliktera eller särskilja dem genom att inkludera efternamnet. Men inom vart och ett av Smith- och Jones-hushållen för sig, förstår varje familj att "Bob" syftar på den som hör till just det hushållet. Så till exempel i varje hushålls sammanhang behöver Alice inte tilltala sin man som Bob Jones, och Cathy behöver inte hänvisa till sin man som Bob Smith:de kan var och en bara säga "Bob".
Postgresql nuvarande schema är ungefär som hushållet i exemplet ovan. Objekt i det aktuella schemat kan refereras till okvalificerade, men hänvisning till objekt med liknande namn i andra scheman kräver att namnet kvalificeras genom att prefixet schemanamnet enligt ovan.
Det aktuella schemat härleds från konfigurationsparametern "search_path". Den här parametern lagrar en kommaseparerad lista med schemanamn och kan undersökas med kommandot
SHOW search_path;eller ställ in ett nytt värde med
SET search_path TO schema [, schema, ...];Det första schemanamnet i listan är det "aktuella schemat" och är där nya objekt skapas om de anges utan schemanamnskvalifikation.
Den kommaseparerade listan med schemanamn tjänar också till att bestämma sökordningen med vilken systemet lokaliserar befintliga okvalificerade namngivna objekt. Till exempel, tillbaka till Smith och Jones grannskap, skulle en paketleverans adresserad bara till "Bob" kräva besök hos varje hushåll tills den första invånaren som heter "Bob" hittas. Observera att detta kanske inte är den avsedda mottagaren. Samma logik gäller för Postgresql. Systemet söker efter tabeller, vyer och andra objekt inom scheman i ordningen sökväg, och sedan används det först hittade namnmatchningsobjektet. Schemakvalificerade namngivna objekt används direkt utan referens till sökvägen.
I standardkonfigurationen avslöjar frågan om sökvägskonfigurationsvariabeln detta värde
SHOW search_path;
Search_path
--------------
"$user", publicSystemet tolkar det första värdet som visas ovan som det aktuella inloggade användarnamnet och tillgodoser användningsfallet som nämnts tidigare där varje användare tilldelas ett användarnamnet schema för en arbetsyta skild från andra användare. Om inget sådant användarnamn har skapats ignoreras den posten och det "offentliga" schemat blir det aktuella schemat där nya objekt skapas.
Så tillbaka till vårt tidigare exempel på att skapa tabellen "hollywood.actors", om vi inte hade kvalificerat tabellnamnet med schemanamnet, skulle tabellen ha skapats i det offentliga schemat. Om vi förväntade oss att skapa alla objekt inom ett specifikt schema, kan det vara bekvämt att ställa in sökvägsvariabeln som t.ex.
SET search_path TO hollywood,public;underlättar förkortningen att skriva okvalificerade namn för att skapa eller komma åt databasobjekt.
Det finns också en systeminformationsfunktion som returnerar det aktuella schemat med en fråga
select current_schema();I händelse av fettfingrar stavningen kan ägaren av ett schema ändra namnet, förutsatt att användaren också har skapa privilegier för databasen, med
ALTER SCHEMA old_name RENAME TO new_name;Och slutligen, för att ta bort ett schema från en databas finns det ett drop-kommando
DROP SCHEMA schema_name;DROP-kommandot misslyckas om schemat innehåller några objekt, så de måste tas bort först, eller så kan du valfritt rekursivt ta bort ett schema allt dess innehåll med alternativet CASCADE
DROP SCHEMA schema_name CASCADE;Dessa grunder hjälper dig att förstå scheman!