Gästförfattare:Michael J Swart (@MJSwart)
Jag lägger ner mycket tid på att översätta programvarukrav till schema och frågor. Dessa krav är ibland lätta att implementera men är ofta svåra. Jag vill prata om UI-designval som leder till dataåtkomstmönster som är besvärliga att implementera med SQL Server.
Sortera efter kolumn
Sort-By-Column är ett så välbekant mönster att vi kan ta det för givet. Varje gång vi interagerar med programvara som visar en tabell kan vi förvänta oss att kolumnerna kan sorteras så här:
Sort-By-Colunn är ett bra mönster när all data får plats i webbläsaren. Men om datamängden är miljarder rader stor kan detta bli besvärligt även om webbsidan bara kräver en sida med data. Tänk på denna tabell med låtar:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Och betrakta dessa fyra frågor sorterade efter varje kolumn:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
Även för en så här enkel fråga finns det olika frågeplaner. De två första frågorna använder täckande index:
Den tredje frågan måste göra en nyckelsökning som inte är idealisk:
Men det värsta är den fjärde frågan som måste skanna hela tabellen och göra en sortering för att returnera de första 20 raderna:
Poängen är att även om den enda skillnaden är ORDER BY-satsen, måste dessa frågor analyseras separat. Den grundläggande enheten för SQL-inställning är frågan. Så om du visar mig UI-krav med tio sorterbara kolumner, visar jag dig tio frågor att analysera.
När blir det här besvärligt?
Funktionen Sortera efter kolumn är ett bra UI-mönster, men det kan bli besvärligt om data kommer från en enorm växande tabell med många, många kolumner. Det kan vara frestande att skapa täckande index på varje kolumn, men det har andra kompromisser. Columnstore-index kan hjälpa under vissa omständigheter, men det introducerar en annan nivå av besvärlighet. Det finns inte alltid ett lätt alternativ.
Sidade resultat
Att använda sökresultat är ett bra sätt att inte överväldiga användaren med för mycket information på en gång. Det är också ett bra sätt att inte överväldiga databasservrarna ... vanligtvis.
Tänk på den här designen:

Datan bakom detta exempel kräver att man räknar och bearbetar hela datasetet för att kunna rapportera antalet resultat. Frågan för det här exemplet kan använda syntax så här:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Det är bekväm syntax, och frågan producerar bara 25 rader. Men bara för att resultatet är litet betyder det inte nödvändigtvis att det är billigt. Precis som vi såg med Sort-By-Column-mönstret är en TOP-operatör bara billig om den inte behöver sortera en massa data först.
Asynkrona sidförfrågningar
När en användare navigerar från en sida med resultat till nästa kan webbförfrågningarna separeras med sekunder eller minuter. Detta leder till problem som liknar de fallgropar man ser när man använder NOLOCK. Till exempel:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
När en rad läggs till mellan de två förfrågningarna kan användaren se samma rad två gånger. Och om en rad tas bort kan användaren missa en rad när de navigerar på sidorna. Detta Paged-Results-mönster motsvarar "Ge mig rader 26-50". När den riktiga frågan borde vara "Ge mig de kommande 25 raderna". Skillnaden är subtil.
Bättre mönster
Med Paged-Results kan "OFFSET @N ROWS" ta längre och längre tid när @N växer. Överväg istället Ladda-Mer-knappar eller Oändlig rullning. Med Load-More-sökning finns det åtminstone en chans att effektivt använda ett index. Frågan skulle se ut ungefär så här:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Det lider fortfarande av några av fallgroparna med asynkrona sidförfrågningar, men på grund av bokmärket kommer användaren att fortsätta där de slutade.
Söka text efter delsträng
Sökning finns överallt på internet. Men vilken lösning ska användas på baksidan? Jag vill varna för att söka efter en delsträng med SQL Servers LIKE-filter med jokertecken som detta:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Det kan leda till obekväma resultat så här:
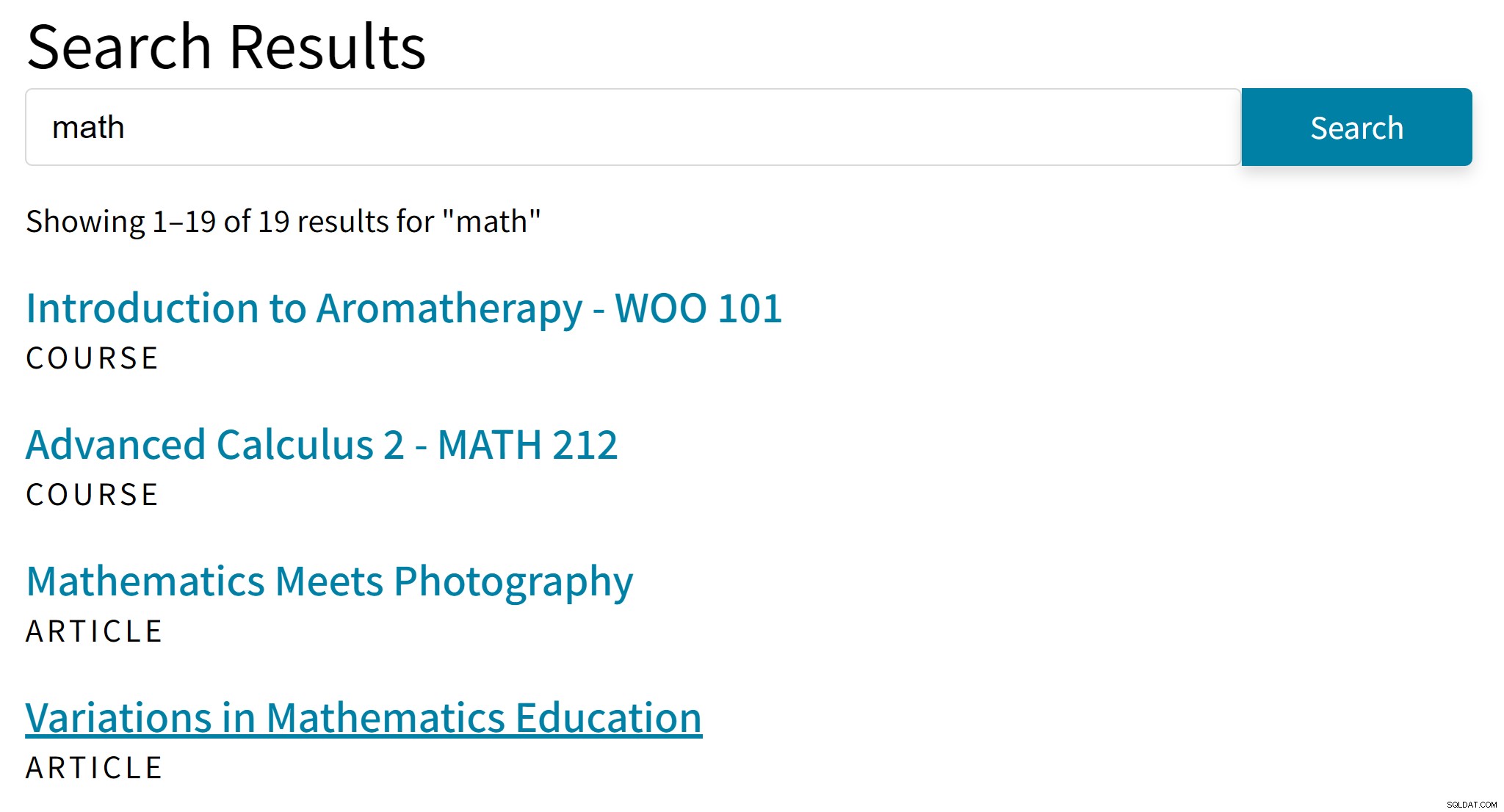
"Aromaterapi" är förmodligen inte en bra träff för söktermen "matte". Samtidigt saknas artiklar i sökresultaten som bara nämner algebra eller trigonometri.
Det kan också vara mycket svårt att genomföra effektivt med SQL Server. Det finns inget enkelt index som stöder denna typ av sökning. Paul White gav en knepig lösning med Trigram Wildcard String Search i SQL Server. Det finns också svårigheter som kan uppstå med kollationer och Unicode. Det kan bli en dyr lösning för en inte så bra användarupplevelse.
Vad du ska använda istället
SQL Servers fulltextsökning verkar som om det kan hjälpa, men jag har personligen aldrig använt det. I praktiken har jag bara sett framgång i lösningar utanför SQL Server (t.ex. Elasticsearch).
Slutsats
Enligt min erfarenhet har jag funnit att mjukvarudesigners ofta är mycket mottagliga för feedback om att deras design ibland kommer att vara besvärlig att implementera. När de inte är det, har jag tyckt att det är användbart att lyfta fram fallgroparna, kostnaderna och leveranstiden. Den typen av feedback är nödvändig för att hjälpa till att bygga underhållbara, skalbara lösningar.
Om författaren
 Michael J Swart är en passionerad databasproffs och bloggare som fokuserar på databasutveckling och mjukvaruarkitektur. Han tycker om att prata om allt datarelaterat, att bidra till samhällsprojekt. Michael bloggar som "Database Whisperer" på michaeljswart.com.
Michael J Swart är en passionerad databasproffs och bloggare som fokuserar på databasutveckling och mjukvaruarkitektur. Han tycker om att prata om allt datarelaterat, att bidra till samhällsprojekt. Michael bloggar som "Database Whisperer" på michaeljswart.com.