Som alla programmeringsspråk har T-SQL sin del av vanliga buggar och fallgropar, av vilka några orsakar felaktiga resultat och andra orsakar prestandaproblem. I många av dessa fall finns det bästa praxis som kan hjälpa dig att undvika att hamna i problem. Jag undersökte andra Microsoft Data Platform MVPs och frågade om de buggar och fallgropar som de ser ofta eller som de bara tycker är särskilt intressanta, och de bästa metoderna som de använder för att undvika dessa. Jag har många intressanta fall.
Stort tack till Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser och Chan Ming Man för att du delar med dig av din kunskap och erfarenhet!
Den här artikeln är den första i en serie om ämnet. Varje artikel fokuserar på ett visst tema. Den här månaden fokuserar jag på buggar, fallgropar och bästa praxis som är relaterade till determinism. En deterministisk beräkning är en som garanterat ger upprepningsbara resultat med samma indata. Det finns många buggar och fallgropar som är resultatet av användningen av icke-deterministiska beräkningar. I den här artikeln tar jag upp implikationerna av att använda icke-deterministisk ordning, icke-deterministiska funktioner, flera referenser till tabelluttryck med icke-deterministiska beräkningar och användningen av CASE-uttryck och NULLIF-funktionen med icke-deterministiska beräkningar.
Jag använder exempeldatabasen TSQLV5 i många av exemplen i den här serien.
Icketerministisk ordning
En vanlig källa för buggar i T-SQL är användningen av icke-deterministisk ordning. Det vill säga när din beställning efter lista inte unikt identifierar en rad. Det kan vara presentationsbeställning, TOP/OFFSET-FETCH-beställning eller fönsterbeställning.
Ta till exempel ett klassiskt personsökningsscenario med OFFSET-FETCH-filtret. Du måste fråga tabellen Sales.Orders och returnera en sida med 10 rader åt gången, sorterade efter orderdatum, fallande (senast först). Jag kommer att använda konstanter för offset- och hämta-elementen för enkelhetens skull, men vanligtvis är de uttryck som är baserade på indataparametrar.
Följande fråga (kalla det Fråga 1) returnerar den första sidan av de 10 senaste beställningarna:
ANVÄND TSQLV5; VÄLJ orderid, orderdate, custid FRÅN Sales.Order BESTÄLL EFTER orderdatum DESC OFFSET 0 RADER HÄMTA ENDAST NÄSTA 10 RADER;
Planen för fråga 1 visas i figur 1.
 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
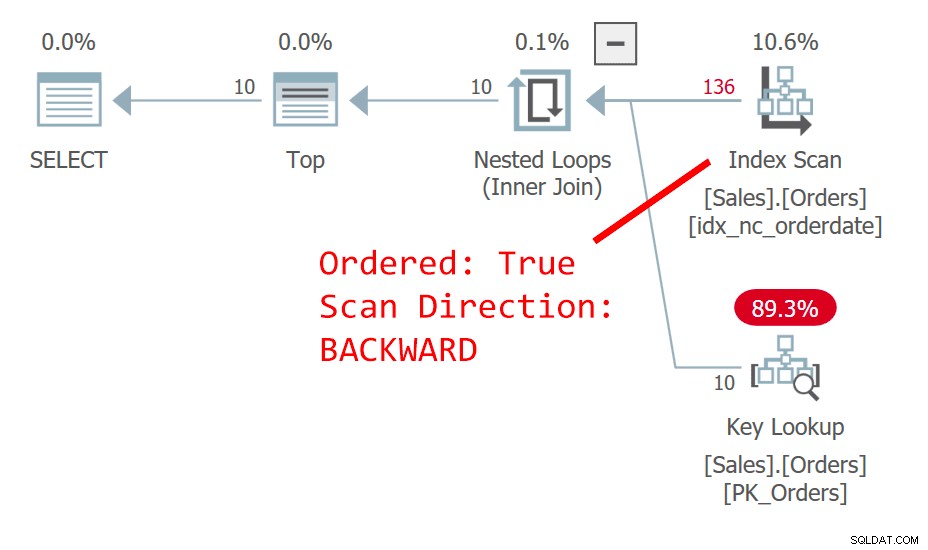
Frågan ordnar raderna efter orderdatum, fallande. Orderdatumkolumnen identifierar inte en rad unikt. Denna icke-deterministiska ordning innebär att det begreppsmässigt inte finns någon preferens mellan raderna med samma datum. Vad som avgör vilken rad SQL Server föredrar i händelse av oavgjort är saker som planval och fysisk datalayout – inte något som du kan lita på som är repeterbart. Planen i figur 1 skannar indexet på orderdatum baklänges. Det råkar vara så att den här tabellen har ett klustrade index på orderid, och i en klustrad tabell används den klustrade indexnyckeln som en radlokalisering i icke-klustrade index. Det blir faktiskt implicit positionerat som det sista nyckelelementet i alla icke-klustrade index även om SQL Server teoretiskt sett kunde ha placerat det i indexet som en inkluderad kolumn. Så implicit är det icke-klustrade indexet på orderdate faktiskt definierat på (orderdate, orderid). Följaktligen, i vår ordnade bakåtsökning av indexet, mellan kopplade rader baserat på orderdatum, nås en rad med ett högre orderid-värde före en rad med ett lägre orderid-värde. Den här frågan genererar följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 5019 5019 5019 5019 2019 2019 10-1 80 *** 11068 2019-05-04 62
Använd sedan följande fråga (kalla den Fråga 2) för att få den andra sidan med 10 rader:
VÄLJ orderid, orderdate, custid FRÅN Sales.Order BESTÄLL EFTER orderdatum DESC OFFSET 10 RADER HÄMT ENDAST NÄSTA 10 RADER;
Planen för Query visas i figur 2.
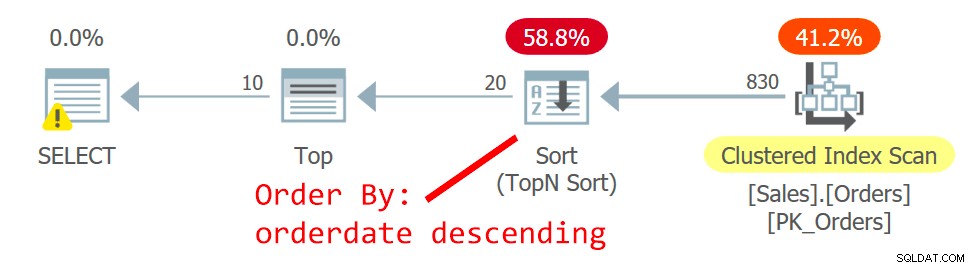
Figur 2:Plan för fråga 2
Optimeraren väljer en annan plan - en skannar det klustrade indexet på ett oordnat sätt och använder en TopN-sortering för att stödja Top-operatörens begäran att hantera offset-hämtningsfiltret. Anledningen till förändringen är att planen i figur 1 använder ett icke-klustrade icke-täckande index, och ju längre sidan du är ute efter, desto fler uppslag krävs. Med den andra sidans begäran passerade du vändpunkten som motiverar användningen av det icke-täckande indexet.
Även om skanningen av det klustrade indexet, som definieras med orderid som nyckeln, är en oordnad sådan, använder lagringsmotorn en indexorderskanning internt. Detta har att göra med storleken på indexet. Upp till 64 sidor föredrar lagringsmotorn i allmänhet indexorderskanningar framför allokeringsorderskanningar. Även om indexet var större, under den läsbestämda isoleringsnivån och data som inte är markerade som skrivskyddade, använder lagringsmotorn en indexorderskanning för att undvika dubbelläsning och överhoppning av rader som ett resultat av siddelningar som inträffar under skanna. Under de givna förhållandena, i praktiken, mellan rader med samma datum, får denna plan tillgång till en rad med en lägre orderid före en med en högre orderid.
Den här frågan genererar följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 6-10 32 11062 6-10 32 11062 6-10 32 11062 6-1 04-29 53 11058 2019-04-29 6
Observera att även om den underliggande informationen inte ändrades, så fick du samma order (med order-ID 11069) på både första och andra sidan!
Förhoppningsvis är den bästa praxisen här tydlig. Lägg till en tiebreaker till din order-by-lista för att få en deterministisk ordning. Till exempel, ordna efter orderdatum fallande, orderid fallande.
Försök igen och fråga efter första sidan, den här gången med en deterministisk ordning:
VÄLJ orderid, orderdate, custid FRÅN Sales.Order ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS HÄMTA ENDAST NÄSTA 10 RADER;
Du får garanterat följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 5019 5019 5019 5019 2019 2019 10-1 80 11068 2019-05-04 62
Be om den andra sidan:
VÄLJ order-id, orderdatum, custid FRÅN Sales.Order BESTÄLL EFTER orderdatum DESC, orderid DESC OFFSET 10 RADER HÄMTA ENDAST NÄSTA 10 RADER;
Du får garanterat följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 301 2019 2019 2019 2019 2019 2019 2019 2019 67 11058 2019-04-29 6
Så länge det inte förekom några förändringar i den underliggande informationen, är du garanterad att få på varandra följande sidor utan upprepningar eller hoppa över rader mellan sidorna.
På ett liknande sätt, genom att använda fönsterfunktioner som ROW_NUMBER med icke-deterministisk ordning, kan du få olika resultat för samma fråga beroende på planformen och den faktiska åtkomstordningen mellan banden. Tänk på följande fråga (kalla den fråga 3), implementera förstasidesbegäran med radnummer (som tvingar fram användningen av indexet på orderdatum i illustrationssyfte):
MED C AS (VÄLJ orderid, orderdatum, kund, ROW_NUMBER() ÖVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate)) ) VÄLJ orderid, orderdatum, kund FRÅN C WHERE n MELLAN 1 OCH 10;
Planen för denna fråga visas i figur 3:
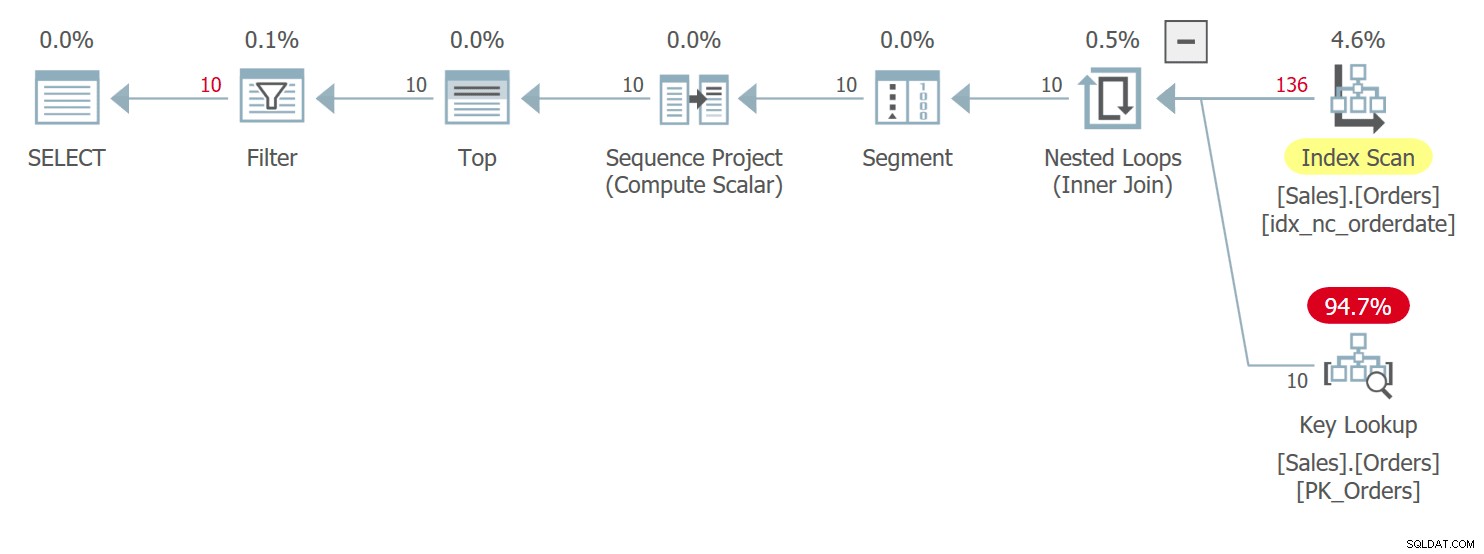
Figur 3:Plan för fråga 3
Du har mycket liknande villkor här som de jag beskrev tidigare för fråga 1 med dess plan som visades tidigare i figur 1. Mellan rader med kopplingar i orderdate-värdena får denna plan tillgång till en rad med ett högre orderid-värde före en med ett lägre orderid värde. Den här frågan genererar följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 5019 5019 5019 5019 2019 2019 10-1 80 *** 11068 2019-05-04 62
Kör sedan frågan igen (kalla den Query 4), och begär den första sidan, men den här gången tvingar du fram användningen av det klustrade indexet PK_Orders:
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) VÄLJ orderid, orderdate, custid FRÅN C WHERE n MELLAN 1 OCH 10;
Planen för denna fråga visas i figur 4.

Figur 4:Plan för fråga 4
Den här gången har du mycket liknande villkor som de jag beskrev tidigare för fråga 2 med dess plan som visades tidigare i figur 2. Mellan rader med kopplingar i orderdate-värdena får denna plan tillgång till en rad med ett lägre orderid-värde före en med en högre orderid värde. Den här frågan genererar följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 5-09 5019 5019 2019 5019 5019 2019 2019 50-1 17 *** 11068 2019-05-04 62
Observera att de två körningarna gav olika resultat även om ingenting ändrades i den underliggande informationen.
Återigen, den bästa praxisen här är enkel – använd deterministisk ordning genom att lägga till en tiebreaker, som så:
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) VÄLJ orderid, orderdate, custid FRÅN C WHERE n MELLAN 1 OCH 10;
Den här frågan genererar följande utdata:
orderid orderdate custid ------------------ ---------- ---------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 5-2019 5-019 5019 5019 5019 5019 2019 2019 10-1 80 11068 2019-05-04 62
Det returnerade setet är garanterat repeterbart oavsett planens form.
Det är förmodligen värt att nämna att eftersom denna fråga inte har en presentationsordning efter klausul i den yttre frågan, finns det ingen garanterad presentationsordning här. Om du behöver en sådan garanti måste du lägga till en presentationsordning per klausul, som så:
MED C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) VÄLJ orderid, orderdate, custid FRÅN C WHERE n MELLAN 1 OCH 10 ORDER BY n;
Icketerministiska funktioner
En icke-deterministisk funktion är en funktion som med samma indata kan returnera olika resultat i olika exekveringar av funktionen. Klassiska exempel är SYSDATETIME, NEWID och RAND (när de anropas utan ett inmatningsfrö). Beteendet hos icke-deterministiska funktioner i T-SQL kan vara överraskande för vissa och kan i vissa fall leda till buggar och fallgropar.
Många antar att när du anropar en icke-deterministisk funktion som en del av en fråga, utvärderas funktionen separat per rad. I praktiken utvärderas de flesta icke-deterministiska funktioner en gång per referens i frågan. Betrakta följande fråga som ett exempel:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Eftersom det bara finns en referens till var och en av de icke-deterministiska funktionerna SYSDATETIME och RAND i frågan, utvärderas var och en av dessa funktioner endast en gång, och dess resultat upprepas över alla resultatrader. Jag fick följande utdata när jag körde den här frågan:
orderid dt rnd ------------------ -------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0,962042872007464 11019 2019-02-04 17:03:07.9229177 0,9621017 0,9621017 0,9621017 0,9621017 0,96210207:01-9 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.929177 0Som ett exempel där att inte förstå detta beteende kan resultera i en bugg, anta att du behöver skriva en fråga som returnerar tre slumpmässiga beställningar från Sales.Orders-tabellen. Ett vanligt första försök är att använda en TOP-fråga med ordning baserad på RAND-funktionen, med tanke på att funktionen skulle utvärderas separat per rad, som så:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();I praktiken utvärderas funktionen endast en gång för hela frågan; därför får alla rader samma resultat, och beställningen är helt opåverkad. Faktum är att om du kontrollerar planen för den här frågan ser du ingen sorteringsoperator. När jag körde den här frågan flera gånger fick jag samma resultat:
orderid ---------- 11008 11019 11039Frågan motsvarar faktiskt en utan en ORDER BY-klausul, där presentationsordning inte är garanterad. Så tekniskt sett är ordningen icke-deterministisk, och teoretiskt sett kan olika exekveringar resultera i olika ordningsföljder, och därmed i ett annat urval av topp 3 rader. Sannolikheten för detta är dock låg och du kan inte tänka dig att den här lösningen producerar tre slumpmässiga rader i varje exekvering.
Ett undantag från regeln att en icke-deterministisk funktion anropas en gång per referens i frågan är funktionen NEWID, som returnerar en globalt unik identifierare (GUID). När den används i en fråga är den här funktionen är åberopas separat per rad. Följande fråga visar detta:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;Den här frågan genererade följande utdata:
orderid mynewid ------------------ ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...Värdet på själva NEWID är ganska slumpmässigt. Om du använder CHECKSUM-funktionen ovanpå den får du ett heltalsresultat med en ännu bättre slumpmässig fördelning. Så ett sätt att få tre slumpmässiga beställningar är att använda en TOP-fråga med beställning baserad på CHECKSUM(NEWID()), som så:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());Kör den här frågan upprepade gånger och märk att du får en annan uppsättning med tre slumpmässiga beställningar varje gång. Jag fick följande utdata i en exekvering:
orderid ---------- 11031 10330 10962Och följande utdata i en annan körning:
orderid ---------- 10308 10885 10444Förutom NEWID, vad händer om du behöver använda en icke-deterministisk funktion som SYSDATETIME i en fråga, och du behöver den utvärderas separat per rad? Ett sätt att uppnå detta är att använda en användardefinierad funktion (UDF) som anropar den icke-deterministiska funktionen, som så:
SKAPA ELLER ÄNDRA FUNKTION dbo.MySysDateTime() RETURNERAR DATETIME2 AS BEGIN RETURN SYSDATETIME(); SLUTET; GÅDu anropar sedan UDF i frågan som så (kalla det Query 5):
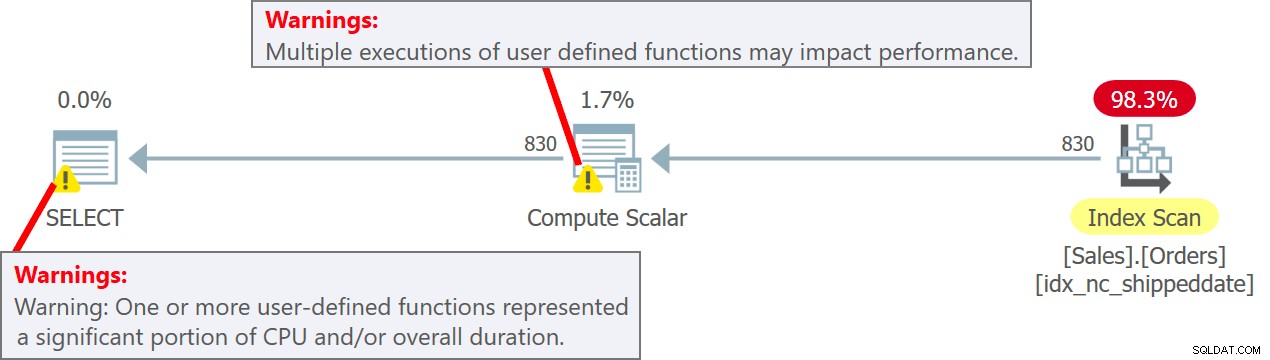
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;UDF exekveras per rad den här gången. Du måste dock vara medveten om att det finns en ganska skarp prestationsstraff förknippad med exekvering per rad av UDF. Dessutom är att anropa en skalär T-SQL UDF en parallellismhämmare.
Planen för denna fråga visas i figur 5.
Figur 5:Plan för fråga 5Lägg märke till i planen att UDF verkligen anropas per källrad i Compute Scalar-operatorn. Lägg också märke till att SentryOne Plan Explorer varnar dig om den potentiella prestationsstraffen som är förknippad med användningen av UDF både i Compute Scalar-operatorn och i planens rotnod.
Jag fick följande utdata från körningen av den här frågan:
orderid mydt ------------------ -------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-200:2019-200:2019-200:2019-2019-2019-2019-2019-2019-2019-201-20-1 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421212-02-04 17:07:03.03.303.30303033 .. .Observera att utdataraderna har flera olika datum- och tidsvärden i mydt-kolumnen.
Du kanske har hört att SQL Server 2019 tar itu med det vanliga prestandaproblemet som orsakas av skalära T-SQL UDF:er genom att infoga sådana funktioner. UDF måste dock uppfylla en lista med krav för att vara inlineable. Ett av kraven är att UDF inte anropar någon icke-deterministisk inneboende funktion såsom SYSDATETIME. Anledningen till detta krav är att du kanske skapade UDF exakt för att få en exekvering per rad. Om UDF blev infogat, skulle den underliggande icke-deterministiska funktionen exekveras endast en gång för hela frågan. Faktum är att planen i figur 5 genererades i SQL Server 2019, och du kan tydligt se att UDF inte blev infogat. Det beror på användningen av den icke-deterministiska funktionen SYSDATETIME. Du kan kontrollera om en UDF är inlineable i SQL Server 2019 genom att fråga attributet is_inlineable i vyn sys.sql_modules, så här:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Den här koden genererar följande utdata som talar om att UDF MySysDateTime inte är inlineable:
is_inlineable ------------ 0För att demonstrera en UDF som är inlinebar, här är definitionen av en UDF som heter EndOfyear som accepterar ett inmatningsdatum och returnerar respektive slutdatum:
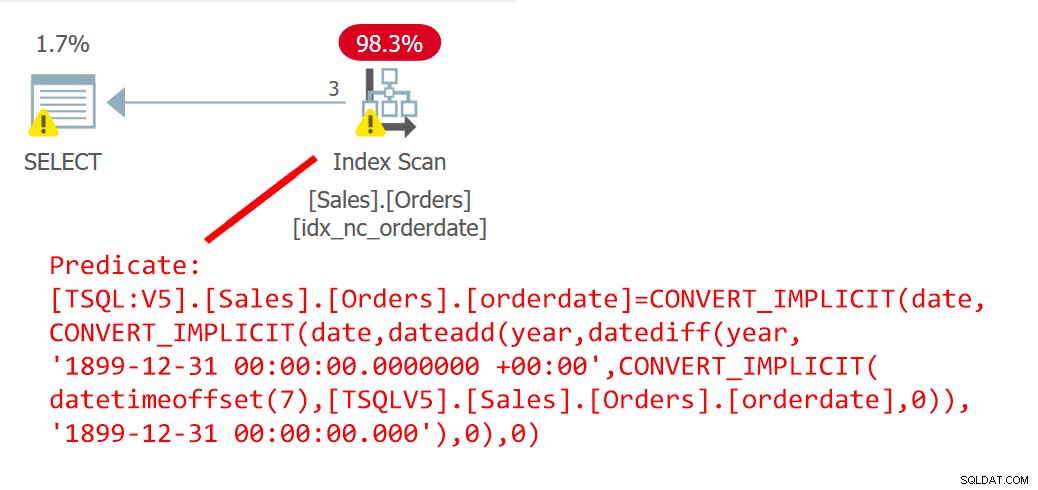
SKAPA ELLER ÄNDRA FUNKTION dbo.EndOfYear(@dt AS DATE) RETURNERS DATE AS BEGIN RETURN DATEADD(år, DATEDIFF(år, '18991231', @dt), '18991231'); SLUTET; GÅDet finns ingen användning av icke-deterministiska funktioner här, och koden uppfyller även de andra kraven för inlining. Du kan verifiera att UDF är inlineable genom att använda följande kod:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Denna kod genererar följande utdata:
is_inlineable ------------ 1Följande fråga (kalla det Query 6) använder UDF EndOfYear för att filtrera beställningar som gjordes vid ett årsslutsdatum:
SELECT orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Planen för denna fråga visas i figur 6.
Figur 6:Plan för fråga 6Planen visar tydligt att UDF blev inbyggd.
Tabelluttryck, icke-determinism och flera referenser
Som nämnts anropas icke-deterministiska funktioner som SYSDATETIME en gång per referens i en fråga. Men vad händer om du refererar till en sådan funktion en gång i en fråga i ett tabelluttryck som en CTE, och sedan har en yttre fråga med flera referenser till CTE? Många människor inser inte att varje referens till tabelluttrycket utökas separat, och den infogade koden resulterar i flera referenser till den underliggande icke-deterministiska funktionen. Med en funktion som SYSDATETIME, beroende på den exakta tidpunkten för var och en av körningarna, kan du få olika resultat för var och en. Vissa människor tycker att detta beteende är överraskande.
Detta kan illustreras med följande kod:
DECLARE @i AS INT =1, @rc AS INT =NULL; WHILE 1 =1 BEGIN; MED C1 AS ( VÄLJ SYSDATETIME() SOM dt ), C2 AS ( VÄLJ dt FRÅN C1 UNION VÄLJ dt FRÅN C1 ) VÄLJ @rc =COUNT(*) FRÅN C2; OM @rc> 1 BREAK; SET @i +=1; SLUTET; VÄLJ @rc AS distinkta värden, @i AS iterationer;Om båda referenserna till C1 i frågan i C2 representerade samma sak, skulle denna kod ha resulterat i en oändlig loop. Men eftersom de två referenserna utökas separat, när timingen är sådan att varje anrop sker i ett annat 100-nanosekundersintervall (precisionen för resultatvärdet), resulterar föreningen i två rader, och koden bör bryta från slinga. Kör den här koden och se själv. Efter några upprepningar går den sönder. Jag fick följande resultat i en av avrättningarna:
distinkta värden iterationer -------------------- ---------- 2 448Det bästa är att undvika att använda tabelluttryck som CTE och vyer, när den inre frågan använder icke-deterministiska beräkningar och den yttre frågan hänvisar till tabelluttrycket flera gånger. Det är naturligtvis såvida du inte förstår konsekvenserna och du är okej med dem. Alternativa alternativ kan vara att bevara det inre frågeresultatet, t.ex. i en temporär tabell, och sedan fråga den tillfälliga tabellen hur många gånger som helst.
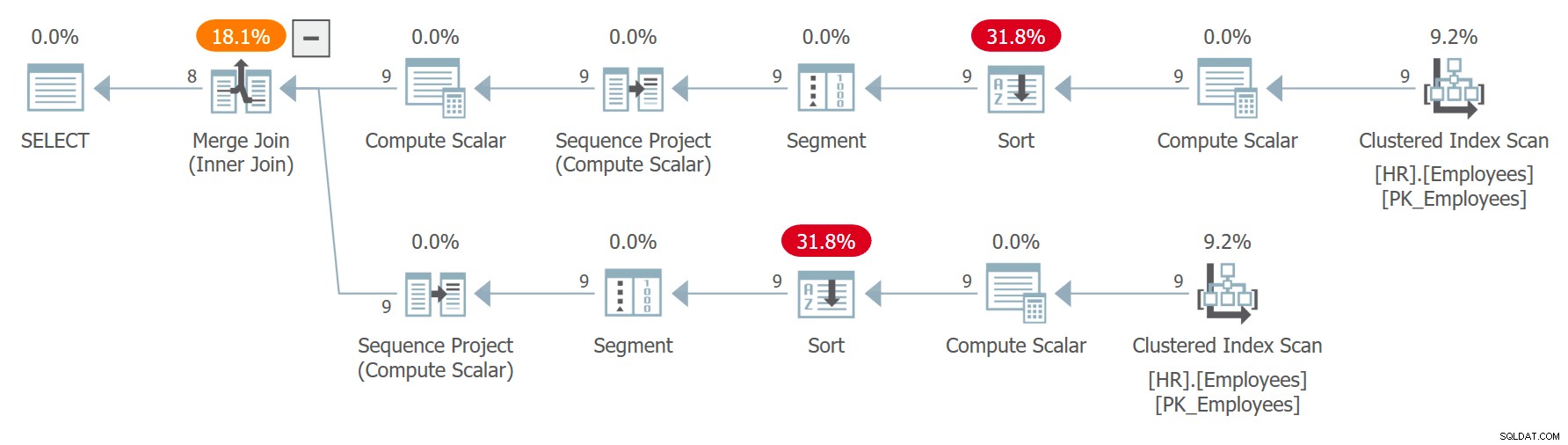
För att visa exempel där att du inte följer den bästa praxisen kan få dig i problem, anta att du behöver skriva en fråga som parar anställda från tabellen HR.Employees slumpmässigt. Du kommer på följande fråga (kalla den fråga 7) för att hantera uppgiften:
MED C AS ( VÄLJ empid, förnamn, efternamn, ROW_NUMBER() ÖVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) VÄLJ C1.empid AS empid1, C1.firstname AS firstname1, C1. efternamn AS efternamn1, C2.empid AS empid2, C2.förnamn AS förnamn2, C2.efternamn AS efternamn2 FRÅN C AS C1 INNER JOIN C AS C2 PÅ C1.n =C2.n + 1;Planen för denna fråga visas i figur 7.
Figur 7:Plan för fråga 7Observera att de två referenserna till C utökas separat, och att radnumren beräknas oberoende för varje referens ordnad efter oberoende anrop av uttrycket CHECKSUM(NEWID()). Det betyder att samma anställd inte är garanterad att få samma radnummer i de två utökade referenserna. Om en anställd får radnummer x i C1 och radnummer x – 1 i C2, kopplar frågan ihop medarbetaren med honom eller henne själv. Till exempel fick jag följande resultat i en av avrättningarna:
empid1 förnamn1 efternamn1 empid2 förnamn2 efternamn2 ----------- ---------- -------------------- ---------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russell King ***Observera att det finns tre fall här av självpar. Detta är lättare att se genom att lägga till ett filter i den yttre frågan som specifikt letar efter självpar, som så:
MED C AS ( VÄLJ empid, förnamn, efternamn, ROW_NUMBER() ÖVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) VÄLJ C1.empid AS empid1, C1.firstname AS firstname1, C1. efternamn AS efternamn1, C2.empid AS empid2, C2.firstname AS fornamn2, C2.efternamn AS efternamn2 FRÅN C AS C1 INNER JOIN C AS C2 PÅ C1.n =C2.n + 1 WHERE C1.empid =C2.empid;Du kan behöva köra den här frågan ett antal gånger för att se problemet. Här är ett exempel på resultatet som jag fick i en av avrättningarna:
empid1 förnamn1 efternamn1 empid2 förnamn2 efternamn2 ----------- ---------- -------------------- ---------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkEnligt bästa praxis är ett sätt att lösa detta problem att bevara det inre frågeresultatet i en temporär tabell och sedan efterfråga flera instanser av den temporära tabellen efter behov.
Ett annat exempel illustrerar buggar som kan vara resultatet av användningen av icke-deterministisk ordning och flera referenser till ett tabelluttryck. Anta att du behöver fråga tabellen Sales.Orders och för att göra trendanalys vill du para ihop varje order med nästa baserat på orderdatum. Din lösning måste vara kompatibel med pre-SQL Server 2012-system vilket innebär att du inte kan använda de uppenbara LAG/LEAD-funktionerna. Du bestämmer dig för att använda en CTE som beräknar radnummer för att positionera rader baserat på orderdatumsordning och sedan sammanfoga två instanser av CTE, parar order baserat på en offset på 1 mellan radnumren, som så (kalla denna fråga 8):
MED C AS ( SELECT *, ROW_NUMBER() ÖVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) VÄLJ C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FRÅN C AS C1 VÄNSTER YTTRE JOIN C AS C2 PÅ C1.n =C2.n + 1;Planen för denna fråga visas i figur 8.
Figur 8:Plan för fråga 8
Radnummerordningen är inte deterministisk eftersom orderdatum inte är unikt. Observera att de två referenserna till CTE utökas separat. Märkligt nog, eftersom frågan letar efter en annan delmängd av kolumner från var och en av instanserna, beslutar optimeraren att använda ett annat index i varje fall. I ett fall använder den en ordnad bakåtsökning av indexet på orderdatum, vilket effektivt skannar rader med samma datum baserat på orderid fallande ordning. I det andra fallet skannar den det klustrade indexet, ordnat falskt och sorterar sedan, men effektivt bland rader med samma datum kommer den åt raderna i stigande ordning. Det beror på liknande resonemang som jag gav i avsnittet om icke-deterministisk ordning tidigare. Detta kan resultera i att samma rad får radnummer x i en instans och radnummer x – 1 i den andra instansen. I ett sådant fall kommer anslutningen att matcha en beställning med sig själv istället för med nästa som den borde.
Jag fick följande resultat när jag körde den här frågan:
orderid1 orderdate1 custid1 orderid2 orderdate2 ---------- ---------- ---------- ---------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 5-107 *** 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 110973 110973 5 20-10 20-1 20-1 20-1 05 *** ...Observera självmatcherna i resultatet. Återigen, problemet kan lättare identifieras genom att lägga till ett filter som letar efter självmatchningar, som så:
MED C AS ( SELECT *, ROW_NUMBER() ÖVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) VÄLJ C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 FRÅN C AS C1 VÄNSTER YTTRE JOIN C AS C2 PÅ C1.n =C2.n + 1 WHERE C1.orderid =C2.orderid;Jag fick följande utdata från den här frågan:
orderid1 orderdate1 custid1 orderid2 orderdate2 ---------- ---------- ---------- ---------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 60 2019-04-30 60 20 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...Den bästa praxisen här är att se till att du använder unik ordning för att garantera determinism genom att lägga till en tiebreaker som orderid till fönsterordningsklausulen. Så även om du har flera referenser till samma CTE, kommer radnumren att vara desamma i båda. Om du vill undvika att beräkningarna upprepas kan du också överväga att bevara det inre frågeresultatet, men då måste du överväga den extra kostnaden för sådant arbete.
CASE/NULLIF och icke-deterministiska funktioner
När du har flera referenser till en icke-deterministisk funktion i en fråga, utvärderas varje referens separat. Vad som kan vara förvånande och till och med resultera i buggar är att du ibland skriver en referens, men implicit omvandlas den till flera referenser. Så är situationen med vissa användningar av CASE-uttrycket och IIF-funktionen.
Tänk på följande exempel:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Jämn' WHEN 1 THEN 'Oud' END;Här är resultatet av det testade uttrycket ett icke-negativt heltalsvärde, så klart att det måste vara antingen jämnt eller udda. Det kan inte vara varken jämnt eller udda. Men om du kör den här koden tillräckligt många gånger kommer du ibland att få en NULL som indikerar att den underförstådda ELSE NULL-satsen i CASE-uttrycket var aktiverad. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Slutsats
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!