Indexerade vyer kan skapas i alla utgåvor av SQL Server, men det finns ett antal beteenden att vara medveten om om du vill få ut det mesta av dem.
Automatisk statistik kräver en NOEXPAND-tips
SQL Server kan skapa statistik automatiskt för att hjälpa till med kardinalitetsuppskattning och kostnadsbaserat beslutsfattande under frågeoptimering. Den här funktionen fungerar med indexerade vyer såväl som bastabeller, men bara om vyn är uttryckligen namngiven i frågan och NOEXPAND ledtråd anges. (Det finns alltid ett statistikobjekt kopplat till varje index på en vy, det är den automatiska genereringen och underhållet av statistik som inte är associerad med ett index som vi talar om här.)
Om du är van vid att arbeta med icke-Enterprise-utgåvor av SQL Server, kanske du aldrig har märkt detta beteende tidigare. Lägre upplagor av SQL Server kräver NOEXPAND tips för att skapa en frågeplan som får åtkomst till en indexerad vy. När NOEXPAND anges skapas automatisk statistik på indexerade vyer precis som med vanliga tabeller.
Exempel – Standardversion med NOEXPAND
Med hjälp av SQL Server 2012 Standard Edition och exempeldatabasen Adventure Works skapar vi först en vy som sammanfogar två försäljningstabeller och beräknar total orderkvantitet per kund och produkt:
SKAPA VY dbo.CustomerOrdersWITH SCHEMABINDING ASSELECT SOH.CustomerID, SOD.ProductID, OrderQual =SUM(SOD.OrderQty), NumRows =COUNT_BIG(*)FROM Sales.SalesOrderDetail AS SODJOIN Sales.SalesOrderONSOD.SalesOrderON .SalesOrderIDGROUP BY SOH.CustomerID, SOD.ProductID;
För att den här vyn ska stödja statistik måste vi materialisera den genom att lägga till ett unikt klustrat index. Kombinationen av kund- och produkt-ID är garanterat unik i vyn (per definition) så vi kommer att använda det som nyckeln. Vi skulle kunna specificera de två kolumnerna åt båda hållen i indexet, men om vi antar att vi förväntar oss att fler frågor ska filtreras efter produkt, gör vi Produkt-ID till den ledande kolumnen. Den här åtgärden skapar också indexstatistik, med ett histogram byggt från produkt-ID-värden.
SKAPA UNIKT CLUSTERED INDEX cuq PÅ dbo.CustomerOrders (ProductID, CustomerID);
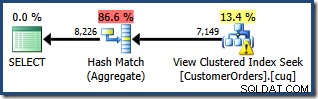
Vi ombeds nu att skriva en fråga som visar den totala mängden beställningar per kund, för ett visst sortiment av produkter. Vi förväntar oss att en exekveringsplan som använder den indexerade vyn kommer att vara en effektiv strategi, eftersom den kommer att undvika en sammanfogning och arbeta på data som redan är delvis aggregerad. Eftersom vi använder SQL Server Standard Edition måste vi ange vyn explicit och använda en NOEXPAND tips för att skapa en frågeplan som får åtkomst till den indexerade vyn:
VÄLJ CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS CO WITH (NOEXPAND)WHERE CO.ProductID MELLAN 711 OCH 718GROUP BY CO.CustomerID;
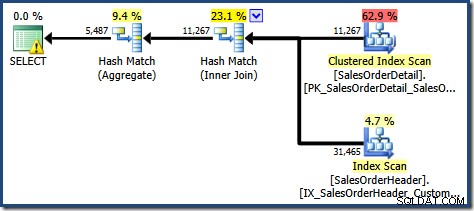
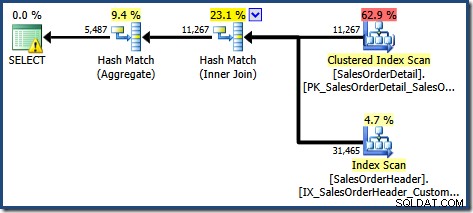
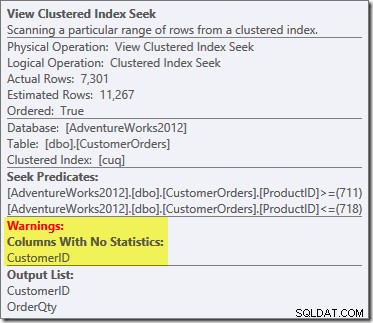
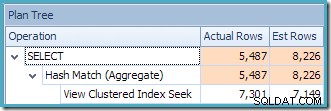
Den framställda exekveringsplanen visar en sökning i den indexerade vyn för att hitta rader för produkterna av intresse följt av en aggregering för att beräkna den totala kvantiteten per kund:
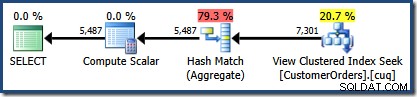
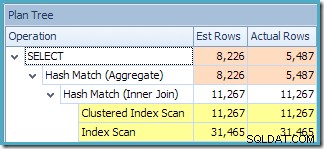
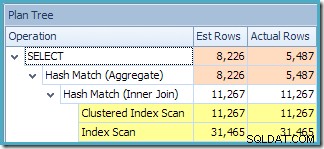
Planträdvyn i SQL Sentry Plan Explorer visar att kardinalitetsuppskattningen är exakt korrekt för den indexerade vysökningen och mycket bra för resultatet av aggregatet:
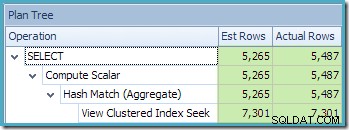
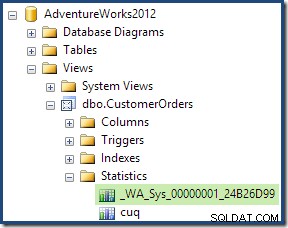
Som en del av kompileringen och optimeringsprocessen för den här frågan skapade SQL Server ytterligare ett statistikobjekt i kolumnen Kund-ID i den indexerade vyn. Denna statistik är byggd eftersom det förväntade antalet och fördelningen av kund-ID:n kan vara viktig, till exempel vid val av en aggregeringsstrategi. Vi kan se den nya statistiken med Management Studio Object Explorer:
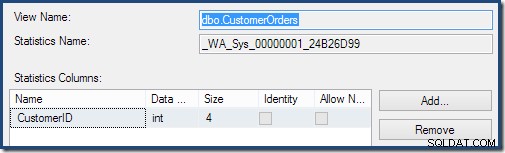
Dubbelklicka på statistikobjektet bekräftar att det byggdes från kolumnen Kund-ID i vyn (inte en bastabell):
Indexerade vyer kan förbättra kardinalitetsuppskattningen
Fortfarande använder vi Standard Edition, vi släpper och återskapar nu den indexerade vyn (vilket också tappar visningsstatistiken) och kör frågan igen, denna gång med NOEXPAND tips kommenterade:
VÄLJ CO.CustomerID, SUM(CO.OrderQuty)FROM dbo.CustomerOrders AS CO --WITH (NOEXPAND)WHERE CO.ProductID MELLAN 711 OCH 718GROUP BY CO.CustomerID;
Som förväntat när du använder Standard Edition utan NOEXPAND , den resulterande frågeplanen fungerar på bastabellerna snarare än vyn direkt:

Varningstriangeln på rotoperatören i planen ovan varnar oss för ett potentiellt användbart index i tabellen Sales Order Detail, vilket inte är viktigt för våra nuvarande syften. Denna sammanställning skapar ingen statistik på den indexerade vyn. Den enda statistiken på vyn efter frågekompilering är den som är kopplad till det klustrade indexet:
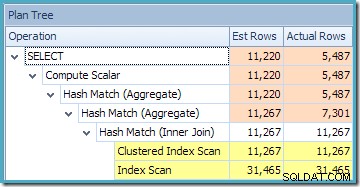
Planträdsvyn för frågan visar att kardinalitetsuppskattningen är korrekt för de två tabellskanningarna och sammanfogningen, men ganska lite sämre för de andra planoperatörerna:
Använder den indexerade vyn med en NOEXPAND ledtråd resulterade i mer exakta uppskattningar för vår testfråga eftersom bättre kvalitetsinformation var tillgänglig från statistik om vyn – i synnerhet statistiken som är kopplad till vyindexet.
Som en allmän regel försämras noggrannheten hos statistisk information ganska snabbt när den passerar och modifieras av frågeplansoperatörer. Enkla sammanfogningar är ofta inte så dåliga i detta avseende, men information om resultatet av en aggregering är ofta inte bättre än en välgrundad gissning. Att förse frågeoptimeraren med mer exakt information med hjälp av statistik om indexerade vyer kan vara en användbar teknik för att öka planernas kvalitet och robusthet.
En vy utan NOEXPAND kan ge en sämre plan
Frågeplanen som visas ovan (Standard Edition, utan NOEXPAND ) är faktiskt mindre optimal än om vi själva hade skrivit frågan mot bastabellerna, snarare än att tillåta frågeoptimeraren att utöka vyn. Frågan nedan uttrycker samma logiska krav, men refererar inte till vyn:
VÄLJ SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProduktID MELLAN 711 OCH 718GROUP. BY SOHID;Denna fråga producerar följande exekveringsplan:
Den här planen har en aggregeringsoperation mindre än tidigare. När vyexpansion användes kunde frågeoptimeraren tyvärr inte ta bort en redundant aggregeringsoperation, vilket resulterade i en mindre effektiv exekveringsplan. Den slutliga kardinalitetsuppskattningen för den nya frågan är också något bättre än när den indexerade vyn refererades utan
NOEXPAND:
Ändå är de bästa uppskattningarna fortfarande de som produceras när man refererar till den indexerade vyn med
NOEXPAND(upprepas nedan för enkelhetens skull):
Enterprise Edition och visningsmatchning
På en Enterprise Edition-instans kan frågeoptimeraren använda en indexerad vy även om frågan inte nämner vyn explicit. Om optimeraren kan matcha en del av frågeträdet med en indexerad vy, kan den välja att göra det, baserat på sin uppskattning av kostnaderna för att använda vyn eller inte. Visningsmatchningslogiken är ganska smart, men den har gränser som är ganska lätta att nå i praktiken. Även där visningsmatchning lyckas, kan optimeraren fortfarande vilseledas av felaktiga kostnadsuppskattningar.
Frågetipset EXPAND VIEWS
Börja med de sällsynta av möjligheterna, det kan finnas tillfällen där en fråga refererar till en indexerad vy, men en bättre plan skulle erhållas genom att gå till bastabellerna istället. Under dessa omständigheter ger frågetipset
EXPAND VIEWSkan användas:VÄLJ CO.CustomerID, SUM(CO.OrderQty)FROM dbo.CustomerOrders AS COWHERE CO.ProductID MELLAN 711 OCH 718GROUP BY CO.CustomerIDOPTION (EXPANDA VYER);På Enterprise Edition producerar den här frågan samma plan som i Standard Edition när
NOEXPANDledtråd uteslöts (inklusive den redundanta aggregeringsoperationen):
Till skillnad från
EXPAND VIEWSantydan är dåligt namngiven, enligt min mening. SQL Server expanderar alltid vydefinitioner i en fråga om inteNOEXPANDledtråd anges.EXPAND VIEWShint inaktiverar regler i optimeraren som kan matcha delar av det utökade trädet tillbaka till indexerade vyer. I avsaknad av någon ledtråd utökar SQL Server först en vy till dess bastabelldefinition och överväger sedan att matcha tillbaka till indexerade vyer. Ett bättre namn förEXPAND VIEWSledtråd kan ha varitDISABLE INDEXED VIEW MATCHING, för det är vad den gör.
EXPAND VIEWSledtråd används förmodligen oftast för att förhindra att en fråga mot bastabeller matchas till en indexerad vy:VÄLJ SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProduktID MELLAN 711 OCH 718OPGRUPP VID SOHP OCH 718OPGRUPP VID SOH;>Frågetipset resulterar i samma exekveringsplan och uppskattningar som vi såg när vi använde Standard Edition och samma fråga endast för bastabell:
Enterprise View Matchning och statistik
Även i Enterprise Edition skapas fortfarande icke-indexvystatistik bara om
NOEXPANDledtråd används. För att vara helt tydlig med det, resulterar funktionen för endast Enterprise-visningsmatchning aldrig i att vystatistik skapas eller uppdateras. Detta ointuitiva beteende är värt att utforska lite, eftersom det kan ha överraskande biverkningar.Vi kör nu vår grundläggande fråga mot vyn på en Enterprise Edition-instans, utan några tips:
VÄLJ CO.CustomerID, SUM(CO.OrderQuty)FROM dbo.CustomerOrders AS COWHERE CO.ProductID MELLAN 711 OCH 718GROUP BY CO.CustomerID;
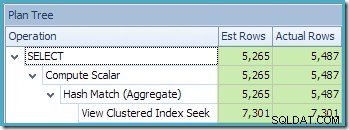
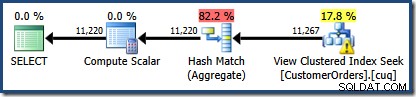
En ny sak där är varningstriangeln på View Clustered Index Seek. Verktygstipset visar detaljerna:
Vi använde inte en
NOEXPANDtips, så statistik i kolumnen Kund-ID i den indexerade vyn skapades inte automatiskt. Statistiken om kund-ID är faktiskt inte särskilt viktig i detta förenklade exempel, men det kommer inte alltid att vara fallet.Kurious Cardinality Estimations
Det andra av intresse är att kardinalitetsuppskattningarna verkar vara sämre än något fall vi har stött på hittills, inklusive standardversionsexemplen.
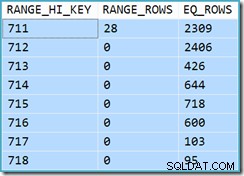
Det är initialt svårt att se var kardinalitetsuppskattningen för View Clustered Index Seek (11 267) kom ifrån. Vi förväntar oss att uppskattningen baseras på produkt-ID-histograminformation från statistiken som är kopplad till vyklustrade index. Den relevanta delen av detta histogram visas nedan:
DBCC SHOW_STATISTICS ('dbo.CustomerOrders', 'cuq') MED HISTOGRAM;
Med tanke på att tabellen inte har ändrats sedan statistiken skapades, skulle vi förvänta oss att uppskattningen är en enkel summa av RANGE_ROWS och EQ_ROWS för produkt-ID-värden mellan 711 och 718 (observera att uppskattningen bör exkludera de 28 RANGE_ROWS som visas mot 711-posten eftersom dessa rader finns under nyckelvärdet 711). Summan av EQ_ROWS som visas är 7 301. Detta är exakt antalet rader som faktiskt returneras av vyn – så var kom uppskattningen på 11 267 ifrån?
Svaret ligger i hur vymatchning fungerar för närvarande. Vår fråga specificerade inte
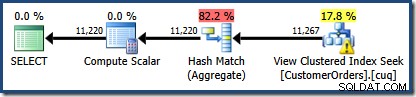
NOEXPANDledtråd, så initiala kardinalitetsuppskattningar baseras på det vyexpanderade frågeträdet. Detta är lättast att se genom att titta igen på den beräknade planen för samma fråga medEXPAND VIEWSspecificerat:
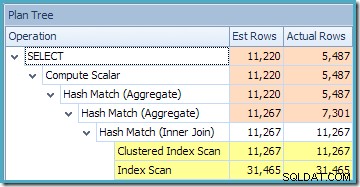
Det röda skuggade området representerar den del av trädet som ersätts av vymatchningsaktivitet. Utdatakardinaliteten från detta område är 11 267. Den oskuggade delen med uppskattningen på 11 220 påverkas inte av vymatchning. Det här är exakt de uppskattningar vi försökte förklara:
Vymatchning ersatte helt enkelt det rödskuggade området med en logiskt likvärdig sökning på den indexerade vyn. Den använde inte statistisk information från vyn för att räkna om kardinalitetsuppskattningen.
Till viss del kan du förmodligen förstå varför det kan fungera på det här sättet:i allmänhet finns det ingen anledning att förvänta sig att en uppskattning som beräknas från en uppsättning statistisk information är bättre än en annan. Man skulle kunna hävda att statistik över indexerade vyer är mer sannolikt att vara korrekta här, jämfört med statistik som härleds efter sammanfogning i det rödskuggade området, men det kan vara svårt att generalisera det, eller att korrekt redogöra för hur snabbt olika källor till statistisk information kan bli inaktuell när de underliggande uppgifterna ändras.
Man kan också hävda att om vi var så säkra på att den indexerade vyinformationen var bättre, skulle vi ha använt en
NOEXPANDledtråd.Ännu fler nyfikna kardinalitetsuppskattningar
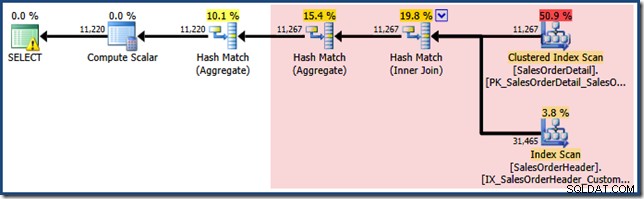
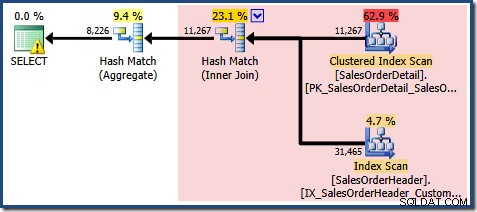
En ännu mer intressant situation uppstår med Enterprise Edition om vi skriver frågan mot bastabellerna och förlitar oss på automatisk vymatchning:
VÄLJ SOH.CustomerID, SUM(OrderQty)FROM Sales.SalesOrderHeader AS SOHJOIN Sales.SalesOrderDetail AS SOD PÅ SOD.SalesOrderID =SOH.SalesOrderIDWHERE SOD.ProduktID MELLAN 711 OCH 718GROUP. BY SOHID;
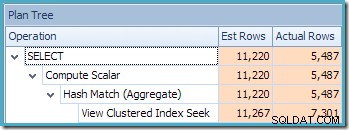
Den saknade statistikvarningen är densamma som tidigare och har samma förklaring. Den mer intressanta egenskapen är att vi nu har en lägre uppskattning för antalet rader som produceras av View Clustered Index Seek (7 149) och en ökad uppskattning för antalet rader som returneras från aggregeringen (8 226).
För att understryka poängen verkar den här frågeplanen vara baserad på idén att 7 149 källrader kan aggregeras för att producera 8 226 rader!
En del av förklaringen är densamma som tidigare.
EXPAND VIEWSfrågeplan, som visar det röda området som kommer att ersättas av vymatchning visas nedan:
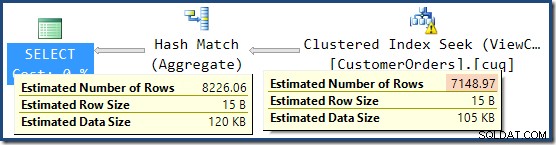
Detta förklarar var den slutliga uppskattningen på 8 226 kommer ifrån, men hur är det med uppskattningen på 7 149 rader? Enligt logiken som vi sett tidigare verkar det som att vyn borde visa en uppskattning av 11 267 rader?
Svaret är att uppskattningen på 7 149 är en gissning. Ja verkligen. Den indexerade vyn innehåller totalt 79 433 rader. Den magiska gissningsprocenten för predikatet Produkt-ID MELLAN är 9 % – vilket ger 0,09 * 79433 =7148,97 rader. SSMS-frågeplanen visar att denna beräkning är exakt korrekt, även före avrundning:
I den här situationen verkar SQL Server-optimeraren ha föredragit en gissning baserad på indexerad vykardinalitet framför uppskattningen av post-join-kardinalitet från det ersatta underträdet. Nyfiken.
Sammanfattning
Använda
NOEXPANDledtråd garanterar att en indexerad vy kommer att användas i den slutliga frågeplanen, och gör det möjligt att automatiskt skapa, underhålla och använda icke-indexstatistik av frågeoptimeraren. AnvänderNOEXPANDsäkerställer också att de initiala kardinalitetsuppskattningarna baseras på indexerad vyinformation snarare än att de härleds från bastabeller.Om
NOEXPANDär inte specificerad, ersätts vyreferenser alltid med deras bastabelldefinitioner innan frågekompileringen börjar (och därför före initial kardinalitetsuppskattning). Endast i Enterprise SKU:er kan indexerade vyer ersättas tillbaka i frågeträdet senare i optimeringsprocessen.
EXPAND VIEWSfrågetips hindrar optimeraren från att utföra indexerad vymatchning i Enterprise Edition. Detta gäller oavsett om frågan ursprungligen refererade till en indexerad vy eller inte. När vymatchning utförs kan en befintlig kardinalitetsuppskattning ersättas med en gissning under vissa omständigheter.Statistik som visas som saknad i en indexerad vy kan skapas manuellt, men optimeraren kommer i allmänhet inte att använda dem för frågor som inte använder en
NOEXPANDledtråd.Att använda indexerade vyer kan förbättra kardinalitetsuppskattningen, särskilt om vyn innehåller sammanfogningar eller aggregationer. Frågor har störst chans att dra nytta av mer exakt visningsstatistik om
NOEXPANDanges.