Det här inlägget är en del av en serie artiklar om radmål. Du hittar den första delen här:
- Del 1:Ställa in och identifiera radmål
Det är relativt välkänt att använda TOP eller en SNABB n frågetips kan ställa in ett radmål i en exekveringsplan (se Ställa in och identifiera radmål i exekveringsplaner om du behöver en uppfräschning om radmål och deras orsaker). Det är ganska mindre vanligt att semi joins (och anti joins) också kan introducera ett radmål, även om detta är något mindre troligt än vad som är fallet för TOPP , SNABB och STÄLL IN RADANTAL .
Den här artikeln hjälper dig att förstå när och varför en semi-join anropar optimerarens radmålslogik.
Semi går med
En semi-join returnerar en rad från en join-ingång (A) om det finns minst en matchande rad på den andra joiningången (B).
De väsentliga skillnaderna mellan en semi join och en vanlig join är:
- Semi-join returnerar antingen varje rad från ingång A, eller så gör den inte det. Ingen radduplicering kan förekomma.
- Vanlig sammanfogning dubblerar rader om det finns flera matchningar på sammanfogningspredikatet.
- Semi-join är definierad för att endast returnera kolumner från ingång A.
- Vanlig koppling kan returnera kolumner från endera (eller båda) kopplingsingångar.
T-SQL saknar för närvarande stöd för direkt syntax som FRÅN EN SEMI JOIN B PÅ A.x =B.y , så vi måste använda indirekta former som EXISTS , NÅGRA/NÅGON (inklusive motsvarande förkortning IN för jämlikhetsjämförelser) och ställ in INTERSECT .
Beskrivningen av en semi-join ovan antyder naturligtvis tillämpningen av ett radmål, eftersom vi är intresserade av att hitta valfri matchande rad i B, inte alla sådana rader . Ändå kanske en logisk semi-join uttryckt i T-SQL inte leder till en exekveringsplan som använder ett radmål av flera skäl, som vi kommer att packa upp härnäst.
Omvandling och förenkling
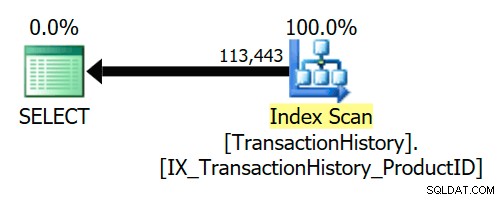
En logisk semi-join kan förenklas bort eller ersättas med något annat under frågekompilering och optimering. AdventureWorks-exemplet nedan visar en semi-join som tas bort helt på grund av en pålitlig främmande nyckelrelation:
VÄLJ TH.ProductID FROM Production.TransactionHistory SOM THWHERE TH.ProductID IN( SELECT P.ProductID FROM Production.Product AS P);
Den främmande nyckeln säkerställer att Produkt rader kommer alltid att finnas för varje historikrad. Som ett resultat får exekveringsplanen endast åtkomst till TransactionHistory tabell:
Ett vanligare exempel ses när semi-kopplingen kan omvandlas till en inre koppling. Till exempel:
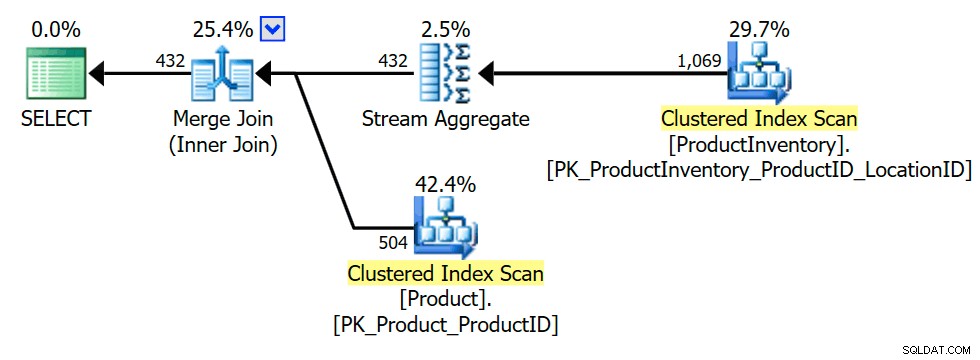
SELECT P.ProductID FROM Production.Product AS P WHERE EXISTS( SELECT * FROM Production.ProductInventory AS INV WHERE INV.ProductID =P.ProductID);
Utförandeplanen visar att optimeraren introducerade ett aggregat (gruppering på INV.ProductID ) för att säkerställa att den inre kopplingen endast kan returnera Produkt rader en gång eller inte alls (som krävs för att bevara semantik som semantik):
Omvandlingen till inre koppling undersöks tidigt eftersom optimeraren kan fler knep för inre equijoins än för semi-joins, vilket potentiellt leder till fler optimeringsmöjligheter. Naturligtvis är det slutliga planvalet fortfarande ett kostnadsbaserat beslut bland de utforskade alternativen.
Tidiga optimeringar
Även om T-SQL saknar direkt SEMI JOIN syntax, optimeraren vet allt om semi-anslutningar inbyggt och kan manipulera dem direkt. Den vanliga lösningen för semi-join-syntaxer omvandlas till en "riktig" intern semi-join tidigt i frågekompileringsprocessen (långt innan ens en trivial plan övervägs).
De två huvudsakliga alternativa syntaxgrupperna är EXISTS/INTERSECT , och NÅGON/NÅGON/IN . FINNS och INTERSECT fall skiljer sig endast genom att det senare kommer med en implicit DISTINCT (gruppering på alla projicerade kolumner). Båda FINNS och INTERSECT tolkas som en EXISTS med korrelerad underfråga.
Till exempel kan den semi-join vi har använt hittills också skrivas med IN :
VÄLJ P.ProductIDFROM Production.Product AS PWHERE P.ProductID IN /* eller =NÅGOT/NÅGRA */( VÄLJ TH.ProductIDFROM Production.TransactionHistory AS TH)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON1);<8621); /pre>Optimeringsinmatningsträdet är som följer:
Den skalära operatorn ScaOp_SomeComp är
SOMEjämförelse som nämnts ovan. 2:an är koden för ett likhetstest, eftersomINmotsvarar=SOME. Om du är intresserad finns det koder från 1 till 6 som representerar (<, =, <=,>, !=,>=) respektive jämförelseoperatorer.Återgår till
EXISTSsyntax som jag föredrar att använda oftast för att uttrycka en semi-join indirekt:SELECT P.ProductIDFROM Production.Product AS PWHERE EXISTS( SELECT * FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);Optimeringsinmatningsträdet är:
Det trädet är en ganska direkt översättning av frågetexten; Observera dock att
SELECT *har redan ersatts av en projektion av det konstanta heltalsvärdet 1 (se näst sista textraden).Nästa sak som optimeraren gör är att avinstallera underfrågan i det relationella urvalet (=filter) med hjälp av regeln RemoveSubqInSel . Optimeraren gör alltid detta, eftersom den inte kan arbeta direkt på underfrågor. Resultatet är en ansök (a.k.a korrelerad eller lateral sammanfogning):
(Samma regel för borttagning av underfråga ger samma utdata för
SOMEinmatningsträd också).Nästa steg är att skriva om ansökan som en vanlig anslutning med ApplyHandler härska familjen. Detta är något som optimeraren alltid försöker göra, eftersom den har fler utforskningsregler för anslutningar än vad den gör för att tillämpa. Alla ansökningar kan inte skrivas om som en anslutning, men det aktuella exemplet är enkelt och lyckas:
Notera att typen av sammanfogning är vänster semi. Detta är faktiskt exakt samma träd som vi skulle få omedelbart om T-SQL stödde syntax som:
VÄLJ P.ProductID FRÅN Production.Product SOM VÄNSTER SEMI JOIN Production.TransactionHistory AS TH ON TH.ProductID =P.ProductID;Det skulle vara trevligt att kunna uttrycka frågor mer direkt på det här sättet. Hur som helst, den intresserade läsaren uppmuntras att utforska ovanstående förenklingsaktiviteter med andra logiskt likvärdiga sätt att skriva denna semi-join i T-SQL.
Det viktiga i detta skede är att optimeraren alltid tar bort underfrågor , ersätter dem med en applicera. Den försöker sedan skriva om ansökan som en vanlig join för att maximera chanserna att hitta en bra plan. Kom ihåg att allt det föregående äger rum innan ens en trivial plan övervägs. Under kostnadsbaserad optimering kan optimeraren också överväga att gå tillbaka till en applicering.
Hash and Merge Semi Join
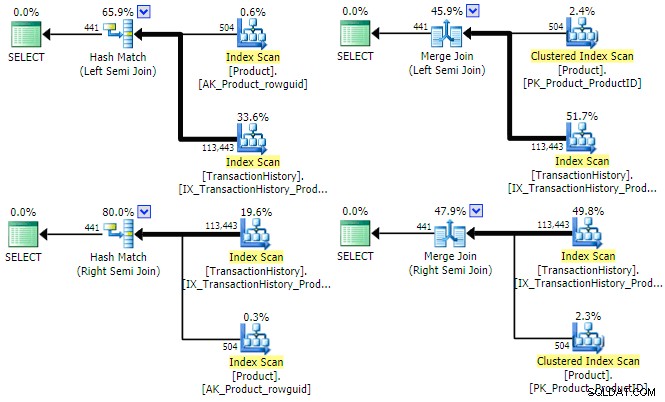
SQL Server har tre huvudsakliga fysiska implementeringsalternativ tillgängliga för en logisk semi-join. Så länge som ett equijoin-predikat finns, är hash och merge join tillgängliga; båda kan fungera i vänster- och höger-semijoin-lägen. Kapslade loops-join stöder endast vänster (inte höger) semi-join, men kräver inget equijoin-predikat. Låt oss titta på hashen och slå samman fysiska alternativ för vår exempelfråga (skriven som en uppsättning skär den här gången):
SELECT P.ProductID FROM Production.Product AS PINTERSECTSELECT TH.ProductID FROM Production.TransactionHistory AS TH;Optimeraren kan hitta en plan för alla fyra kombinationerna av (vänster/höger) och (hash/sammanfogning) semi-join för denna fråga:
Det är värt att kort nämna varför optimeraren kan överväga både vänster- och högerhalvanslutningar för varje sammanfogningstyp. För hash semi join är en viktig kostnadsövervägande den uppskattade storleken på hashtabellen, som alltid är den vänstra (övre) ingången initialt. För merge semi join, bestämmer egenskaperna för varje ingång om en en-till-många eller mindre effektiv många-till-många sammanfogning med arbetstabell kommer att användas.
Det kan vara uppenbart från exekveringsplanerna ovan att varken hash eller merge semi join skulle tjäna på att sätta ett radmål . Båda jointyperna testar alltid joinpredikatet vid själva joinen och syftar till att konsumera alla rader från båda ingångarna för att returnera en fullständig resultatuppsättning. Det betyder inte att prestandaoptimeringar inte existerar för hash och merge join i allmänhet – till exempel kan båda använda bitmappar för att minska antalet rader som når sammanfogningen. Snarare är poängen att ett radmål på någon av ingångarna inte skulle göra en hash- eller sammanfogad semi-join mer effektiv.
Inkapslade loopar och applicera Semi Join
Den återstående fysiska kopplingstypen är kapslade loopar, som finns i två varianter:vanliga (okorrelerade) kapslade loopar och applicera kapslade loopar (ibland även kallade korrelerade eller lateral gå med).
Vanliga kapslade loops join liknar hash och merge join genom att join-predikatet utvärderas vid join. Som tidigare betyder detta att det inte finns något värde i att sätta ett radmål på någon av ingångarna. Den vänstra (övre) ingången kommer alltid att förbrukas helt så småningom, och den inre ingången har inget sätt att bestämma vilken eller vilka rader som ska prioriteras, eftersom vi inte kan veta om en rad kommer att gå med eller inte förrän predikatet testas vid sammanfogningen .
Däremot har en applicera kapslad loop-join en eller flera yttre referenser (korrelerade parametrar) vid join, med join-predikatet nedtryckt den inre (nedre) sidan av fogen. Detta skapar en möjlighet för användbar tillämpning av ett radmål. Kom ihåg att en semi-join bara kräver att vi kontrollerar förekomsten av en rad på join-ingång B som matchar den aktuella raden på join-ingång A (tänker bara på kapslade loops join-strategier nu).
Med andra ord, vid varje iteration av en applicering kan vi sluta titta på ingång B så snart den första matchningen hittas, med hjälp av det nedtryckta join-predikatet. Det är precis sånt här ett radmål är bra för:generera en del av en plan som är optimerad för att snabbt returnera de första n matchande raderna (där
n =1här).Naturligtvis kan ett radmål vara bra eller inte, beroende på omständigheterna. Det är inget speciellt med semi join row-målet i det avseendet. Tänk på en situation där insidan av semi-kopplingen är mer komplex än en enkel enkel tabellåtkomst, kanske en flerbordskoppling. Att ställa in ett radmål kan hjälpa optimeraren att välja en effektiv navigeringsstrategi endast för det specifika underträdet , hitta den första matchande raden för att tillfredsställa semi-kopplingen via kapslade loops-kopplingar och indexsökningar. Utan radmålet kan optimeraren naturligtvis välja hash eller sammanfoga kopplingar med sorteringar för att minimera den förväntade kostnaden för att returnera alla möjliga rader. Observera att det finns ett antagande här, nämligen att folk vanligtvis skriver semi-joins med förväntningen att en rad som matchar sökvillkoret faktiskt existerar. Detta verkar vara ett rimligt antagande för mig.
Oavsett vilket är den viktiga punkten i detta skede:Endast ansök kapslade loopar join har ett radmål tillämpas av optimeraren (kom dock ihåg att ett radmål för applicering av kapslade loopar läggs till endast om radmålet är mindre än uppskattningen utan det). Vi kommer att titta på ett par bearbetade exempel för att förhoppningsvis klargöra allt detta härnäst.
Nested Loops Semi Join-exempel
Följande skript skapar två temporära tabeller. Den första har siffror från 1 till 20 inklusive; den andra har 10 kopior av varje nummer i den första tabellen:
SLIPTA TABELL OM FINNS #E1, #E2; SKAPA TABELL #E1 (c1 heltal NULL); SKAPA TABELL #E2 (c1 heltal NULL); INSERT #E1 (c1)SELECT SV.numberFROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=20; INSERT #E2 (c1)SELECT (SV.number % 20) + 1FROM master.dbo.spt_values AS SVWHERE SV.[type] =N'P' AND SV.number>=1 AND SV.number <=200;Utan några index och ett relativt litet antal rader väljer optimeraren en kapslad loop (istället för hash eller sammanfogning) implementering för följande semi-join-fråga). De odokumenterade spårningsflaggorna tillåter oss att se optimizerns utdataträd och radmålinformation:
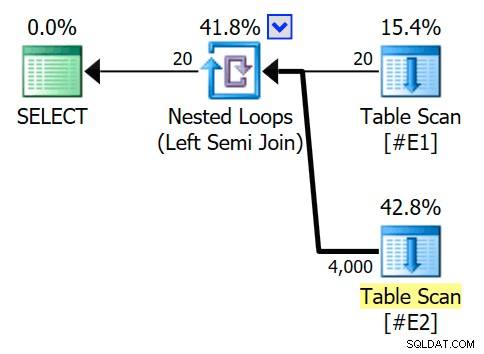
VÄLJ E1.c1 FRÅN #E1 SOM E1VAR E1.c1 IN (VÄLJ E2.c1 FRÅN #E2 SOM E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Den beräknade exekveringsplanen har en halvfogad kapslad loop-koppling, med 200 rader per fullständig genomsökning av tabell
#E2. De 20 iterationerna av slingan ger en total uppskattning av 4 000 rader:
Egenskaperna för den kapslade loopsoperatorn visar att predikatet tillämpas vid sammanfogningen vilket betyder att detta är en okorrelerad kapslad loop-koppling :
Spårningsflaggans utdata (på fliken SSMS-meddelanden) visar en kapslad loops semi-join och inget radmål (RowGoal 0):
Observera att planen efter genomförandet för denna leksaksfråga inte kommer att visa 4 000 rader som läses från tabell #E2 totalt. Kapslade slingor semi sammanfogning (korrelerade eller inte) kommer att sluta leta efter fler rader på insidan (per iteration) så snart den första matchningen för den nuvarande yttre raden påträffas. Nu är ordningen på rader som påträffas från heap-skanningen av #E2 vid varje iteration icke-deterministisk (och kan vara olika för varje iteration), så i princip nästan alla rader skulle kunna testas vid varje iteration, i händelse av att den matchande raden påträffas så sent som möjligt (eller faktiskt, om det inte finns någon matchande rad, inte alls).
Om vi till exempel antar en runtime-implementering där rader råkar skannas i samma ordning (t.ex. "insättningsordning") varje gång, skulle det totala antalet skannade rader i detta leksaksexempel vara 20 rader vid den första iterationen, 1 rad på den andra iterationen, 2 rader på den tredje iterationen, och så vidare för totalt 20 + 1 + 2 + (…) + 19 =210 rader. Det är faktiskt ganska troligt att du kommer att observera denna summa, som säger mer om begränsningarna för enkel demonstrationskod än om något annat. Man kan inte lita på ordningen på rader som returneras från en oordnad åtkomstmetod lika lite som man kan lita på den till synes ordnade utdata från en fråga utan en
ORDER BYpå toppnivån klausul.Ansök Semi Join
Vi skapar nu ett icke-klustrat index på den större tabellen (för att uppmuntra optimeraren att välja en applicera semi-join) och kör frågan igen:
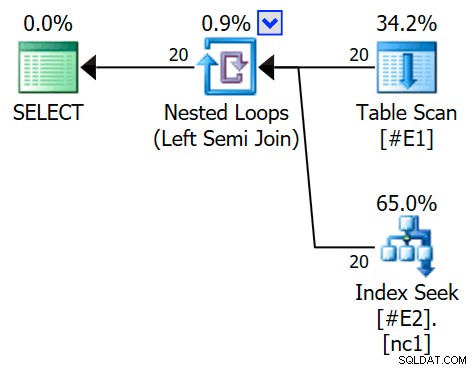
SKAPA INKLUSTERAT INDEX nc1 PÅ #E2 (c1); VÄLJ E1.c1 FRÅN #E1 SOM E1VAR E1.c1 IN (VÄLJ E2.c1 FRÅN #E2 SOM E2)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);Exekveringsplanen har nu en appliceringssemi-join, med 1 rad per indexsökning (och 20 iterationer som tidigare):
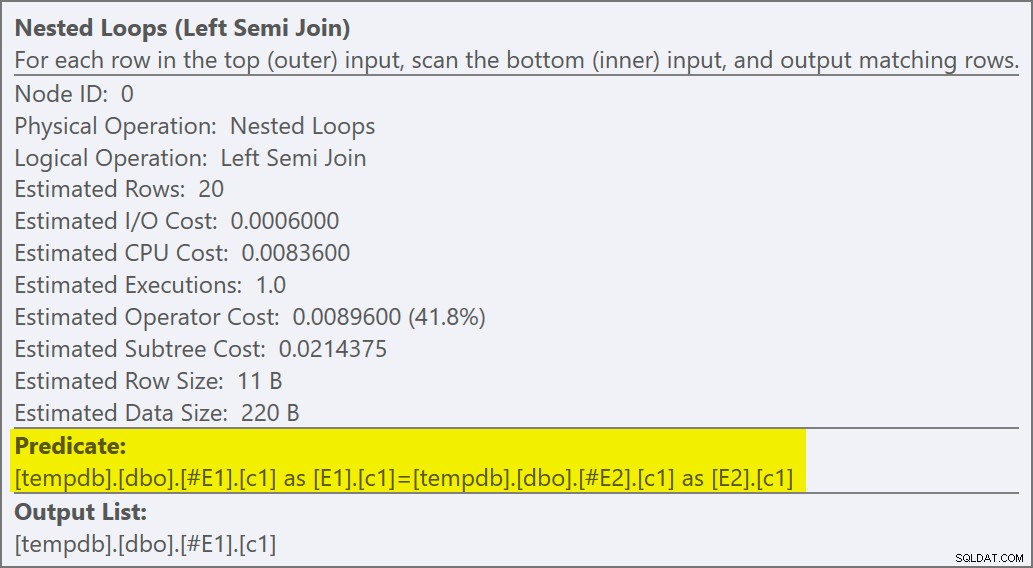
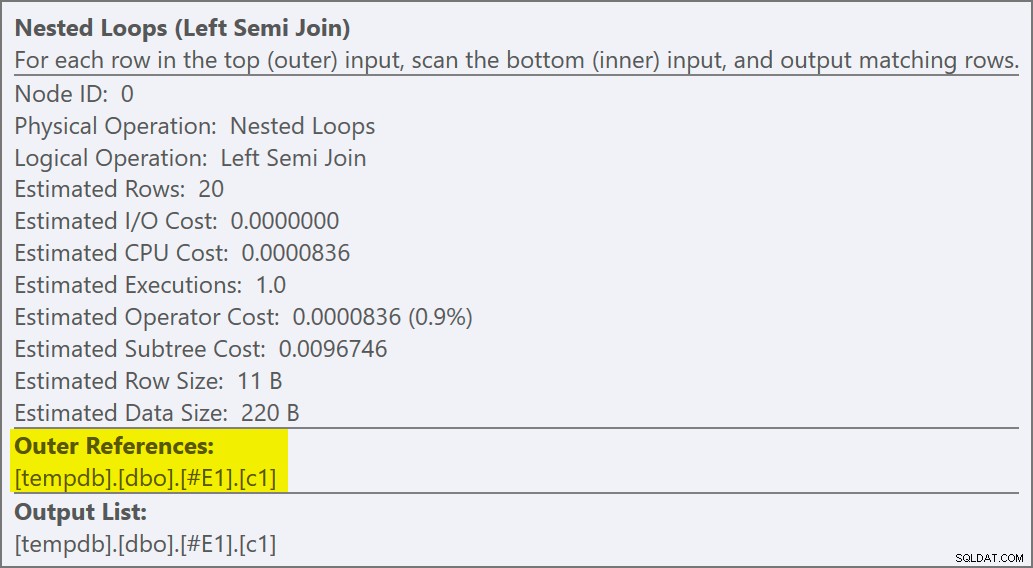
Vi kan säga att det är en ansök halvanslutning eftersom sammanfogningsegenskaperna visar en yttre referens snarare än ett sammanfogningspredikat:
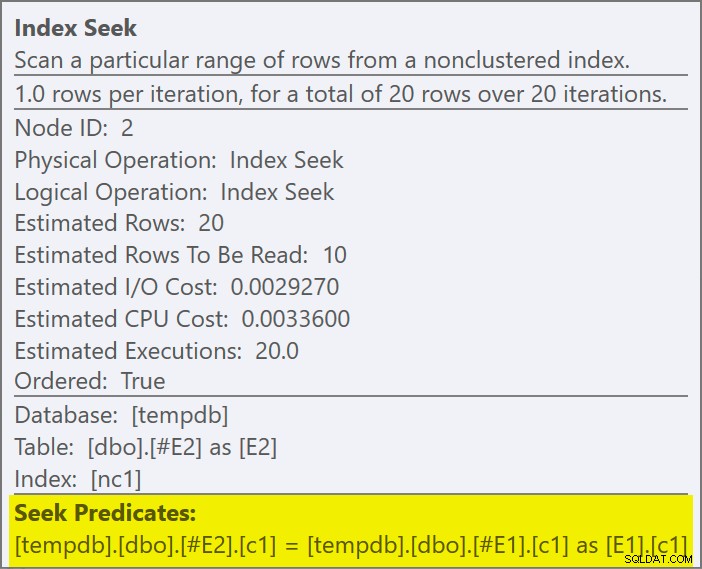
Anslutningspredikatet har tryckts ned insidan av appliceringen och matchas till det nya indexet:
Varje sökning förväntas returnera 1 rad, trots att varje värde dupliceras 10 gånger i den tabellen; detta är en effekt av radmålet . Radmålet blir lättare att identifiera på SQL Server-byggen som exponerar EstimateRowsWithoutRowGoal plan-attribut (SQL Server 2017 CU3 i skrivande stund). I en kommande version av Plan Explorer kommer detta också att exponeras på verktygstips för relevanta operatörer:
Spårningsflaggan är:
Den fysiska operatören har ändrats från en loop-join till en applicering som körs i vänster semi join-läge. Tillgång till tabell
#E2har fått ett radmål på 1 (kardinaliteten utan radmålet visas som 10). Radmålet är inte en stor affär i det här fallet eftersom kostnaden för att hämta uppskattningsvis tio rader per sökning inte är särskilt mycket mer än för en rad. Inaktiverar radmål för den här frågan (med spårningsflagga 4138 ellerDISABLE_OPTIMIZER_ROWGOALfrågetips) skulle inte ändra formen på planen.Icke desto mindre, i mer realistiska frågor, kan kostnadsreduktionen på grund av målet på den inre sidan av raderna göra skillnaden mellan konkurrerande implementeringsalternativ. Om du till exempel inaktiverar radmålet kan det leda till att optimeraren väljer en hash- eller sammanfogad semi-join istället, eller något av många andra alternativ som övervägs för frågan. Om inte annat så återspeglar radmålet här exakt det faktum att en applicerad semi-join slutar söka på insidan så snart den första matchningen hittas, och går vidare till nästa yttre sidorad.
Observera att dubbletter skapades i tabellen
#E2så att målet för applicera semi join-rad (1) skulle vara lägre än den normala uppskattningen (10, från statistikdensitetsinformation). Om det inte fanns några dubbletter, raduppskattningen för varje sökning i#E2skulle också vara 1 rad, så ett radmål på 1 skulle inte tillämpas (kom ihåg den allmänna regeln om detta!)Radmål kontra topp
Med tanke på att exekveringsplaner inte alls indikerar närvaron av ett radmål före SQL Server 2017 CU3, kan man tycka att det hade varit tydligare att implementera denna optimering med en explicit Top-operator, snarare än en dold egenskap som ett radmål. Tanken skulle vara att helt enkelt placera en Top (1) operatör på insidan av en applicerad semi/anti join istället för att sätta ett radmål vid själva join.
Att använda en Top-operatör på detta sätt skulle inte ha varit helt utan prejudikat. Till exempel finns det redan en speciell version av Top känd som en radantal topp som ses i exekveringsplaner för datamodifiering när
SET ROWCOUNTinte är noll är i kraft (observera att denna specifika användning har fasats ut sedan 2005 även om den fortfarande är tillåten i SQL Server 2017). Implementeringen av toppantalet rader är lite klumpig eftersom den översta operatören alltid visas som en topp (0) i exekveringsplanen, oavsett den faktiska gränsen för antal rader som gäller.Det finns ingen övertygande anledning till varför målet för applicera semi join row inte kunde ha ersatts med en explicit Top (1) operator. Som sagt, det finns några skäl att föredra att inte göra det:






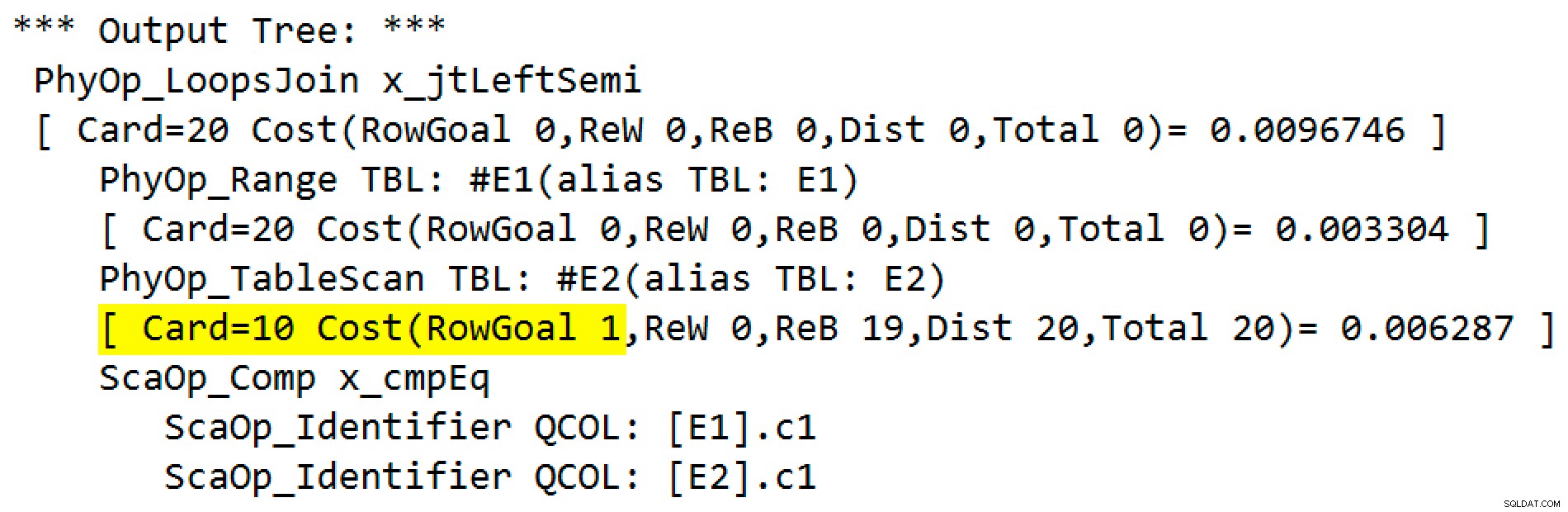
- Att lägga till en explicit topp (1) kräver mer optimeringskodning och testning än att lägga till ett radmål (som redan används för andra saker).
- Top är inte en relationsoperator; optimeraren har lite stöd för resonemang om det. Detta skulle kunna påverka planens kvalitet negativt genom att begränsa optimerarens förmåga att omvandla delar av en frågeplan, t.ex. genom att flytta runt aggregat, fackföreningar, filter och sammanfogningar.
- Det skulle introducera en tät koppling mellan appliceringsimplementeringen av semi-fogen och toppen. Specialfall och tät koppling är bra sätt att introducera buggar och göra framtida ändringar svårare och mer felbenägna.
- Toppen (1) skulle vara logiskt överflödig och endast närvarande för sin radmålsbieffekt.
Den sista punkten är värd att utöka med ett exempel:
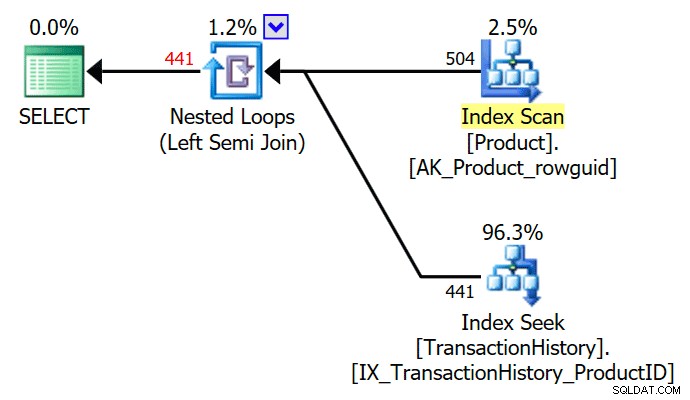
VÄLJ P.ProductID FRÅN Production.Product SOM PWHERE FINNS (VÄLJ TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
TOPP (1) i den existerande underfrågan förenklas bort av optimeraren, vilket ger en enkel semi-join-exekveringsplan:
Optimeraren kan också ta bort en redundant DISTINCT eller GRUPPER EFTER i underfrågan. Följande ger alla samma plan som ovan:
-- Redundant DISTINCTSELECT P.ProductID FROM Production.Product SOM PWHERE FINNS (VÄLJ DISTINCT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID); -- Redundant GROUP BYSELECT P.ProductID FROM Production.Product SOM PWHERE FINNS (VÄLJ TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID GROUP BY TH.ProductID); -- Redundant DISTINCT TOP (1)VÄLJ P.ProductID FROM Production.Product SOM PWHERE FINNS (VÄLJ DISTINCT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Sammanfattning och sista tankar
Endast ansök kapslade loopar semi join kan ha ett radmål satt av optimeraren. Detta är den enda join-typen som trycker ner join-predikatet/-erna från joinen, vilket gör det möjligt att testa om det finns en matchning tidigt . Okorrelerade kapslade loopar semi-anslutna nästan aldrig* sätter ett radmål, och inte heller en hash- eller sammanfogad semi-join. Applicera kapslade loopar kan särskiljas från okorrelerade kapslade loopar genom närvaron av yttre referenser (istället för ett predikat) på de kapslade slingorna join-operator för en applicering.
Chanserna att se en applicerad semi-anslutning i den slutliga genomförandeplanen beror något på tidig optimeringsaktivitet. I brist på direkt T-SQL-syntax måste vi uttrycka semi-kopplingar i indirekta termer. Dessa tolkas till ett logiskt träd som innehåller en underfråga, vilken tidig optimeringsaktivitet omvandlas till en applicering, och sedan till en okorrelerad semi-join där så är möjligt.
Denna förenklingsaktivitet avgör om en logisk semi-koppling presenteras för den kostnadsbaserade optimeraren som en applicerad eller vanlig semi-join. När den presenteras som en logisk applicera semi join, är CBO nästan säker på att ta fram en slutgiltig utförandeplan som innehåller fysiska applicerings kapslade loopar (och så sätter ett radmål). När CBO presenteras med en okorrelerad semi-join, kan överväg omvandling till en applicering (eller kanske inte). Det slutliga valet av plan är en serie kostnadsbaserade beslut som vanligt.
Liksom alla radmål, kan semi join-row-målet vara bra eller dåligt för prestationen. Att veta att en applicera semi join sätter ett radmål kommer åtminstone att hjälpa människor att känna igen och ta itu med orsaken om ett problem skulle uppstå. Lösningen kommer inte alltid (eller ens vanligtvis) att inaktivera radmål för frågan. Förbättringar av indexering (och/eller frågan) kan ofta göras för att ge ett effektivt sätt att hitta den första matchande raden.
Jag kommer att täcka anti semi-anslutningar i en separat artikel, och fortsätter med radmålsserien.
* Undantaget är en okorrelerad kapslad loops semi join utan join-predikat (en ovanlig syn). Detta sätter ett radmål.