@rob_farley din senaste stackoverflow-lösning för att beställa efter ett värde först sedan är ett fält geni! Ville tacka dig personligen.
— Joel Sacco (@Jsac90) 11 augusti 2016
Jag såg den här tweeten komma igenom...
Och det fick mig att titta på vad det syftade på, eftersom jag inte hade skrivit något "nyligen" på StackOverflow om att beställa data. Det visade sig att det var det här svaret jag hade skrivit , som även om det inte var det accepterade svaret, har samlat över hundra röster.
Den som ställde frågan hade ett mycket enkelt problem – att vilja få vissa rader att visas först. Och min lösning var enkel:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Det verkar ha varit ett populärt svar, bland annat för Joel Sacco (enligt den tweeten ovan).
Tanken är att bilda ett uttryck, och ordning efter det. ORDER BY bryr sig inte om det är en faktisk kolumn eller inte. Du kunde ha gjort detsamma med APPLY, om du verkligen föredrar att använda en "kolumn" i din ORDER BY-klausul.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Om jag använder några frågor mot WideWorldImporters kan jag visa dig varför dessa två frågor verkligen är exakt likadana. Jag ska fråga tabellen Sales.Orders och be om att Orders for Salesperson 7 ska visas först. Jag kommer också att skapa ett lämpligt täckande index:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Planerna för dessa två frågor ser identiska ut. De fungerar identiskt – samma läsningar, samma uttryck, de är verkligen samma fråga. Om det finns en liten skillnad i den faktiska CPU:n eller varaktigheten, är det en slump på grund av andra faktorer.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
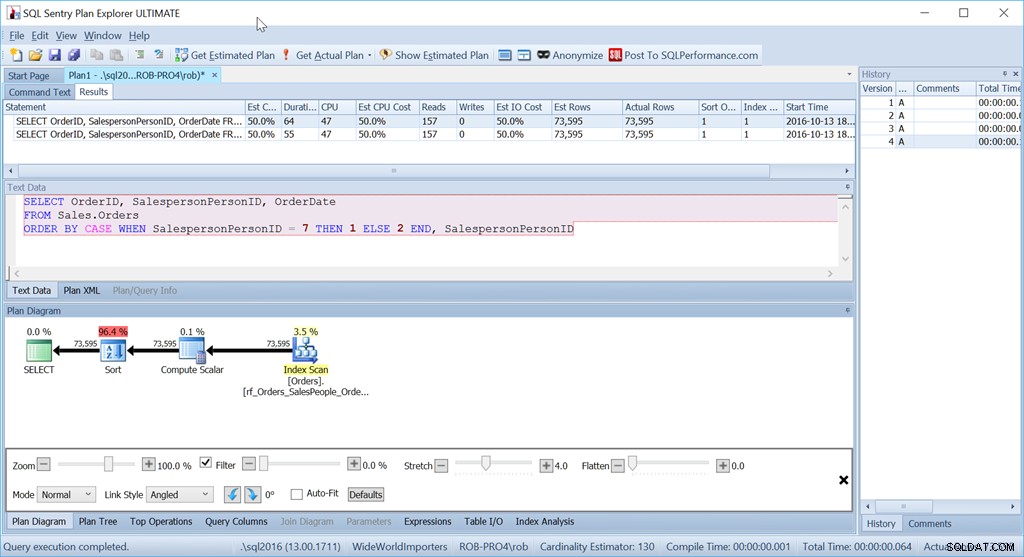
Och ändå är detta inte frågan som jag faktiskt skulle använda i den här situationen. Inte om prestation var viktig för mig. (Det är det vanligtvis, men det är inte alltid värt att skriva en fråga den långa vägen om mängden data är liten.)
Det som stör mig är sorteringsoperatören. Det är 96,4% av kostnaden!
Fundera på om vi helt enkelt vill beställa med SäljarePersonID:
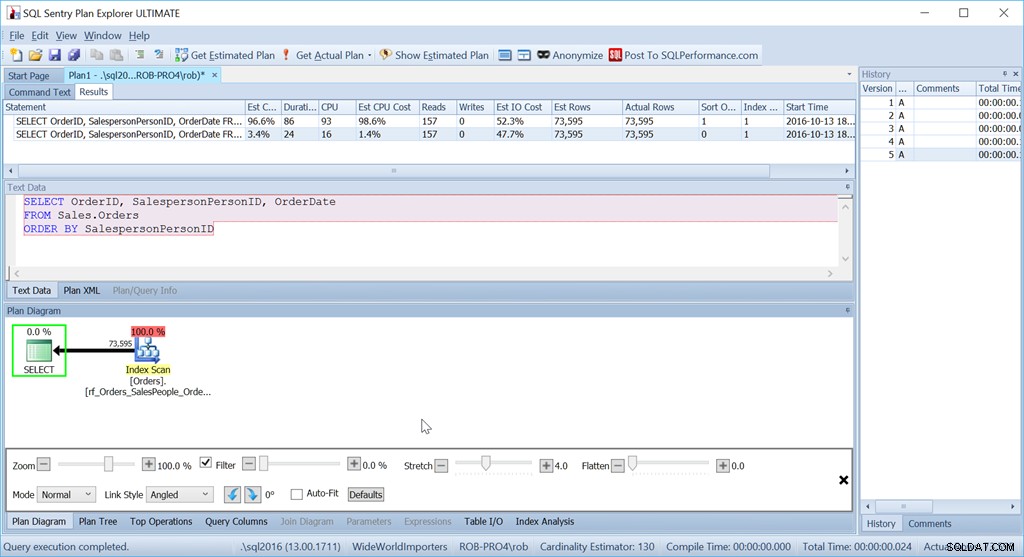
Vi ser att den här enklare frågans uppskattade CPU-kostnad är 1,4 % av batchen, medan den specialsorterade versionens är 98,6 %. Det är SJUTTIO GÅNGER värre. Läsningarna är dock desamma – det är bra. Längden är mycket sämre, och det är CPU också.
Jag är inte förtjust i Sorts. De kan vara otäcka.
Ett alternativ jag har här är att lägga till en beräknad kolumn i min tabell och indexera den, men det kommer att ha en inverkan på allt som letar efter alla kolumner i tabellen, till exempel ORM, Power BI eller något som gör SELECT * . Så det är inte så bra (även om vi någonsin får lägga till dolda beräknade kolumner, skulle det vara ett riktigt bra alternativ här).
Ett annat alternativ, som är mer långrandigt (vissa kanske föreslår att det skulle passa mig – och om du trodde det:Oj! Var inte så oförskämd!), och använder fler läsningar, är att fundera på vad vi skulle göra i verkligheten om vi behövde göra det här.
Om jag hade en hög med 73 595 beställningar, sorterade efter Säljarorder, och jag behövde returnera dem med en viss Säljare först, skulle jag inte bortse från ordningen de var i och helt enkelt sortera dem alla, jag skulle börja med att dyka in och hitta de för säljare 7 – hålla dem i den ordning de var i. Sedan skulle jag hitta de som inte var de som inte var säljare 7 – lägga dem härnäst och återigen hålla dem i den ordning de redan var in.
I T-SQL görs det så här:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Detta får två uppsättningar data och sammanfogar dem. Men frågeoptimeraren kan se att den behöver bibehålla SalespersonPersonID-ordningen när de två uppsättningarna är sammanlänkade, så den gör en speciell typ av sammankoppling som upprätthåller den ordningen. Det är en sammanfogning (sammankoppling) och planen ser ut så här:
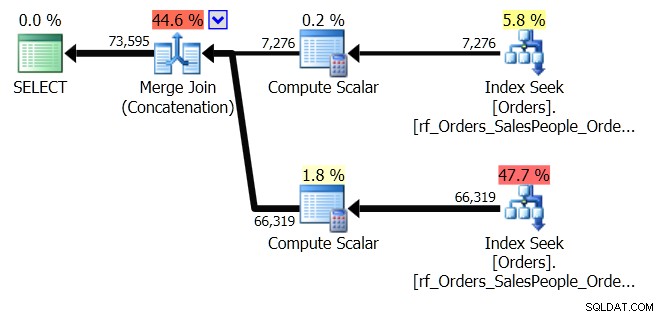
Du kan se att det är mycket mer komplicerat. Men förhoppningsvis kommer du också att märka att det inte finns någon sorteringsoperatör. Merge Join (Concatenation) drar data från varje gren och producerar en datauppsättning som är i rätt ordning. I det här fallet kommer det att dra alla 7 276 rader för säljare 7 först och sedan dra de andra 66 319, eftersom det är den nödvändiga ordningen. Inom varje uppsättning finns data i SalespersonPersonID-ordning, som bibehålls när data flödar igenom.
Jag nämnde tidigare att den använder fler läsningar, och det gör den. Om jag visar SET STATISTICS IO-utgången, och jämför de två frågorna, ser jag detta:
Tabell 'Arbetsbord'. Scan count 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob read-ahead läser 0.Tabell 'Order'. Scanning 1, logiskt läser 157, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'Order '. Scan count 3, logiskt läser 163, fysiskt läser 0, läs framåt läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Med versionen "Anpassad sortering" är det bara en skanning av indexet, med 157 läsningar. Med "Union All"-metoden är det tre skanningar – en för SäljarePersonID =7, en för SäljarePersonID <7 och en för SäljarePersonID> 7. Vi kan se de två sista genom att titta på egenskaperna för den andra Indexsökningen:
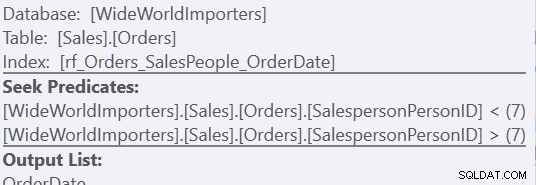
För mig kommer fördelen dock genom avsaknaden av ett arbetsbord.
Titta på den beräknade CPU-kostnaden:

Det är inte så litet som våra 1,4 % när vi helt undviker sorteringen, men det är fortfarande en enorm förbättring jämfört med vår anpassade sorteringsmetod.
Men ett ord av varning...
Anta att jag hade skapat det indexet annorlunda och hade OrderDate som en nyckelkolumn snarare än som en inkluderad kolumn.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Nu fungerar min "Union All"-metod inte alls som avsett.
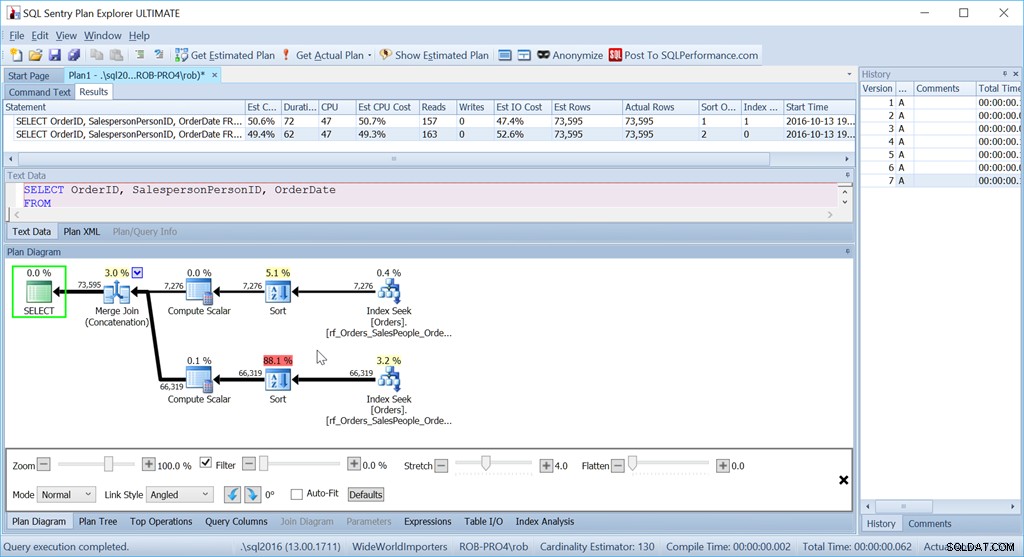
Trots att jag använder exakt samma frågor som tidigare har min fina plan nu två sorteringsoperatorer, och den presterar nästan lika dåligt som min ursprungliga Scan + Sort-version.
Anledningen till detta är en egenhet hos operatorn Merge Join (Concatenation), och ledtråden finns i sorteringsoperatorn.

Det är beställning efter SalespersonPersonID följt av OrderID – som är den klustrade indexnyckeln i tabellen. Den väljer detta eftersom detta är känt för att vara unikt, och det är en mindre uppsättning kolumner att sortera efter än SalespersonPersonID följt av OrderDate följt av OrderID, som är den datauppsättningsordning som produceras av tre indexintervallssökningar. En av de gånger då frågeoptimeraren inte märker ett bättre alternativ som finns där.
Med detta index skulle vi också behöva vår datauppsättning sorterad efter OrderDate för att producera vår föredragna plan.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
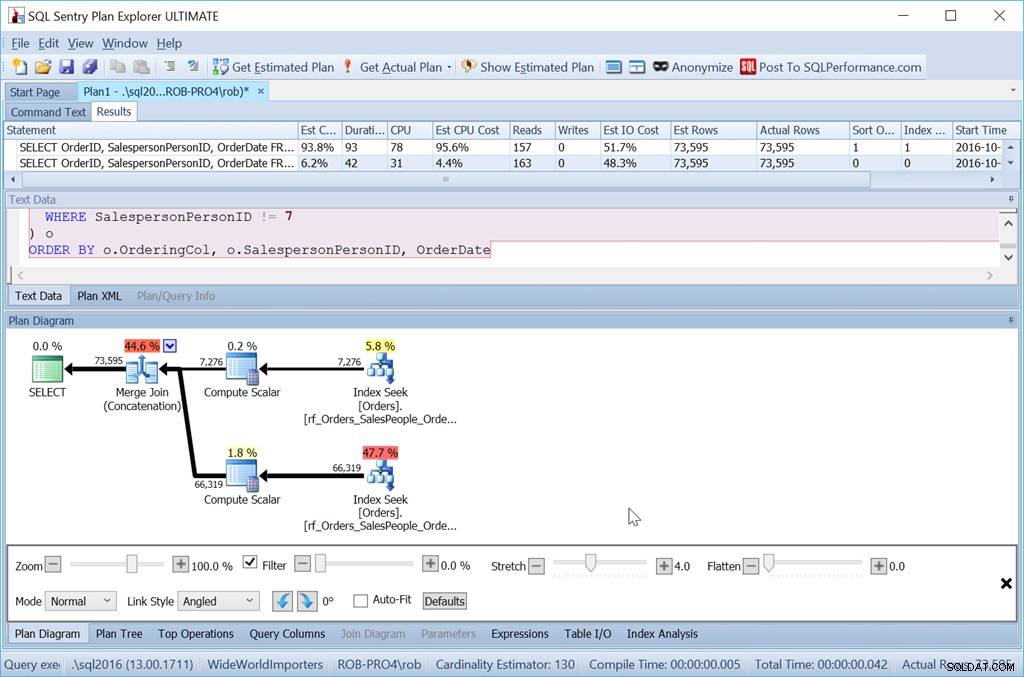
Så det är definitivt mer ansträngning. Frågan är längre för mig att skriva, den är mer läsning och jag måste ha ett index utan extra nyckelkolumner. Men det går säkert snabbare. Med ännu fler rader är påverkan ännu större, och jag behöver inte heller riskera att en sort spiller till tempdb.
För små uppsättningar är mitt StackOverflow-svar fortfarande bra. Men när den sorteringsoperatören kostar mig i prestanda, så använder jag metoden Union All / Merge Join (sammankoppling).