En av många förbättringar av exekveringsplanen i SQL Server 2012 var tillägget av trådreservation och användningsinformation för parallella exekveringsplaner. Det här inlägget tittar på exakt vad dessa siffror betyder och ger ytterligare insikter om hur man förstår parallellt exekvering.
Överväg att följande fråga körs mot en förstorad version av AdventureWorks-databasen:
SELECT
BP.ProductID,
cnt = COUNT_BIG(*)
FROM dbo.bigProduct AS BP
JOIN dbo.bigTransactionHistory AS BTH
ON BTH.ProductID = BP.ProductID
GROUP BY BP.ProductID
ORDER BY BP.ProductID; Frågeoptimeraren väljer en parallell exekveringsplan:
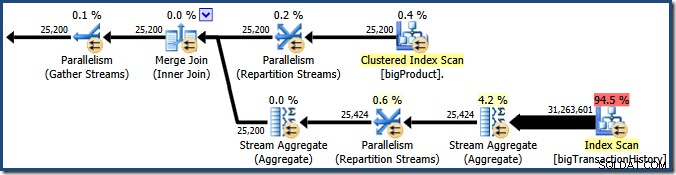
Plan Explorer visar information om användning av parallella trådar i rotnodens verktygstips. För att se samma information i SSMS, klicka på planens rotnod, öppna fönstret Egenskaper och expandera ThreadStat nod. Genom att använda en maskin med åtta logiska processorer tillgängliga för SQL Server att använda, visas trådanvändningsinformationen från en typisk körning av denna fråga nedan, Plan Explorer till vänster, SSMS-vy till höger:
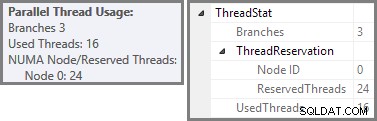
Skärmdumpen visar exekveringsmotorn som reserverat 24 trådar för den här frågan och avslutades med 16 av dem. Den visar också att frågeplanen har tre grenar , även om det inte står exakt vad en gren är. Om du har läst min Simple Talk-artikel om körning av parallella frågor, kommer du att veta att grenar är delar av en parallell frågeplan som avgränsas av växlingsoperatorer. Diagrammet nedan ritar gränserna och numrerar grenarna (klicka för att förstora):

Gren två (orange)
Låt oss först titta på gren två lite mer detaljerat:
Vid en grad av parallellism (DOP) på åtta finns det åtta trådar som kör den här grenen av frågeplanen. Det är viktigt att förstå att detta är hela genomförandeplanen vad gäller dessa åtta trådar – de har ingen kunskap om den vidare planen.
I en seriell exekveringsplan läser en enda tråd data från en datakälla, bearbetar raderna genom ett antal planoperatorer och returnerar resultat till destinationen (vilket kan vara ett SSMS-frågeresultatfönster eller en databastabell, till exempel).
I en gren för en parallell exekveringsplan är situationen mycket lik:varje tråd läser data från en källa, bearbetar raderna genom ett antal planoperatörer och returnerar resultat till destinationen. Skillnaderna är att destinationen är en utbytesoperatör (parallellism), och datakällan kan också vara ett utbyte.
I den orange grenen är datakällan en Clustered Index Scan, och destinationen är den högra sidan av en Repartition Streams-växel. Den högra sidan av en börs kallas producentsidan , eftersom den ansluter till en gren som lägger till data till växeln.
De åtta trådarna i den orangea grenen samarbetar för att skanna tabellen och lägga till rader till börsen. Exchange sätter ihop rader till paket i sidstorlek. När ett paket är fullt skjuts det över växeln till andra sidan. Om utbytet har ett annat tomt paket tillgängligt att fylla, fortsätter processen tills alla datakällrader har bearbetats (eller tills utbytet tar slut på tomma paket).
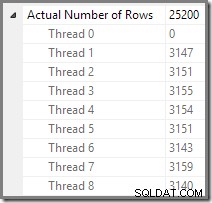
Vi kan se antalet rader som behandlas i varje tråd med hjälp av planträdvyn i Plan Explorer:
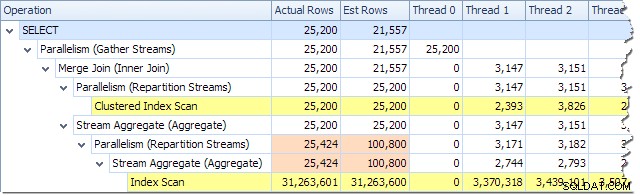
Plan Explorer gör det enkelt att se hur rader är fördelade över trådar för alla den fysiska verksamheten i planen. I SSMS är du begränsad till att se raddistribution för en enda planoperatör. För att göra detta klickar du på en operatörsikon, öppnar fönstret Egenskaper och expanderar sedan noden Faktiskt antal rader. Grafiken nedan visar SSMS-information för Repartition Streams-noden vid gränsen mellan de orange och lila grenarna:
Grench Three (grön)
Gren tre liknar gren två, men den innehåller en extra Stream Aggregate-operatör. Den gröna grenen har också åtta trådar, vilket gör att totalt sexton har setts hittills. De åtta gröna grentrådarna läser data från en icke-klusterad indexskanning, utför någon form av aggregering och skickar resultaten till producentsidan av en annan Repartition Streams-börs.
Verktygstipset för Plan Explorer för Stream Aggregate visar att det grupperas efter produkt-ID och beräknar ett uttryck märkt partialagg1005 :
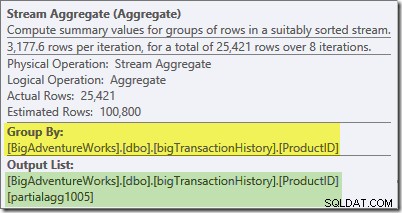
Fliken Uttryck visar att uttrycket är resultatet av räkningen av raderna i varje grupp:

Streamaggregatet beräknar en partiell (även känd som "lokal") aggregat. Det partiella (eller lokala) kvalet betyder helt enkelt att varje tråd beräknar aggregatet på raderna den ser. Rader från Index Scan fördelas mellan trådar med hjälp av ett efterfrågebaserat schema:det finns ingen fast fördelning av rader i förväg; trådar får en rad rader från skanningen när de frågar efter dem. Vilka rader som hamnar på vilka trådar är i huvudsak slumpmässigt eftersom det beror på tidsproblem och andra faktorer.
Varje tråd ser olika rader från skanningen, men rader med samma produkt-ID kan ses av mer än en tråd. Sammanställningen är "partiell" eftersom delsummor för en viss produkt-ID-grupp kan visas i mer än en tråd; det är "lokalt" eftersom varje tråd beräknar sitt resultat endast baserat på de rader den råkar ta emot. Säg till exempel att det finns 1 000 rader för produkt-ID #1 i tabellen. En tråd kan råka se 432 av dessa rader, medan en annan kan se 568. Båda trådarna kommer att ha en delvis antal rader för produkt-ID #1 (432 i en tråd, 568 i den andra).
Partiell aggregering är en prestandaoptimering eftersom den minskar antalet rader tidigare än vad som annars skulle vara möjligt. I den gröna grenen resulterar tidig aggregering i att färre rader sätts samman till paket och skjuts över Repartition Stream-växeln.
Gren 1 (lila)

Den lila grenen har åtta trådar till, vilket är tjugofyra än så länge. Varje tråd i den här grenen läser rader från de två Repartition Streams-växlarna och skriver rader till en Gather Streams-växel. Den här grenen kan verka komplicerad och obekant, men den läser bara rader från en datakälla och skickar resultat till en destination, som vilken annan frågeplan som helst.
Den högra sidan av planen visar data som läses från andra sidan av de två Repartition Streams-växlarna som ses i de orangea och gröna grenarna. Den här (vänstra) sidan av börsen kallas konsumenten sida, eftersom trådar som bifogas här är läsande (förbrukande) rader. De åtta lila grentrådarna är konsumenter av data vid de två Repartition Streams-växlarna.
Den vänstra sidan av den lila grenen visar rader som skrivs till producenten sidan av ett Gather Streams-utbyte. samma åtta trådar (det vill säga konsumenter på Repartition Streams-börserna) utför en producent roll här.
Varje tråd i den lila grenen kör varje operatör i grenen, precis som en enda tråd utför varje operation i en seriell exekveringsplan. Den största skillnaden är att det finns åtta trådar som körs samtidigt, som var och en arbetar på olika rader vid varje given tidpunkt, med olika instanser av frågeplansoperatörerna.
Streamaggregatet i den här grenen är globalt aggregat. Den kombinerar de partiella (lokala) aggregaten som beräknats i den gröna grenen (kom ihåg exemplet med ett antal 432 i en tråd och 568 i den andra) för att producera en kombinerad summa för varje produkt-ID. Verktygstipset för Plan Explorer visar det globala resultatuttrycket, märkt Expr1004:
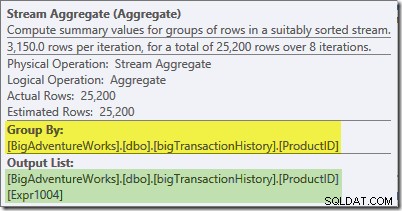
Det korrekta globala resultatet per produkt-ID beräknas genom att summera de partiella aggregaten, som fliken Uttryck illustrerar:
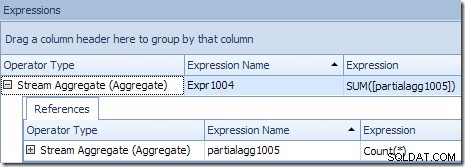
För att fortsätta vårt (imaginära) exempel, det korrekta resultatet av 1 000 rader för produkt-ID #1 erhålls genom att summera de två delsummorna av 432 och 568.
Var och en av de åtta lila grentrådarna läser data från konsumentsidan av de två Gather Streams-utbytena, beräknar de globala aggregaten, utför Merge Join på produkt-ID och lägger till rader till Gather Streams-utbytet längst till vänster om den lila grenen. Kärnprocessen skiljer sig inte så mycket från en vanlig serieplan; skillnaderna ligger i var rader läses ifrån, var de skickas till och hur rader är fördelade mellan trådarna...
Exchange Row Distribution
Den uppmärksammade läsaren kommer att undra över ett par detaljer vid det här laget. Hur lyckas den lila grenen beräkna korrekta resultat per produkt-ID men den gröna grenen kunde inte (resultat för samma produkt-ID spreds över många trådar)? Dessutom, om det finns åtta separata sammanfogningar (en per tråd), hur garanterar SQL Server att rader som kommer att sammanfogas hamnar i samma instans av sammanfogningen?
Båda dessa frågor kan besvaras genom att titta på hur de två uppdelningsströmmarna byter vägrader från producentsidan (i de gröna och orangea grenarna) till konsumentsidan (i den lila grenen). Vi kommer att titta på Repartition Streams-utbytet som gränsar till de orangea och lila grenarna först:
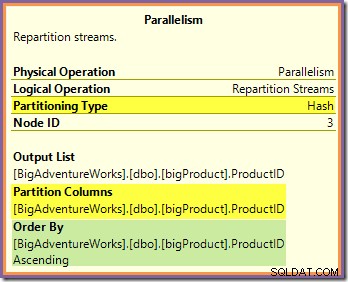
Denna växel dirigerar inkommande rader (från den orange grenen) med hjälp av en hashfunktion som appliceras på produkt-ID-kolumnen. Effekten är att alla rader för ett visst produkt-ID är garanterade att dras till samma lila grentråd. De orange och lila trådarna vet ingenting om denna routing; allt detta hanteras internt av börsen.
Allt de orangea trådarna vet är att de returnerar rader till den överordnade iteratorn som bad om dem (producentsidan av utbytet). Likaså är alla lila trådar 'vet' att de läser rader från en datakälla. Utbytet avgör vilket paket en inkommande orange-trådsrad ska gå in i, och det kan vara vilket som helst av åtta kandidatpaket. På samma sätt bestämmer utbytet vilket paket en rad ska läsas från för att tillgodose en läsbegäran från en lila tråd.
Var försiktig så att du inte får en mental bild av att en viss orange (producerande) tråd är kopplad direkt till en viss lila (konsument-) tråd. Det är inte så den här frågeplanen fungerar. En apelsinproducent kan slutar med att skicka rader till alla lila konsumenter – routingen beror helt på värdet av produkt-ID-kolumnen i varje rad som den bearbetar.
Observera också att ett paket med rader på börsen bara överförs när det är fullt (eller när producentsidan tar slut på data). Föreställ dig utbytespaketen en rad i taget, där rader för ett visst paket kan komma från vilken som helst av producentsidans (orange) trådar. När ett paket är fullt skickas det vidare till konsumentsidan, där en viss konsumenttråd (lila) kan börja läsa från den.
Repartition Streams-växeln som gränsar till de gröna och lila grenarna fungerar på ett mycket liknande sätt:
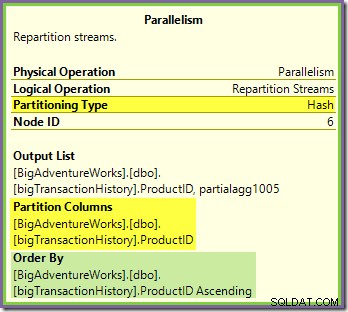
Rader dirigeras till paket i detta utbyte med samma hashfunktion i samma partitioneringskolumn som för orange-lila utbyte sett tidigare. Det betyder att båda Repartition Streams utbyter ruttrader med samma produkt-ID till samma lila grentråd.
Det här förklarar hur Stream Aggregate i den lila grenen kan beräkna globala aggregat – om en rad med ett visst produkt-ID visas på en viss lila grentråd, kommer den tråden garanterat att se alla rader för det produkt-ID:t (och inte annan tråd kommer).
Den gemensamma utbytespartitioneringskolumnen är också join-nyckeln för sammanfogningen, så alla rader som kan gå med garanteras att behandlas av samma (lila) tråd.
En sista sak att notera är att båda utbytena är orderbevarande (a.k.a 'sammanslagning') utbyten, som visas i attributet Ordna efter i verktygstipsen. Detta möter sammanfogningskravet att inmatningsrader sorteras på sammanfogningsnycklarna. Observera att börser aldrig sorterar rader själva, de kan bara konfigureras för att bevara befintlig ordning.
Tråd noll
Den sista delen av avrättningsplanen ligger till vänster om Gather Streams-utbytet. Den körs alltid på en enda tråd - samma som används för att köra hela en vanlig serieplan. Den här tråden är alltid märkt "Tråd 0" i genomförandeplaner och kallas ibland för "koordinator"-tråden (en beteckning som jag inte tycker är särskilt användbar).
Tråd noll läser rader från konsumentsidan (vänster) av Gather Streams-börsen och returnerar dem till klienten. Det finns inga trådnoll-iteratorer förutom utbytet i det här exemplet, men om det fanns skulle de alla köras på samma enda tråd. Observera att Gather Streams också är en sammanslagningsbörs (den har ett Order By-attribut):

Mer komplexa parallella planer kan inkludera andra seriella exekveringszoner än den till vänster om den slutliga Gather Streams-utbytet. Dessa seriella zoner körs inte i tråd noll, men det är en detalj att utforska en annan gång.
Reserverade och använda trådar har besökts igen
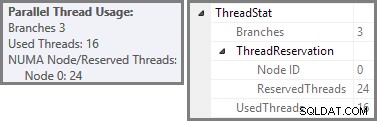
Vi har sett att denna parallella plan innehåller tre grenar. Detta förklarar varför SQL Server reserverad 24 trådar (tre grenar vid DOP 8). Frågan är varför endast 16 trådar rapporteras som "använda" i skärmdumpen ovan.
Det finns två delar till svaret. Den första delen gäller inte denna plan, men den är viktig att känna till i alla fall. Antalet grenar som rapporteras är det maximala antalet som kan köras samtidigt .
Som du kanske vet, "blockerar" vissa planoperatörer - vilket innebär att de måste konsumera alla sina inmatningsrader innan de kan producera den första utmatningsraden. Det tydligaste exemplet på en blockerande (även känd som stop-and-go)-operatör är Sortera. En sortering kan inte returnera den första raden i sorterad ordning innan den har sett varje inmatningsrad eftersom den sista inmatningsraden kanske sorterar först.
Operatörer med flera ingångar (till exempel sammanfogningar och sammanslutningar) kan vara blockerande med avseende på en ingång, men icke-blockerande ('pipelined') med avseende på den andra. Ett exempel på detta är hash join – byggingången blockerar, men sondens ingång är pipelined. Byggingången blockeras eftersom den skapar hashtabellen mot vilken probrader testas.
Närvaron av blockerande operatörer innebär att en eller flera parallella grenar kan vara garanterad att slutföra innan andra kan börja. Där detta inträffar kan SQL Server återanvända trådarna som används för att bearbeta en färdig gren för en senare gren i sekvensen. SQL Server är mycket konservativa när det gäller trådreservation, så endast grenar som är garanterade att slutföra innan en annan startar använd denna trådreservationsoptimering. Vår frågeplan innehåller inga blockerande operatörer, så det rapporterade antalet filialer är bara det totala antalet filialer.
Den andra delen av svaret är att trådar fortfarande kan återanvändas om de händer att slutföra innan en tråd i en annan gren startar. Hela antalet trådar är fortfarande reserverat i det här fallet, men den faktiska användningen kan vara lägre. Hur många trådar en parallell plan faktiskt använder beror bland annat på timingfrågor och kan variera mellan utföranden.
Parallella trådar börjar inte köras samtidigt, men återigen får detaljerna vänta på ett annat tillfälle. Låt oss titta på frågeplanen igen för att se hur trådar kan återanvändas, trots bristen på blockerande operatörer:
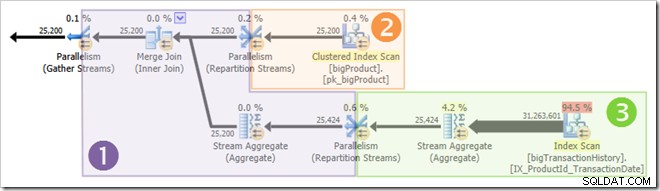
Det är klart att trådar i gren ett inte kan slutföra innan trådar i grenar två eller tre startar, så det finns ingen chans till trådåteranvändning där. Gren tre är också osannolikt att slutföra innan antingen gren ett eller gren två startar eftersom det har så mycket arbete att göra (nästan 32 miljoner rader att sammanställa).
Gren två är en annan sak. Den relativt lilla storleken på produkttabellen betyder att det finns en anständig chans att filialen kan slutföra sitt arbete innan gren tre startar. Om läsning av produkttabellen inte resulterar i någon fysisk I/O kommer det inte att ta särskilt lång tid för åtta trådar att läsa de 25 200 raderna och skicka dem till den orange-lila gränsen Repartition Streams Exchange.
Detta är exakt vad som hände i testkörningarna som användes för skärmdumparna som vi sett hittills i det här inlägget:de åtta orangea grentrådarna slutfördes tillräckligt snabbt för att de skulle kunna återanvändas för den gröna grenen. Totalt användes sexton unika trådar, så det är vad genomförandeplanen rapporterar.
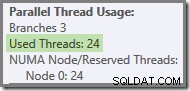
Om frågan körs om med en kall cache, är fördröjningen som introduceras av den fysiska I/O tillräckligt för att säkerställa att gröna grentrådar startar innan några orange grentrådar har slutförts. Inga trådar återanvänds, så exekveringsplanen rapporterar att alla 24 reserverade trådar faktiskt användes:
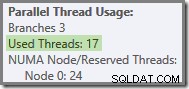
Mer generellt är valfritt antal "begagnade trådar" mellan de två ytterligheterna (16 och 24 för denna frågeplan) möjligt:
Slutligen, notera att tråden som kör seriedelen av planen till vänster om de sista Gather Streams räknas inte i parallelltrådssummorna. Det är inte en extra tråd som läggs till för att passa parallellt exekvering.
Sluta tankar
Det fina med utbytesmodellen som används av SQL Server för att implementera parallell exekvering är att all komplexitet med att buffra och flytta rader mellan trådar är gömd i utbytesoperatorer (parallellism). Resten av planen är uppdelad i snygga "grenar", avgränsade av utbyten. Inom en filial beter sig varje operatör på samma sätt som i en serieplan – i nästan alla fall har filialoperatörerna ingen kunskap om att den bredare planen använder parallellt exekvering överhuvudtaget.
Nyckeln till att förstå parallell exekvering är att (mentalt) bryta isär den parallella planen vid utbytesgränserna, och att föreställa varje gren som DOP-separat serie planer, alla exekverar samtidighet på en distinkt delmängd av rader. Kom särskilt ihåg att varje sådan serieplan kör alla operatörer i den grenen – SQL Server gör inte kör varje operatör på sin egen tråd!
Att förstå det mest detaljerade beteendet kräver lite eftertanke, särskilt hur rader dirigeras inom utbyten och hur motorn garanterar korrekta resultat, men då kräver det mesta som är värt att veta lite eftertanke, eller hur?