[ Del 1 | Del 2 | Del 3 | Del 4 ]
Mycket har skrivits under åren om att förstå och optimera SELECT frågor, utan snarare mindre om datamodifiering. Den här serien av inlägg tittar på ett problem som är specifikt för INSERT , UPDATE , DELETE och MERGE frågor – Halloween-problemet.
Frasen "Halloweenproblem" myntades ursprungligen med hänvisning till en SQL UPDATE fråga som var tänkt att ge en höjning på 10 % till varje anställd som tjänade mindre än $25 000. Problemet var att frågan fortsatte att ge 10 % höjningar tills alla tjänat minst 25 000 USD. Vi kommer att se längre fram i den här serien att det underliggande problemet även gäller INSERT , DELETE och MERGE frågor, men för den här första posten kommer det att vara bra att undersöka UPDATE problem i detalj.
Bakgrund
SQL-språket tillhandahåller ett sätt för användare att specificera databasändringar med en UPDATE uttalande, men syntaxen säger ingenting om hur databasmotorn bör utföra ändringarna. Å andra sidan specificerar SQL-standarden att resultatet av en UPDATE måste vara samma som om den hade körts i tre separata och icke-överlappande faser:
- En skrivskyddad sökning avgör vilka poster som ska ändras och de nya kolumnvärdena
- Ändringar tillämpas på berörda poster
- Databaskonsistensbegränsningar verifieras
Att implementera dessa tre faser bokstavligen i en databasmotor skulle ge korrekta resultat, men prestandan kanske inte är särskilt bra. De mellanliggande resultaten i varje steg kommer att kräva systemminne, vilket minskar antalet frågor som systemet kan utföra samtidigt. Det minne som krävs kan också överstiga det som är tillgängligt, vilket kräver att åtminstone en del av uppdateringsuppsättningen skrivs ut till disklagring och läses tillbaka igen senare. Sist men inte minst måste varje rad i tabellen beröras flera gånger under denna exekveringsmodell.
En alternativ strategi är att bearbeta UPDATE en rad i taget. Detta har fördelen av att bara röra varje rad en gång och kräver i allmänhet inte minne för lagring (även om vissa operationer, som en fullständig sortering, måste bearbeta hela inmatningsuppsättningen innan den första raden med utdata produceras). Denna iterativa modell är den som används av sökmotorn för SQL Server.
Utmaningen för frågeoptimeraren är att hitta en iterativ (rad för rad) exekveringsplan som uppfyller UPDATE semantik som krävs av SQL-standarden, samtidigt som prestanda och samtidighetsfördelar med pipelined exekvering bibehålls.
Uppdateringsbearbetning
För att illustrera det ursprungliga problemet kommer vi att tillämpa en höjning på 10 % för varje anställd som tjänar mindre än 25 000 USD med Employees tabellen nedan:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Tre-fas uppdateringsstrategi
Den skrivskyddade första fasen hittar alla poster som uppfyller WHERE klausulpredikat och sparar tillräckligt med information för att den andra fasen ska kunna utföra sitt arbete. I praktiken innebär detta att man registrerar en unik identifierare för varje kvalificerande rad (de klustrade indexnycklarna eller högradsidentifieraren) och det nya lönevärdet. När fas ett är klar, skickas hela uppsättningen av uppdateringsinformation till den andra fasen, som lokaliserar varje post som ska uppdateras med hjälp av den unika identifieraren, och ändrar lönen till det nya värdet. Den tredje fasen kontrollerar sedan att inga databasintegritetsbegränsningar överträds av tabellens slutliga tillstånd.
Iterativ strategi
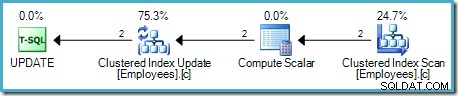
Detta tillvägagångssätt läser en rad i taget från källtabellen. Om raden uppfyller WHERE klausulpredikat tillämpas löneförhöjningen. Denna process upprepas tills alla rader har bearbetats från källan. Ett exempel på genomförandeplan med denna modell visas nedan:

Som är vanligt för SQL Servers efterfrågestyrda pipeline, startar exekveringen vid operatören längst till vänster – UPDATE I detta fall. Den begär en rad från tabelluppdateringen, som frågar efter en rad från Compute Scalar, och ner i kedjan till tabellskanningen:
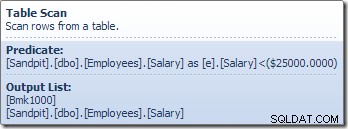
Tabellskanningsoperatören läser rader en i taget från lagringsmotorn, tills den hittar en som uppfyller lönepredikatet. Utdatalistan i grafiken ovan visar operatören Tabellskanning som returnerar en radidentifierare och det aktuella värdet i kolumnen Lön för denna rad. En enda rad som innehåller referenser till dessa två informationsdelar skickas till Compute Scalar:
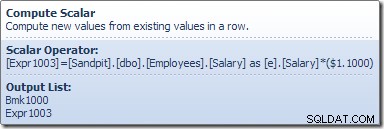
Compute Scalar definierar ett uttryck som tillämpar lönehöjningen på den aktuella raden. Den returnerar en rad som innehåller referenser till radidentifieraren och den modifierade lönen till tabelluppdateringen, som anropar lagringsmotorn för att utföra dataändringen. Denna iterativa process fortsätter tills tabellsökningen tar slut på rader. Samma grundläggande process följs om tabellen har ett klustrat index:
Den största skillnaden är att den/de klustrade indexnycklarna och uniquiifier (om sådan finns) används som radidentifierare istället för en heap RID.
Problemet
Att byta från den logiska trefasoperationen som definieras i SQL-standarden till den fysiska iterativa exekveringsmodellen har infört ett antal subtila förändringar, varav bara en vi ska titta på idag. Ett problem kan uppstå i vårt pågående exempel om det finns ett icke-klustrat index i kolumnen Lön, som frågeoptimeraren bestämmer sig för att använda för att hitta rader som kvalificerar sig (Lön <$25 000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Rad-för-rad-exekveringsmodellen kan nu ge felaktiga resultat, eller till och med hamna i en oändlig loop. Tänk på en (imaginär) iterativ exekveringsplan som söker löneindexet, returnerar en rad åt gången till Compute Scalar och slutligen vidare till Update-operatören:

Det finns ett par extra Compute Scalars i denna plan på grund av en optimering som hoppar över icke-klustrade indexunderhåll om lönevärdet inte har ändrats (endast möjligt för en noll lön i det här fallet).
Om man ignorerar det, är det viktiga med den här planen att vi nu har en beställd partiell indexskanning som skickar en rad åt gången till en operatör som modifierar samma index (den gröna markeringen i SQL Sentry Plan Explorer-grafiken ovan gör det tydligt att Clustered Operatören Index Update underhåller både bastabellen och det icke-klustrade indexet).
Hur som helst, problemet är att genom att bearbeta en rad i taget kan uppdateringen flytta den aktuella raden framför skanningspositionen som används av Indexsök för att hitta rader som ska ändras. Att arbeta igenom exemplet bör göra det påståendet lite tydligare:
Det icke-klustrade indexet nyckelas, och sorteras stigande, på lönevärdet. Indexet innehåller också en pekare till den överordnade raden i bastabellen (antingen en heap RID eller de klustrade indexnycklarna plus uniquiifier om det behövs). För att göra exemplet lättare att följa, anta att bastabellen nu har ett unikt klustrat index i kolumnen Namn, så det icke-klustrade indexinnehållet i början av uppdateringsbearbetningen är:
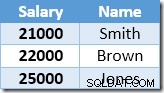
Den första raden som returneras av Index Seek är $21 000-lönen för Smith. Detta värde uppdateras till $23 100 i bastabellen och det icke-klustrade indexet av operatorn Clustered Index. Det icke-klustrade indexet innehåller nu:
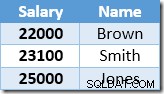
Nästa rad som returneras av Index Seek kommer att vara $22 000-posten för Brown som uppdateras till $24 200:
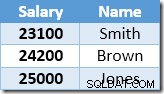
Nu hittar Index Seek värdet på 23 100 $ för Smith, som uppdateras igen , till 25 410 USD. Denna process fortsätter tills alla anställda har en lön på minst $25 000 – vilket inte är ett korrekt resultat för den givna UPDATE fråga. Samma effekt under andra omständigheter kan leda till en rinnande uppdatering som bara avslutas när servern får slut på loggutrymme eller ett överflödesfel uppstår (det kan inträffa i det här fallet om någon hade noll i lön). Detta är Halloween-problemet eftersom det gäller uppdateringar.
Undvika Halloween-problemet för uppdateringar
Örnögda läsare kommer att ha märkt att de beräknade kostnadsprocenterna i den imaginära Index Seek-planen inte gick upp till 100 %. Detta är inte ett problem med Plan Explorer – jag tog medvetet bort en nyckeloperatör från planen:

Frågeoptimeraren inser att denna pipelined uppdateringsplan är sårbar för Halloween-problemet och introducerar en Eager Table Spool för att förhindra att det inträffar. Det finns ingen antydan eller spårningsflagga för att förhindra inkludering av spolen i denna exekveringsplan eftersom den krävs för korrekthet.
Som namnet antyder, konsumerar spolen ivrigt alla rader från sin underordnade operatör (indexsökningen) innan den returnerar en rad till sin överordnade Compute Scalar. Effekten av detta är att införa fullständig fasseparation – alla kvalificerade rader läses och sparas i tillfällig lagring innan några uppdateringar utförs.
Detta för oss närmare den trefasiga logiska semantiken i SQL-standarden, även om planexekveringen fortfarande är i grunden iterativ, med operatorer till höger om spolen som bildar läsmarkören , och operatorer till vänster som bildar skrivmarkören . Innehållet i spolen läses fortfarande och bearbetas rad för rad (det skickas inte en masse som jämförelsen med SQL-standarden annars kan få dig att tro).
Nackdelarna med fasseparationen är desamma som nämnts tidigare. Tabellrullen förbrukar tempdb utrymme (sidor i buffertpoolen) och kan kräva fysisk läsning och skrivning till disk under minnestryck. Frågeoptimeraren tilldelar en uppskattad kostnad till spolen (med förbehåll för alla vanliga varningar om uppskattningar) och kommer att välja mellan planer som kräver skydd mot Halloween-problemet jämfört med de som inte gör det baserat på beräknad kostnad som normalt. Naturligtvis kan optimeraren felaktigt välja mellan alternativen av någon av de normala anledningarna.
I det här fallet är avvägningen mellan effektivitetsökningen genom att söka direkt till kvalificerade poster (de med en lön <$25 000) kontra den beräknade kostnaden för spolen som krävs för att undvika Halloween-problemet. En alternativ plan (i detta specifika fall) är en fullständig genomsökning av det klustrade indexet (eller högen). Denna strategi kräver inte samma Halloween-skydd eftersom nycklarna av det klustrade indexet ändras inte:

Eftersom indexnycklarna är stabila kan rader inte flytta positionen i indexet mellan iterationer, vilket undviker Halloween-problemet i det aktuella fallet. Beroende på körtidskostnaden för Clustered Index Scan jämfört med Index Seek plus Eager Table Spool-kombinationen som setts tidigare, kan den ena planen köras snabbare än den andra. Ett annat övervägande är att planen med Halloween Protection kommer att få fler lås än den fullständiga planen, och låsen kommer att hållas längre.
Sluta tankar
Att förstå Halloween-problemet och effekterna det kan ha på frågeplaner för datamodifiering hjälper dig att analysera dataförändrande exekveringsplaner och kan erbjuda möjligheter att undvika kostnaderna och biverkningarna av onödigt skydd där ett alternativ finns tillgängligt.
Det finns flera former av Halloween-problemet, som inte alla orsakas av att läsa och skriva till nycklarna i ett gemensamt register. Halloween-problemet är inte heller begränsat till UPDATE frågor. Frågeoptimeraren har fler knep i rockärmen för att undvika Halloween-problemet förutom brute-force fasseparation med hjälp av en Eager Table Spool. Dessa punkter (och fler) kommer att utforskas i nästa avsnitt av den här serien.
[ Del 1 | Del 2 | Del 3 | Del 4 ]