Livförsäkring är något vi alla hoppas att vi inte kommer att behöva, men som vi vet är livet oförutsägbart. I den här artikeln fokuserar vi på att formulera en datamodell som ett livförsäkringsbolag kan använda för att lagra sin information.
Livförsäkring som koncept
Innan vi börjar diskutera den faktiska datamodellen för ett livförsäkringsbolag kommer vi kort att påminna oss själva om vad försäkring är och hur det fungerar så att vi har en bättre uppfattning om vad vi arbetar med.
Försäkring är ett ganska gammalt koncept som går tillbaka till och med före medeltiden, då många skrån erbjöd försäkringar för att skydda sina medlemmar i oväntade situationer. Till och med den berömda astronomen, matematikern, vetenskapsmannen och uppfinnaren Edmund Halley sysslade med försäkringar och arbetade med statistik och dödlighet som utgjorde ryggraden i moderna försäkringsmodeller.
Varför ska du behöva betala för försäkringen? Tanken är ganska enkel – du betalar ett visst belopp (premien) i utbyte mot att försäkringsbolaget garanterar att du eller din familj kommer att få ekonomisk kompensation om något oväntat händer dig eller din egendom. När det gäller en livförsäkring utser du en förmånstagare som ska få en summa pengar (förmånen) vid din död. Tanken är att dessa pengar ska hjälpa dem att återhämta sig från sin förlust, särskilt om din död skapar några ekonomiska problem.
Naturligtvis betalar försäkringsbolag vanligtvis ut mycket mindre i förmåner än vad de tjänar på premier och genom att investera dina pengar på till exempel aktiemarknaden. Annars skulle de gå i konkurs och hela systemet skulle falla isär!
Det är ganska mycket kärnan i det. Nu när vi har fått det ur vägen, låt oss gå vidare och ta en titt på datamodellen för ett typiskt livförsäkringsbolag.
Datamodellen:Översikt
Datamodellen vi kommer att arbeta med består av fem ämnesområden:
- Anställda
- Produkter
- Kunder
- Erbjudanden
- Betalningar
Vi kommer att täcka vart och ett av dessa avsnitt mer i detalj, i den ordning de är listade ovan.
Ämnesområde #1:Anställda
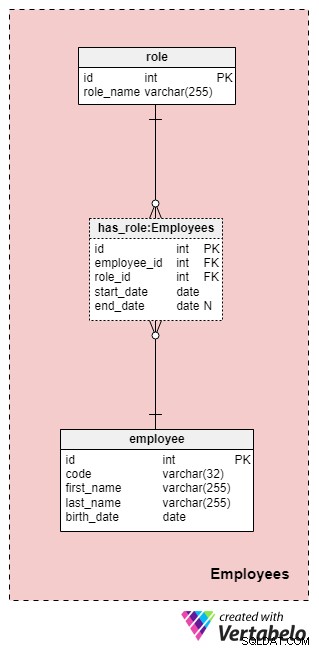
Detta område är inte nödvändigtvis specifikt för denna datamodell men är fortfarande mycket viktigt eftersom tabellerna häri kommer att refereras av andra ämnesområden. För ändamålen med vår försäkringsbolagsdatamodell behöver vi naturligtvis veta vem som utförde vilken åtgärd (t.ex. vem som representerade vårt företag när vi arbetade med kunden/klienten, vem som skrev under policyn och så vidare).
Listan över alla företagets anställda lagras i employee tabell. För varje anställd lagrar vi följande information:
code— en unik nyckel som identifierar en enskild anställd. Eftersom koden kommer att användas som ett attribut i andra tabeller, kommer den att fungera som en alternativ nyckel i den här tabellen.first_nameochlast_name— den anställdes för- respektive efternamn.birth_date— den anställdes födelsedatum.
Naturligtvis skulle vi säkert kunna inkludera många andra medarbetarrelaterade attribut i den här tabellen, men dessa fyra är mer än tillräckligt för nu. Vi kommer att följa det här mönstret genom hela artikeln och försöka hålla saker och ting så enkla som möjligt, men observera att du definitivt kan utöka denna datamodell för att inkludera ytterligare information.
Eftersom anställda kan ändra sina roller i vårt företag när som helst behöver vi en ordbokstabell för att representera företagets roller och en tabell för att lagra värden. Listan över alla möjliga roller som anställda kan ta på vårt livförsäkringsbolag lagras i role lexikon. Den har bara ett attribut som heter role_name som innehåller unikt identifierande värden.
Vi kommer att relatera anställda och roller med hjälp av has_role tabell. Förutom de främmande nycklarna employee_id och role_id , lagrar vi två värden:start_date och end_date . Dessa två värden anger det intervall inom vilket denna företagsroll var aktiv för en viss anställd. end_date kommer att innehålla värdet null tills ett slutdatum för denna medarbetares roll har fastställts. Den alternativa nyckeln för denna tabell är kombinationen av employee_id , role_id och start_date . För att undvika att samma roll dupliceras för samma anställd måste vi kontrollera programmatiskt för eventuella överlappningar varje gång vi lägger till en ny post i tabellen eller uppdaterar en befintlig.
Ämnesområde #2:Produkter
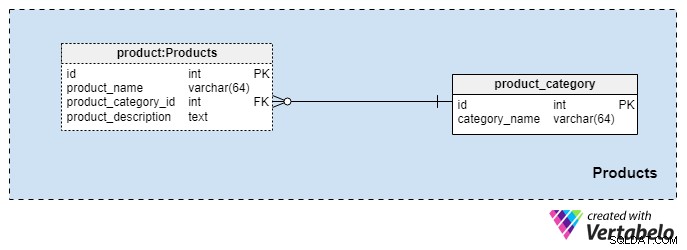
Detta ämnesområde är ganska litet och innehåller bara två tabeller. Värden från dessa tabeller är en förutsättning för våra andra ämnesområden, så vi kommer att diskutera dessa kort.
product_category ordboken lagrar de mest allmänna produktkategorierna som vi planerar att erbjuda våra kunder. Det enda värdet vi kommer att lagra i den här tabellen är det unika category_name för att ange vilken typ av försäkring vi erbjuder, vilket kan vara personlig livförsäkring, familjelivförsäkring och så vidare.
Vi kommer att kategorisera våra produkter ytterligare med product tabell. Den här tabellen representerar de faktiska produkterna vi säljer och inte deras kategorier. Som du kan föreställa dig kan vi gruppera produkter efter varaktighet (t.ex. 10 eller 20 år, eller till och med en livstid). Om vi väljer att göra det kommer vi sannolikt att ha produkter med samma product_category_id men olika namn och beskrivningar. För varje produkt lagrar vi följande grundläggande information:
product_name— Namnet på denna produkt. Den används som en alternativ nyckel för denna tabell i kombination medproduct_category_idattribut. Det är osannolikt att vi kommer att ha två produkter med samma namn som tillhör olika kategorier, men det är ändå en möjlighet.product_category_id— identifierar kategorin som denna produkt tillhör.product_description— textbeskrivning av denna produkt.
Ämnesområde #3:Klienter
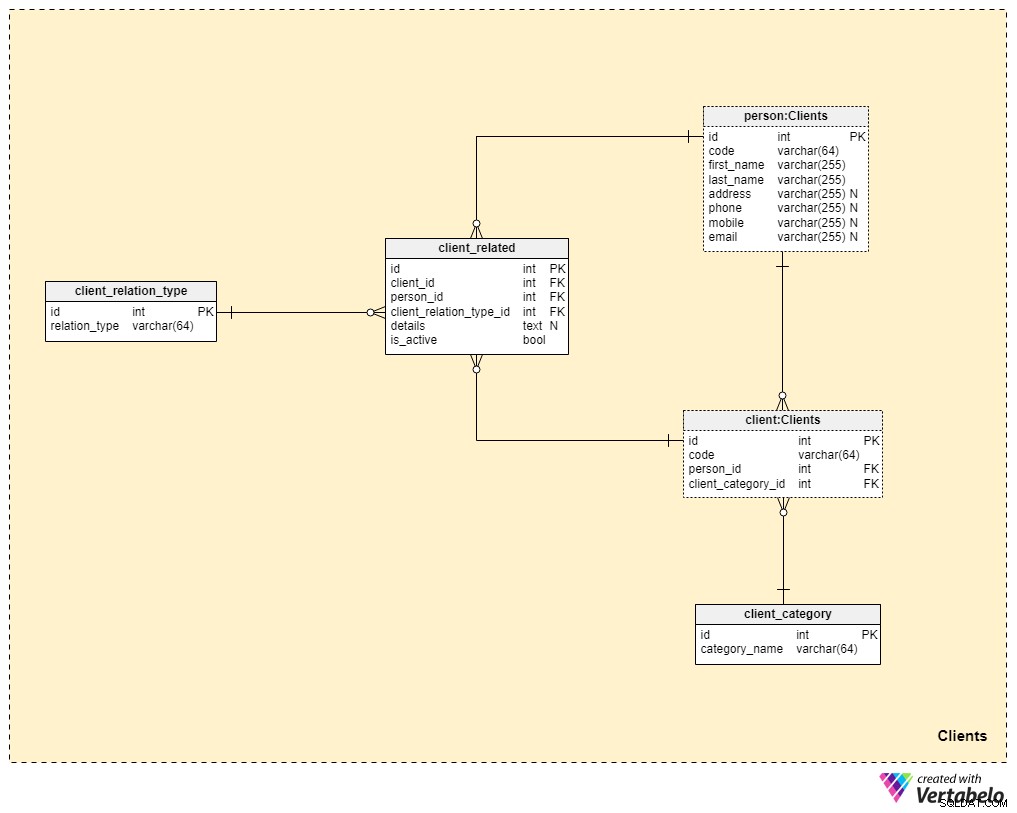
Vi kommer nu mycket närmare kärnan i vår datamodell, men vi är inte riktigt där än. Livförsäkring är unik eftersom en försäkring kan överföras till en familjemedlem eller någon annan, medan försäkringar för andra former av försäkringar (som sjukförsäkring eller bilförsäkring) tillhör en enskild kund och inte kan överlåtas. Av denna anledning behöver vi inte bara lagra information om klienten som försäkringen tillhör utan också information om relaterade personer och deras relation till klienten.
Vi börjar med client tabell. För varje klient kommer vi att lagra den unika koden som genererats eller infogats manuellt för den klienten, såväl som främmande nycklar som refererar till tabellen med deras personliga data (person_id ) och tabellen som innehåller vår interna kategorisering (client_category_id ).
client_category ordboken låter oss gruppera kunder baserat på deras demografiska och ekonomiska uppgifter. Kundkategorierna kommer sedan att användas för att fastställa vilken försäkring vi är redo att erbjuda till en viss kund. Här lagrar vi bara en lista med unika värden som vi sedan tilldelar kunderna.
Eftersom vi pratar om livförsäkring, så vi antar att en kund är en enskild individ. Men som vi nämnde tidigare kan det finnas andra personer relaterade till klienten som försäkringen kan överföras till eller som kan få försäkringsförmånen vid klientens död. Av denna anledning har vi skapat en separat person tabell. För varje post i den här tabellen lagrar vi följande information:
code— ett automatiskt genererat eller manuellt infogat värde som används för att unikt identifiera den relaterade personen.first_nameochlast_name— personens för- respektive efternamn.address,phone,mobileochemail— kontaktuppgifter för denna person, som alla innehåller godtyckliga värden.
De återstående två tabellerna i detta ämnesområde behövs för att beskriva karaktären av relationen mellan klienter och andra människor.
Listan över alla möjliga relationstyper lagras i client_relation_type lexikon. Precis som med andra ordböcker kommer detta att innehålla en lista med unika namn som vi senare kommer att använda när vi beskriver relationen mellan en viss klient och en annan person.
Faktiska relationsdata lagras i client_related tabell. För varje post i den här tabellen lagrar vi referenser till klienten (client_id ), den relaterade personen (person_id ), typen av den relationen (client_relation_type_id ), alla tilläggsdetaljer (details ), om någon, och en flagga som indikerar om relationen för närvarande är aktiv (is_active ). Den alternativa nyckeln i den här tabellen definieras av kombinationen av client_id , person_id och client_relation_type_id .
Ämnesområde #4:Erbjudanden
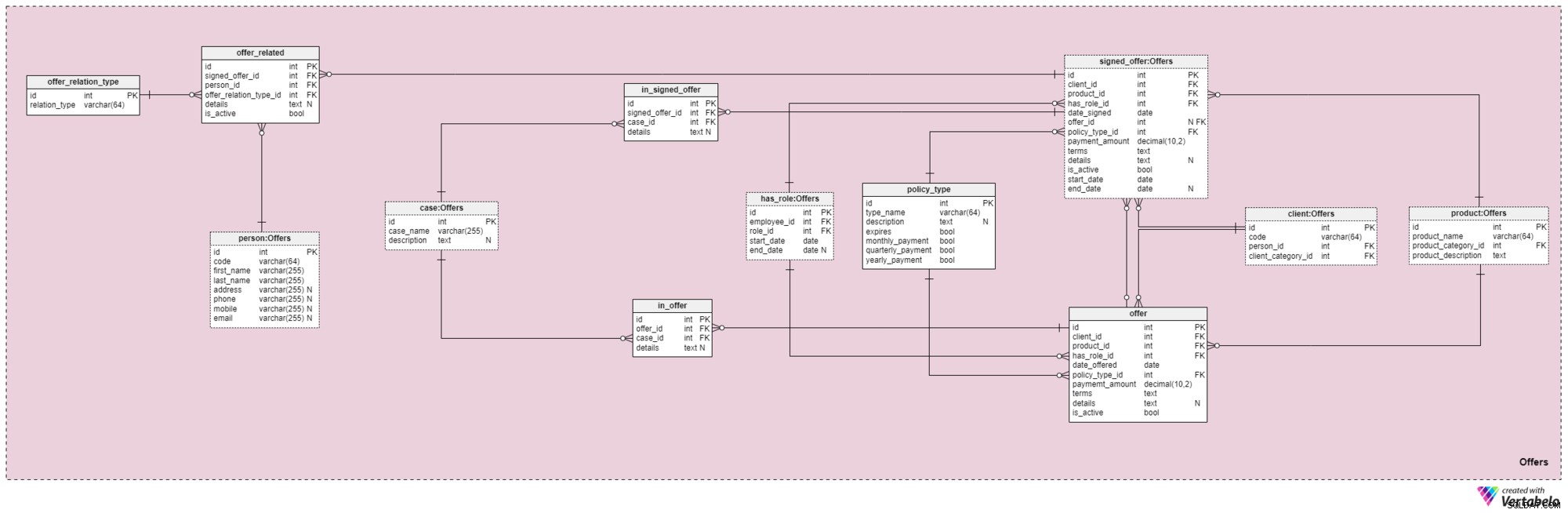
Detta ämnesområde och det som följer är kärnan i denna datamodell. De täcker erbjudanden och signerade försäkringar, samt betalningar relaterade till erbjudanden. Först kommer vi att beskriva ämnesområdet Erbjudanden. Det kan verka komplicerat eftersom det innehåller 12 tabeller. Men fyra av dessa 12 (has_role , product , client och person ) beskrevs i tidigare ämnesområden, så vi kommer inte att upprepa vår diskussion här.
offer och signed_offer tabeller har liknande strukturer eftersom de kommer att användas för att lagra mycket liknande data i vår modell. Men medan offer kommer huvudsakligen att användas för att lagra alla policyer (och deras uppgifter) som vi har erbjudit våra kunder, signed_offer Tabellen kommer att användas strikt för att lagra information om kunder som faktiskt har undertecknat policyer med vårt företag. Vi kommer att täcka dessa tabeller tillsammans och notera eventuella skillnader där de förekommer. Attributen i dessa två tabeller är följande:
client_id— hänvisning till den unika identifieraren för kunden som undertecknade ett visst erbjudande.product_id— hänvisning till den unika identifieraren för produkten som ingick i det undertecknade erbjudandet.has_role_id— hänvisning till den anställdes ID och den roll de hade när erbjudandet presenterades/undertecknades.date_offeredochdate_signed— faktiska datum som anger när detta erbjudande presenterades för kunden respektive när det undertecknades.offer_id— en hänvisning till det tidigare erbjudandet för denna kund. Detta kan innehålla ett värde på null eftersom kunden kunde ha skrivit på en policy utan att ha något tidigare erbjudande från företaget, till exempel om de kontaktade oss på egen hand. Det här attributet tillhör striktsigned_offertabell.policy_type_id— hänvisning till ordboken av policytyp som anger vilken typ av policy vi erbjöd kunden eller fick dem att skriva under.payment_amount— det belopp som kunden måste betala för försäkringen regelbundet.terms— alla villkor i avtalet, i textformat (XML). Tanken är att lagra alla viktiga detaljer om den ekonomiska delen av policyn i detta attribut. Exempel på text vi kan lagra är det totala försäkringsbeloppet, antalet betalningar som kunden måste göra och så vidare.details— eventuella ytterligare detaljer, i textformat.is_active— flagga som anger om posten fortfarande är aktiv.start_dateochend_date— ange det tidsintervall inom vilket denna policy är/var aktiv. Om policyn undertecknades för en livstid kommer slutdatum att innehålla värdet null.
Det finns också policy_type ordbok som vi kort nämnt tidigare. Vi behöver en viss grad av flexibilitet i hur vi erbjuder samma produkt till olika kunder, baserat på faktorer som ålder, hälsa, civilstånd, kreditrisk och så vidare. För varje policytyp lagrar vi ett type_name identifierare, en ytterligare textlig description , en flagga med namnet löper ut som anger om försäkringen kan löpa ut, och en annan flagga som anger om försäkringstypens premier måste betalas månadsvis, kvartalsvis eller årligen. Några förväntade försäkringstyper är:Livslängd, Hela livet, Universellt liv, Garanterat Universellt Liv, Variabelt Liv, Variabelt Universellt Liv och Livförsäkring efter pensionering.
När vi går vidare måste vi nu definiera alla fall och situationer som en viss policy kan täcka. Vi måste relatera dessa fall till specifika erbjudanden och undertecknade erbjudanden.
Listan över alla möjliga fall som våra försäkringar täcker lagras i case lexikon. Varje post i den här tabellen kan identifieras unikt med dess case_name och har en ytterligare description , om en sådan behövs.
in_offer och in_signed_offer tabeller delar samma struktur eftersom de lagrar samma data. Den enda skillnaden mellan de två är att den första lagrar ärenden som omfattas av försäkringen som bara erbjöds kunden, medan den andra lagrar ärenden i försäkringen som undertecknats av kunden. För varje post i dessa två tabeller lagrar vi det unika paret offer_id /signed_offer_id och case_id , varav den senare anger det fall eller incident som omfattas av försäkringen. Alla andra detaljer kommer att lagras i ett textattribut om det behövs.
Som vi nämnde tidigare är livförsäkringar nästan alltid relaterade inte bara till kunder utan även till deras familjemedlemmar eller släktingar. Vi måste lagra dessa relationer även på detta område. De kommer att definieras när en policy undertecknas, men de kan också ändras under hela policyn.
Det första vi behöver göra är att skapa en ordbok som innehåller alla möjliga värden som kan tilldelas en relation. I vår modell är detta offer_relation_type lexikon. Förutom primärnyckeln innehåller den här tabellen bara ett attribut – relation_type – som bara kan innehålla unika värden.
Vi är nästan där! Den sista tabellen i detta ämnesområde heter offer_related . Det avser ett undertecknat erbjudande till alla som är släkt med kunden. Därför måste vi lagra referenser till den signerade policyn (signed_offer_id ) och den relaterade personen (person_id ) och ange även typen av den relationen (offer_relation_type_id ). Dessutom måste vi lagra details relaterad till denna post och skapa en flagga för att kontrollera om den fortfarande är giltig i vårt system.
Ämnesområde #5:Betalningar
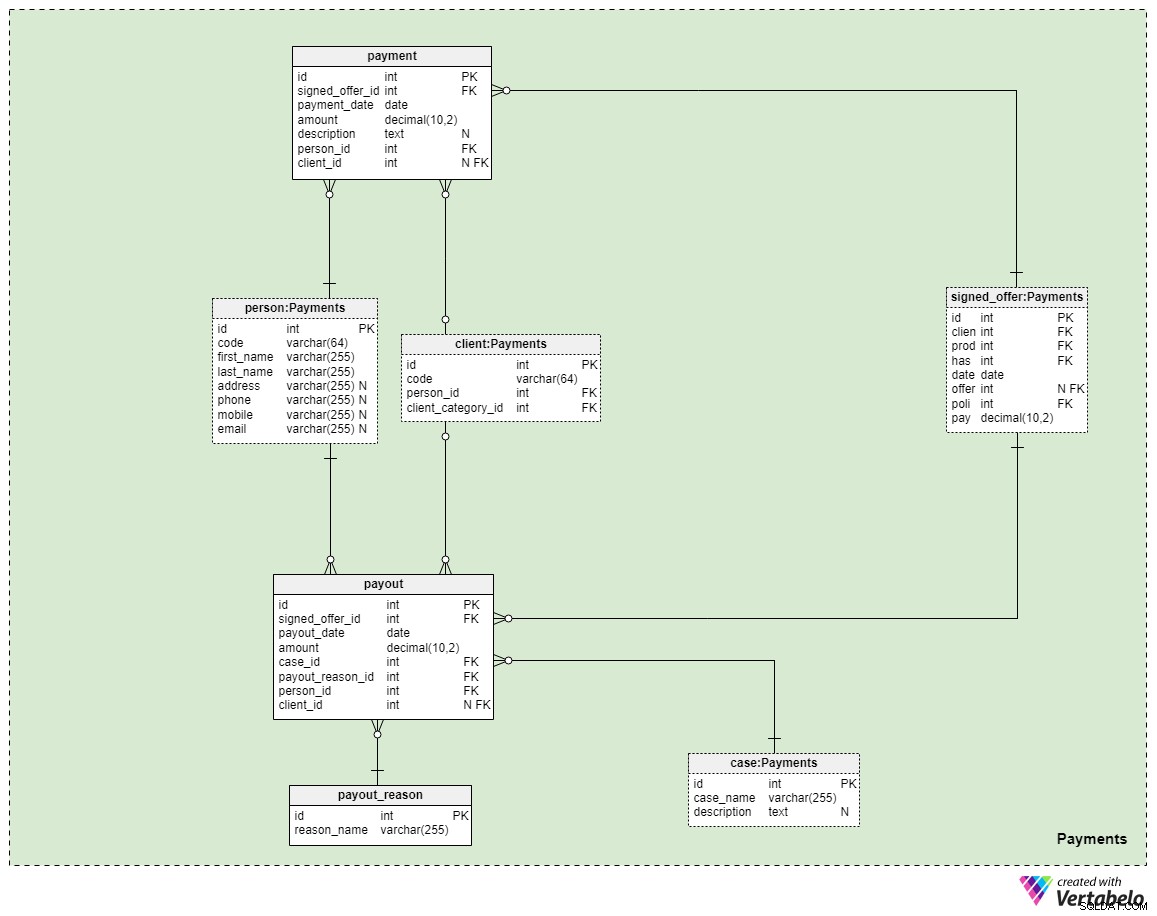
Det sista ämnesområdet i vår modell handlar om betalningar. Här introducerar vi bara tre nya tabeller:payment , payout_reason och payout .
Alla betalningar relaterade till policyer lagras i payment tabell. Vi inkluderade bara de viktigaste attributen här:
signed_offer_id— hänvisning till den unika identifieraren för det undertecknade erbjudandet (policy).payment_date— det datum då denna betalning gjordes.amount— det faktiska beloppet som betalades.description— en valfri beskrivning av betalningen, i textformat.person_id— Hänvisning till den unika identifieraren för den person som gjorde betalningen. Observera att kunden som undertecknade erbjudandet inte nödvändigtvis är den enda personen som kan göra en betalning.client_id— hänvisning till den unika identifieraren för den kund som gjorde betalningen. Det här attributet kommer endast att innehålla ett värde om kunden själv har gjort betalningen.
De återstående två tabellerna representerar kanske den viktigaste anledningen till att vi betalar för livförsäkring - att i händelse av att något skulle hända oss kommer utbetalningar att göras till våra familjemedlemmar eller liv-/affärspartners. Hur detta händer beror på din situation och villkoren för den specifika policy du skrev under. Vi använder två enkla tabeller för att täcka dessa fall.
Den första är en ordbok med titeln payout_reason och har en klassisk ordboksstruktur. Förutom det primära nyckelattributet har vi bara ett attribut – reason_name – som kommer att lagra en lista med unika värden som anger varför denna utbetalning gjordes.
Den sista tabellen i modellen är payout tabell. Det är väldigt likt payment tabell, men de viktigaste skillnaderna noteras nedan:
payout_date— det datum då utbetalningen gjordes.case_id— hänvisning till den unika identifieraren för det relaterade fall eller incident som utlöste betalningen. Detta bör matcha ett av ID:n som ingår i policyn.payout_reason_id— hänvisning till ordboken som beskriver orsaken till utbetalningen mer detaljerat. Även om utbetalningsfallet är kortare och mer allmänt, kommer utbetalningsorsaken att ge mer specifik information om vad som hände.person_idochclient_id— hänvisar till personen och klienten relaterade till utbetalningen, respektive.
Sammanfattning
Grymt bra! Vi har framgångsrikt byggt vår livförsäkringsdatamodell. Innan vi avslutar vår diskussion är det värt att notera att det finns mycket mer som kan tas upp i den här modellen. I den här artikeln ville vi främst täcka grunderna i modellen för att ge dig en uppfattning om hur den ser ut och fungerar. Här är några fler detaljer som man skulle kunna införliva i en sådan datamodell:
- Ytterligare policyuppgraderingar täcks inte av vår nuvarande modell (om du t.ex. vill göra årliga erbjudanden för befintliga policyer kommer du inte att kunna göra det med den här strukturen). Vi bör lägga till några fler tabeller för att lagra alla policyändringar för presenterade/signerade erbjudanden.
- Allt pappersarbete har avsiktligt utelämnats. Naturligtvis kommer det att finnas en hel del pappersarbete i samband med en viss livförsäkring, särskilt för signeringsprocessen och utbetalningar. Vi kan bifoga dokument som beskriver klientens status vid tidpunkten för undertecknandet av policyn och eventuella ändringar på vägen, såväl som alla dokument relaterade till utbetalningar.
- Denna modell innehåller inte den struktur som krävs för beräkning av policyrisk. Vi bör ha alla parametrar som vi behöver testa och alla intervall som avgör hur en kunds värde påverkar den övergripande beräkningen. Resultaten av dessa beräkningar skulle behöva lagras för varje erbjudande och undertecknad policy.
- Fakturustrukturen är i verkligheten mycket mer komplex än vad vi täckte inom ämnesområdet betalningar. Vi nämnde inte ens finansiella konton någonstans i vår modell.
Tydligen är försäkringsverksamheten ganska komplex. Vi diskuterade bara en datamodell för livförsäkring i den här artikeln - kan du föreställa dig hur denna datamodell skulle utvecklas om vi skulle driva ett företag som erbjuder ett antal olika försäkringstyper? Det skulle säkert kräva mycket planering och eftertanke för att presentera en organiserad datamodell för ett sådant företag.
Om du har några förslag eller idéer för att förbättra vår datamodell får du gärna meddela oss i kommentarerna nedan!