Du har förmodligen gjort några av dessa misstag när du började din databasdesignkarriär. Kanske gör du dem fortfarande, eller så kommer du att göra några i framtiden. Vi kan inte gå tillbaka i tiden och hjälpa dig att ångra dina fel, men vi kan rädda dig från framtida (eller nuvarande) huvudvärk.
Genom att läsa den här artikeln kan du spara många timmar på att fixa design- och kodproblem, så låt oss dyka in. Jag har delat upp listan över fel i två huvudgrupper:de som är icke-tekniska till sin natur och de som är enbart tekniska . Båda dessa grupper är en viktig del av databasdesign.
Uppenbarligen, om du inte har tekniska färdigheter, kommer du inte att veta hur man gör något. Det är inte förvånande att se dessa fel på listan. Men icke-tekniska färdigheter? Folk kanske glömmer dem, men dessa färdigheter är också en mycket viktig del av designprocessen. De tillför värde till din kod och de relaterar tekniken till det verkliga problem du behöver lösa.
Så låt oss börja med de icke-tekniska problemen först och sedan gå vidare till de tekniska.
Icke-tekniska databasdesignfel
#1 Dålig planering
Detta är definitivt ett icke-tekniskt problem, men det är ett stort och vanligt problem. Vi blir alla exalterade när ett nytt projekt startar och när vi går in i det ser allt bra ut. I början är projektet fortfarande en tom sida och du och din kund börjar gärna arbeta med något som kommer att skapa en bättre framtid för er båda. Det här är jättebra, och en stor framtid kommer förmodligen att bli det slutliga resultatet. Men ändå måste vi hålla fokus. Detta är den del av projektet där vi kan göra avgörande misstag.
Innan du sätter dig ner för att rita en datamodell måste du vara säker på att:
- Du är helt medveten om vad din kund gör (dvs. deras affärsplaner relaterade till detta projekt och även deras övergripande bild) och vad de vill att detta projekt ska uppnå nu och i framtiden.
- Du förstår affärsprocessen och, om eller när det behövs, är du redo att ge förslag för att förenkla och förbättra den (t.ex. för att öka effektiviteten och intäkterna, minska kostnader och arbetstimmar, etc).
- Du förstår dataflödet i kundens företag. Helst skulle du känna till varje detalj:vem som arbetar med data, vem som gör ändringar, vilka rapporter som behövs, när och varför allt detta händer.
- Du kan använda språket/terminologin som din klient använder. Även om du kanske eller kanske inte är expert inom deras område, är din klient definitivt det. Be dem förklara det du inte förstår. Och när du förklarar tekniska detaljer för kunden, använd språk och terminologi som de förstår.
- Du vet vilka tekniker du kommer att använda, från databasmotorn och programmeringsspråken till andra verktyg. Vad du väljer att använda är nära relaterat till problemet du ska lösa, men det är viktigt att inkludera kundens preferenser och deras nuvarande IT-infrastruktur.
Under planeringsfasen bör du få svar på dessa frågor:
- Vilka tabeller kommer att vara de centrala tabellerna i din modell? Du kommer förmodligen att ha några av dem, medan de andra tabellerna kommer att vara några av de vanliga (t.ex. användarkonto, roll). Glöm inte ordböcker och relationer mellan tabeller.
- Vilka namn kommer att användas för tabeller i modellen? Kom ihåg att hålla terminologin liknande den som klienten använder för närvarande.
- Vilka regler kommer att gälla vid namngivning av tabeller och andra objekt? (Se punkt 4 om namnkonventioner.)
- Hur lång tid tar hela projektet? Detta är viktigt, både för ditt schema och för kundens tidslinje.
Först när du har alla dessa svar är du redo att dela en första lösning på problemet. Den lösningen behöver inte vara en komplett ansökan – kanske ett kort dokument eller till och med några meningar på språket för kundens verksamhet.
God planering är inte specifik för datamodellering; det är tillämpligt på nästan alla IT-projekt (och icke-IT-projekt). Att hoppa över är bara ett alternativ om 1) du har ett riktigt litet projekt; 2) uppgifterna och målen är tydliga, och 3) du har riktigt bråttom. Ett historiskt exempel är Sputnik 1 lanseringsingenjörer som ger verbala instruktioner till teknikerna som monterade den. Projektet hade bråttom på grund av nyheten att USA planerar att skjuta upp sin egen satellit snart – men jag antar att du inte kommer att ha så bråttom.
#2 Otillräcklig kommunikation med kunder och utvecklare
När du startar databasdesignprocessen kommer du förmodligen att förstå de flesta av huvudkraven. Vissa är väldigt vanliga oavsett verksamhet, t.ex. användarroller och statuser. Å andra sidan kommer vissa tabeller i din modell att vara ganska specifika. Till exempel, om du bygger en modell för ett taxiföretag, har du bord för fordon, förare, kunder etc.
Ändå kommer inte allt att vara självklart i början av ett projekt. Du kan missförstå vissa krav, klienten kan lägga till några nya funktioner, du kommer att se något som kan göras annorlunda, processen kan ändras, etc. Alla dessa orsakar förändringar i modellen. De flesta ändringar kräver att du lägger till nya tabeller, men ibland kommer du att ta bort eller ändra tabeller. Om du redan har börjat skriva kod som använder dessa tabeller, måste du också skriva om den koden.
För att minska tiden som ägnas åt oväntade ändringar bör du:
- Prata med utvecklare och kunder och var inte rädd för att ställa viktiga affärsfrågor. När du tror att du är redo att börja, fråga dig själv Täcks situation X i vår databas? Klienten gör för närvarande Y på detta sätt; förväntar vi oss en förändring inom en snar framtid? När vi är säkra på att vår modell har förmågan att lagra allt vi behöver på rätt sätt kan vi börja koda.
- Om du står inför en stor förändring i din design och du redan har skrivit mycket kod, bör du inte försöka hitta en snabb lösning. Gör det som det skulle ha gjorts, oavsett hur det är i dagsläget. En snabb lösning kan spara lite tid nu och skulle förmodligen fungera bra ett tag, men det kan förvandlas till en riktig mardröm senare.
- Om du tror att något är okej nu men kan bli ett problem senare, ignorera det inte. Analysera det området och implementera ändringar om de kommer att förbättra systemets kvalitet och prestanda. Det kommer att kosta lite tid, men du kommer att leverera en bättre produkt och sova mycket bättre.
Om du försöker undvika att göra ändringar i din datamodell när du ser ett potentiellt problem - eller om du väljer en snabb lösning istället för att göra det ordentligt - kommer du att betala för det förr eller senare.
Håll också kontakten med din kund och utvecklarna under hela projektet. Kontrollera alltid och se om några ändringar har gjorts sedan din senaste diskussion.
#3 Dålig eller saknad dokumentation
För de flesta av oss kommer dokumentation i slutet av projektet. Om vi är välorganiserade har vi förmodligen dokumenterat saker på vägen och vi behöver bara avsluta allt. Men ärligt talat så brukar det inte vara så. Att skriva dokumentation sker precis innan projektet stängs – och precis efter att vi mentalt är färdiga med den datamodellen!
Priset som betalas för ett dåligt dokumenterat projekt kan vara ganska högt, några gånger högre än priset vi betalar för att dokumentera allt ordentligt. Föreställ dig att hitta en bugg några månader efter att du har avslutat projektet. Eftersom du inte dokumenterade ordentligt vet du inte var du ska börja.
Glöm inte att skriva kommentarer medan du arbetar. Förklara allt som behöver ytterligare förklaras, och skriv i princip ner allt du tror kommer att vara användbart en dag. Du vet aldrig om eller när du behöver den extra informationen.
Tekniska databasdesignfel
#4 Använder inte en namnkonvention
Du vet aldrig säkert hur länge ett projekt kommer att pågå och om du kommer att ha mer än en person som arbetar med datamodellen. Det finns en punkt när du är riktigt nära datamodellen, men du har inte börjat rita den ännu. Det är då det är klokt att bestämma hur du ska namnge objekt i din modell, i databasen och i den allmänna applikationen. Innan du börjar modellera bör du veta:
- Är tabellnamn singular eller plural?
- Kommer vi att gruppera tabeller med namn? (T.ex. alla klientrelaterade tabeller innehåller "client_", alla uppgiftsrelaterade tabeller innehåller "task_", etc.)
- Kommer vi att använda stora och små bokstäver, eller bara små bokstäver?
- Vilket namn kommer vi att använda för ID-kolumnerna? (Det kommer troligen att vara "id".)
- Hur namnger vi främmande nycklar? (Med största sannolikhet "id_" och namnet på den refererade tabellen.)
Jämför en del av en modell som inte använder namnkonventioner med samma del som använder namnkonventioner, som visas nedan:
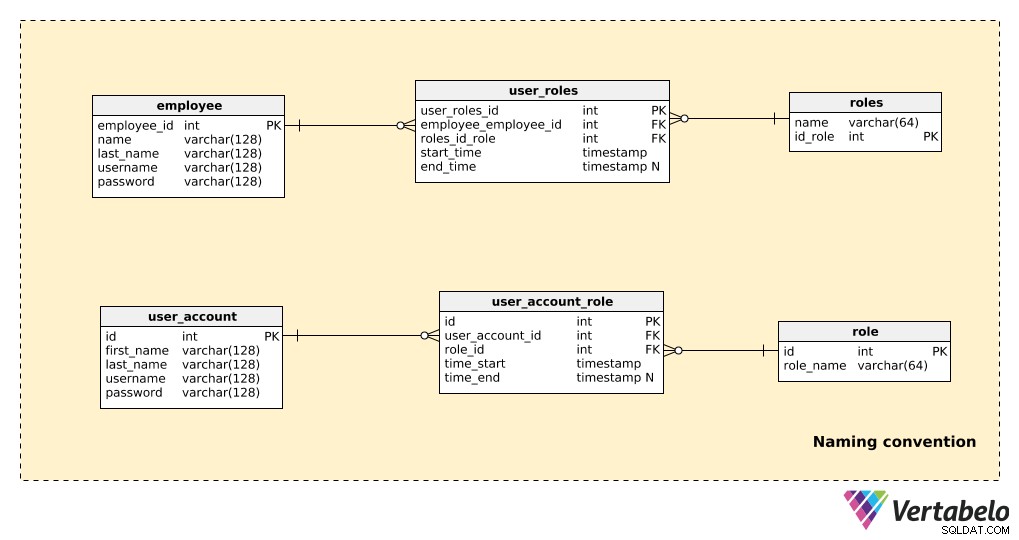
Det finns bara ett fåtal tabeller här, men det är fortfarande ganska uppenbart vilken modell som är lättare att läsa. Lägg märke till att:
- Båda modellerna "fungerar", så det finns inga problem på den tekniska sidan.
- I exemplet utan namnkonvention (de tre övre tabellerna) finns det några saker som väsentligt påverkar läsbarheten:att använda både singular- och pluralformer i tabellnamnen; icke-standardiserade primärnyckelnamn (
employees_id,id_role); och attribut i olika tabeller delar samma namn (t.ex. namn visas i både "employee" och "roles” tabeller).
Föreställ dig nu vilken röra vi skulle skapa om vår modell innehöll hundratals tabeller. Vi kanske skulle kunna arbeta med en sådan modell (om vi skapade den själva) men vi skulle göra någon väldigt otur om de var tvungna att arbeta med den efter oss.
För att undvika framtida problem med namn, använd inte reserverade SQL-ord, specialtecken eller mellanslag i dem.
Så innan du börjar skapa några namn, skapa ett enkelt dokument (kanske bara några sidor långt) som beskriver namnkonventionen du har använt. Detta kommer att öka läsbarheten för hela modellen och förenkla framtida arbete.
Du kan läsa mer om namnkonventioner i dessa två artiklar:
- Namnkonventioner i databasmodellering
- En känslolös logisk titt på SQL Server-namnkonventioner
#5 normaliseringsproblem
Normalisering är en viktig del av databasdesign. Varje databas bör normaliseras till minst 3NF (primära nycklar är definierade, kolumner är atomära och det finns inga upprepade grupper, partiella beroenden eller transitiva beroenden). Detta minskar dataduplicering och säkerställer referensintegritet.
Du kan läsa mer om normalisering i den här artikeln. Kort sagt, när vi pratar om relationsdatabasmodellen talar vi om den normaliserade databasen. Om en databas inte är normaliserad kommer vi att stöta på en massa problem relaterade till dataintegritet.
I vissa fall kanske vi vill avnormalisera vår databas. Om du gör detta, ha en riktigt bra anledning. Du kan läsa mer om databasdenormalisering här.
#6 Använda modellen Entity-Attribute-Value (EAV)
EAV står för entity-attribute-value. Denna struktur kan användas för att lagra ytterligare data om vad som helst i vår modell. Låt oss ta en titt på ett exempel.
Anta att vi vill lagra några ytterligare kundattribut. "customer tabellen är vår enhet, "attribute Tabellen är uppenbarligen vårt attribut och "attribute_value Tabellen innehåller värdet av det attributet för den kunden.
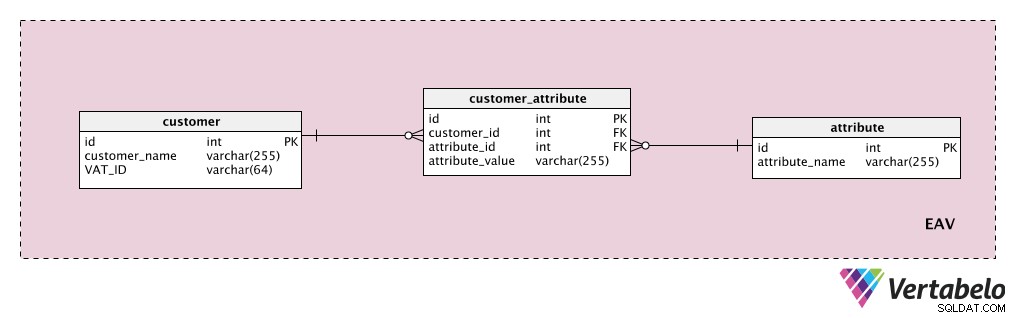
Först lägger vi till en ordbok med en lista över alla möjliga egenskaper vi kan tilldela en kund. Detta är "attribute ” tabell. Det kan innehålla egenskaper som "kundvärde", "kontaktuppgifter", "ytterligare information" etc. "customer_attribute Tabellen innehåller en lista över alla attribut, med värden, för varje kund. För varje kund kommer vi bara att ha poster för de attribut de har, och vi lagrar "attribute_value ” för det attributet.
Det här kan verka riktigt bra. Det skulle tillåta oss att enkelt lägga till nya egenskaper (eftersom vi lägger till dem som värden i "customer_attribute ” tabell). Därmed skulle vi undvika att göra ändringar i databasen. Nästan för bra för att vara sant.
Och det är för bra. Även om modellen kommer att lagra den data vi behöver, är det mycket mer komplicerat att arbeta med sådan data. Och det inkluderar nästan allt, från att skriva enkla SELECT-frågor till att få alla kundrelaterade värden till att infoga, uppdatera eller ta bort värden.
Kort sagt, vi bör undvika EAV-strukturen. Om du måste använda den, använd den bara när du är 100 % säker på att den verkligen behövs.
#7 Använda en GUID/UUID som primärnyckel
En GUID (Globally Unique Identifier) är ett 128-bitars nummer som genereras enligt regler som definieras i RFC 4122. De är ibland också kända som UUID (Universally Unique Identifiers). Den största fördelen med en GUID är att den är unik; chansen att du slår samma GUID två gånger är verkligen osannolik. Därför verkar GUID vara en utmärkt kandidat för kolumnen för primärnyckeln. Men så är inte fallet.
En allmän regel för primärnycklar är att vi använder en heltalskolumn med egenskapen autoincrement inställd på "yes". Detta kommer att lägga till data i sekventiell ordning till den primära nyckeln och ge optimal prestanda. Utan en sekventiell nyckel eller en tidsstämpel går det inte att veta vilken data som infogades först. Detta problem uppstår också när vi använder UNIKA verkliga värden (t.ex. ett momsregistreringsnummer). Även om de har UNIKA värden, är de inte bra primärnycklar. Använd dem som alternativa nycklar istället.
En ytterligare anmärkning: Jag föredrar att använda enkolumns automatiskt genererade heltalsattribut som primärnyckel. Det är definitivt den bästa praxisen. Jag rekommenderar att du undviker att använda sammansatta primärnycklar.
#8 Otillräcklig indexering
Index är en mycket viktig del av arbetet med databaser, men en grundlig diskussion om dem ligger utanför den här artikelns omfattning. Lyckligtvis har vi redan några artiklar relaterade till index som du kan kolla in för att lära dig mer:- Vad är ett databasindex?
- Allt om index:Grunderna
- Allt om index del 2:MySQL-indexstruktur och prestanda
Den korta versionen är att jag rekommenderar att du lägger till ett index varhelst du förväntar dig att det kommer att behövas. Du kan också lägga till dem efter att databasen är i produktion om du ser att prestandan förbättras om du lägger till index på en viss plats.
#9 Redundanta data
Redundanta data bör i allmänhet undvikas i alla modeller. Det tar inte bara upp ytterligare diskutrymme utan det ökar också avsevärt risken för dataintegritetsproblem. Om något måste vara överflödigt bör vi se till att originaldata och "kopian" alltid är i konsekventa tillstånd. Faktum är att det finns vissa situationer där redundant data är önskvärt:
- I vissa fall måste vi tilldela prioritet till en viss åtgärd – och för att få detta att hända måste vi utföra komplexa beräkningar. Dessa beräkningar skulle kunna använda många tabeller och förbruka mycket resurser. I sådana fall skulle det vara klokt att utföra dessa beräkningar under ledig tid (och därmed undvika prestationsproblem under arbetstid). Om vi gör det på det här sättet kan vi lagra det beräknade värdet och använda det senare utan att behöva räkna om det. Naturligtvis är värdet redundant; Men vad vi vinner i prestanda är betydligt mer än vad vi förlorar (en del hårddiskutrymme).
- Vi kan också lagra en liten uppsättning rapportdata i databasen. Till exempel, i slutet av dagen kommer vi att lagra antalet samtal vi gjorde den dagen, antalet framgångsrika försäljningar, etc. Rapporteringsdata bör endast lagras på detta sätt om vi behöver använda dem ofta. Återigen kommer vi att förlora lite utrymme på hårddisken, men vi kommer att undvika att räkna om data eller ansluta till rapportdatabasen (om vi har en sådan).
I de flesta fall bör vi inte använda redundant data eftersom:
- Att lagra samma data mer än en gång i databasen kan påverka dataintegriteten. Om du lagrar en kunds namn på två olika platser bör du göra eventuella ändringar (infoga/uppdatera/ta bort) på båda platserna samtidigt. Detta komplicerar också koden du behöver, även för de enklaste operationerna.
- Medan vi kan lagra vissa aggregerade nummer i vår operativa databas, bör vi göra detta endast när vi verkligen behöver det. En operativ databas är inte avsedd att lagra rapporteringsdata, och att blanda dessa två är i allmänhet en dålig praxis. Alla som producerar rapporter måste använda samma resurser som användare som arbetar med operativa uppgifter; rapporteringsfrågor är vanligtvis mer komplexa och kan påverka prestandan. Därför bör du separera din operativa databas och din rapportdatabas.
Nu är det din tur att väga in
Jag hoppas att läsningen av den här artikeln har gett dig några nya insikter och kommer att uppmuntra dig att följa bästa praxis för datamodellering. De kommer att spara lite tid!
Har du upplevt något av problemen som nämns i den här artikeln? Tror du att vi har missat något viktigt? Eller tycker du att vi ska ta bort något från vår lista? Berätta för oss i kommentarerna nedan.