Introduktion
Utvecklare uppmanas ofta att använda lagrade procedurer för att undvika de så kallade ad hoc-frågorna vilket kan resultera i onödig uppblåsthet av planens cache. Du förstår, när återkommande SQL-kod skrivs inkonsekvent eller när det finns kod som genererar dynamisk SQL i farten, har SQL Server en tendens att skapa en exekveringsplan för varje enskild exekvering. Detta kan minska den totala prestandan med:
Kräver en kompileringsfas för varje kodexekvering.
Uppblåsa plancachen med för många planhandtag som kanske inte kan återanvändas.
Optimera för ad hoc-arbetsbelastningar
Ett sätt som detta problem hanterades tidigare är att optimera instansen för ad hoc-arbetsbelastningar. Att göra detta kan bara vara till hjälp om de flesta databaser eller de viktigaste databaserna i instansen huvudsakligen kör Ad Hoc SQL.
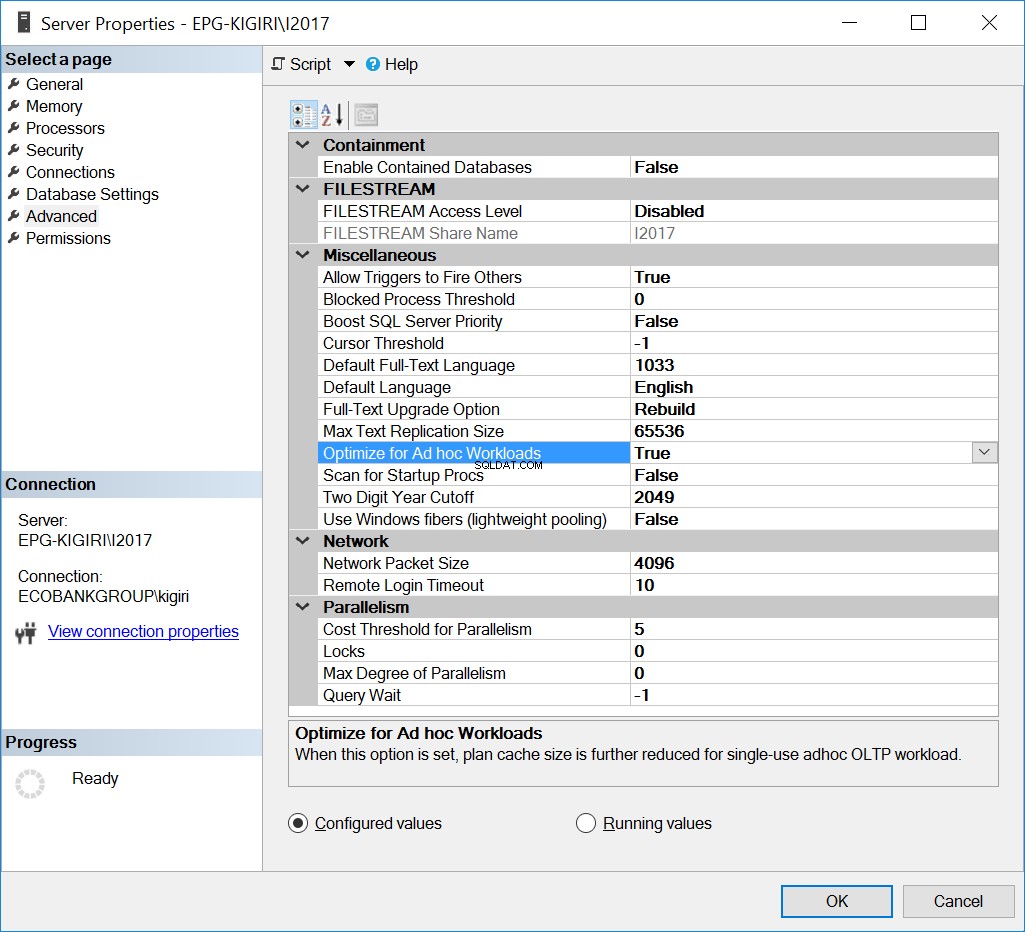
Fig. 1 Optimera för ad hoc-arbetsbelastningar
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
I huvudsak säger detta alternativ till SQL Server att spara en delversion av planen som kallas den kompilerade planen. Stubben tar mycket mindre plats än hela planen.
Som ett alternativ till den här metoden, tar vissa människor sig an frågan ganska brutalt och tömmer plancachen då och då. Eller, på ett mer försiktigt sätt, spola "engångsplaner" genom att använda DBCC FREESYSTEMCACHE. Att spola hela plancachen har sina nackdelar, som du kanske redan vet.
Använda lagrade procedurer och parametrar
Genom att använda lagrade procedurer kan man praktiskt taget eliminera problemet som orsakas av Ad Hoc SQL. En lagrad procedur kompileras endast en gång och samma plan återanvänds för efterföljande körningar av samma eller liknande SQL-frågor. När lagrade procedurer används för att implementera affärslogik, ligger nyckelskillnaden i SQL-frågorna som så småningom kommer att exekveras av SQL Server i parametrarna som skickas vid körningstidpunkten. Eftersom planen redan är på plats och klar för användning kommer SQL Server att använda samma plan oavsett vilken parameter som skickas.
Skev data
I vissa scenarier är informationen vi har att göra med inte jämnt fördelad. Vi kan visa detta – först måste vi skapa en tabell:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); Vår tabell innehåller data om klubbmedlemmar från olika länder. Ett stort antal klubbmedlemmar är från Ghana, medan två andra nationer har tio respektive två medlemmar. För att hålla fokus på agendan och för enkelhetens skull använde jag bara tre länder och samma namn för medlemmar som kommer från samma land. Jag lade också till ett klustrat index i ID-kolumnen och ett icke-klustrat index i CountryCode-kolumnen för att visa effekten av olika exekveringsplaner för olika värden.
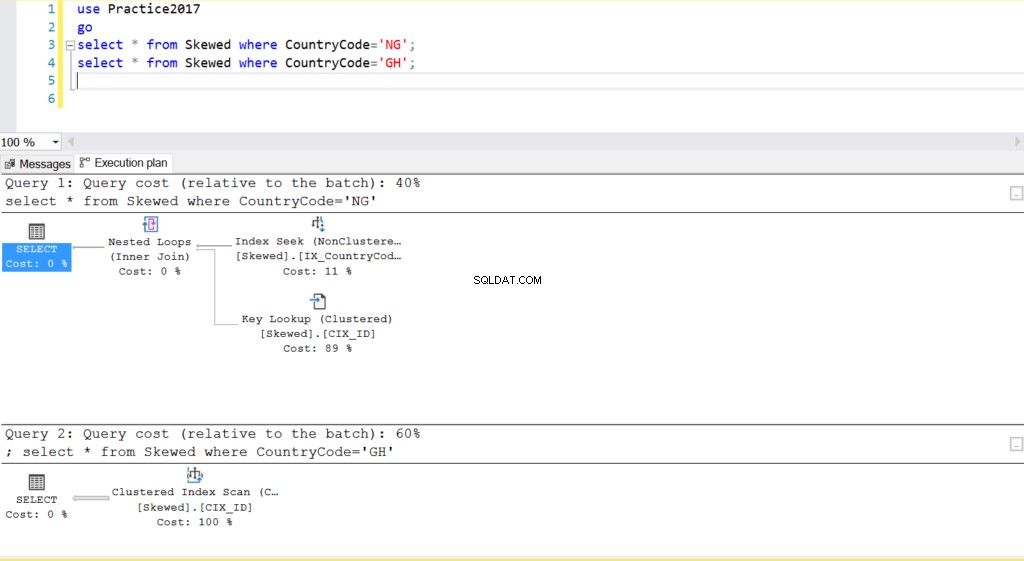
Fig. 2 exekveringsplaner för två frågor
När vi frågar tabellen efter poster där CountryCode är NG och GH, finner vi att SQL Server använder två olika exekveringsplaner i dessa fall. Detta beror på att det förväntade antalet rader för CountryCode='NG' är 10, medan det för CountryCode='GH' är 10000. SQL Server bestämmer den föredragna exekveringsplanen baserat på tabellstatistik. Om det förväntade antalet rader är högt jämfört med det totala antalet rader i tabellen, beslutar SQL Server att det är bättre att helt enkelt göra en fullständig tabellsökning istället för att hänvisa till ett index. Med ett mycket mindre uppskattat antal rader blir indexet användbart.
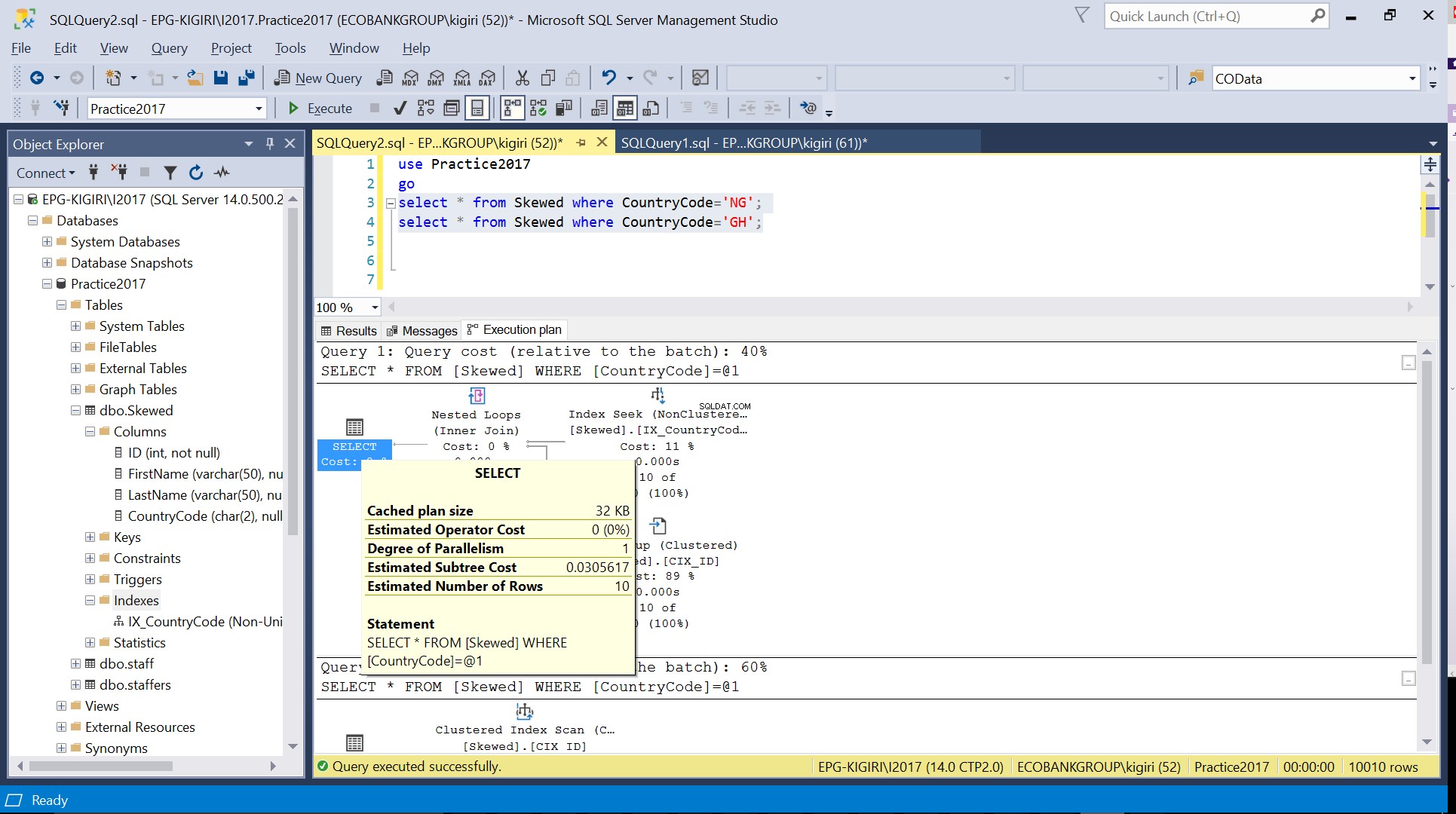
Fig. 3 Uppskattat antal rader för CountryCode=’NG’
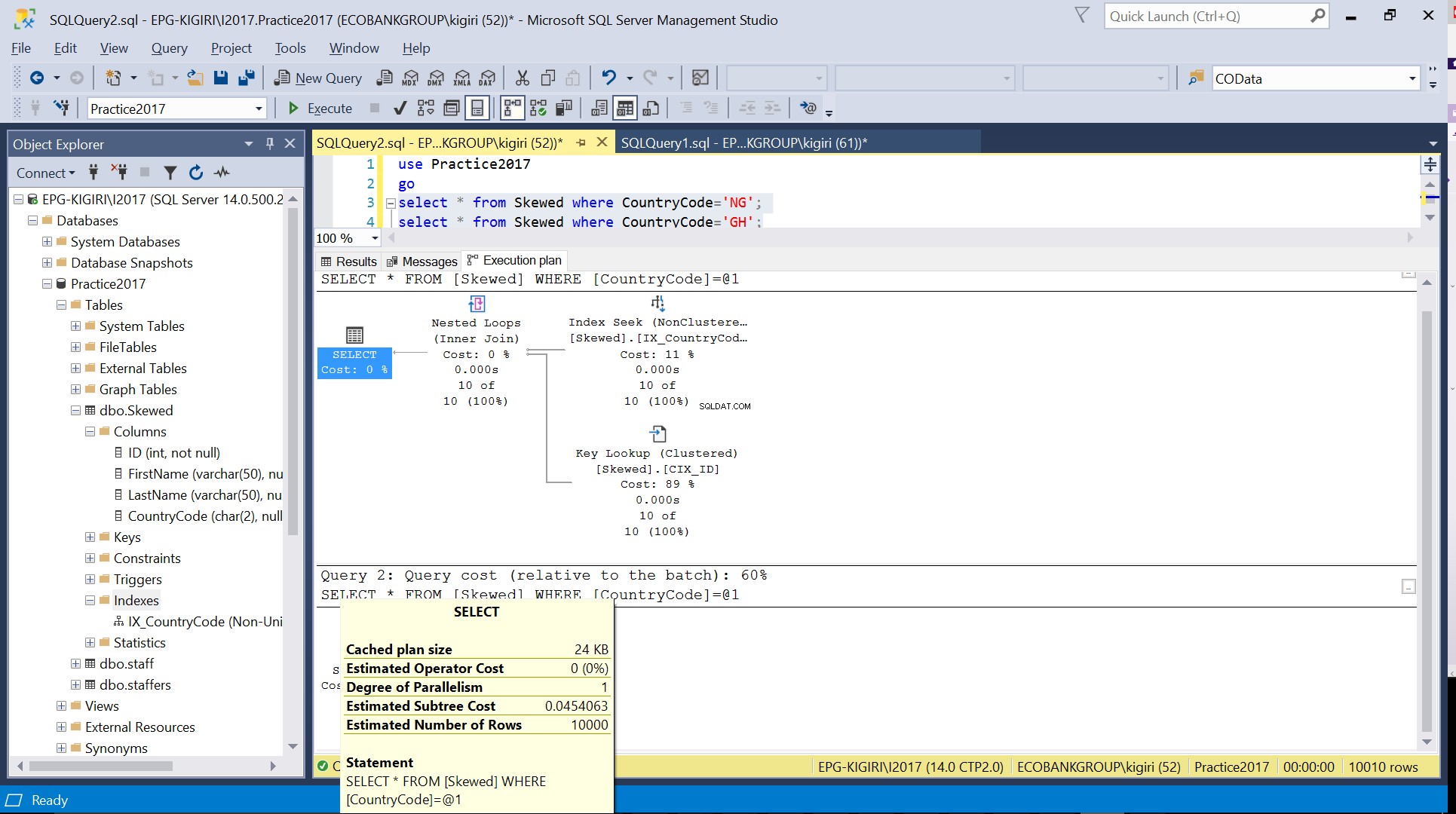
Fig. 4 Uppskattat antal rader för CountryCode=’GH’
Ange lagrade procedurer
Vi kan skapa en lagrad procedur för att hämta de poster vi vill ha genom att använda samma fråga. Den enda skillnaden denna gång är att vi skickar CountryCode som en parameter (se Lista 3). När vi gör detta upptäcker vi att utförandeplanen är densamma oavsett vilken parameter vi passerar. Exekveringsplanen som kommer att användas bestäms av exekveringsplanen som returneras vid första gången den lagrade proceduren anropas. Till exempel, om vi kör proceduren med CountryCode='GH' först, kommer den att använda en fullständig tabellskanning från den tidpunkten. Om vi sedan rensar procedurens cache och kör proceduren med CountryCode=’NG’ först, kommer den att använda indexbaserade skanningar i framtiden.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
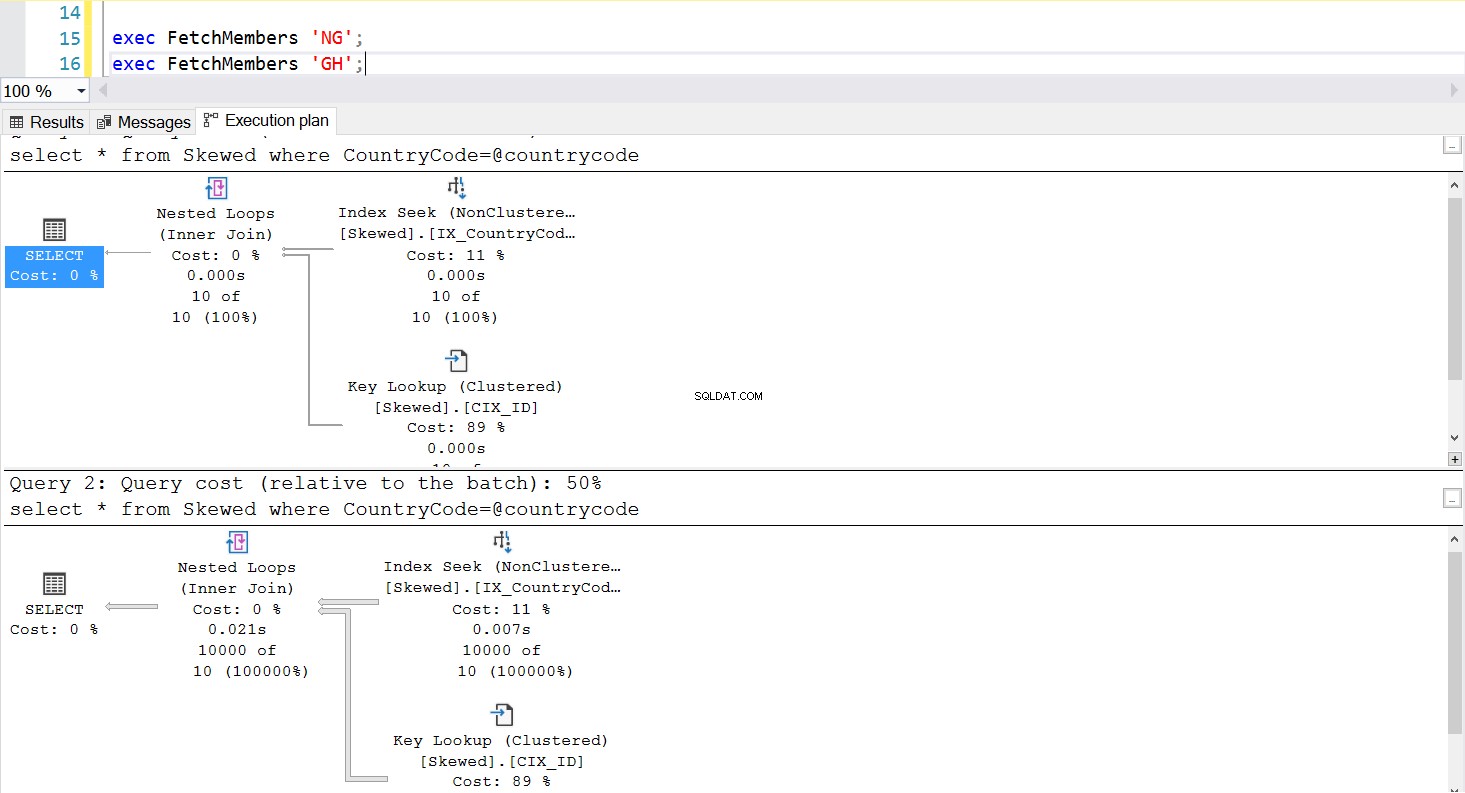
Fig. 5 Utförandeplan för indexsökning när 'NG' används först
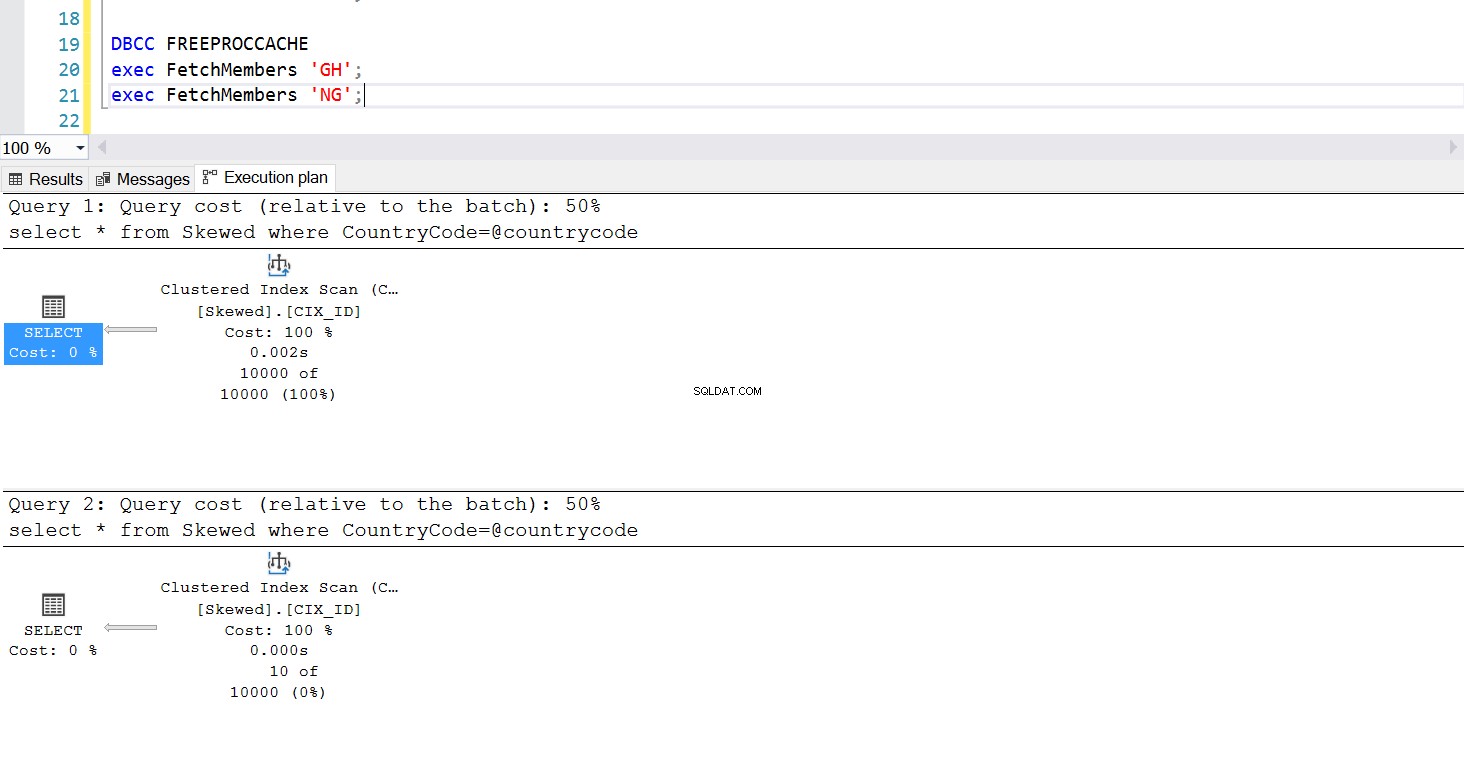
Fig. 6 Klustrad indexavsökningsplan när 'GH' används först
Körningen av den lagrade proceduren fungerar som den är designad – den nödvändiga utförandeplanen används konsekvent. Detta kan dock vara ett problem eftersom en exekveringsplan inte är lämplig för alla frågor om data är skev. Att använda ett index för att hämta en samling rader som är nästan lika stora som hela tabellen är inte effektivt – inte heller att använda en fullständig skanning för att bara hämta ett litet antal rader. Detta är Parameter Sniffing-problemet.
Möjliga lösningar
Ett vanligt sätt att hantera Parameter Sniffing-problemet är att medvetet anropa omkompilering närhelst den lagrade proceduren exekveras. Detta är mycket bättre än att tömma plancachen – förutom om du vill tömma cachen för denna specifika SQL-fråga, vilket är fullt möjligt. Ta en titt på en uppdaterad version av den lagrade proceduren. Den här gången använder den OPTION (RECOMPILE) för att hantera problemet. Fig. 6 visar oss att, närhelst den nya lagrade proceduren exekveras, använder den en plan som är lämplig för parametern vi skickar.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
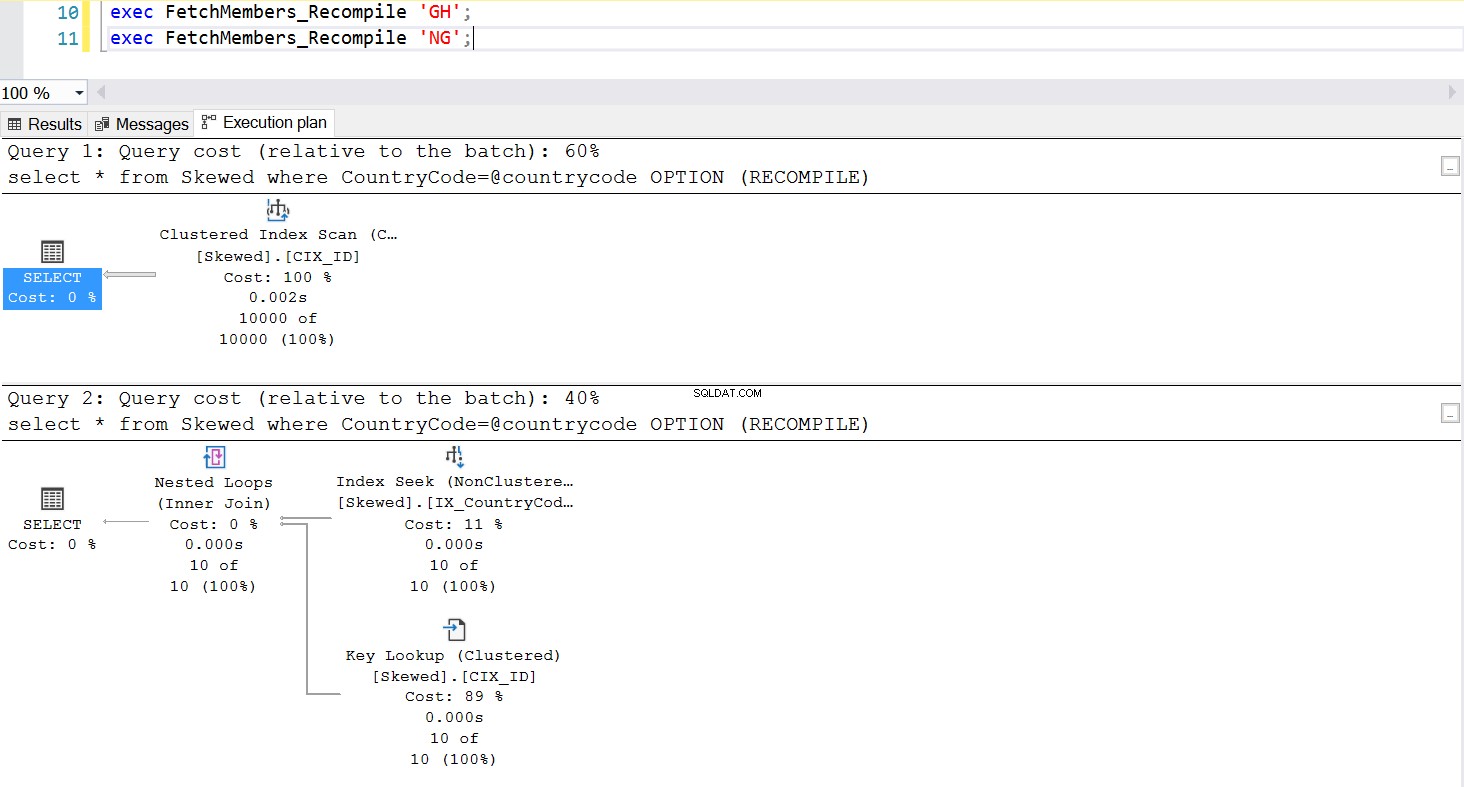
Fig. 7 Beteende för den lagrade proceduren med OPTION (OMKOMPILERA)
Slutsats
I den här artikeln har vi tittat på hur konsekventa exekveringsplaner för lagrade procedurer kan bli ett problem när data vi har att göra med är skev. Vi har också visat detta i praktiken och lärt oss om en gemensam lösning på problemet. Jag vågar påstå att denna kunskap är ovärderlig för utvecklare som använder SQL Server. Det finns ett antal andra lösningar på detta problem – Brent Ozar gick djupare in i ämnet och lyfte fram några mer djupgående detaljer och lösningar på SQLDay Poland 2017. Jag har listat motsvarande länk i referensavsnittet.
Referenser
Planera cache och optimera för adhoc-arbetsbelastningar
Identifiera och åtgärda problem med parametersniffning