Innan vi går igenom prestandaproblemet med Forwarded Records och löser det måste vi se över strukturen för SQL Server-tabellerna.
Översikt över tabellstruktur
I SQL Server är den grundläggande enheten för datalagringen 8-KB-sidorna . Varje sida börjar med en 96-byte rubrik som lagrar systeminformationen om den sidan. Sedan kommer tabellraderna att lagras på datasidorna i serie efter rubriken. I slutet av sidan kommer radförskjutningstabellen, som innehåller en post för varje rad, att lagras mitt emot sekvensen av raderna på sidan. Den här radförskjutningsposten visar hur långt den första byten av den raden är placerad från början av sidan.
SQL Server ger oss två typer av tabeller, baserade på strukturen i den tabellen. Den klustrade Tabell lagrar och sorterar data på datasidorna baserat på de fördefinierade värdena för Clustered index key kolumn eller kolumner. Dessutom är datasidorna i Clustered-tabellen sorterade och sammanlänkade i en länkad lista baserad på Clustered-indexnyckelvärdena. B-trädet strukturen för Clustered index ger en snabb dataåtkomstmetod baserad på Clustered index nyckelvärden. Om en ny rad infogas eller ett befintligt nyckelvärde uppdateras i Clustered-tabellen kommer SQL Server att lagra det nya värdet i rätt logisk position som passar den infogade radstorleken utan att bryta mot ordningskriterierna. Om det infogade eller uppdaterade värdet är större än det tillgängliga utrymmet på datasidan delas sidan upp i två sidor för att passa det nya värdet.
Den andra typen av tabeller är Högen tabell, där data inte sorteras inom datasidorna i någon ordning och sidorna inte är länkade tillsammans, eftersom det inte finns något Clusterindex definierat i den tabellen, för att upprätthålla eventuella sorteringskriterier. Att spåra de sidor som inte är sorterade i några beställningskriterier eller länkade samman i högtabellen är inte ett lätt uppdrag. För att förenkla spårningsprocessen för sidtilldelningen i heaptabellen använder SQL Server indexallokeringskartan (IAM), den enda logiska kopplingen mellan datasidorna i heaptabellen, genom att behålla en post för varje datasida i tabellen eller indexet i IAM-tabellen. För att hämta all data från heaptabellen skannar SQL Server Engine av IAM för att lokalisera omfattningen, vilket bildar 8 sidor som lagrar den begärda informationen.
Problem med vidarebefordrade poster
Om en ny rad infogas i heaptabellen kommer SQL Server Engine att skanna Page Free Space (PFS)-sidor för att spåra tilldelningsstatus och utrymmesanvändning på varje datasida för att hitta den första tillgängliga platsen på datasidorna som passar den infogade radstorleken. Sedan läggs raden till på den valda sidan. Om det infogade värdet är större än det tillgängliga utrymmet på datasidorna kommer en ny sida att läggas till den tabellen för att kunna infoga det nya värdet.
Å andra sidan, om befintliga data i heaptabellen modifieras, till exempel, uppdaterade vi en sträng med variabel längd med större datastorlek, och det aktuella utrymmet inte passar den nya datan, kommer data att flyttas till en annan fysisk plats och vidarebefordrad post kommer att infogas i heaptabellen på den ursprungliga dataplatsen, för att peka på den nya platsen för dessa data och för att förenkla spårningsdataplatsen. Den nya dataplatsen innehåller också en pekare som pekar på vidarebefordringspekaren för att hålla den uppdaterad i fallet med att flytta data från den nya platsen och för att förhindra den långa vidarebefordrande pekarkedjan eller ta bort den. Detta kan leda till att även vidarebefordransposten tas bort.
Även om omdirigeringsmetoden för Forwarded Records minskar behovet av den resurskrävande tabell- och icke-klustrade index-ombyggnadsoperationerna för att uppdatera dataadresserna varje gång platsen för data ändras, fördubblar den också antalet läsningar som krävs för att hämta data. SQL Server kommer att besöka den gamla platsen först, där den hittar den vidarebefordrade posten som omdirigerar den till den nya dataplatsen. Sedan kommer den att läsa den begärda datan och utföra läsoperationen två gånger. Dessutom leder problemet med Forwarded Records till att sekventiell data som läses till slumpmässig data som läses, vilket påverkar datahämtningens funktion negativt över tiden.
Låt oss skapa följande ForwardRecordDemo hög tabell med CREATE TABLE T-SQL-satsen nedan:
CREATE TABLE ForwardRecordDemo ( ID INT IDENTITY (1,1), Emp_Name NVARCHAR (50), Emp_BirthDate DATETIME, Emp_Salary INT )
Fyll sedan i tabellen med 3K-poster för teständamål, med hjälp av INSERT INTO T-SQL-satsen nedan:
INSERT INTO ForwardRecordDemo VALUES ('John','2000-05-05',500)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Zaid','1999-01-07',700)
GO 1000
INSERT INTO ForwardRecordDemo VALUES ('Frank','1988-07-04',900)
GO 1000 Identifiera problemet med vidarebefordrade poster
Informationen om tabelltypen och antalet sidor som konsumeras under lagring av tabelldata, såväl som indexfragmenteringsprocenten och antalet vidarebefordrade poster för en specifik tabell kan ses genom att fråga sys.dm_db_index_physical_stats systemets dynamiska hanteringsfunktion och genom att gå vidare till DETALJERAD läge för att returnera antalet vidarekopplingsposter. För att göra detta, använd T-SQL-skriptet nedan:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Som du kan se från frågeresultatet är den föregående tabellen högtabellen som inte har något Clusterindex skapat på sig för att sortera data på sidorna och länka sidorna mellan varandra. De 3K-rader som infogas i tabellen är tilldelade 15 datasidor, utan vidarebefordrade poster och noll fragmenteringsprocent, som visas i resultatet nedan:

När du definierar datatypen för en kolumn som VARCHAR eller NVARCHAR, är värdet som anges i datatypsdefinitionen den högsta tillåtna storleken för den strängen, utan att helt reservera det beloppet samtidigt som värdena sparas på datasidorna. Till exempel John anställds namn som infogas i den tabellen reserverar endast 8 byte av de maximala 100 byte för den kolumnen, med tanke på att om du sparar NVARCHAR-strängen fördubblas antalet byte som krävs för VARCHAR-kolumnen, som visas i DATALENGTH funktionsresultat nedan:
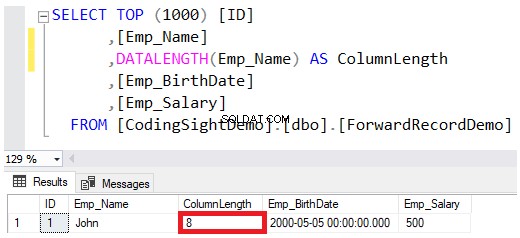
Om du vill uppdatera värdet på kolumnen Emp_Name för att inkludera det fullständiga namnet på den anställde John, använd UPDATE-satsen nedan:
UPDATE ForwardRecordDemo SET Emp_Name='John David Micheal' WHERE Emp_Name='John'
Kontrollera längden på den uppdaterade kolumnen med DATALENGTH fungera. Du kommer att se att längden på Emp_Name-kolumnen i de uppdaterade raderna har utökats med 28 byte per varje kolumn, vilket är ungefär 3,5 ytterligare datasidor till den tabellen, som visas i resultatet nedan:
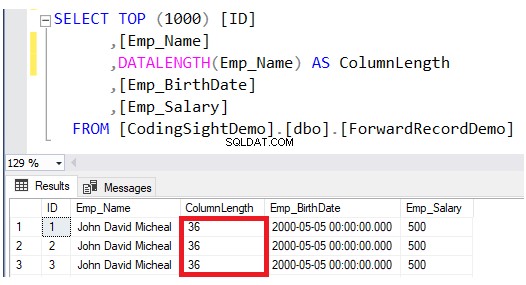
Kontrollera sedan antalet vidarebefordrade poster efter uppdateringsåtgärden genom att fråga sys.dm_db_index_physical_stats-systemets dynamiska hanteringsfunktion. För att göra detta, använd T-SQL-skriptet nedan:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Som du kan se kommer en uppdatering av Emp_Name-kolumnen på 1K-poster med större strängvärden, utan att lägga till någon ny post, tilldela de extra 5 sidor till den tabellen, snarare än 3,5 sidor som förväntat tidigare. Detta kommer att hända på grund av generering av 484 vidarebefordrade poster för att peka på de nya platserna för den flyttade datan. Detta kan göra att tabellen blir 33 % fragmenterad, som tydligt visas nedan:

Återigen, om du lyckas uppdatera värdet på Emp_Name-kolumnen för att inkludera det fullständiga namnet på Zaid-anställda, använd UPDATE-satsen nedan:
UPDATE ForwardRecordDemo SET Emp_Name='Zaid Fuad Zreeq' WHERE Emp_Name='Zaid'
Kontrollera längden på den uppdaterade kolumnen med DATALENGTH fungera. Du kommer att se att längden på Emp_Name-kolumnen i de uppdaterade raderna utökas med 22 byte per varje kolumn, vilket är ungefär 2,7 ytterligare datasidor läggs till i den tabellen, som visas i resultatet nedan:
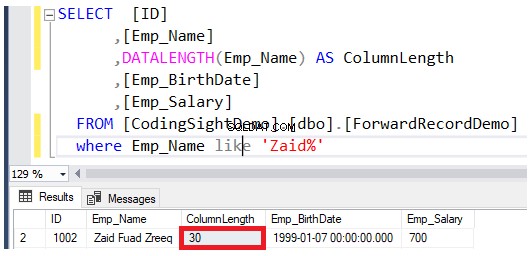
Kontrollera antalet vidarebefordrade poster efter att ha utfört uppdateringen. Du kan göra detta genom att fråga sys.dm_db_index_physical_stats-systemets dynamiska hanteringsfunktion med samma T-SQL-skript nedan:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Resultatet kommer att visa dig att uppdatering av Emp_Name-kolumnen på de andra 1K-posterna med större strängvärden utan att infoga någon ny rad kommer att tilldela ytterligare 4 sidor till den tabellen, istället för 2,7 sidor som förväntat. Detta kommer att hända på grund av att ytterligare 417 genereras vidarebefordrade poster för att peka på de nya platserna för de flyttade uppgifterna och behålla samma 33 % fragmenteringsprocent, som visas nedan:

Åtgärda problemet med vidarebefordrade poster
Det enklaste sättet att åtgärda problemet med vidarebefordrade poster är att uppskatta den maximala längden på strängen som kommer att lagras i kolumnen och tilldela den med den fasta längden datatypen för den kolumnen istället för att använda datatypen med variabel längd. Det optimala permanenta sättet att åtgärda problemet med vidarebefordrade poster är att lägga till Clustered index till det bordet. På detta sätt kommer tabellen att konverteras fullständigt till en Clustered-tabell, som sorteras baserat på Clustered-indexnyckelvärdena. Det kommer att styra ordningen på befintliga data, de nyligen infogade och uppdaterade data som inte passar det aktuella tillgängliga utrymmet på datasidan, som beskrivits tidigare i inledningen av den här artikeln.
Om att lägga till det klustrade indexet till den tabellen inte är ett alternativ för specifika krav, såsom mellantabellerna eller ETL-tabellerna, kan du lösa problemet med vidarebefordrade poster tillfälligt genom att övervaka de vidarebefordrade posterna och bygga om högtabellen för att ta bort den, vilket kommer att uppdatera även alla icke-klustrade index på den heaptabellen. Funktionaliteten för att bygga om heaptabellen introduceras i SQL Server 2008 genom att använda ALTER TABLE...REBUILD T-SQL-kommando.
För att se prestandapåverkan av de vidarebefordrade posterna på datahämtningsfrågorna, låt oss köra SELECT-frågan som utför sökningen baserat på Emp_Name-kolumnvärdenю Men innan du kör frågan, aktivera TIME- och IO-statistiken:
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
Som ett resultat kommer du att se 925 logiska läsoperationer utförs för att hämta de begärda data inom 84ms som visas nedan:

För att bygga om högtabellen för att ta bort alla vidarebefordrade poster, använd kommandot ALTER TABLE...REBUILD:
ALTER TABLE ForwardRecordDemo REBUILD;
Kör samma SELECT-sats igen:
SELECT * FROM ForwardRecordDemo WHERE Emp_Name like 'John%'
TIME- och IO-statistiken visar dig att endast 21 logiska läsoperationer jämfört med 925 logiska läsoperationer med de vidarebefordrade posterna inkluderade utförs för att hämta de begärda data inom 79 ms :

För att kontrollera antalet vidarebefordrade poster efter att ha byggt om heaptabellen, kör du sys.dm_db_index_physical_stats-systemets dynamiska hanteringsfunktion, använd samma T-SQL-skript nedan:
SELECT
OBJECT_NAME(PhysSta.object_id) as DBTableName,
PhysSta.index_type_desc,
PhysSta.avg_fragmentation_in_percent,
PhysSta.forwarded_record_count,
PhysSta.page_count
FROM sys.dm_db_index_physical_stats (DB_ID(), DEFAULT, DEFAULT, DEFAULT, 'DETAILED') AS PhysSta
WHERE OBJECT_NAME(PhysSta.object_id) = 'ForwardRecordDemo' AND forwarded_record_count is NOT NULL
Du ser det bara 21 sidor, med föregående 3 sidor som konsumeras för de vidarebefordrade posterna, tilldelas den tabellen för att lagra data, vilket liknar det uppskattade resultatet vi har fått under datainsättningen och uppdateringsoperationerna (15+3.5+2.7). Efter att ha byggt om högtabellen tas alla vidarebefordrade poster bort nu. Som ett resultat har vi en tabell utan fragmentering:

Problemet med vidarebefordrade poster är en viktig prestandafråga som databasadministratörer bör tänka på när de planerar för högbordsunderhåll. De tidigare resultaten hämtas från vår testtabell som endast innehåller 3K-poster. Du kan föreställa dig hur många sidor som kommer att slösas bort av de vidarebefordrade posterna och försämringen av I/O-prestanda, på grund av att man läser ett stort antal vidarebefordrade poster när man läser från enorma tabeller!
Referenser:
- Arkitekturguide för sidor och omfattningar
- dm_db_index_physical_stats (Transact-SQL)
- ÄNDRA TABELL (Transact-SQL)
- Att känna till "vidarebefordrade poster" kan hjälpa till att diagnostisera svåra att hitta prestandaproblem