Dessa tester (databasen AdventureWorks2008R2) visar vad som händer:
SET NOCOUNT ON;
SET STATISTICS IO ON;
PRINT 'Test #1';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE '%be%';
PRINT 'Test #2';
DECLARE @Pattern NVARCHAR(50);
SET @Pattern=N'%be%';
SELECT p.BusinessEntityID, p.LastName
FROM Person.Person p
WHERE p.LastName LIKE @Pattern;
SET STATISTICS IO OFF;
SET NOCOUNT OFF;
Resultat:
Test #1
Table 'Person'. Scan count 1, logical reads 106
Test #2
Table 'Person'. Scan count 1, logical reads 106
Resultaten från SET STATISTICS IO visar att LIO är samma .Men genomförandeplanerna är helt olika: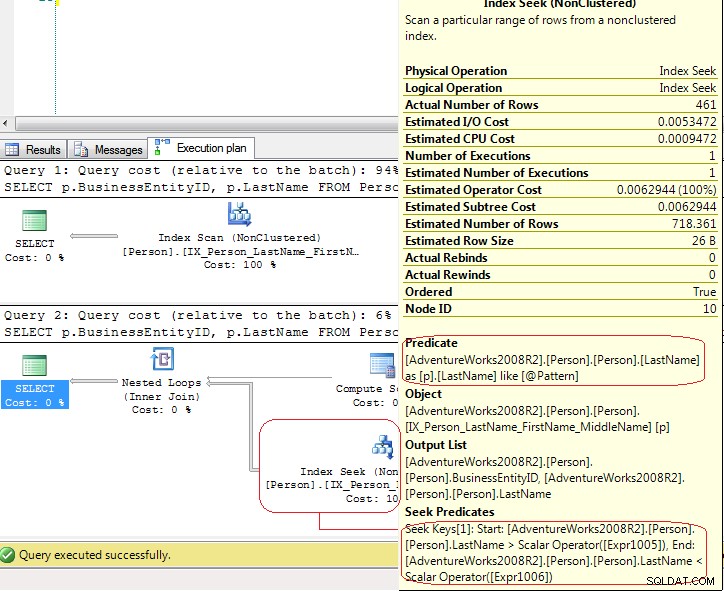
I det första testet använder SQL Server en Index Scan explicit men i det andra testet använder SQL Server en Index Seek som är en Index Seek - range scan . I det sista fallet använder SQL Server en Compute Scalar operatör för att generera dessa värden
[Expr1005] = Scalar Operator(LikeRangeStart([@Pattern])),
[Expr1006] = Scalar Operator(LikeRangeEnd([@Pattern])),
[Expr1007] = Scalar Operator(LikeRangeInfo([@Pattern]))
och Index Seek operatören använder ett Seek Predicate (optimerad) för en range scan (LastName > LikeRangeStart AND LastName < LikeRangeEnd ) plus ytterligare ett ooptimerat Predicate (LastName LIKE @pattern ).
Mitt svar:det är inte en "riktig" Index Seek . Det är en Index Seek - range scan som i det här fallet har samma prestanda som Index Scan .
Se också skillnaden mellan Index Seek och Index Seek (liknande debatt):Så...är det en sökning eller en sökning?
.
Redigera 1: Exekveringsplanen för OPTION(RECOMPILE) (se Aarons rekommendation snälla) visar också en Index Scan (istället för Index Seek ):