I början har vi det här -- vilket är ganska rörigt.
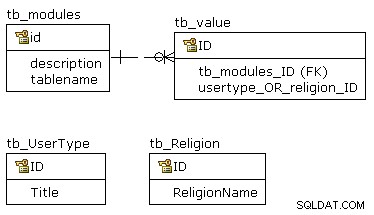
För att rensa lite lägger jag till två vyer och en synonym:
create view v_Value as
select
ID as ValueID
, tb_modules_ID as ModuleID
, usertype_OR_religion_ID as RemoteID
from tb_value ;
go
create view v_Religion as
select
ID
, ReligionName as Title
from tb_religion ;
go
create synonym v_UserType for tb_UserType ;
go
Och nu ser modellen ut som
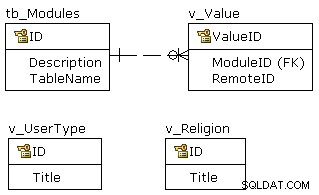
Det är lättare nu att skriva frågan
;
with
q_mod as (
select
m.ID as ModuleID
, coalesce(x1.ID , x2.ID) as RemoteID
, coalesce(x1.Title , x2.Title) as Title
, m.Description as ModuleType
from tb_Modules as m
left join v_UserType as x1 on m.TableName = 'tb_UserType'
left join v_Religion as x2 on m.TableName = 'tb_Religion'
)
select
a.ModuleID
, v.ValueID
, a.RemoteID
, a.ModuleType
, a.Title
from q_mod as a
join v_Value as v on (v.ModuleID = a.ModuleID and v.RemoteID = a.RemoteID) ;
Det finns ett uppenbart mönster i den här frågan, så den kan skapas som dynamisk sql om du måste lägga till en annan tabell av modultyp. Använd ID när du lägger till ytterligare en tabell och Title för att slippa använda en vy.
REDIGERA
Att bygga dynamisk sql (eller fråga på applikationsnivå)
Ändra rad 6 och 7, x-indexet är tb_modules.id
coalesce(x1. , x2. , x3. ..)
Lägg till rader till vänster sammanfogning (under rad 11)
left join v_SomeName as x3 on m.TableName = 'tb_SomeName'
SomeName är tb_modules.description och x-index matchar tb_modules.id
REDIGERA 2
Det enklaste skulle förmodligen vara att paketera ovanstående fråga i en vy och sedan varje gång schemat ändras dynamiskt låda och köra ALTER VIEW . På så sätt ändras inte frågan från programmets punkt.