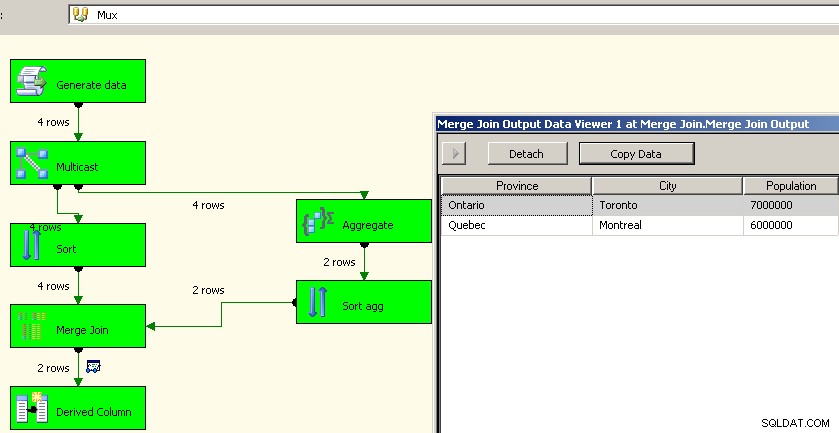
Håller helt med @PaulStock om att aggregat är bäst att lämna till källsystem. Ett aggregat i SSIS är en helt blockerande komponent ungefär som en sorts och jag har har redan argumenterat på den punkten .
Men det finns tillfällen då de här operationerna i källsystemet helt enkelt inte kommer att fungera. Det bästa jag har kunnat komma på är att i princip dubbelbearbeta datan. Ja, ick men jag kunde aldrig hitta ett sätt att passera en kolumn opåverkad. För Min/Max-scenarier skulle jag vilja ha det som ett alternativ, men uppenbarligen skulle något som en Sum göra det svårt för komponenten att veta vilken "källa"-rad den skulle knytas till.
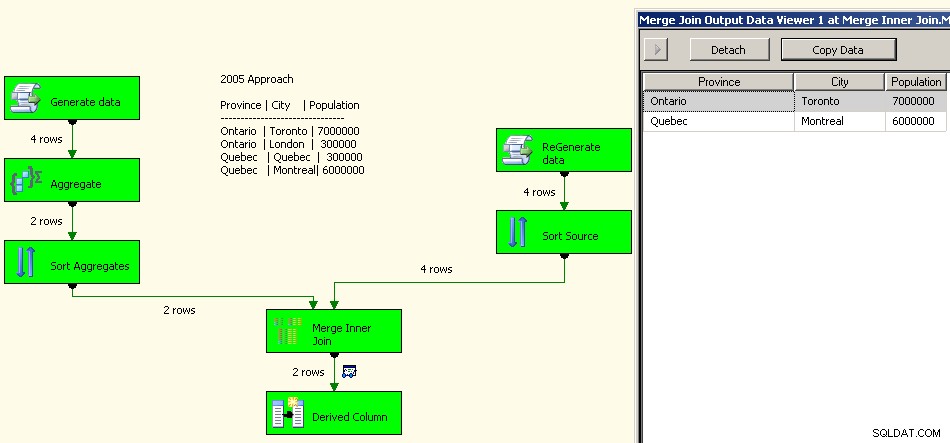
2005
En implementering från 2005 skulle se ut så här. Din prestation kommer inte att bli bra, faktiskt några storleksordningar från bra eftersom du kommer att ha alla dessa blockerande transformationer där förutom att behöva bearbeta din källdata.
Slå samman gå med 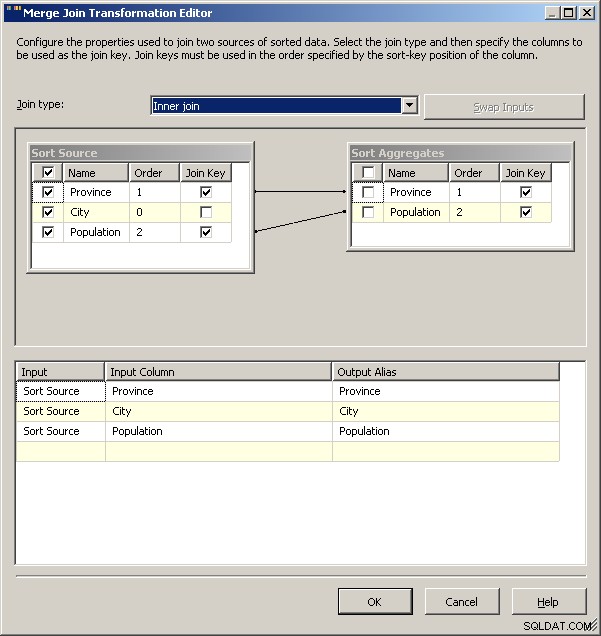
2008
Under 2008 har du möjlighet att använda Cache Connection Manager vilket skulle hjälpa till att eliminera blockerande transformationer, åtminstone där det är viktigt, men du kommer fortfarande att behöva betala kostnaden för dubbelbearbetning av dina källdata.
Dra två dataflöden till arbetsytan. Den första kommer att fylla i cache-anslutningshanteraren och bör vara där sammanställningen sker.
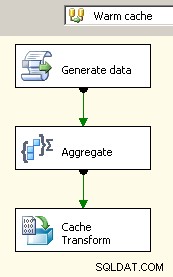
Nu när cachen har samlad data där, släpp en uppslagsuppgift i ditt huvuddataflöde och gör en uppslagning mot cachen.
Fliken Allmän sökning
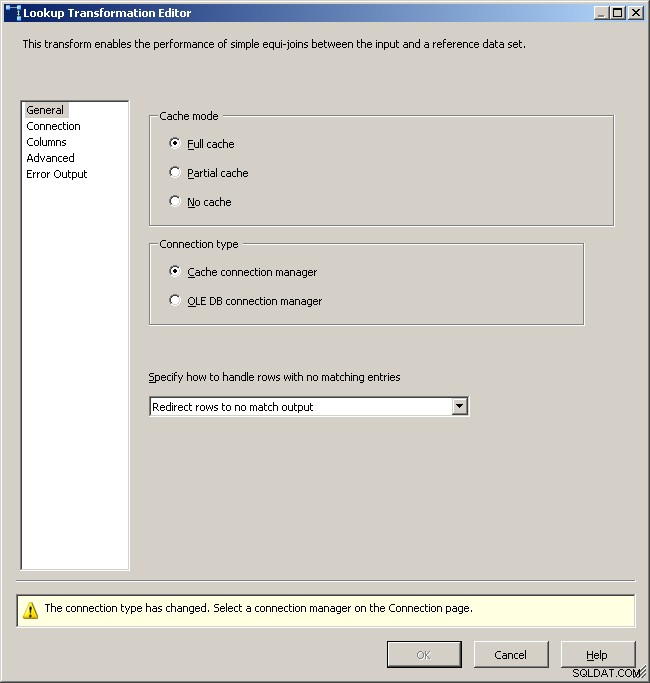
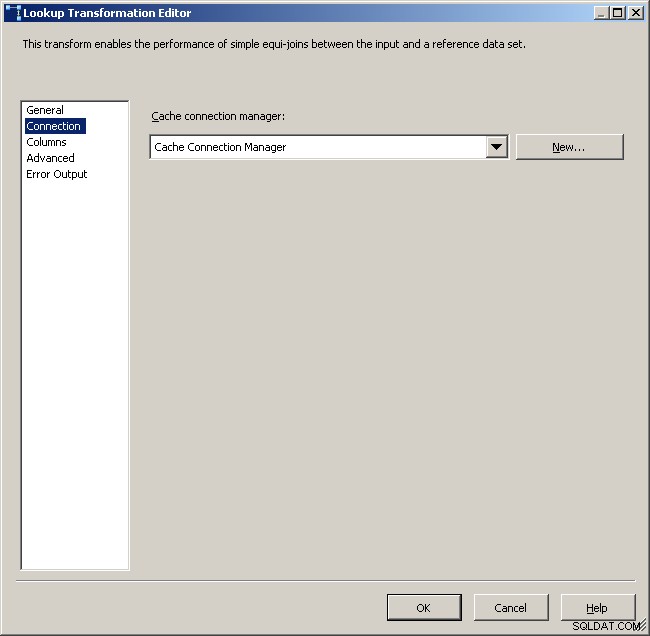
Välj cacheanslutningshanteraren
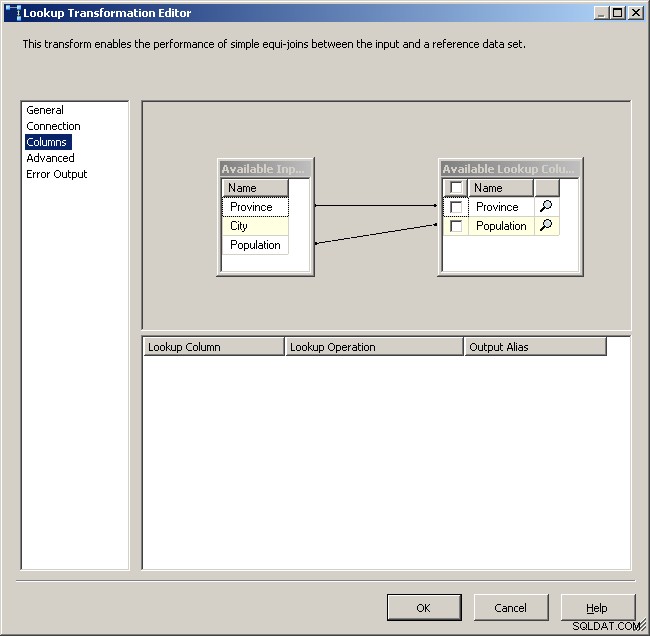
Kartlägg lämpliga kolumner
Stor framgång 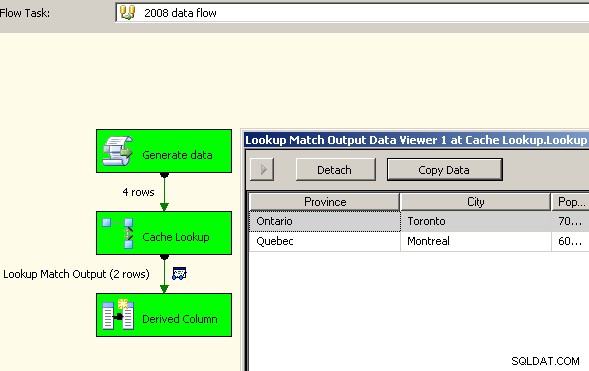
Skriptuppgift
Det tredje tillvägagångssättet jag kan tänka mig, 2005 eller 2008, är att skriva det själv. Som en allmän regel försöker jag undvika skriptuppgifterna men det här är ett fall där det förmodligen är vettigt. Du måste göra det till en asynkron skriptomvandling utan hantera dina sammanställningar där. Mer kod att underhålla men du kan bespara dig besväret med att bearbeta din källdata igen.
Slutligen, som en allmän varning, skulle jag undersöka vad effekten av band kommer att göra med din lösning. För den här datamängden skulle jag förvänta mig att något som Guelph plötsligt skulle svälla och knyta Toronto men om det gjorde det, vad ska paketet göra? Just nu kommer båda att resultera i 2 rader för Ontario men är det det avsedda beteendet? Manus låter dig förstås definiera vad som händer i fallet med slipsar. Du skulle förmodligen kunna stå 2008 års lösning på huvudet genom att cachelagra den "normala" data och använda den som ditt uppslagsvillkor och använda aggregaten för att dra tillbaka bara en av banden. 2005 kan förmodligen göra samma sak bara genom att sätta aggregatet som vänster källa för sammanfogningen
Redigeringar
Jason Horner hade en bra idé i sin kommentar. Ett annat tillvägagångssätt skulle vara att använda en multicast-transformation och utföra aggregeringen i en ström och sammanföra den igen. Jag kunde inte komma på hur jag skulle få det att fungera med ett fackförbund, men vi kunde använda sorteringar och sammanslagningar ungefär som i ovanstående. Detta är förmodligen ett bättre tillvägagångssätt eftersom det besparar oss besväret att omarbeta källdata.