
Datans tillgänglighet, tillgänglighet och prestanda är avgörande för affärsframgång. Prestandajustering och SQL-frågeoptimering är knepiga men nödvändiga metoder för databasproffs. De kräver att man tittar på olika samlingar av data med hjälp av utökade händelser, perfmon, exekveringsplaner, statistik och index för att nämna några. Ibland ber programägare att få öka systemresurserna (CPU och minne) för att förbättra systemets prestanda. Men du kanske inte behöver dessa extra resurser och de kan ha en kostnad förknippad med dem. Ibland är allt som krävs är att göra mindre förbättringar för att ändra frågebeteendet.
I den här artikeln kommer vi att diskutera några bästa metoder för optimering av SQL-frågor att tillämpa när du skriver SQL-frågor.
VÄLJ * kontra VÄLJ kolumnlista
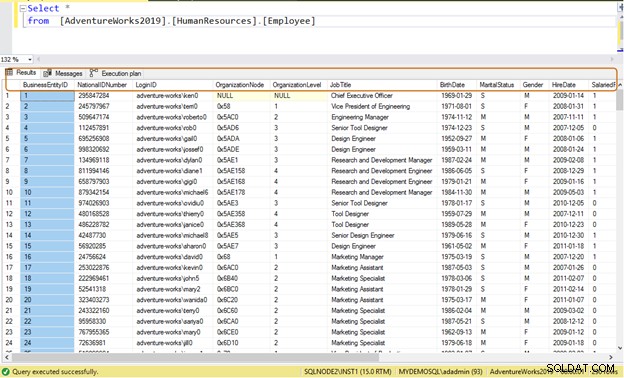
Vanligtvis använder utvecklare SELECT *-satsen för att läsa data från en tabell. Den läser all kolumns tillgängliga data i tabellen. Antag att en tabell [AdventureWorks2019].[HumanResources].[Anställd] lagrar data för 290 anställda och du har ett krav på att hämta följande information:
- Anställds nationellt ID-nummer
- DOB
- Kön
- Anställningsdatum
Ineffektiv fråga: Om du använder SELECT *-satsen returnerar den all kolumns data för alla 290 anställda.
Välj * från [AdventureWorks2019].[HumanResources].[Anställd]
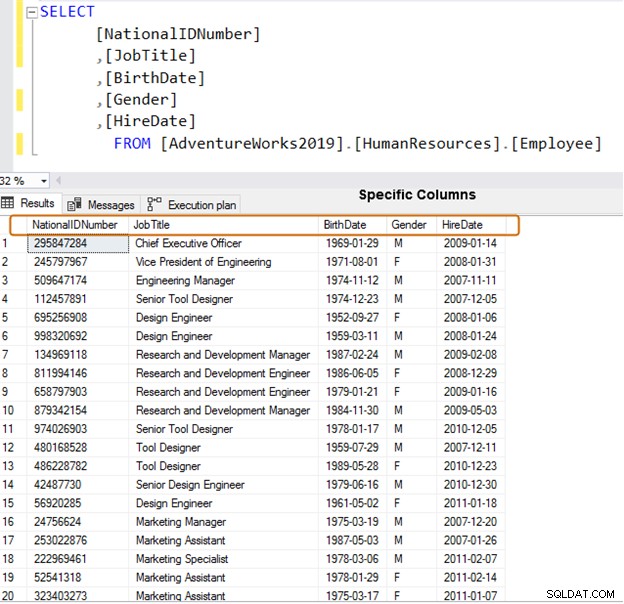
Använd istället specifika kolumnnamn för datahämtning.
VÄLJ [NationalIDNumber],[JobTitle],[BirthDate],[Gender],[HireDate]FRÅN [AdventureWorks2019].[HumanResources].[Anställd]
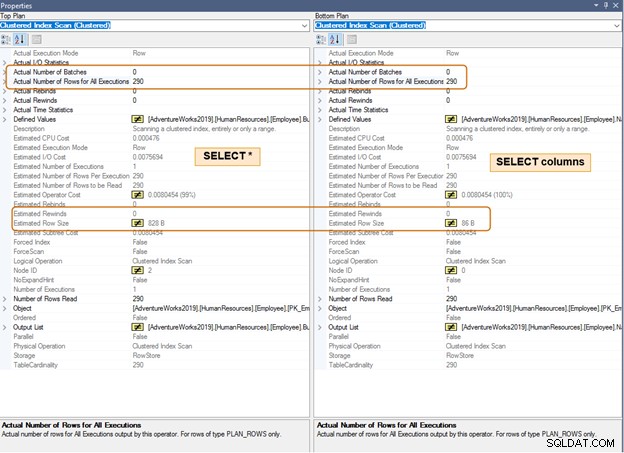
I utförandeplanen nedan, notera skillnaden i den beräknade radstorleken för samma antal rader. Du kommer också att märka en skillnad i CPU och IO för ett stort antal rader.
Användning av COUNT() kontra EXISTS
Anta att du vill kontrollera om en specifik post finns i SQL-tabellen. Vanligtvis använder vi COUNT (*) för att kontrollera posten, och den returnerar antalet poster i utdata.
Vi kan dock använda funktionen IF EXISTS() för detta ändamål. För jämförelsen aktiverade jag statistiken innan jag körde frågorna.
Frågan för COUNT()
STÄLL IN STATISTIK IO PÅVälj antal(*) från [AdventureWorks2019].[Sales].[SalesOrderDetail]där [SalesOrderDetailID]=44824STÄLL STATISTIK IO AV
Frågan för IF EXISTS()
STÄLL IN STATISTIK IO ONIF EXISTS(Välj [CarrierTrackingNumber] från [AdventureWorks2019].[Sales].[SalesOrderDetail]där [SalesOrderDetailID]=44824) SKRIV UT 'YES'ELSEPRINT 'NO'SET STATISTICS IO IO .Jag använde statisticsparser för att analysera statistikresultaten för båda frågorna. Titta på resultaten nedan. Frågan med COUNT(*) har 276 logiska läsningar medan IF EXISTS() har 83 logiska läsningar. Du kan till och med få en mer signifikant minskning av logiska läsningar med IF EXISTS(). Därför bör du använda den för att optimera SQL-frågor för bättre prestanda.
Undvik att använda SQL DISTINCT
När vi vill ha unika poster från frågan använder vi vanligtvis SQL DISTINCT-satsen. Anta att du sammanfogade två tabeller, och i utgången returnerar den dubblettraderna. En snabb lösning är att ange operatorn DISTINCT som undertrycker den dubblerade raden.
Låt oss titta på de enkla SELECT-satserna och jämföra utförandeplanerna. Den enda skillnaden mellan båda frågorna är en DISTINCT-operator.
SELECT SalesOrderID FROM Sales.SalesOrderDetailGoSELECT DISTINCT SalesOrderID FROM Sales.SalesOrderDetailGoMed DISTINCT-operatören är frågekostnaden 77 %, medan den tidigare frågan (utan DISTINCT) bara har 23 % batchkostnad.
Du kan använda GROUP BY, CTE eller en underfråga för att skriva effektiv SQL-kod istället för att använda DISTINCT för att få distinkta värden från resultatuppsättningen. Dessutom kan du hämta ytterligare kolumner för en distinkt resultatuppsättning.
VÄLJ SalesOrderID FRÅN Sales.SalesOrderDetail Group efter SalesOrderIDAnvändning av jokertecken i SQL-frågan
Anta att du vill söka efter de specifika poster som innehåller namn som börjar med den angivna strängen. Utvecklare använder ett jokertecken för att söka efter de matchande posterna.
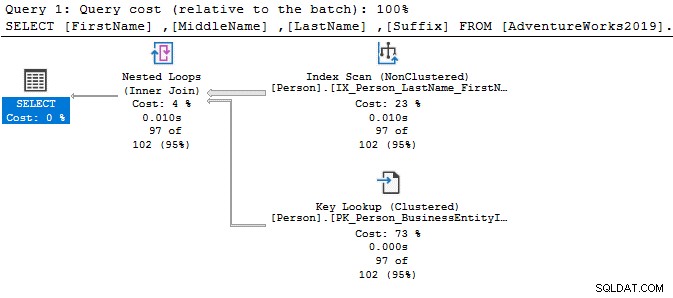
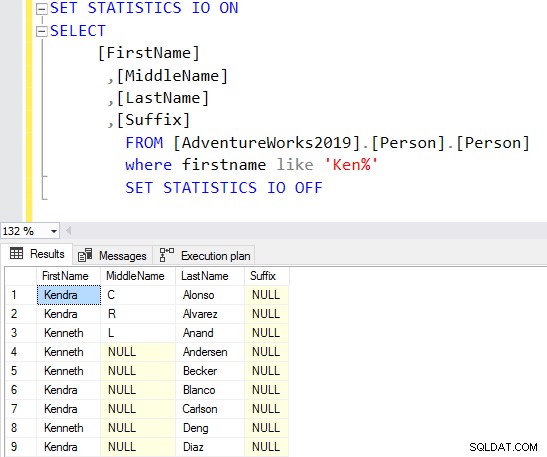
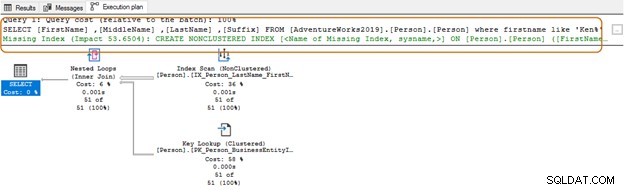
I frågan nedan söker den efter strängen Ken i kolumnen för förnamn. Den här frågan hämtar de förväntade resultaten av Ken dra och Ken neth. Men det ger också oväntade resultat, till exempel Macken zie och Nken ge.
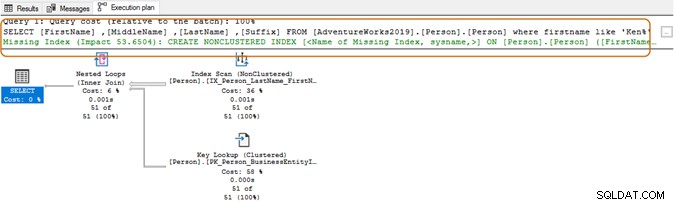
I exekveringsplanen ser du indexskanningen och nyckelsökningen för ovanstående fråga.
Du kan undvika det oväntade resultatet genom att använda jokertecknet i slutet av strängen.
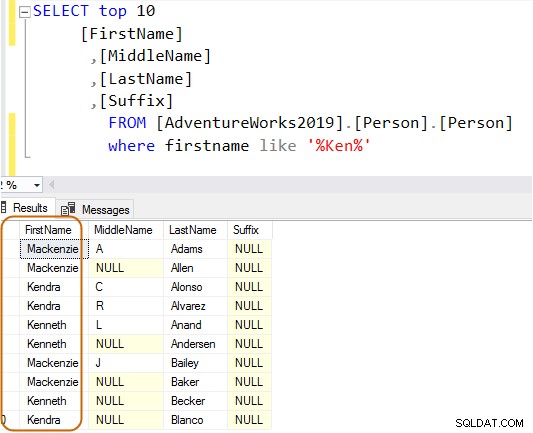
VÄLJ Topp 10[FirstName],[MiddleName],[LastName],[Suffix]FRÅN [AdventureWorks2019].[Person].[Person]Där förnamn som 'Ken%'Nu får du det filtrerade resultatet baserat på dina krav.
När du använder jokertecken i början kanske frågeoptimeraren inte kan använda det lämpliga indexet. Som visas i skärmdumpen nedan, med en efterföljande vild karaktär, föreslår frågeoptimeraren ett saknat index också.
Här vill du utvärdera dina applikationskrav. Du bör försöka undvika att använda ett jokertecken i söksträngarna, eftersom det kan tvinga frågeoptimeraren att använda en tabellsökning. Om tabellen är enorm skulle den kräva högre systemresurser för IO, CPU och minne och kan orsaka prestandaproblem för din SQL-fråga.
Användning av WHERE- och HAVING-satserna
WHERE- och HAVING-satserna används som dataradfilter. WHERE-satsen filtrerar data innan grupperingslogiken tillämpas, medan HAVING-satsen filtrerar rader efter de aggregerade beräkningarna.
Till exempel, i frågan nedan använder vi ett datafilter i HAVING-satsen utan en WHERE-sats.
Välj SalesOrderID,SUM(UnitPrice* OrderQuty) som OrderTotalFrom Sales.salesOrderDetailGROUP BY SalesOrderIDHAVING SalesOrderID>30000 and SalesOrderID<55555 and SUM(UnitPrice* OrderQty)>1GoFöljande fråga filtrerar data först i WHERE-satsen och använder sedan HAVING-satsen för det samlade datafiltret.
Välj SalesOrderID,SUM(UnitPrice* OrderQuty) som OrderTotalFrom Sales.salesOrderDetailwhere SalesOrderID>30000 och SalesOrderID<55555GROUP BY SalesOrderIDHAVING SUM(UnitPrice* OrderQuty)>1000GoJag rekommenderar att du använder WHERE-satsen för datafiltrering och HAVING-satsen för ditt samlade datafilter som bästa praxis.
Användning av IN- och EXISTS-satserna
Du bör undvika att använda IN-operator-satsen för dina SQL-frågor. Till exempel, i frågan nedan, hittade vi först produkt-id:t från tabellen [Production].[TransactionHistory]) och letade sedan efter motsvarande poster i tabellen [Produktion].[Produkt].
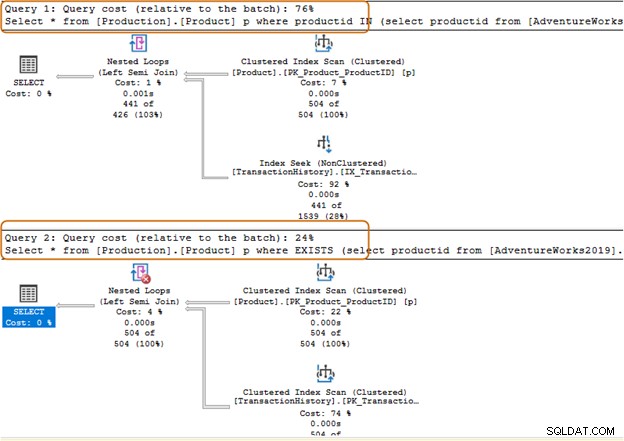
Välj * från [Produktion].[Produkt] p där produkt-id IN (välj produkt-id från [AdventureWorks2019].[Produktion].[TransactionHistory]);GoI frågan nedan ersatte vi IN-satsen med en EXISTS-sats.
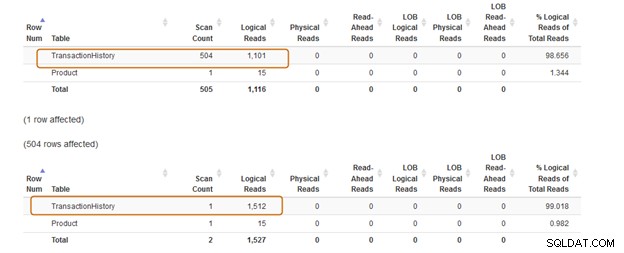
Välj * från [Produktion].[Produkt] p där FINNS (välj produkt-id från [AdventureWorks2019].[Produktion].[TransactionHistory])Låt oss nu jämföra statistiken efter att ha kört båda frågorna.
IN-satsen använder 504 skanningar, medan EXISTS-satsen använder 1 skanning för tabellen [Production].[TransactionHistory]).
IN-klausulens frågebatch kostar 74 %, medan EXISTS-klausulens kostnad är 24 %. Därför bör du undvika IN-satsen, särskilt om underfrågan returnerar en stor datamängd.
Saknade index
Ibland, när vi kör en SQL-fråga och letar efter den faktiska exekveringsplanen i SSMS, får du ett förslag om ett index som kan förbättra din SQL-fråga.
Alternativt kan du använda de dynamiska hanteringsvyerna för att kontrollera detaljerna om saknade index i din miljö.

- sys.dm_db_missing_index_details
- sys.dm_db_missing_index_group_stats
- sys.dm_db_missing_index_groups
- sys.dm_db_missing_index_columns
Vanligtvis följer DBA:er råden från SSMS och skapar indexen. Det kan förbättra frågeprestanda för tillfället. Du bör dock inte skapa indexet direkt baserat på dessa rekommendationer. Det kan påverka andra frågeprestanda och sakta ner dina INSERT- och UPDATE-satser.
- Granska först de befintliga indexen för din SQL-tabell.
- Obs, överindexering och underindexering är båda dåliga för frågeprestanda.
- Tillämpa de saknade indexrekommendationerna med störst effekt efter att ha granskat dina befintliga index och implementerat dem i din lägre miljö. Om din arbetsbelastning fungerar bra efter att ha implementerat det nya saknade indexet är det värt att lägga till it.
Jag föreslår att du läser den här artikeln för detaljerade bästa praxis för indexering: 11 SQL Server Index Best Practices for Improved Performance Tuning.
Frågetips
Utvecklare anger frågetipsen uttryckligen i sina t-SQL-satser. Dessa frågetips åsidosätter frågeoptimerarens beteende och tvingar den att förbereda en körningsplan baserad på din frågetips. Ofta använda frågetips är NOLOCK, Optimera för och Recompile Merge/Hash/Loop. De är kortsiktiga lösningar för dina frågor. Du bör dock arbeta med att analysera din fråga, index, statistik och genomförandeplan för en permanent lösning.
Enligt bästa praxis bör du minimera användningen av alla frågetips. Du vill använda frågetipsen i SQL-frågan efter att först ha förstått implikationerna av den, och använd den inte i onödan.
Påminnelser om optimering av SQL-frågor
Som vi diskuterade är SQL-frågeoptimering en öppen väg. Du kan tillämpa bästa praxis och små korrigeringar som kan förbättra prestandan avsevärt. Överväg följande tips för bättre frågeutveckling:
- Titta alltid på allokering av systemresurser (diskar, CPU, minne)
- Granska dina startspårningsflaggor, index och databasunderhållsuppgifter
- Analysera din arbetsbelastning med hjälp av utökade händelser, profileringsverktyg eller databasövervakningsverktyg från tredje part
- Implementera alltid valfri lösning (även om du är 100 % säker) på testmiljön först och analysera dess inverkan; när du är nöjd, planera för produktionsimplementeringar