
I den här artikeln kommer vi att utforska när och hur man använder SQL PARTITION BY-satsen och jämför den med att använda GROUP BY-satsen.
Förstå fönsterfunktionen
Databasanvändare använder aggregerade funktioner som MAX(), MIN(), AVERAGE() och COUNT() för att utföra dataanalys. Dessa funktioner fungerar på en hel tabell och returnerar enstaka aggregerade data med hjälp av GROUP BY-satsen. Ibland kräver vi aggregerade värden över en liten uppsättning rader. I det här fallet hjälper Window-funktionen i kombination med aggregatfunktionen till att uppnå önskad effekt. Window-funktionen använder OVER()-satsen, och den kan inkludera följande funktioner:
- Partition av: Detta delar upp raderna eller frågeresultatuppsättningen i små partitioner.
- Beställ efter: Detta ordnar raderna i stigande eller fallande ordning för partitionsfönstret. Standardordningen är stigande.
- Rad eller intervall: Du kan ytterligare begränsa raderna i en partition genom att ange start- och slutpunkter.
I den här artikeln kommer vi att fokusera på att utforska SQL PARTITION BY-satsen.
Förbereder exempeldata
Anta att vi har en tabell [SalesLT].[Order] som lagrar kundorderinformation. Den har en kolumn [Stad] som anger kundens stad där beställningen gjordes.
CREATE TABLE [SalesLT].[Orders] ( orderid INT, orderdate DATE, customerName VARCHAR(100), City VARCHAR(50), amount MONEY ) INSERT INTO [SalesLT].[Orders] SELECT 1,'01/01/2021','Mohan Gupta','Alwar',10000 UNION ALL SELECT 2,'02/04/2021','Lucky Ali','Kota',20000 UNION ALL SELECT 3,'03/02/2021','Raj Kumar','Jaipur',5000 UNION ALL SELECT 4,'04/02/2021','Jyoti Kumari','Jaipur',15000 UNION ALL SELECT 5,'05/03/2021','Rahul Gupta','Jaipur',7000 UNION ALL SELECT 6,'06/04/2021','Mohan Kumar','Alwar',25000 UNION ALL SELECT 7,'07/02/2021','Kashish Agarwal','Alwar',15000 UNION ALL SELECT 8,'08/03/2021','Nagar Singh','Kota',2000 UNION ALL SELECT 9,'09/04/2021','Anil KG','Alwar',1000 Go
Låt oss säga att vi vill veta det totala ordervärdet per plats (stad). För detta ändamål använder vi funktionen SUM() och GROUP BY som visas nedan.
SELECT City AS CustomerCity ,sum(amount) AS totalamount FROM [SalesLT].[Orders] GROUP BY city ORDER BY city
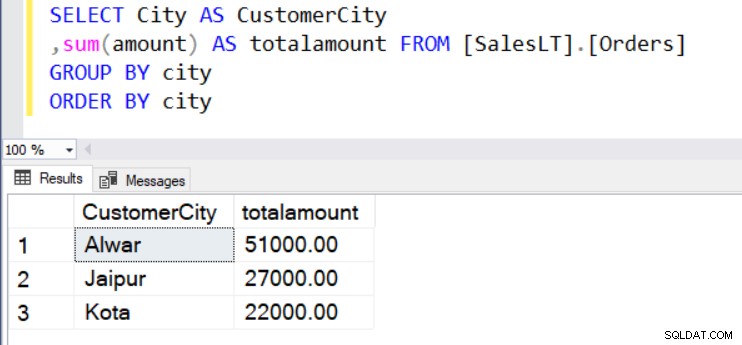
I resultatuppsättningen kan vi inte använda de icke aggregerade kolumnerna i SELECT-satsen. Vi kan till exempel inte visa [CustomerName] i utdata eftersom det inte ingår i GROUP BY-satsen.
SQL Server ger följande felmeddelande om du försöker använda den icke aggregerade kolumnen i kolumnlistan.
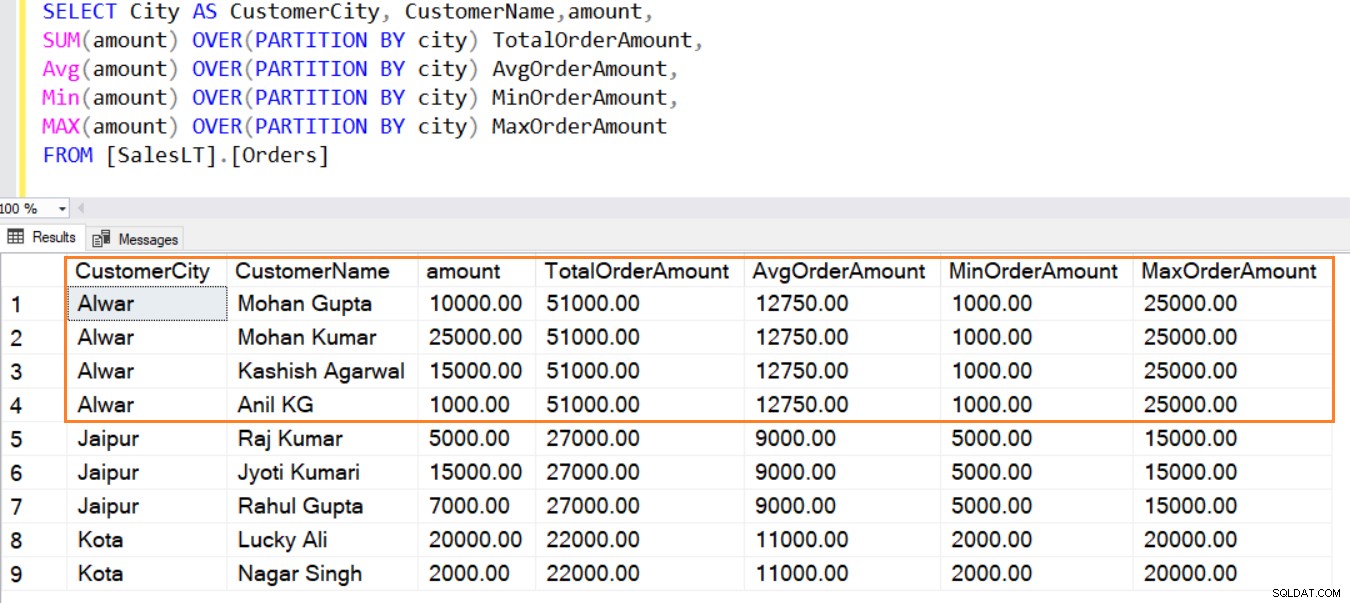
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount FROM [SalesLT].[Orders]
Som visas nedan skapar PARTITION BY-satsen ett mindre fönster (uppsättning datarader), utför aggregeringen och visar den. Du kan också se icke-aggregerade kolumner i denna utdata.
På samma sätt kan du använda funktionerna AVG(), MIN(), MAX() för att beräkna medel-, lägsta- och maxbelopp från raderna i ett fönster.
SELECT City AS CustomerCity, CustomerName,amount, SUM(amount) OVER(PARTITION BY city) TotalOrderAmount, Avg(amount) OVER(PARTITION BY city) AvgOrderAmount, Min(amount) OVER(PARTITION BY city) MinOrderAmount, MAX(amount) OVER(PARTITION BY city) MaxOrderAmount FROM [SalesLT].[Orders]
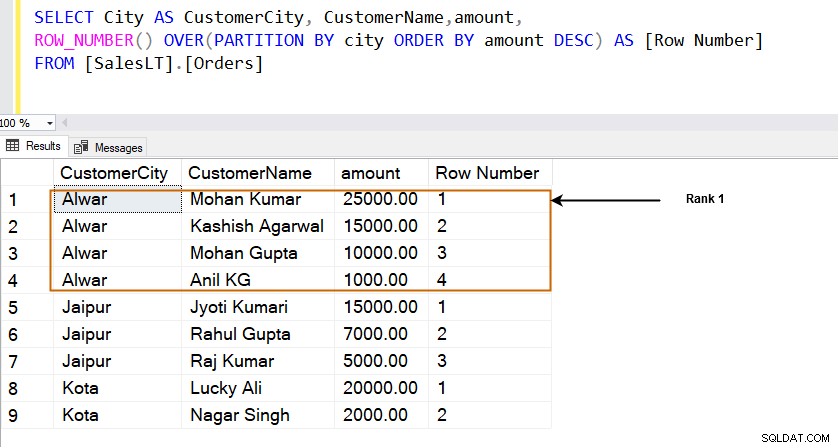
Använda SQL PARTITION BY-satsen med funktionen ROW_NUMBER()
Tidigare fick vi de aggregerade värdena i ett fönster med hjälp av PARTITION BY-satsen. Anta att vi istället för summan kräver den kumulativa summan i en partition.
En ackumulerad summa fungerar på följande sätt.
| Rad | Akumulerad summa |
| 1 | Rang 1+ 2 |
| 2 | Rang 2+3 |
| 3 | Rang 3+4 |
Radrankningen beräknas med funktionen ROW_NUMBER(). Låt oss först använda den här funktionen och se radrankningarna.
- ROW_NUMBER()-funktionen använder OVER- och PARTITION BY-satserna och sorterar resultaten i stigande eller fallande ordning. Den börjar rangordna rader från 1 enligt sorteringsordningen.
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number] FROM [SalesLT].[Orders]
Till exempel i staden [Alwar] finns raden med det högsta beloppet (25000,00) i rad 1. Som visas nedan rangordnar den rader i fönstret som anges av PARTITION BY-satsen. Till exempel har vi tre olika städer [Alwar], [Jaipur] och [Kota], och varje fönster (stad) får sina rader.
För att beräkna den kumulativa summan använder vi följande argument.
- AKTUELL RAD:Den anger start- och slutpunkten i det angivna intervallet.
- 1 följande:Den anger antalet rader (1) som ska följa från den aktuella raden.
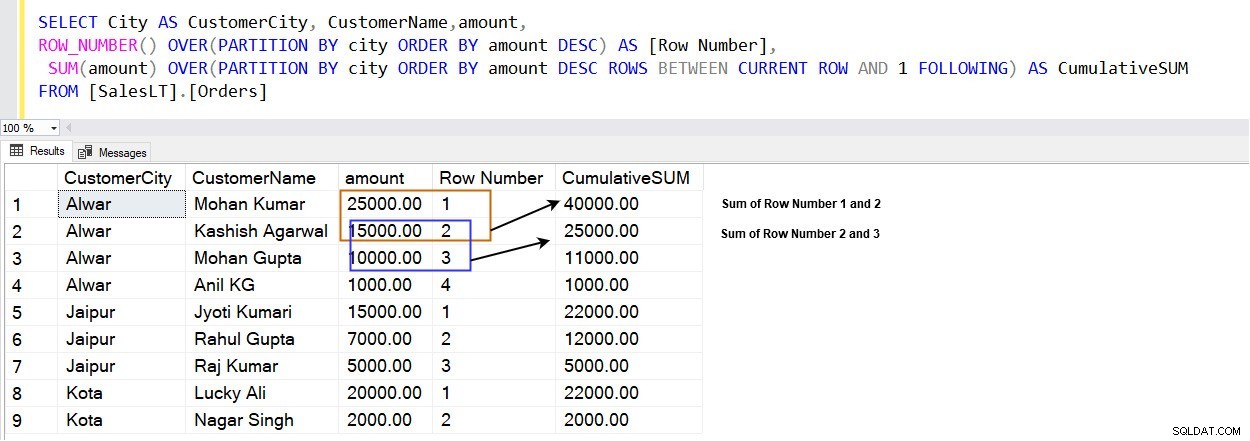
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS BETWEEN CURRENT ROW AND 1 FOLLOWING) AS CumulativeSUM FROM [SalesLT].[Orders]
Följande bild visar att du får en kumulativ summa istället för en total summa i ett fönster som anges av PARTITION BY-satsen.
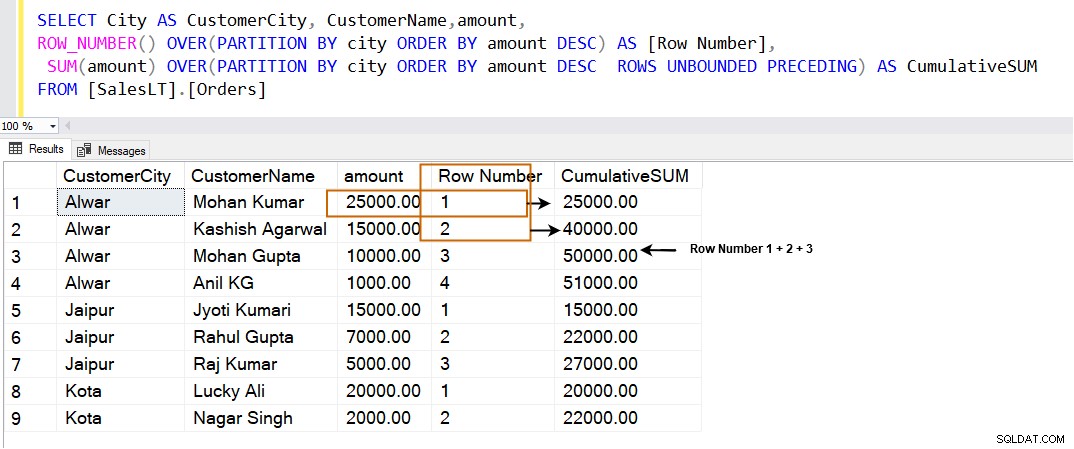
Om vi använder RADER UNBOUNDED PRECEDING i SQL PARTITION BY-satsen beräknar den den kumulativa summan på följande sätt. Den använder de aktuella raderna tillsammans med de rader som har de högsta värdena i det angivna fönstret.
| Rad | Akumulerad summa |
| 1 | ranking 1 |
| 2 | Rang 1+2 |
| 3 | Rang 1+2+3 |
SELECT City AS CustomerCity, CustomerName,amount, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Row Number], SUM(amount) OVER(PARTITION BY city ORDER BY amount DESC ROWS UNBOUNDED PRECEDING) AS CumulativeSUM FROM [SalesLT].[Orders]
Jämföra satsen GROUP BY och SQL PARTITION BY
| GRUPPA EFTER | PARTITION AV |
| Den returnerar en rad per grupp efter att ha beräknat de sammanlagda värdena. | Den returnerar alla rader från SELECT-satsen tillsammans med ytterligare kolumner med aggregerade värden. |
| Vi kan inte använda den icke-aggregerade kolumnen i SELECT-satsen. | Vi kan använda obligatoriska kolumner i SELECT-satsen, och det ger inga fel för den icke aggregerade kolumnen. |
| Det kräver att HAVING-satsen används för att filtrera poster från SELECT-satsen. | PARTITION-funktionen kan ha ytterligare predikat i WHERE-satsen förutom kolumnerna som används i SELECT-satsen. |
| GROUP BY används i vanliga aggregat. | PARTITION BY används i fönsterbaserade aggregat. |
| Vi kan inte använda det för att beräkna radnummer eller deras rangordning. | Den kan beräkna radnummer och deras rangordning i det mindre fönstret. |
Att använda den
Det rekommenderas att använda SQL PARTITION BY-satsen när du arbetar med flera datagrupper för de aggregerade värdena i den individuella gruppen. På samma sätt kan den användas för att visa ursprungliga rader med den extra kolumnen med aggregerade värden.