Hur mycket tid lägger du ner på att felsöka prestandaproblem som databasadministratör eller utvecklare? Har du någonsin spårat det? Som den genomsnittliga totala procentandelen av din dag kanske det inte ser ut som mycket tid, men när problemet är allvarligt kan du ägna timmar åt att spåra det och arbeta igenom orsaksanalys. Ibland försvinner problemet och du vet inte det verkliga ursprunget. Och ännu värre? När du måste kämpa mot dessa problem mitt i natten eller på helgen. Du försöker inte bara lösa ett problem, du förlorar också din personliga fritid. Hur lindrar vi det? Hur tar vi vår tid och ansträngning ur ekvationen och fixar prestanda samtidigt?
Funktionen Automatic Tuning i SQL Server 2017 Enterprise Edition och Azure SQL Database är det första steget för att minska den tid som dataproffs lägger ner på att felsöka och lösa prestandaproblem. Funktionen inkluderar automatisk plankorrigering och automatisk indexhantering (endast tillgängligt i Azure SQL Database), som är aktiverade oberoende. I det här inlägget vill jag fokusera på funktionen Automatisk plankorrigering. Med Automatic Plan Correction, om SQL Server upptäcker att en fråga har gått tillbaka avsevärt, kommer den att tvinga den senast kända bra planen för frågan att stabilisera prestandan. I huvudsak, snarare än att du, DBA eller utvecklare, blir uppringd på helgen om systemprestanda, kommer SQL Server att ta upp det åt dig. Låter för lätt, eller hur? Låt oss ta en titt.
Under täcket
För det första är det viktigt att förstå att automatisk plankorrigering använder Query Store, så det måste vara aktiverat för databasen. För det andra är automatisk plankorrigering helt enkelt automatisk plantvång. Medan Query Store marknadsförs som flight-recorder för din databas som spårar frågetext, planer, körtidsstatistik och väntestatistik, låter den dig också tvinga fram en plan för en fråga för att möjliggöra konsekvent prestanda. Automatisk plankorrigering är planframtvingande utan din inblandning.
Aktivera automatisk plankorrigering
Som nämnts måste Query Store först aktiveras för användardatabasen. Detta kan göras i SSMS, med T-SQL och med REST API för Azure SQL DB. Observera att Query Store är aktiverat som standard för databaser i Azure och har varit det sedan 2016 Q4.
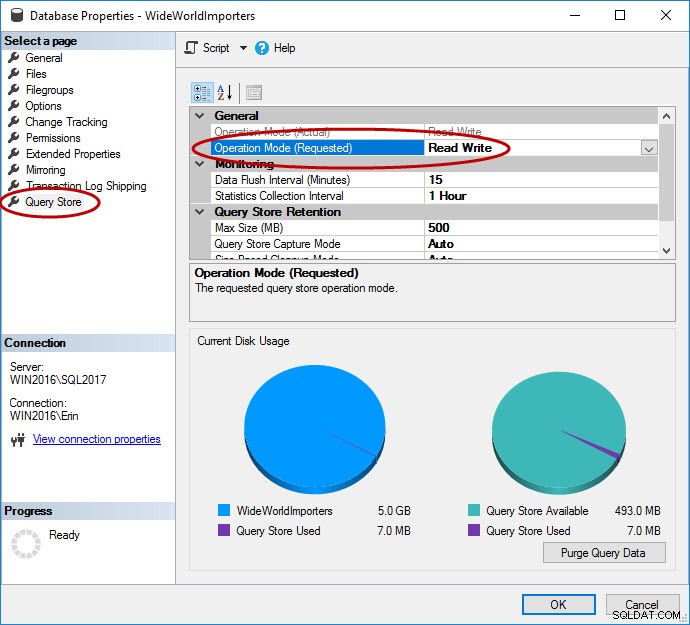
Aktivera Query Store via SSMS
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
Aktivera Query Store med T-SQL
Ovanstående kod är standard T-SQL från SSMS om du skriptar ut den. I Azure SQL Database kör du inte USE-satsen. Om du vill ändra något av standardalternativen, läs mitt inlägg i Query Store Settings om vad dessa alternativ är och överväganden för alternativa värden.
När Query Store har aktiverats kan du använda Azure Portal, T-SQL eller EST API för att aktivera automatisk plankorrigering i Azure SQL Database ((och C# och PowerShell är under arbete). Det kan endast aktiveras med T-SQL i SQL Server 2017.
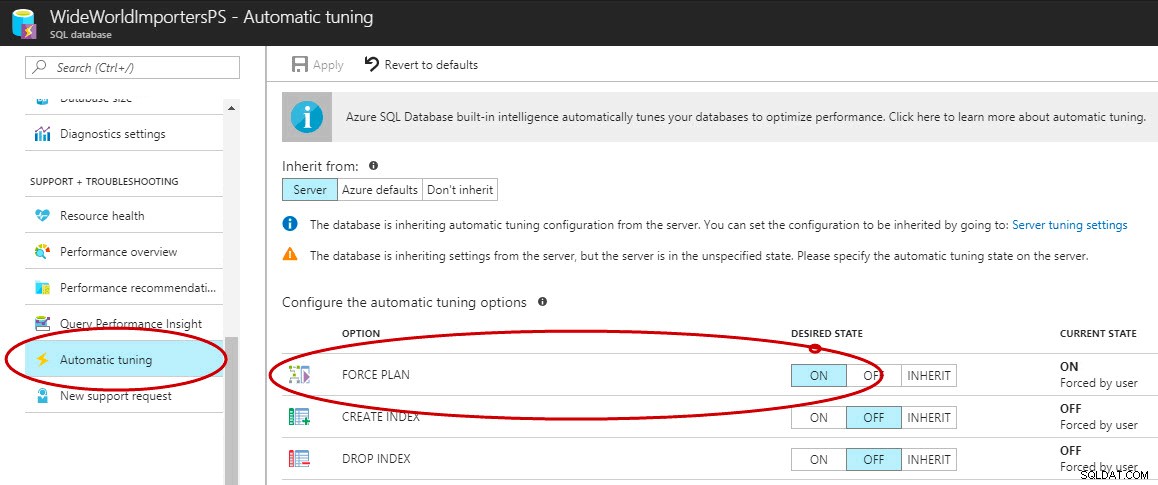
Aktivera automatisk plankorrigering i Azure Portal
ALTER DATABASE [WideWorldImporters] SET AUTOMATIC_TUNING ( FORCE_LAST_GOOD_PLAN = ON ); GO
Aktivera automatisk plankorrigering i T-SQL
Observera att automatisk plankorrigering kommer att aktiveras som standard för nya databaser i Azure inom en snar framtid. Från och med januari 2018 aktiveras automatisk justering för Azure SQL-databaser som inte redan har det aktiverat, med meddelanden skickade till administratörer så att alternativet kan inaktiveras om så önskas.
Så fungerar det
Med automatisk plankorrigering aktiverad övervakar SQL Server frågeprestanda med hjälp av Query Store-data. Det ser ut efter en betydande förändring* i CPU**-prestanda med ett 48-timmarsfönster***. Lägg märke till asteriskerna i den meningen... de är avsiktligt:
- *Tröskeln för vad som utgör en betydande ändring är inte dokumenterad eftersom Microsoft förbehåller sig rätten att ändra den.
- **Mätet som används för att fastställa förändringen i prestanda (CPU) är inte dokumenterat eftersom Microsoft förbehåller sig rätten att ändra det. Det betyder att Microsoft skulle kunna överväga ytterligare dimensioner för att titta på prestanda om det skulle vara bättre/prestera bättre än enbart CPU.
- ***Den tidsperiod under vilken frågeprestandadata jämförs är inte dokumenterad av samma anledning, Microsoft förbehåller sig rätten att ändra den.
- Obs! Även om ovannämnda saker inte dokumenterades, bekräftade jag med lämpliga personer på Microsoft att denna information kunde delas med att bryta mot eventuella NDA. Det är extremt viktigt att förstå att värdena inte är fasta och kan ändras, med förväntningen att de skulle ändras för att förbättra tillförlitligheten för funktionen.
Bristen på dokumentation och möjligheten till förändringar i tröskeln kan vara frustrerande för vissa individer, men här är vad som är riktigt viktigt att komma ihåg:
Microsoft fångar dagligen in terabyte av operativ telemetridata från SQL Azure-databaser, och denna data är avgörande för de automatiska funktioner som utvecklas. Dessa data inkluderar saker som query_id, query_plan_id och query_hash, och Microsoft fångar INTE query_text eller query_plan (de tittar inte på din faktiska data). Microsoft arkiverar inte bara den operativa telemetrin eller använder den för felsökning, de bryter den datan och använder den för att utveckla algoritmer och modeller för att tillåta SQL Server att fatta oberoende, intelligenta beslut.
SQL Server kan dra fördel av mängden data i Query Store som beskriver prestandan för frågor, och automatisk plankorrigering börjar med att jämföra nuvarande prestanda för en fråga med tidigare prestanda för att avgöra om det finns en regression i prestanda. Har prestandan sjunkit, eller blivit sämre, och i så fall är det avsevärt?
Om det har skett en regression i frågeprestanda, kommer SQL Server att tvinga fram den senast kända bra planen för den frågan, som naturligtvis hämtas från Query Store. Men det stannar inte där. SQL Server fortsätter sedan att övervaka prestanda – fortfarande med hjälp av Query Store – för att bekräfta att den påtvingade planen fortfarande är en bra plan för den frågan, vilket innebär att frågan med den påtvingade planen presterar bättre än den regresserade versionen. Om den frågan inte fungerar bättre, kommer den att upphäva planen. En plan kan också vara avtvingad om det finns en omkompilering, eller om forcering misslyckas.
Denna cykel fortsätter; om en fråga har en påtvingad plan, och den planen inte tvingas fram av någon av de ovannämnda anledningarna, kan samma plan tvingas fram igen senare, eller så kan det finnas en annan plan som tvingas fram för den frågan vid ett senare tillfälle. Detta är en kontinuerlig process som sker så länge du har alternativet Automatisk plankorrigering aktiverat för databasen. Nu, det intressanta är att du kan titta på samma information som den här funktionen fångar och använda den kraftplaner manuellt. Det vill säga, i SQL Server 2017 Enterprise Edition och i Azure SQL Database, samlas denna data in i sys.dm_db_tuning_recommendations DMV även när funktionen Automatic Plan Correction inte är aktiverad, så att du kan undersöka denna data och följa dess rekommendationer för att tvinga fram planer för specifika frågor på egen hand. Observera att om du tvingar fram en plan med hjälp av rekommendationer från sys.dm_db_tuning_recommendations, kommer den aldrig att automatiskt upphävas. Vidare, om du har aktiverat automatisk plankorrigering och du tvingar fram en plan manuellt, kommer den aldrig att automatiskt upphävas. Endast planer som tvingas fram med funktionen Automatisk plankorrigering kommer att upphävas automatiskt.
Kommer jag verkligen att låta SQL Server ha kontroll?
Om du är skeptisk och undrar om du verkligen kan lita på att SQL Server fattar ett planframtvingande beslut, det här är vad jag skulle uppmuntra dig att komma ihåg:
- Den här funktionen utvecklades med en svindlande mängd data som samlats in från nästan två miljoner Azure SQL-databaser. Det är en ny funktion i SQL Server 2017, men den blev global tillgänglig 2016 i Azure, så den här funktionen har verkligen varit tillgänglig i över ett år och den har förfinats.
- Ingenjörerna har gjort ändringar i algoritmen över tiden, eftersom de har fångat in mer data. Det kanske inte hittar varje regression som inträffar – eftersom en regression kanske inte är tillräckligt allvarlig, men jag skulle slå vad om att många av er hellre skulle ha denna funktionskraft mer sällan än för ofta.
- Utöver det, om en plan tvingas fram men orsakar ett problem, är SQL Servers förmåga att återhämta sig från det och avaktivera planen extremt tillförlitlig och sker mycket snabbt.
Sammanfattning
Du kanske inte är bekväm med tanken på att SQL Server åtgärdar prestandaproblem åt dig. Men är det obehaget för att du tror att det kommer att göra ett dåligt beslut? Eller är du orolig för att automatisering ska ta över ditt jobb? Ganska direkt fråga, jag vet. Om det är det förra, så är min rekommendation att titta på data som fångas i sys.dm_db_tuning_recommendations (utan att aktivera automatisk plankorrigering) och se vad SQL Server skulle vilja göra. Stämmer det överens med vad du skulle göra? Hittar den regressioner som du kan missa? Om du inte vill aktivera funktionen för att du är rädd att du plötsligt inte kommer att ha tillräckligt att göra, uppmuntrar jag dig att läsa Conor Cunninghams senaste inlägg, How cloud speed helps SQL Server DBAs. Microsoft försöker inte koda dig från ett jobb. De försöker helt enkelt hantera den lågt hängande frukten så att du kan fokusera på viktigare uppgifter.