För några veckor sedan gjorde jag en ganska stor sak om SQL Server 2016 Service Pack 1. Många funktioner som tidigare reserverats för Enterprise Edition släpptes lös till lägre upplagor, och jag var extatisk över att lära mig om dessa ändringar.
Ändå ser jag några människor som är, låt oss säga, lite mindre upphetsade än jag.
Det är viktigt att komma ihåg att ändringarna här inte var avsedda att ge fullständig funktionsparitet över alla utgåvor; de var för det specifika syftet att skapa en mer konsekvent programmeringsyta. Nu kan kunder använda funktioner som In-Memory OLTP, Columnstore och komprimering utan att oroa sig för den eller de riktade utgåvorna – bara om hur väl de kommer att skalas. Flera säkerhetsfunktioner som egentligen inte verkade ha något med edition att göra öppnas också. Den jag förstod minst var Always Encrypted; Jag kunde inte förstå varför bara Enterprise-kunder behövde skydda saker som kreditkortsdata. Transparent datakryptering är fortfarande enbart för företag, på versioner tidigare än SQL Server 2019, eftersom detta egentligen inte är en programmerbarhetsfunktion (antingen är den på eller inte).
Så vad finns det egentligen för Standard Edition-kunder?
Jag tror att det största problemet de flesta har är att maxminnet i Standard Edition fortfarande är begränsat till 128GB. De tittar på det och säger:"Jösses, tack för alla funktioner, men minnesgränsen betyder att jag inte riktigt kan använda dem."
Ytförändringarna medför dock möjligheter till prestationsförbättringar, även om det inte var deras ursprungliga avsikt (eller ens om det var det – jag var inte med på något av dessa möten). Låt oss ta en närmare titt på en liten del av det finstilta (från de officiella dokumenten):
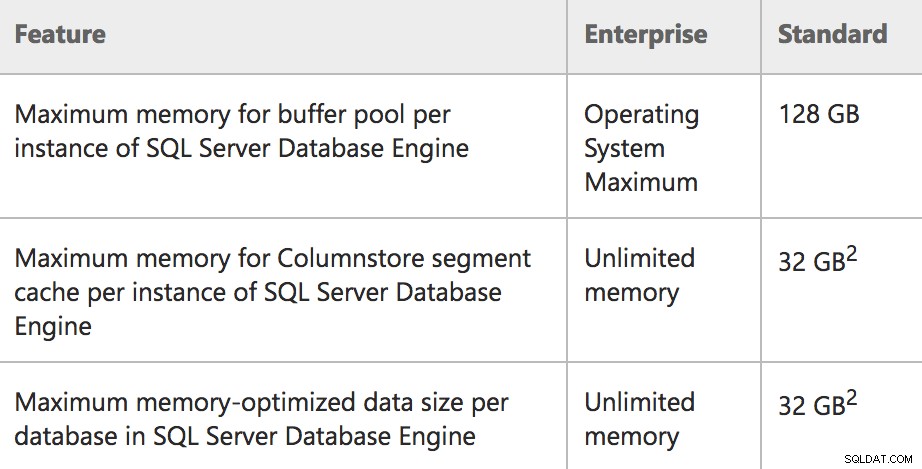 Minnesgränser för Enterprise/Standard i SQL Server 2016 SP1
Minnesgränser för Enterprise/Standard i SQL Server 2016 SP1
Den skarpsinniga läsaren kommer att märka att formuleringen av buffertpoolens gräns har ändrats, från:
Minne:Maximalt utnyttjat minne per instansTill:
Minne:Maximal buffertpoolstorlek per instansDet här är en bättre beskrivning av vad som verkligen händer i Standard Edition:en gräns på 128 GB endast för buffertpoolen, och andra minnesreservationer kan vara utöver det (tänk på pooler som planens cache). Så i själva verket kan en Standard Edition-server använda 128 GB buffertpool, då kan max serverminne vara högre och stödja mer minne som används för andra reservationer. På liknande sätt är Express Edition nu korrekt dokumenterad för att använda 1,4 GB för buffertpoolen.
Du kanske också lägger märke till en mycket specifik formulering i kolumnen längst till vänster (t.ex. "per instans" och "per databas") för de funktioner som exponeras i Standard Edition för första gången. För att vara mer specifik:
- Förekomsten är begränsad till 128 GB minne för buffertpoolen .
- Förekomsten kan ha en ytterligare 32 GB allokerat till Columnstore-objekt, utöver buffertpoolens gräns.
- Varje användardatabas på instansen kan ha en ytterligare 32 GB allokerat till minnesoptimerade tabeller, utöver buffertpoolsgränsen.
Och för att vara kristallklar:Dessa minnesgränser för ColumnStore och In-Memory OLTP subtraheras INTE från buffertpoolsgränsen , så länge servern har mer än 128 GB tillgängligt minne. Om servern har mindre än 128 GB kommer du att se dessa tekniker konkurrera med buffertpoolsminne och i själva verket vara begränsade till en % av max serverminne. Mer information finns i det här inlägget från Microsofts Parikshit Savjani.
Jag har ingen hårdvara till hands för att testa omfattningen av detta, men om du hade en maskin med 256 GB eller 512 GB minne skulle du teoretiskt kunna använda allt med en enda Standard Edition-instans, om du till exempel kunde sprida din In - Minnesdata över databaser i <=32 GB-bitar, totalt 128 GB + (32 GB * (antal databaser)). Om du ville använda ColumnStore istället för In-Memory, kan du sprida dina data över flera instanser, vilket ger dig (128 GB + 32 GB) * (antal instanser). Och du kan kombinera dessa strategier för ((128GB + 32GB ColumnStore) * (Antal instanser)) + (32GB In-Memory * (Antal databaser * Antal instanser)).
Jag är inte säker på om det är praktiskt för din applikation att dela upp din data på detta sätt; Jag antyder bara att det är möjligt. Vissa av er kanske redan gör några av dessa saker för att få bättre användning av Standard Edition på servrar med mer än 128 GB minne.
Med ColumnStore specifikt, förutom att få använda 32GB utöver buffertpoolen, kom ihåg att komprimeringen du kan få här innebär att du ofta kan passa mycket mer i den 32GB-gränsen än vad du skulle kunna med samma data i traditionella rad-butik. Och om du inte kan använda ColumnStore av någon anledning (eller om den fortfarande inte passar in i 32 GB), kan du nu implementera traditionell sid- eller radkomprimering – detta kanske inte tillåter dig att passa in hela din databas i buffertpoolen på 128 GB, men det kan göra att mer av dina data finns i minnet vid varje given tidpunkt.
Liknande saker är möjliga i Express (i lägre skala), där du kan ha 1,4 GB för buffertpool, men ytterligare ~352 MB per instans för ColumnStore och ~352 MB per databas för In-Memory OLTP.
Men Enterprise Edition har fortfarande många fördelar
Det finns många andra skillnader för att behålla intresset för Enterprise Edition, förutom obegränsade minnesbegränsningar runt om – från online-ombyggnader och merry-go-round skanningar till full-on tillgänglighetsgrupper och alla virtualiseringsrättigheter du kan skaka en käpp på. Även ColumnStore-index har väldefinierade prestandaförbättringar reserverade för Enterprise Edition.
Så bara för att det finns några tekniker som gör att du kan få ut mer av Standard Edition, betyder det inte att den på magiskt sätt kommer att skalas för att möta dina prestationsbehov. Precis som mina andra inlägg om "att göra det på en budget" (t.ex. partitionering och läsbara sekundärer), kan du säkert lägga tid och ansträngning på att klämma ihop en lösning, men det kommer bara att ta dig så långt. Poängen med det här inlägget var helt enkelt att visa att du kan komma längre med Standard Edition i 2016 SP1 än du någonsin kunnat förut.