Förra veckan gjorde jag ett par snabba prestandajämförelser och satte den nya STRING_AGG() funktion mot den traditionella FOR XML PATH tillvägagångssätt som jag har använt i evigheter. Jag testade både odefinierad/godtycklig ordning såväl som explicit ordning, och STRING_AGG() kom överst i båda fallen:
- SQL Server v.Next :STRING_AGG() Performance, del 1
För dessa tester utelämnade jag flera saker (inte alla avsiktligt):
- Mikael Eriksson och Grzegorz Łyp påpekade båda att jag inte använde den absolut mest effektiva
FOR XML PATHkonstruera (och för att vara tydlig, det har jag aldrig gjort). - Jag utförde inga tester på Linux; endast på Windows. Jag förväntar mig inte att de kommer att vara väldigt olika, men eftersom Grzegorz såg väldigt olika varaktigheter är detta värt att undersöka ytterligare.
- Jag testade också bara när utdata skulle vara en ändlig, icke-LOB-sträng – vilket jag tror är det vanligaste användningsfallet (jag tror inte att folk vanligtvis kommer att sammanfoga varje rad i en tabell till en enda kommaseparerad sträng, men det är därför jag frågade i mitt tidigare inlägg om ditt användningsfall.
- För beställningstesterna skapade jag inte ett index som kan vara till hjälp (eller försökte något där all data kom från en enda tabell).
I det här inlägget kommer jag att ta itu med ett par av dessa föremål, men inte alla.
FÖR XML-SÖG
Jag hade använt följande:
... FOR XML PATH, TYPE).value(N'.[1]', ...
Efter den här kommentaren från Mikael har jag uppdaterat min kod för att istället använda denna lite annorlunda konstruktion:
... FOR XML PATH(''), TYPE).value(N'text()[1]', ... Linux vs. Windows
Från början hade jag bara brytt mig om att köra tester på Windows:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. Developer Edition (64-bit) on Windows Server 2016 Datacenter 6.3(Build 14393: ) (Hypervisor)
Men Grzegorz gjorde en rättvis poäng att han (och förmodligen många andra) bara hade tillgång till Linux-smaken av CTP 1.1. Så jag lade till Linux i min testmatris:
Microsoft SQL Server vNext (CTP1.1) - 14.0.100.187 (X64) Dec 10 2016 02:51:11 Copyright (C) 2016 Microsoft Corporation. All rights reserved. on Linux (Ubuntu 16.04.1 LTS)
Några intressanta men helt tangentiella observationer:
@@VERSIONvisar inte utgåvan i den här versionen, menSERVERPROPERTY('Edition')returnerar den förväntadeDeveloper Edition (64-bit).- Baserat på byggtiderna som kodats till binärfilerna verkar Windows- och Linux-versionerna nu vara kompilerade samtidigt och från samma källa. Eller så var detta en galen slump.
Oordnade tester
Jag började med att testa den godtyckligt ordnade utgången (där det inte finns någon explicit definierad ordning för de sammanlänkade värdena). Efter Grzegorz använde jag WideWorldImporters (Standard), men gjorde en koppling mellan Sales.Orders och Sales.OrderLines . Det fiktiva kravet här är att mata ut en lista över alla beställningar, och tillsammans med varje beställning, en kommaseparerad lista över varje StockItemID .
Sedan StockItemID är ett heltal kan vi använda en definierad varchar , vilket innebär att strängen kan vara 8000 tecken innan vi behöver oroa oss för att behöva MAX. Eftersom en int kan vara en maxlängd på 11 (egentligen 10, om osignerad), plus ett kommatecken, betyder det att en beställning måste stödja cirka 8 000/12 (666) lagerartiklar i värsta fall (t.ex. alla StockItemID-värden har 11 siffror). I vårt fall är det längsta ID:t 3 siffror, så tills data läggs till skulle vi faktiskt behöva 8 000/4 (2 000) unika lagervaror i varje enskild beställning för att motivera MAX. I vårt fall är det bara 227 lagervaror totalt, så MAX är inte nödvändigt, men det bör du hålla ett öga på. Om en så stor sträng är möjlig i ditt scenario, måste du använda varchar(max) istället för standardvärdet (STRING_AGG() returnerar nvarchar(max) , men trunkeras till 8 000 byte om inte ingången är en MAX-typ).
De initiala frågorna (för att visa exempelutdata och för att observera varaktigheter för enstaka körningar):
SET STATISTICS TIME ON;
GO
SELECT o.OrderID, StockItemIDs = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT o.OrderID,
StockItemIDs = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Sample output:
OrderID StockItemIDs
======= ============
1 67
2 50,10
3 114
4 206,130,50
5 128,121,155
Important SET STATISTICS TIME metrics (SQL Server Execution Times):
Windows:
STRING_AGG: CPU time = 217 ms, elapsed time = 405 ms.
FOR XML PATH: CPU time = 1954 ms, elapsed time = 2097 ms.
Linux:
STRING_AGG: CPU time = 627 ms, elapsed time = 472 ms.
FOR XML PATH: CPU time = 2188 ms, elapsed time = 2223 ms.
*/
Jag ignorerade analysen och kompileringen av tidsdata helt, eftersom de alltid var exakt noll eller tillräckligt nära för att vara irrelevanta. Det fanns mindre avvikelser i exekveringstiderna för varje körning, men inte mycket – kommentarerna ovan återspeglar det typiska deltat i körtid (STRING_AGG verkade dra lite fördel av parallellism där, men bara på Linux, medan FOR XML PATH inte på någon av plattformarna). Båda maskinerna hade en enda sockel, fyrkärnig CPU tilldelad, 8 GB minne, färdig konfiguration och ingen annan aktivitet.
Sedan ville jag testa i skala (helt enkelt en enda session som kör samma fråga 500 gånger). Jag ville inte returnera all utdata, som i ovanstående fråga, 500 gånger, eftersom det skulle ha överväldigat SSMS – och förhoppningsvis inte representerar verkliga frågescenarier ändå. Så jag tilldelade utdata till variabler och mätte bara den totala tiden för varje batch:
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID, @x = STRING_AGG(ol.StockItemID, ',')
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int, @x varchar(8000);
SELECT @i = o.OrderID,
@x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Jag körde dessa tester tre gånger, och skillnaden var stor – nästan en storleksordning. Här är den genomsnittliga varaktigheten för de tre testerna:
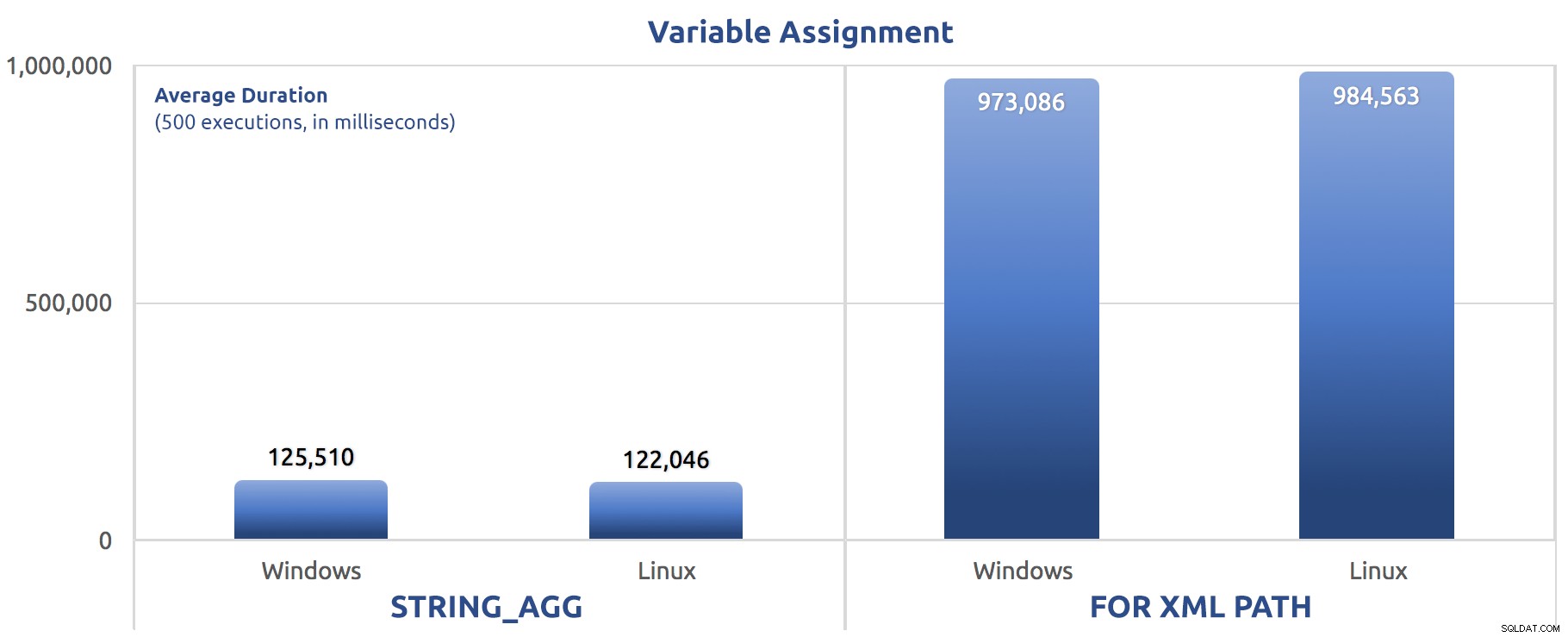 Genomsnittlig varaktighet, i millisekunder, för 500 körningar av variabel tilldelning
Genomsnittlig varaktighet, i millisekunder, för 500 körningar av variabel tilldelning
Jag testade en mängd andra saker på det här sättet också, mest för att vara säker på att jag täckte de typer av tester Grzegorz körde (utan LOB-delen).
- Väljer bara längden på utdata
- Hämta den maximala längden på utdata (för en godtycklig rad)
- Väljer all utdata till en ny tabell
Väljer bara längden på utdata
Den här koden går bara igenom varje beställning, sammanfogar alla StockItemID-värden och returnerar sedan bara längden.
SET STATISTICS TIME ON;
GO
SELECT LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
SELECT LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 142 ms, elapsed time = 351 ms.
FOR XML PATH: CPU time = 1984 ms, elapsed time = 2120 ms.
Linux:
STRING_AGG: CPU time = 310 ms, elapsed time = 191 ms.
FOR XML PATH: CPU time = 2149 ms, elapsed time = 2167 ms.
*/ För batchversionen använde jag återigen variabeltilldelning istället för att försöka returnera många resultatuppsättningar till SSMS. Variabeltilldelningen skulle hamna på en godtycklig rad, men detta kräver fortfarande fullständig genomsökning, eftersom den godtyckliga raden inte väljs först.
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = LEN(STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO 500
SELECT sysdatetime(); Prestandamått för 500 körningar:
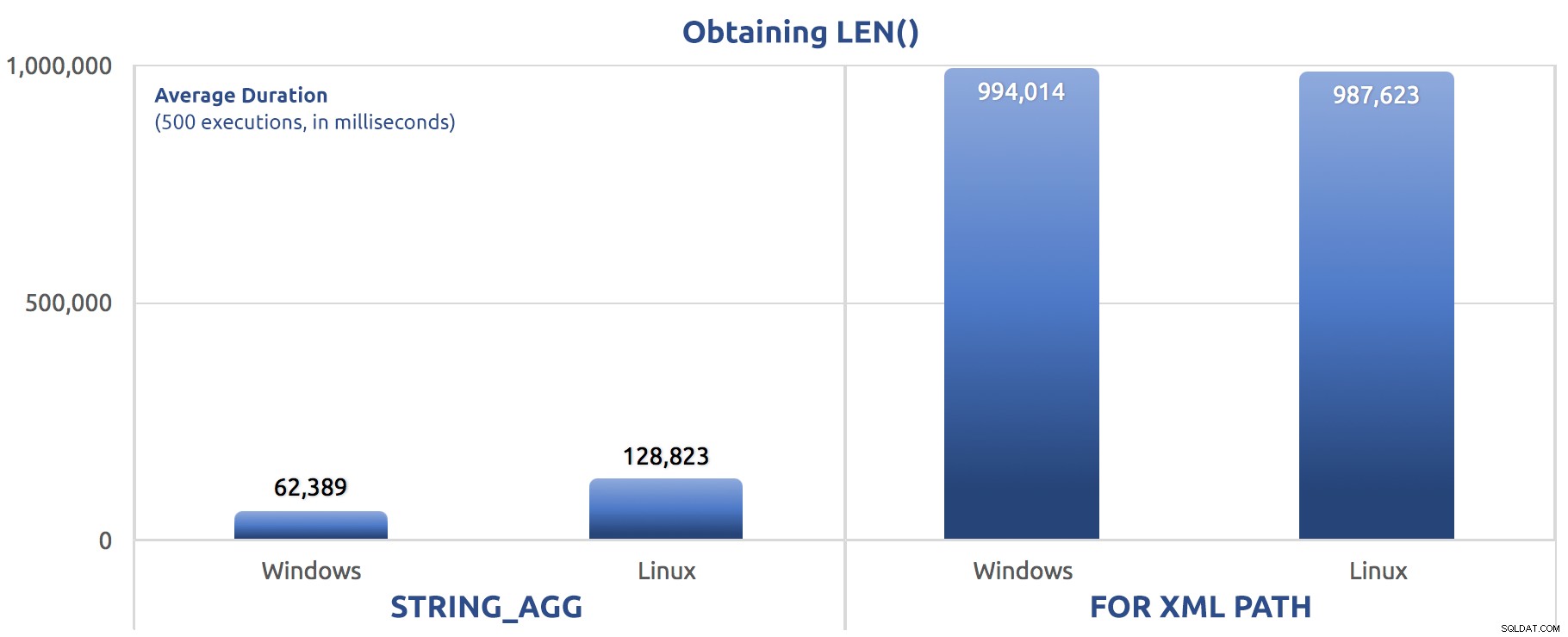 500 körningar för att tilldela LEN() till en variabel
500 körningar för att tilldela LEN() till en variabel
Återigen ser vi FOR XML PATH är mycket långsammare, både på Windows och Linux.
Välja den maximala längden för utgången
En liten variation på det tidigare testet, det här hämtar bara maximum längden på den sammanlänkade utdata:
SET STATISTICS TIME ON;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO
SELECT MAX(s) FROM (SELECT s = LEN(STUFF(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 188 ms, elapsed time = 48 ms.
FOR XML PATH: CPU time = 1891 ms, elapsed time = 907 ms.
Linux:
STRING_AGG: CPU time = 270 ms, elapsed time = 83 ms.
FOR XML PATH: CPU time = 2725 ms, elapsed time = 1205 ms.
*/ Och i skala tilldelar vi bara den utdata till en variabel igen:
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STRING_AGG(ol.StockItemID, ','))
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime();
GO
DECLARE @i int;
SELECT @i = MAX(s) FROM (SELECT s = LEN(STUFF
(
(SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),
1,1,''))
FROM Sales.Orders AS o
GROUP BY o.OrderID) AS x;
GO 500
SELECT sysdatetime(); Prestandaresultat, för 500 körningar, var i genomsnitt över tre körningar:
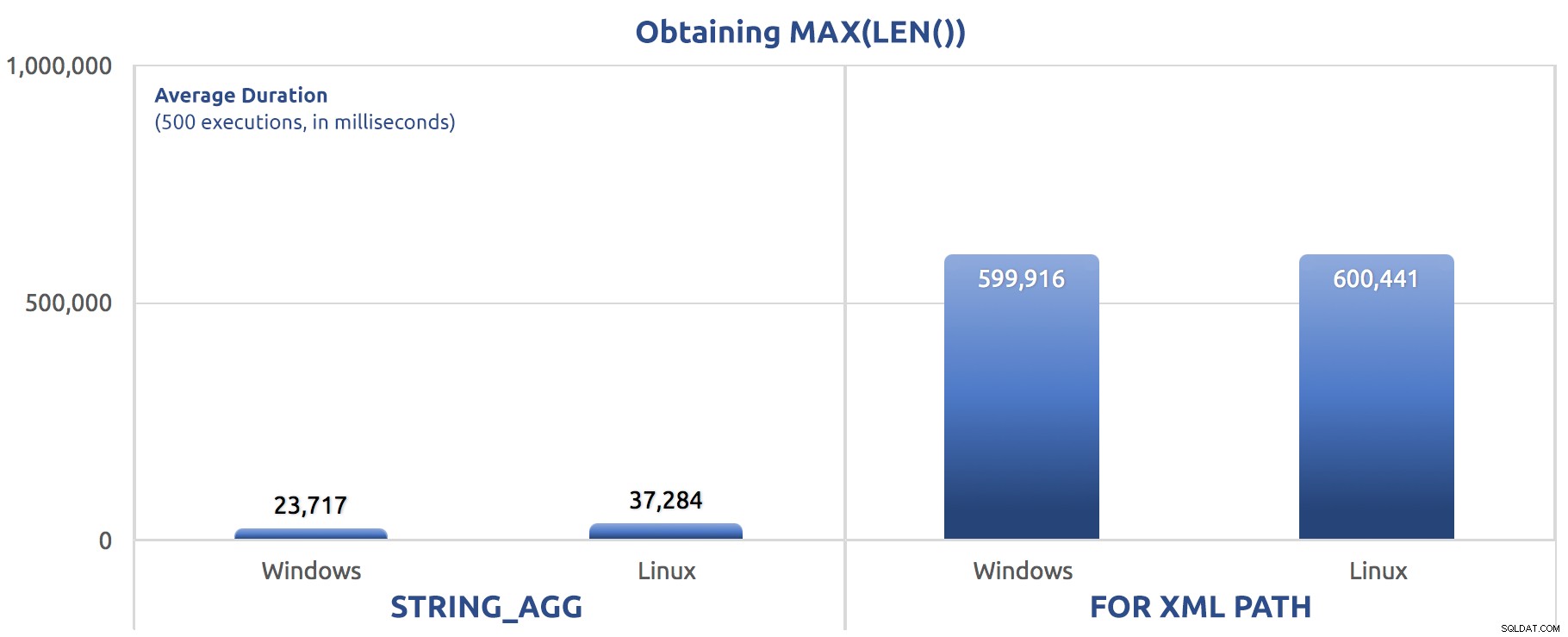 500 körningar för att tilldela MAX(LEN()) till en variabel
500 körningar för att tilldela MAX(LEN()) till en variabel
Du kanske börjar märka ett mönster i dessa tester – FOR XML PATH är alltid en hund, även med de prestationsförbättringar som föreslogs i mitt tidigare inlägg.
VÄLJ IN TILL
Jag ville se om metoden för sammanlänkning hade någon inverkan på skrivandet data tillbaka till disken, vilket är fallet i vissa andra scenarier:
SET NOCOUNT ON;
GO
SET STATISTICS TIME ON;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_AGG;
SELECT o.OrderID, x = STRING_AGG(ol.StockItemID, ',')
INTO dbo.HoldingTank_AGG
FROM Sales.Orders AS o
INNER JOIN Sales.OrderLines AS ol
ON o.OrderID = ol.OrderID
GROUP BY o.OrderID;
GO
DROP TABLE IF EXISTS dbo.HoldingTank_XML;
SELECT o.OrderID, x = STUFF((SELECT ',' + CONVERT(varchar(11),ol.StockItemID)
FROM Sales.OrderLines AS ol
WHERE ol.OrderID = o.OrderID
FOR XML PATH(''), TYPE).value(N'text()[1]',N'varchar(8000)'),1,1,'')
INTO dbo.HoldingTank_XML
FROM Sales.Orders AS o
GROUP BY o.OrderID;
GO
SET STATISTICS TIME OFF;
/*
Windows:
STRING_AGG: CPU time = 218 ms, elapsed time = 90 ms.
FOR XML PATH: CPU time = 4202 ms, elapsed time = 1520 ms.
Linux:
STRING_AGG: CPU time = 277 ms, elapsed time = 108 ms.
FOR XML PATH: CPU time = 4308 ms, elapsed time = 1583 ms.
*/
I det här fallet ser vi att kanske SELECT INTO kunde dra fördel av lite parallellitet, men vi ser ändå FOR XML PATH kamp, med körtider en storleksordning längre än STRING_AGG .
Den batchversionen bytte precis ut SET STATISTICS-kommandona för SELECT sysdatetime(); och la till samma GO 500 efter de två huvudsatserna som med de tidigare testerna. Så här gick det ut (igen, berätta om du har hört den här tidigare):
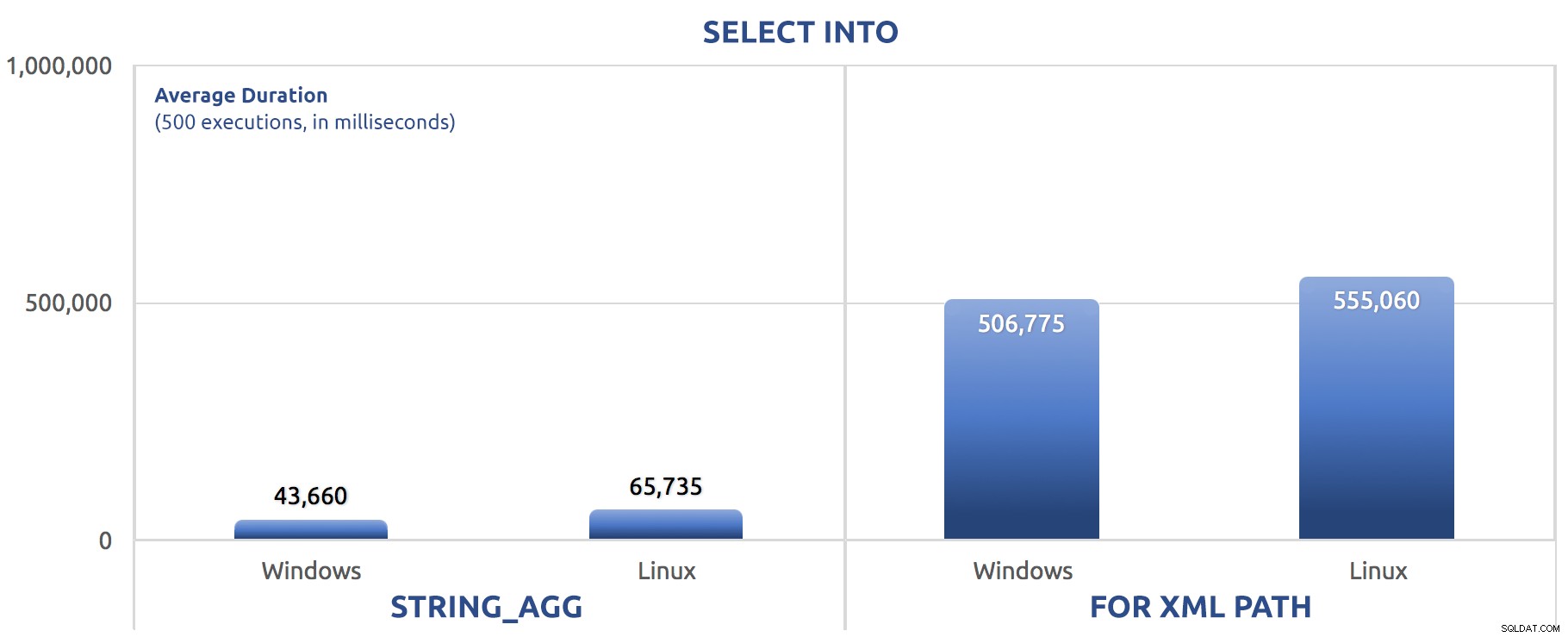 500 körningar av SELECT INTO
500 körningar av SELECT INTO
Beställda tester
Jag körde samma test med den ordnade syntaxen, t.ex.:
... STRING_AGG(ol.StockItemID, ',')
WITHIN GROUP (ORDER BY ol.StockItemID) ...
... WHERE ol.OrderID = o.OrderID
ORDER BY ol.StockItemID
FOR XML PATH('') ... Detta hade väldigt liten inverkan på någonting – samma uppsättning av fyra testriggar visade nästan identiska mätvärden och mönster över hela linjen.
Jag kommer att vara nyfiken på att se om detta är annorlunda när den sammanlänkade utgången är i icke-LOB eller där sammansättningen behöver ordna strängar (med eller utan ett stödjande index).
Slutsats
För icke-LOB-strängar , det är tydligt för mig att STRING_AGG har en definitiv prestandafördel jämfört med FOR XML PATH , på både Windows och Linux. Observera att, för att undvika kravet på varchar(max) eller nvarchar(max) , Jag använde inget som liknade de tester Grzegorz körde, vilket skulle ha inneburit att helt enkelt sammanfoga alla värden från en kolumn, över en hel tabell, till en enda sträng. I mitt nästa inlägg ska jag ta en titt på användningsfallet där utdata från den sammanlänkade strängen möjligen kan vara större än 8 000 byte, och så LOB-typer och omvandlingar skulle behöva användas.