För några veckor sedan skrev jag om hur förvånad jag var över prestandan av en ny inbyggd funktion i SQL Server 2016, STRING_SPLIT() :
- Prestanda överraskningar och antaganden:STRING_SPLIT()
Efter att inlägget publicerats fick jag några kommentarer (offentligt och privat) med dessa förslag (eller frågor som jag förvandlade till förslag):
- Ange en explicit utdatatyp för JSON-metoden, så att den metoden inte drabbas av potentiella prestandakostnader på grund av fallback av
nvarchar(max). - Testar ett lite annorlunda tillvägagångssätt, där något faktiskt görs med datan – nämligen
SELECT INTO #temp. - Visar hur uppskattat antal rader jämförs med befintliga metoder, särskilt när man kapslar delade operationer.
Jag svarade några personer offline, men tyckte att det skulle vara värt att lägga upp en uppföljning här.
Var rättvisare mot JSON
Den ursprungliga JSON-funktionen såg ut så här, utan specifikation för utdatatyp:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); Jag döpte om det och skapade två till med följande definitioner:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Jag trodde att detta skulle förbättra prestandan drastiskt, men tyvärr var det inte så. Jag körde testerna igen och resultatet var följande:
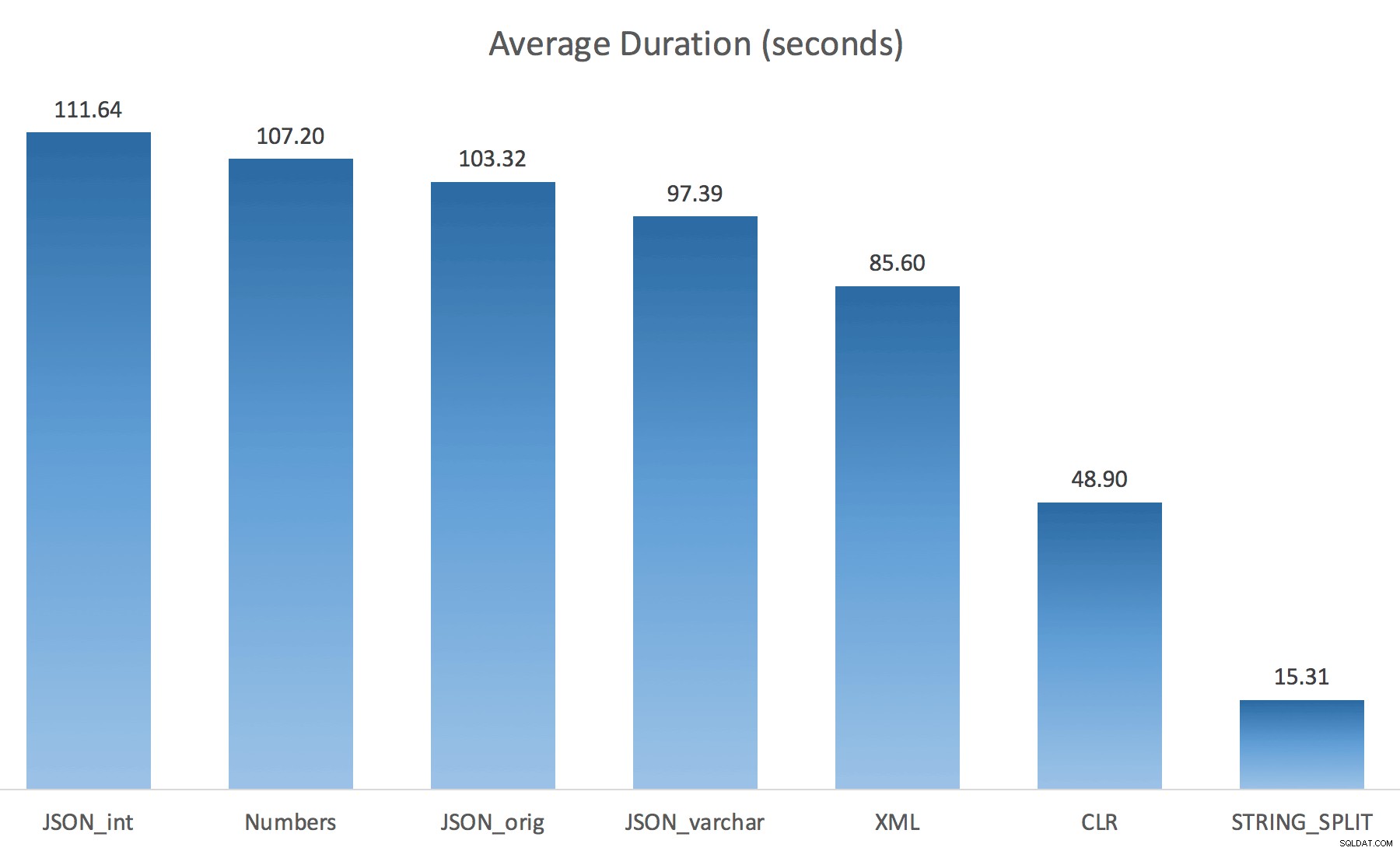
De väntetider som observerats under en slumpmässig instans av testet (filtrerade till de> 25):
| CLR | IO_COMPLETION | 1 595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6 294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4 307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6 110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Siffror | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1 917 |
| IO_COMPLETION | 1 616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Väntor observerade> 25 (observera att det inte finns någon post för STRING_SPLIT )
Medan du ändrar från standard till varchar(100) förbättrade prestandan lite, vinsten var försumbar och ändrades till int gjorde det faktiskt värre. Lägg till detta att du förmodligen behöver lägga till STRING_ESCAPE() till den inkommande strängen i vissa scenarier, ifall de har tecken som stör JSON-tolkningen. Min slutsats är fortfarande att detta är ett snyggt sätt att använda den nya JSON-funktionen, men mest en nyhet som är olämplig i rimlig skala.
Materialisera utdata
Jonathan Magnan gjorde denna skarpsinniga observation i mitt tidigare inlägg:
STRING_SPLIT är verkligen väldigt snabb, men också långsam som fan när man arbetar med temporära tabeller (såvida det inte fixas i en framtida version).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Kommer att vara MYCKET långsammare än SQL CLR-lösning (15x och mer!).
Så jag grävde i. Jag skapade kod som skulle anropa var och en av mina funktioner och dumpa resultaten i en #temp-tabell och ta tid för dem:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
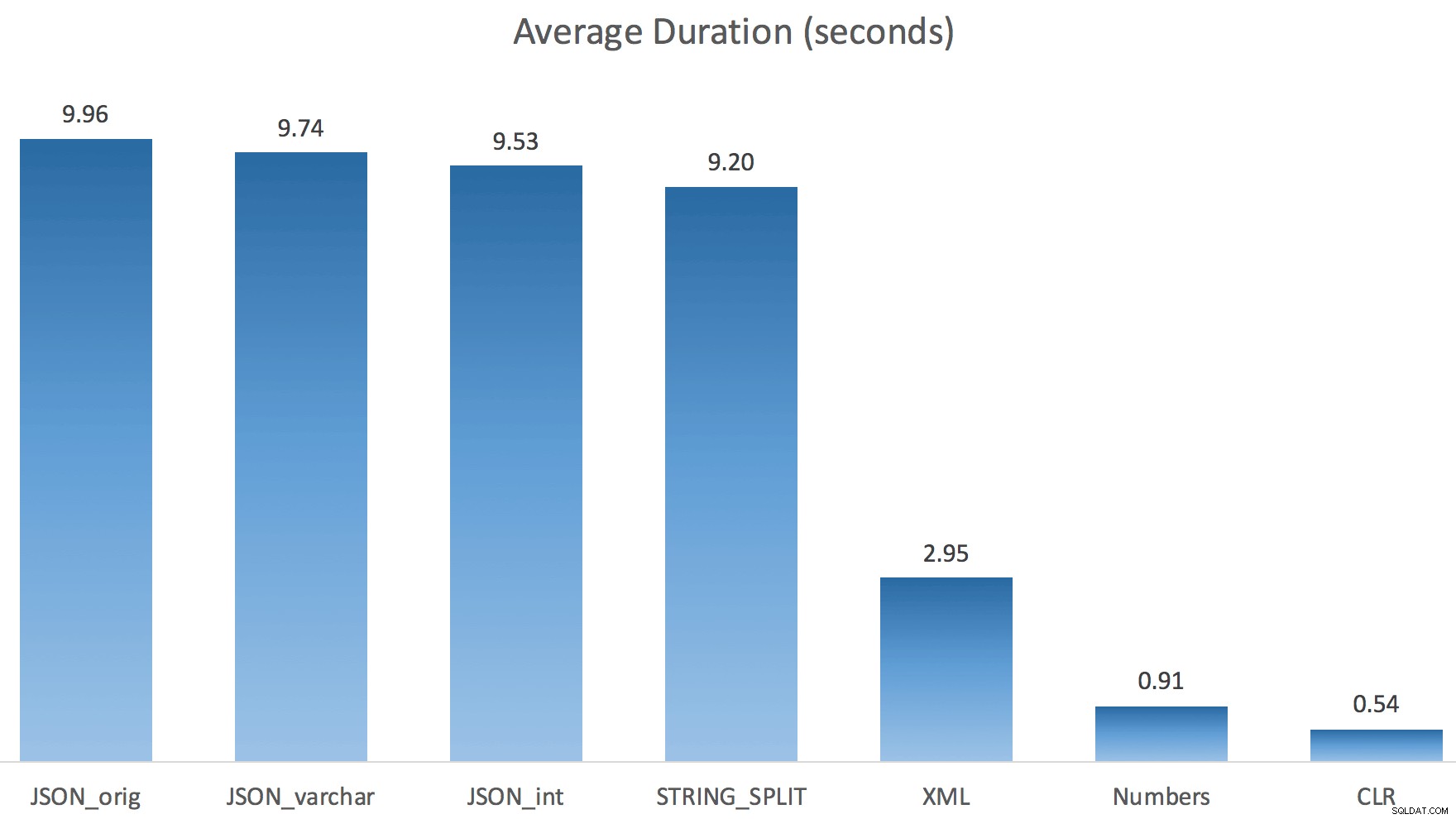
Jag körde bara varje test en gång (istället för en loop 100 gånger), eftersom jag inte ville krossa I/O på mitt system helt. Men efter att ha tagit i genomsnitt tre testkörningar hade Jonathan helt, 100% rätt. Här var varaktigheterna för att fylla en #temp-tabell med ~500 000 rader med varje metod:
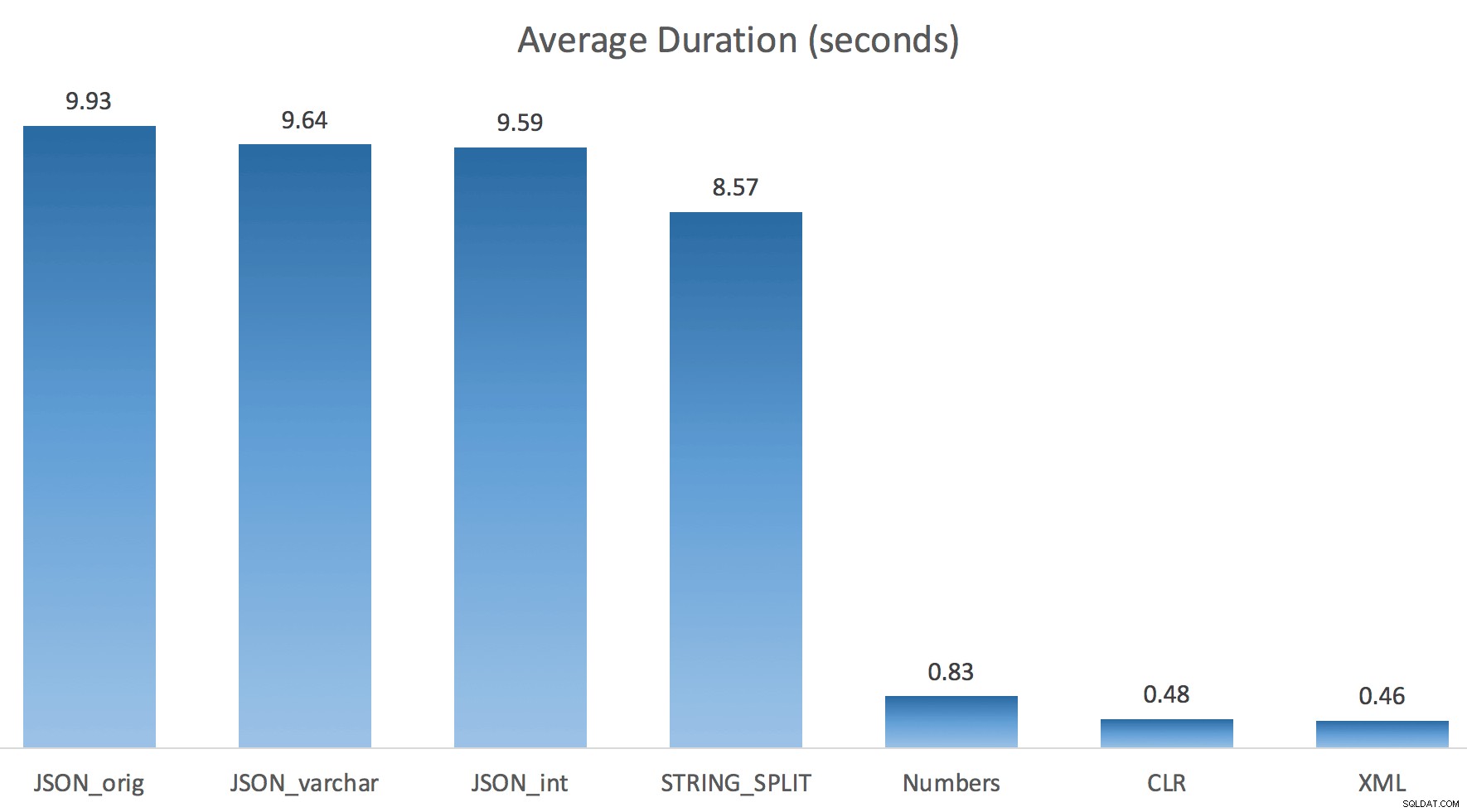
Så här, JSON och STRING_SPLIT metoderna tog cirka 10 sekunder vardera, medan taltabellen, CLR och XML-metoderna tog mindre än en sekund. Förvirrad undersökte jag väntan, och visst, de fyra metoderna till vänster ådrog sig betydande LATCH_EX väntar (cirka 25 sekunder) sågs inte i de andra tre, och det fanns inga andra betydande väntan att tala om.
Och eftersom spärrväntningarna var längre än den totala varaktigheten, gav det mig en ledtråd om att detta hade att göra med parallellism (denna speciella maskin har 4 kärnor). Så jag genererade testkod igen och ändrade bara en rad för att se vad som skulle hända utan parallellitet:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
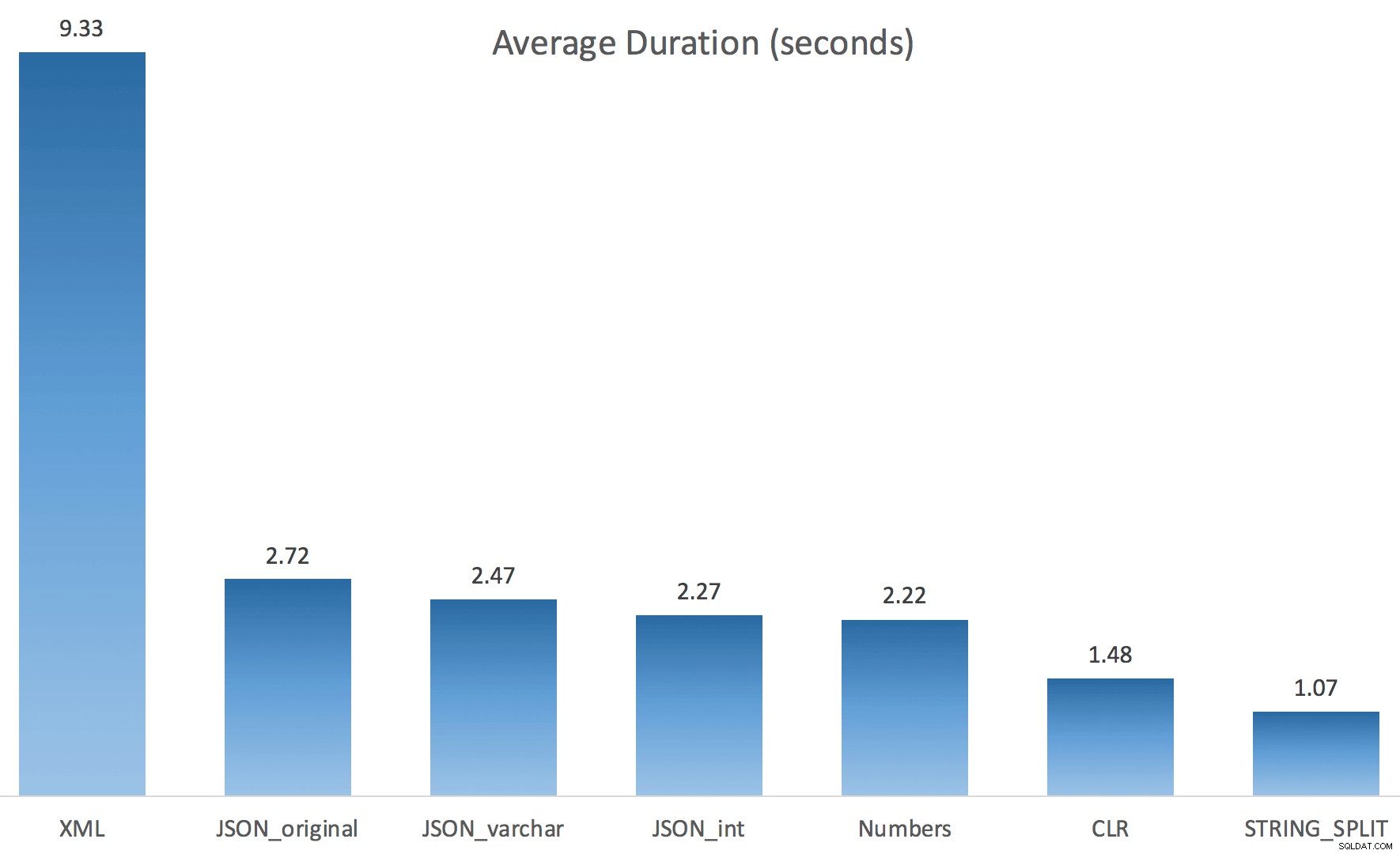
Nu STRING_SPLIT klarade sig mycket bättre (liksom JSON-metoderna), men ändå åtminstone dubbelt så lång tid som CLR tog:
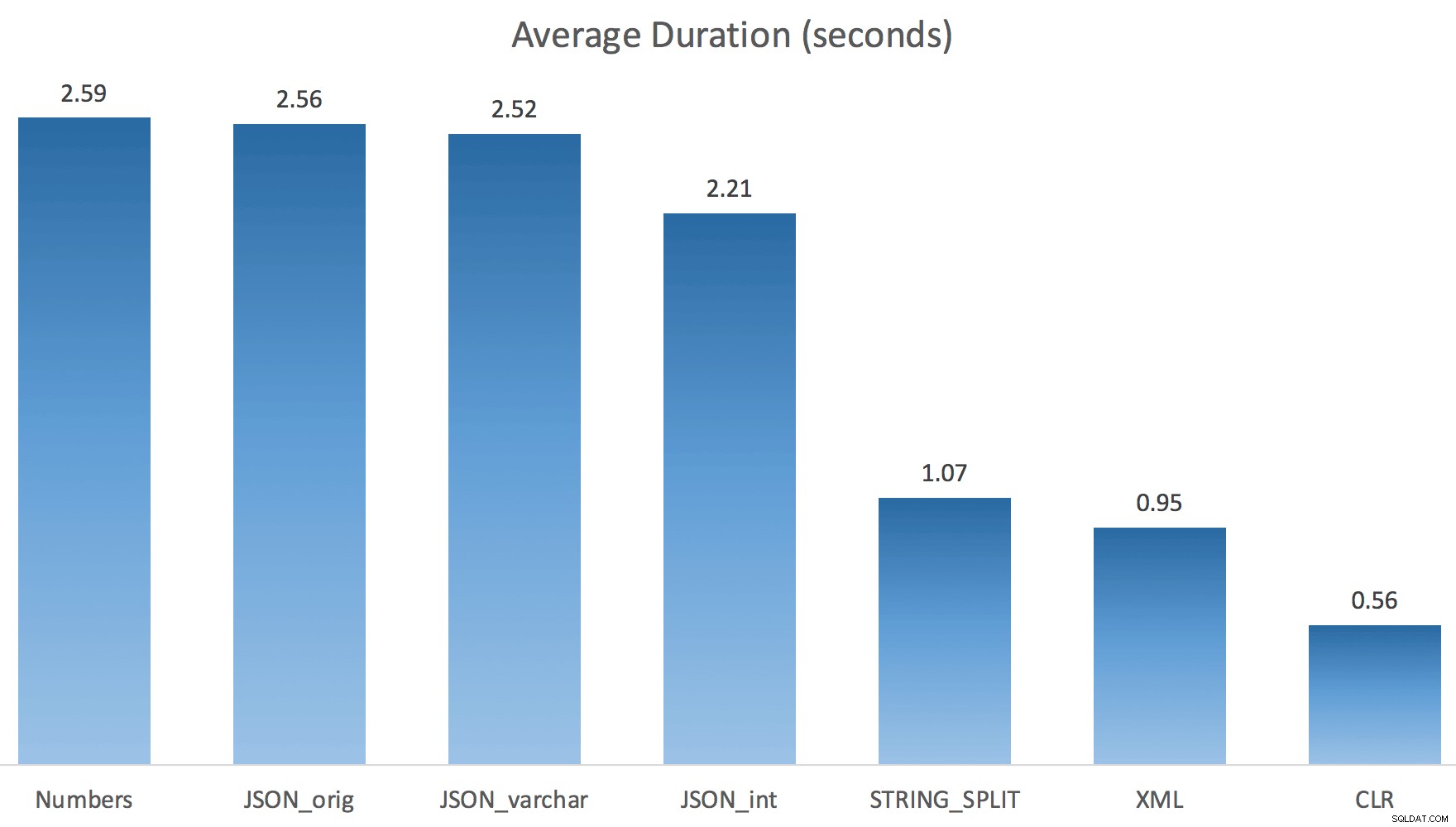
Så det kan finnas ett kvarstående problem med dessa nya metoder när parallellism är inblandat. Det var inte ett problem med tråddistribution (jag kontrollerade det), och CLR hade faktiskt sämre uppskattningar (100x faktiska jämfört med bara 5x för STRING_SPLIT ); bara något underliggande problem med att koordinera spärrarna mellan trådar antar jag. För nu kan det vara värt att använda MAXDOP 1 om du vet att du skriver resultatet på nya sidor.
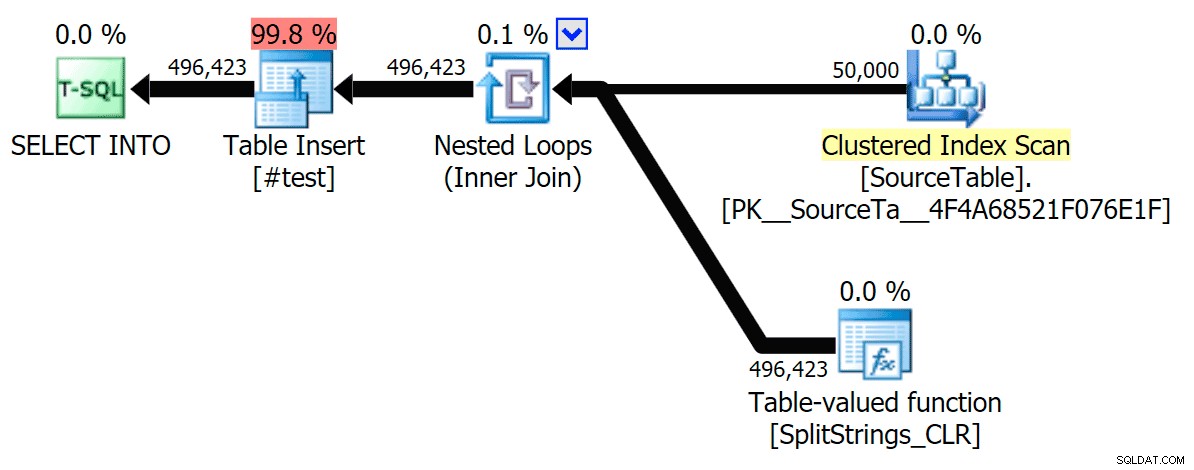
Jag har inkluderat de grafiska planerna som jämför CLR-metoden med den ursprungliga, för både parallell och seriell exekvering (jag har också laddat upp en Query Analysis-fil som du kan öppna upp i SQL Sentry Plan Explorer för att snoka runt på egen hand):
STRING_SPLIT
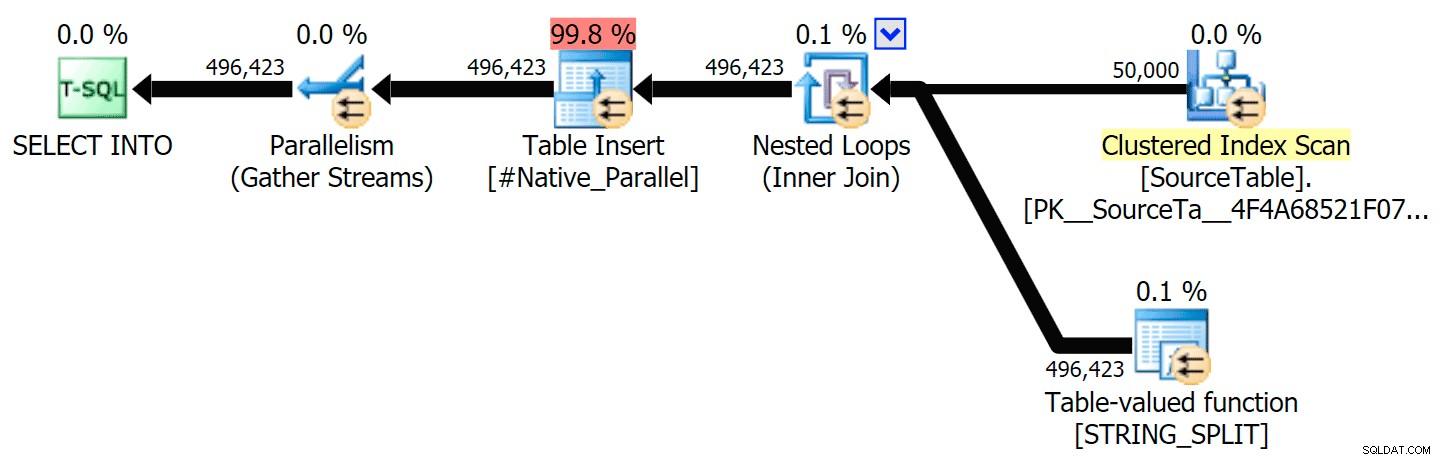
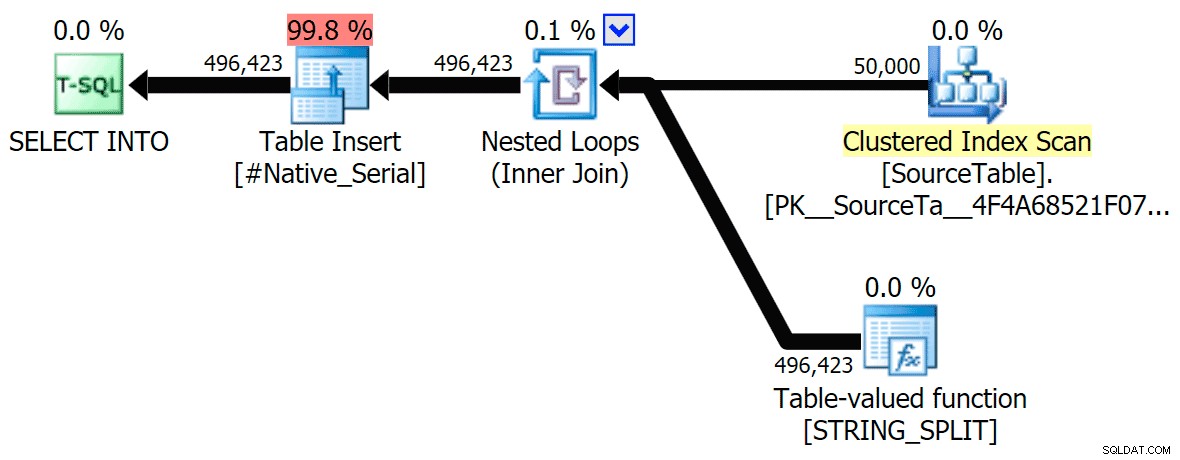
CLR
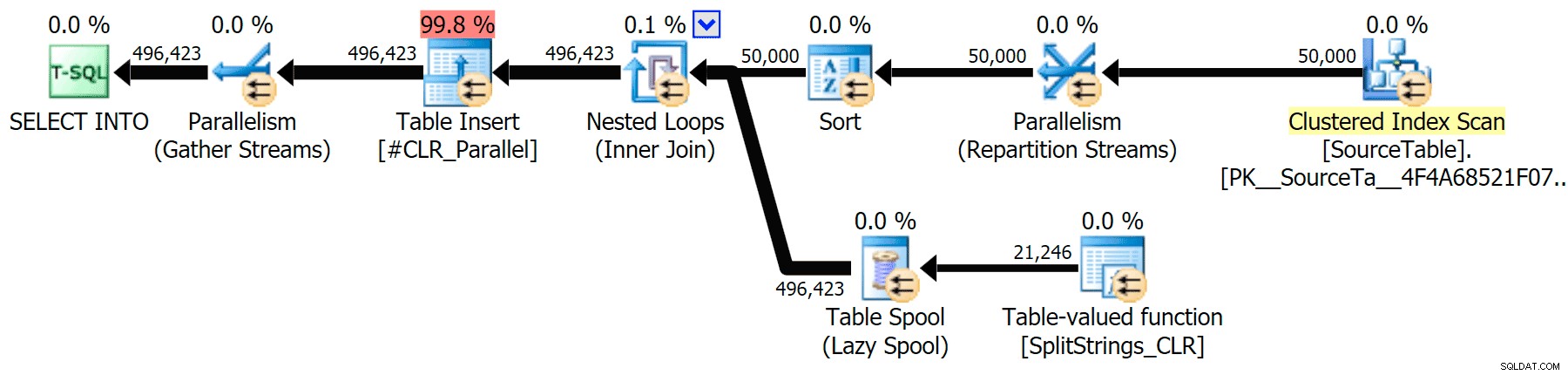
Sorteringsvarningen, FYI, var inget alltför chockerande och hade uppenbarligen inte mycket påtaglig effekt på frågans varaktighet:

- StringSplit.queryanalysis.zip (25 kb)
Spilar ut för sommaren
När jag tittade lite närmare på de planerna märkte jag att det i CLR-planen finns en latspole. Detta introduceras för att säkerställa att dubbletter bearbetas tillsammans (för att spara arbete genom att göra mindre faktisk delning), men den här spolen är inte alltid möjlig i alla planformer, och det kan ge lite av en fördel för de som kan använda den ( t.ex. CLR-planen), beroende på uppskattningar. För att jämföra utan spolar aktiverade jag spårningsflagga 8690 och körde testerna igen. Först, här är den parallella CLR-planen utan spolen:
Och här var de nya varaktigheterna för alla frågor som går parallellt med TF 8690 aktiverade:
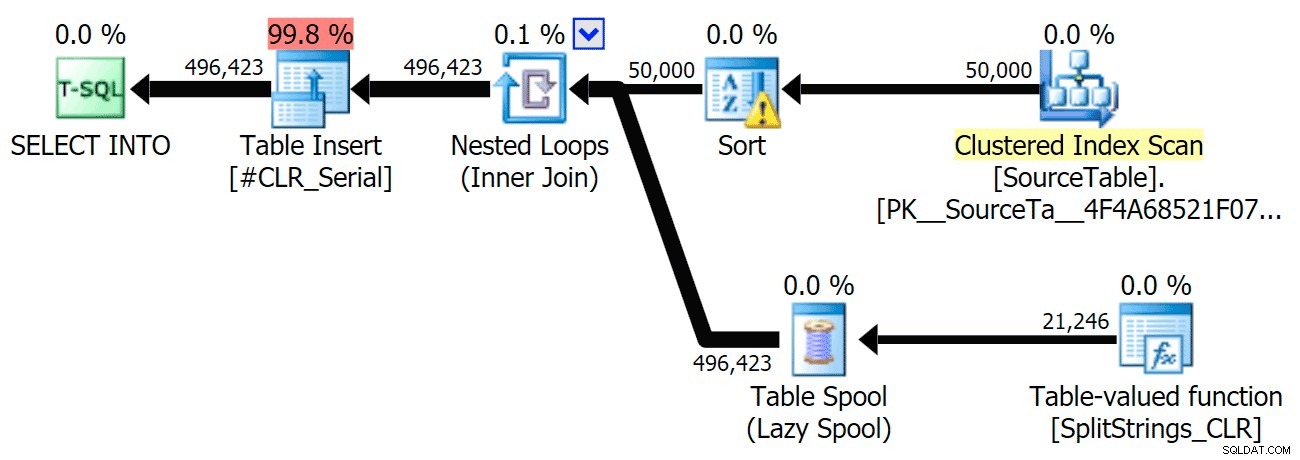
Nu, här är den seriella CLR-planen utan spolen:
Och här var timingresultaten för frågor som använder både TF 8690 och MAXDOP 1 :
(Observera att förutom XML-planen ändrades de flesta av de andra inte alls, med eller utan spårningsflaggan.)
Jämföra beräknat antal rader
Dan Holmes ställde följande fråga:
Hur uppskattar den datastorleken när den ansluts till en annan (eller flera) delad funktion? Länken nedan är en uppskrivning av en CLR-baserad delad implementering. Gör 2016 ett "bättre" jobb med datauppskattningar? (tyvärr har jag inte möjlighet att installera RC än).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Så jag svepte koden från Dans inlägg, ändrade den för att använda mina funktioner och körde den genom Plan Explorer:
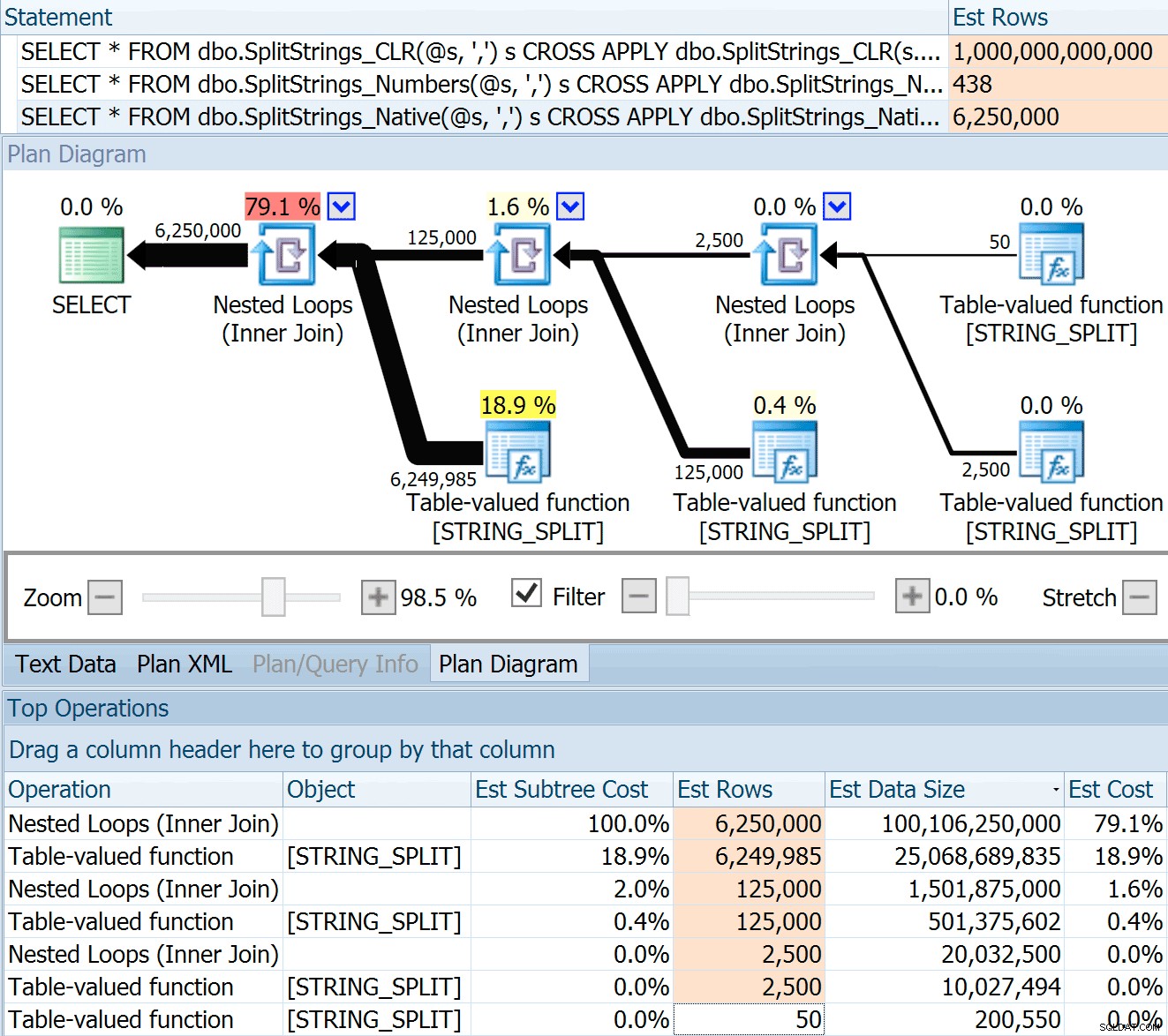
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
SPLIT_STRING tillvägagångssätt kommer förvisso med *bättre* uppskattningar än CLR, men fortfarande grovt över (i det här fallet, när strängen är tom; detta kanske inte alltid är fallet). Funktionen har en inbyggd standard som uppskattar att den inkommande strängen kommer att ha 50 element, så när du kapslar dem får du 50 x 50 (2 500); om du kapslar dem igen, 50 x 2 500 (125 000); och till sist, 50 x 125 000 (6 250 000):
Obs:OPENJSON() beter sig på exakt samma sätt som STRING_SPLIT – den förutsätter också att 50 rader kommer ut från en given delad operation. Jag tänker att det kan vara användbart att ha ett sätt att antyda kardinalitet för funktioner som denna, förutom att spåra flaggor som 4137 (före 2014), 9471 &9472 (2014+), och naturligtvis 9481...
Denna uppskattning på 6,25 miljoner rader är inte bra, men den är mycket bättre än CLR-metoden som Dan talade om, som uppskattar EN TRILLION RADER , och jag tappade räkningen av kommatecken för att bestämma datastorleken – 16 petabyte? exabyte?
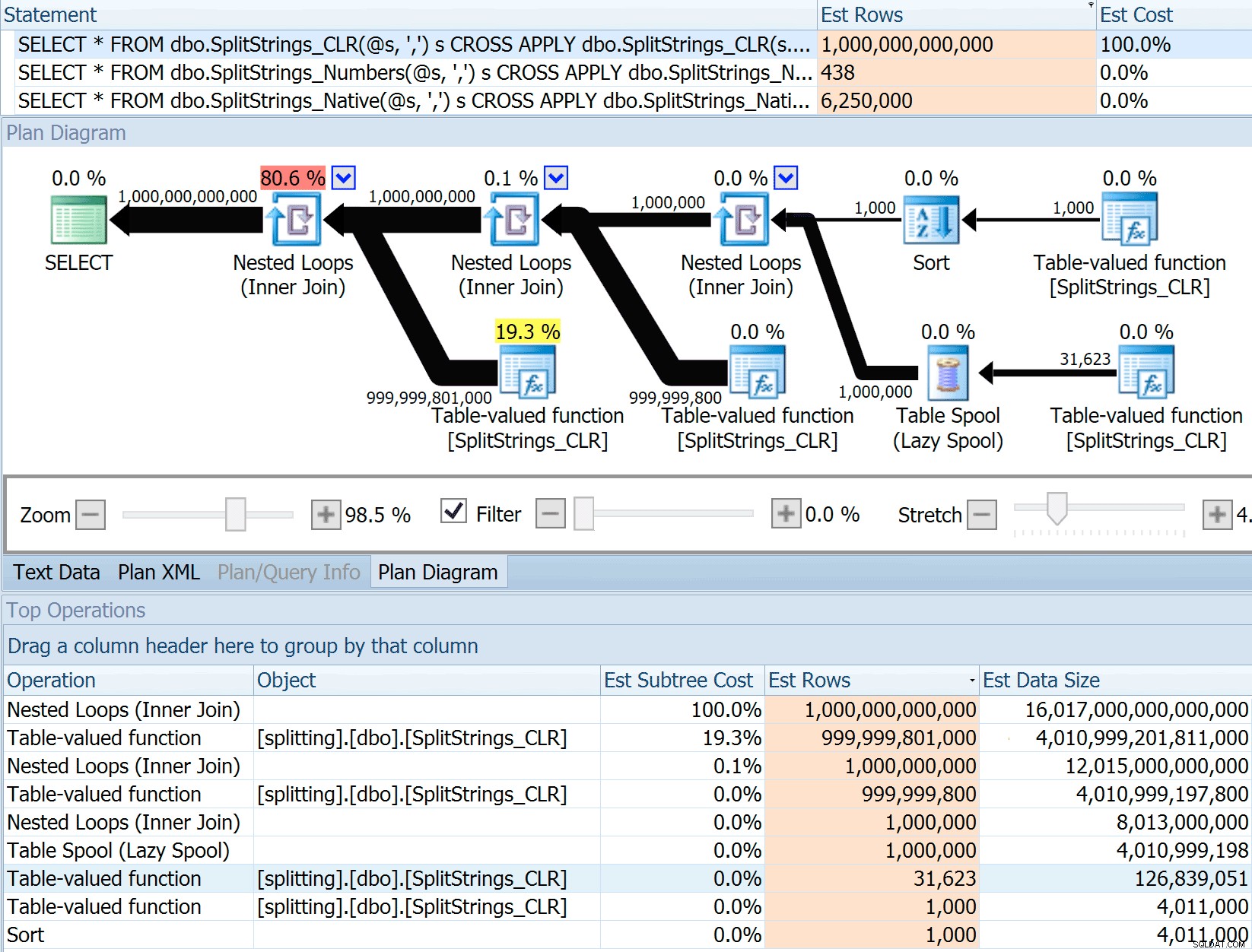
Vissa av de andra tillvägagångssätten klarar sig uppenbarligen bättre när det gäller uppskattningar. Tabellen Numbers uppskattade till exempel ett mycket mer rimligt antal 438 rader (i SQL Server 2016 RC2). Var kommer detta nummer ifrån? Tja, det finns 8 000 rader i tabellen, och om du kommer ihåg har funktionen både ett likhets- och ett olikhetspredikat:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Så, SQL Server multiplicerar antalet rader i tabellen med 10 % (som en gissning) för likhetsfiltret, sedan kvadratroten på 30 % (igen, en gissning) för ojämlikhetsfiltret. Kvadratroten beror på exponentiell backoff, vilket Paul White förklarar här. Detta ger oss:
8000 * 0,1 * SQRT(0,3) =438,178XML-variationen uppskattade lite över en miljard rader (på grund av en tabellspole som uppskattades exekveras 5,8 miljoner gånger), men dess plan var alldeles för komplex för att försöka illustrera här. Kom i alla fall ihåg att uppskattningar uppenbarligen inte berättar hela historien – bara för att en fråga har mer exakta uppskattningar betyder det inte att den kommer att prestera bättre.
Det fanns några andra sätt jag kunde justera uppskattningarna lite:nämligen att tvinga fram den gamla kardinalitetsuppskattningsmodellen (som påverkade både XML- och Numbers-tabellvarianterna), och använda TF:erna 9471 och 9472 (som endast påverkade Numbers-tabellvarianten, eftersom de kontrollerar båda kardinalitet kring flera predikat). Här var sätten jag kunde ändra uppskattningarna bara lite (eller MYCKET). , vid återgång till den gamla CE-modellen):

Den gamla CE-modellen sänkte XML-uppskattningarna med en storleksordning, men för Numbers-tabellen sprängde den fullständigt. Predikatflaggorna ändrade uppskattningarna för tabellen Numbers, men dessa ändringar är mycket mindre intressanta.
Ingen av dessa spårningsflaggor hade någon effekt på uppskattningarna för CLR, JSON eller STRING_SPLIT variationer.
Slutsats
Så vad lärde jag mig här? Ett helt gäng, faktiskt:
- Parallellism kan hjälpa i vissa fall, men när det inte hjälper är det verkligen hjälper inte. JSON-metoderna var ~5 gånger snabbare utan parallellitet och
STRING_SPLITvar nästan 10 gånger snabbare. - Spolen hjälpte faktiskt CLR-metoden att prestera bättre i det här fallet, men TF 8690 kan vara användbar att experimentera med i andra fall där du ser spolar och försöker förbättra prestandan. Jag är säker på att det finns situationer där eliminering av spolen kommer att bli bättre totalt sett.
- Att eliminera spolen skadade verkligen XML-metoden (men bara drastiskt när den tvingades vara entrådig).
- Många roliga saker kan hända med uppskattningar beroende på tillvägagångssätt, tillsammans med vanliga statistik-, distributions- och spårningsflaggor. Tja, jag antar att jag redan visste det, men det finns definitivt ett par bra, konkreta exempel här.
Tack till de som ställde frågor eller uppmanade mig att inkludera mer information. Och som du kanske har gissat från titeln tar jag upp ytterligare en fråga i en andra uppföljning, den här om TVP:er:
- STRING_SPLIT() i SQL Server 2016:Uppföljning #2