Tidigare i veckan lade jag upp en uppföljning av mitt senaste inlägg om STRING_SPLIT() i SQL Server 2016, med flera kommentarer som lämnats på inlägget och/eller skickats till mig direkt:
STRING_SPLIT()i SQL Server 2016 :Uppföljning #1
Efter att det inlägget mestadels skrevs kom det en sen fråga från Doug Ellner:
Hur jämför dessa funktioner med tabellvärderade parametrar?
Nu fanns det redan på min lista över framtida projekt att testa TVP, efter ett nyligen twitterutbyte med @Nick_Craver på Stack Overflow. Han sa att de var glada över att STRING_SPLIT() presterade bra, eftersom de var missnöjda med prestandan att skicka ~7 000 värden in genom en tabellvärderad parameter.
Mina tester
För dessa tester använde jag SQL Server 2016 RC3 (13.0.1400.361) på en 8-kärnig Windows 10 VM, med PCIe-lagring och 32 GB RAM.
Jag skapade en enkel tabell som efterliknade vad de gjorde (väljde cirka 10 000 värden från en tabell över 3+ miljoner radposter), men för mina tester har den mycket färre kolumner och färre index:
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FRÅN sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Jag skapade också en In-Memory-version, eftersom jag var nyfiken på om något tillvägagångssätt skulle fungera annorlunda där:
SKAPA TABELL dbo.Posts_InMemory( PostID int PRIMÄRNYCKEL INKLUSTERAD HASH MED (BUCKET_COUNT =4000000), HitCount int INTE NULL DEFAULT 0) MED (MEMORY_OPTIMIZED =PÅ);
Nu ville jag skapa en C#-app som skulle skicka in 10 000 unika värden, antingen som en kommaseparerad sträng (byggd med en StringBuilder) eller som en TVP (som skickas från en DataTable). Poängen skulle vara att hämta eller uppdatera ett urval av rader baserat på en matchning, antingen till ett element som skapats genom att dela listan, eller ett explicit värde i en TVP. Så koden skrevs för att lägga till vart 300:e värde till strängen eller DataTable (C#-koden finns i en bilaga nedan). Jag tog funktionerna jag skapade i det ursprungliga inlägget, ändrade dem för att hantera varchar(max) , och lade sedan till två funktioner som accepterade en TVP – en av dem minnesoptimerad. Här är tabelltyperna (funktionerna finns i bilagan nedan):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE( PostID int NOT NULL PRIMÄRNYCKEL INKLUSTERAD HASH WITH (BUCKET_COUNT =0ME)0MÅN_0TION; /pre>Jag var också tvungen att göra Numbers-tabellen större för att kunna hantera strängar> 8K och med> 8K element (jag gjorde den till 1MM rader). Sedan skapade jag sju lagrade procedurer:fem av dem tog en
varchar(max)och gå med funktionsutgången för att uppdatera bastabellen, och sedan två för att acceptera TVP och ansluta direkt mot det. C#-koden anropar var och en av dessa sju procedurer, med listan med 10 000 inlägg att välja eller uppdatera, 1 000 gånger. Dessa procedurer finns också i bilagan nedan. Så bara för att sammanfatta, metoderna som testas är:
- Native (
STRING_SPLIT()) - XML
- CLR
- Siffertabell
- JSON (med explicit
intutdata) - Tabellvärderad parameter
- Minnesoptimerad tabellvärderad parameter
Vi kommer att testa att hämta de 10 000 värdena, 1 000 gånger, med hjälp av en DataReader – men inte iterera över DataReader, eftersom det bara skulle göra att testet tar längre tid och skulle vara lika mycket arbete för C#-applikationen oavsett hur databasen är producerade uppsättningen. Vi kommer också att testa att uppdatera de 10 000 raderna, 1 000 gånger vardera, med ExecuteNonQuery() . Och vi kommer att testa mot både de vanliga och minnesoptimerade versionerna av tabellen Posts, som vi kan byta mycket enkelt utan att behöva ändra någon av funktionerna eller procedurerna, med hjälp av en synonym:
SKAPA SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- för att testa en minnesoptimerad version:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- för att testa den diskbaserade versionen igen:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Jag startade programmet, körde det flera gånger för varje kombination för att säkerställa att kompilering, cachning och andra faktorer inte var orättvisa mot partiet som kördes först, och analyserade sedan resultaten från loggningstabellen (jag kollade också sys. dm_exec_procedure_stats för att säkerställa att ingen av tillvägagångssätten hade betydande applikationsbaserad overhead, och det hade de inte).
Resultat – Diskbaserade tabeller
Jag kämpar med datavisualisering ibland – jag försökte verkligen komma på ett sätt att representera dessa mätvärden på ett enda diagram, men jag tror att det bara fanns alldeles för många datapunkter för att få de framträdande att sticka ut.
Du kan klicka för att förstora någon av dessa i en ny flik/fönster, men även om du har ett litet fönster försökte jag göra vinnaren tydlig genom att använda färg (och vinnaren var densamma i alla fall). Och för att vara tydlig, med "Genomsnittlig varaktighet" menar jag den genomsnittliga tid det tog för applikationen att slutföra en loop med 1 000 operationer.
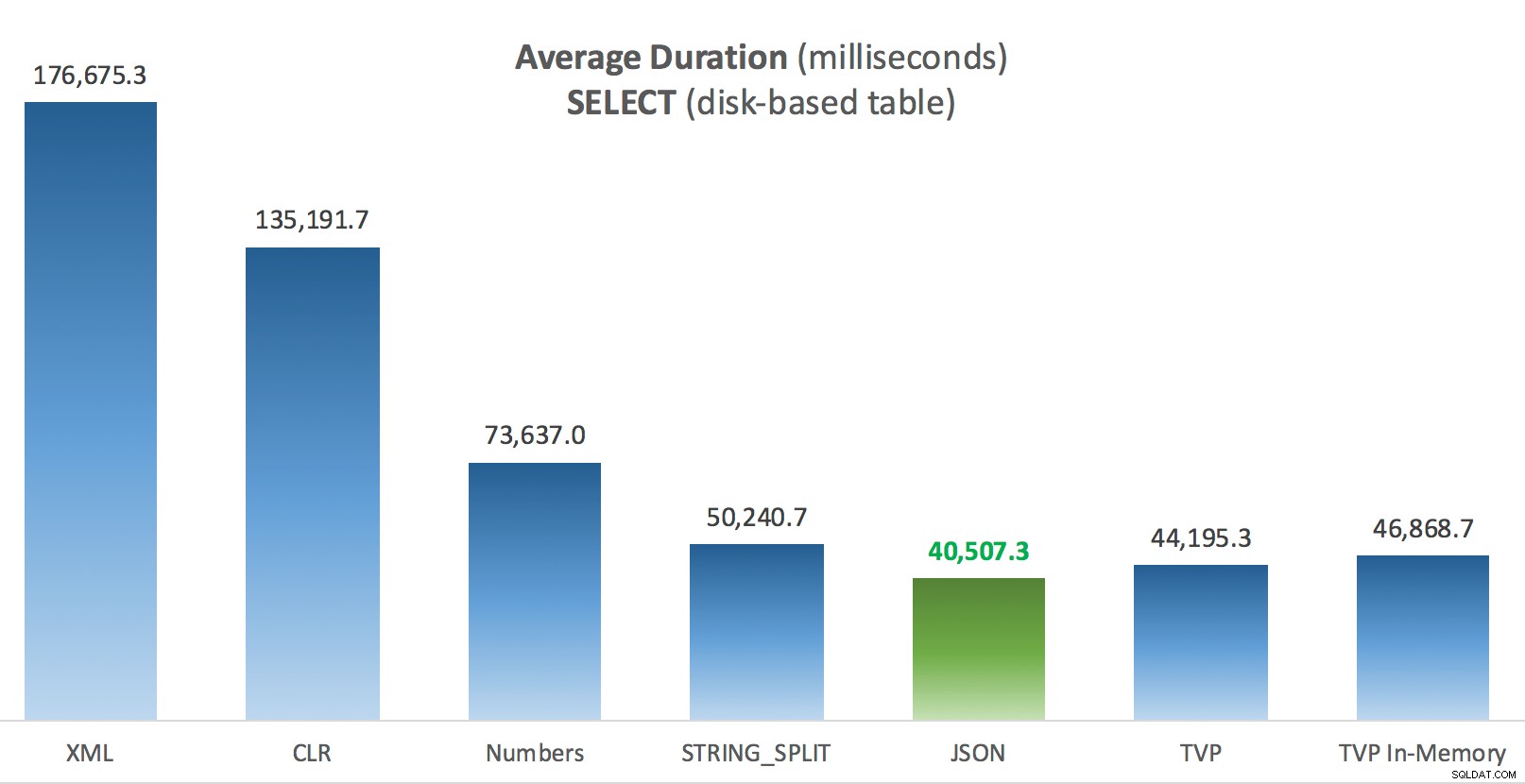 Genomsnittlig varaktighet (millisekunder) för SELECTs mot diskbaserad inläggstabell
Genomsnittlig varaktighet (millisekunder) för SELECTs mot diskbaserad inläggstabell
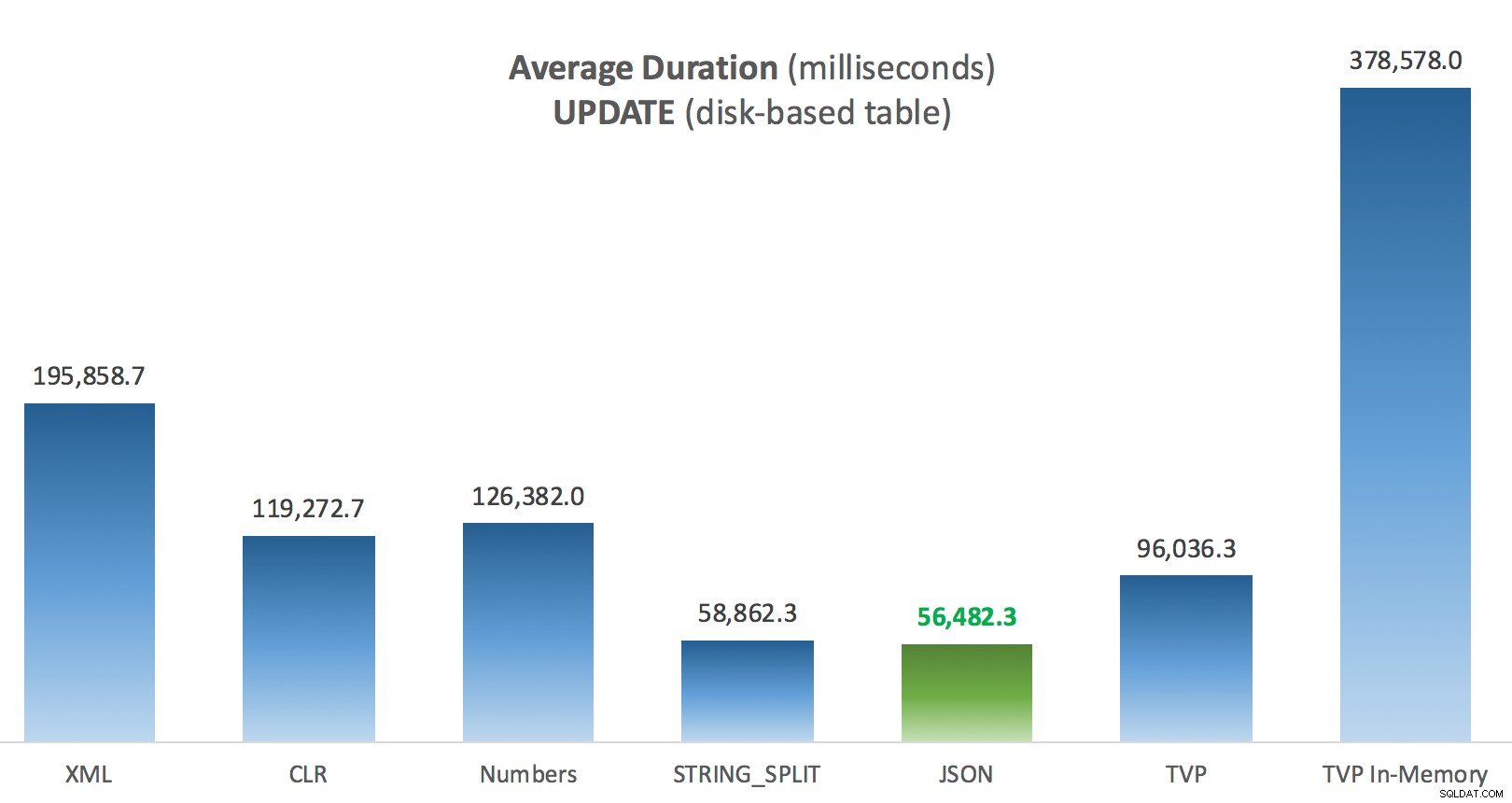 Genomsnittlig varaktighet (millisekunder) för UPPDATERINGAR mot diskbaserad inläggstabell
Genomsnittlig varaktighet (millisekunder) för UPPDATERINGAR mot diskbaserad inläggstabell
Det mest intressanta här, för mig, är hur dåligt den minnesoptimerade TVP:n gjorde när den hjälpte till med en UPDATE . Det visar sig att parallella skanningar för närvarande blockeras för aggressivt när DML är inblandat; Microsoft har erkänt detta som en funktionslucka, och de hoppas kunna åtgärda det snart. Observera att parallell skanning för närvarande är möjlig med SELECT men det är blockerat för DML just nu. (Det kommer inte att lösas i SQL Server 2014, eftersom dessa specifika parallella skanningsoperationer inte är tillgängliga där för någon operation.) När det är åtgärdat, eller när dina TVP:er är mindre och/eller parallellism inte är fördelaktigt ändå, bör du se att minnesoptimerade TVP:er kommer att prestera bättre (mönstret fungerar helt enkelt inte bra för just detta användningsfall av relativt stora TVP).
För detta specifika fall, här är planerna för SELECT (som jag kunde tvinga att gå parallellt) och UPDATE (vilket jag inte kunde):
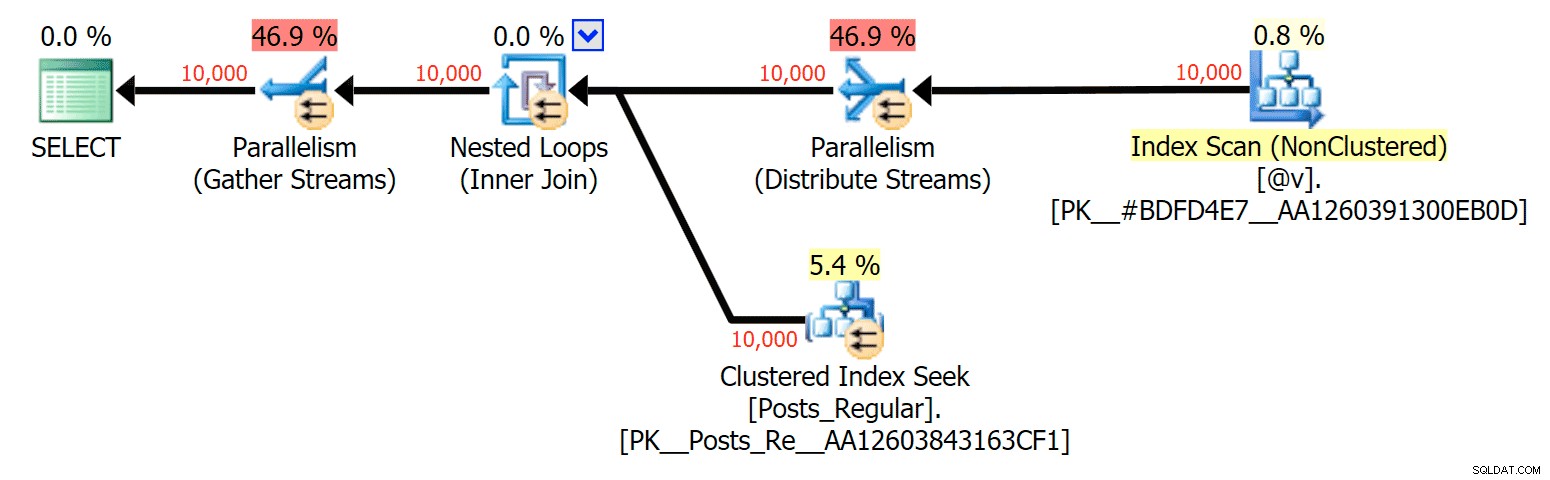 Parallellism i en SELECT-plan som förenar en diskbaserad tabell med en TVP i minnet
Parallellism i en SELECT-plan som förenar en diskbaserad tabell med en TVP i minnet
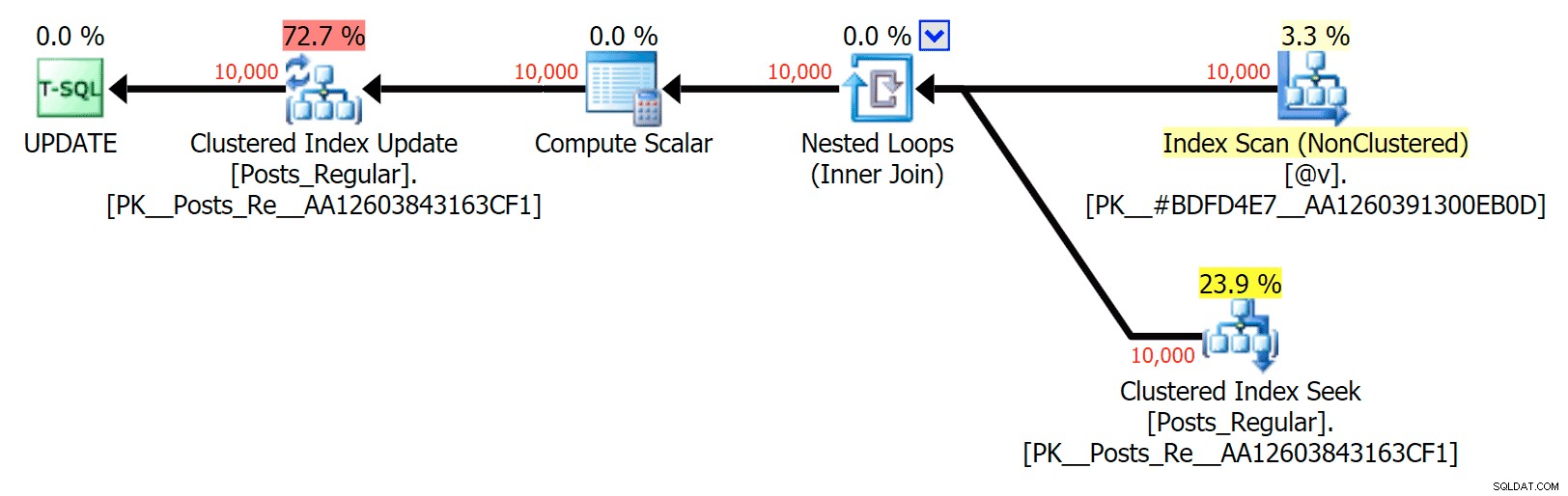 Ingen parallellitet i en UPPDATERINGsplan som kopplar en diskbaserad tabell till ett minne TVP
Ingen parallellitet i en UPPDATERINGsplan som kopplar en diskbaserad tabell till ett minne TVP
Resultat – minnesoptimerade tabeller
Lite mer konsekvens här – de fyra metoderna till höger är relativt jämna, medan de tre till vänster däremot verkar väldigt oönskade. Var också särskilt uppmärksam på absolut skala jämfört med de diskbaserade tabellerna – för det mesta, med samma metoder, och även utan parallellitet, slutar du med mycket snabbare operationer mot minnesoptimerade tabeller, vilket leder till lägre total CPU-användning.
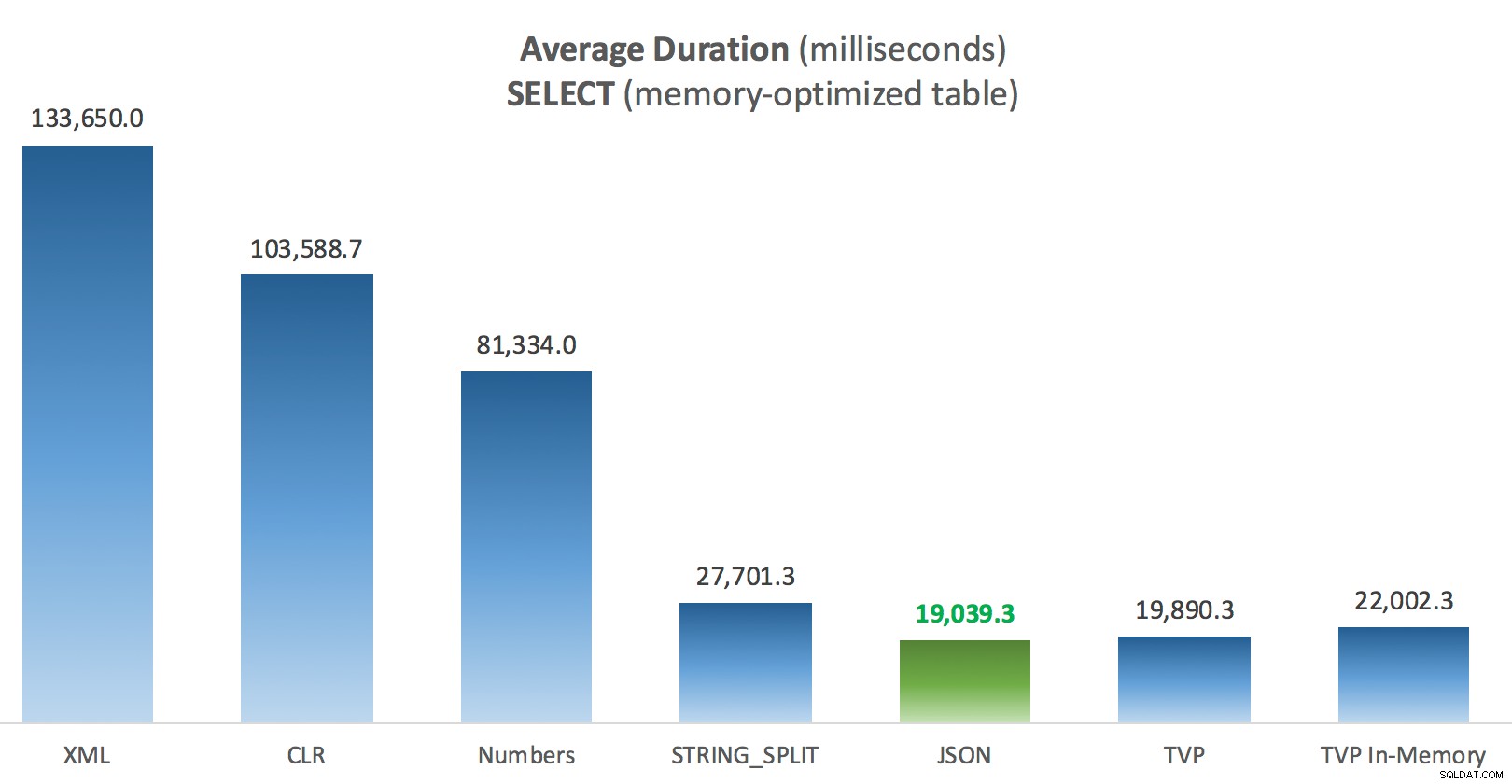 Genomsnittlig varaktighet (millisekunder) för SELECTs mot minnesoptimerad posttabell
Genomsnittlig varaktighet (millisekunder) för SELECTs mot minnesoptimerad posttabell
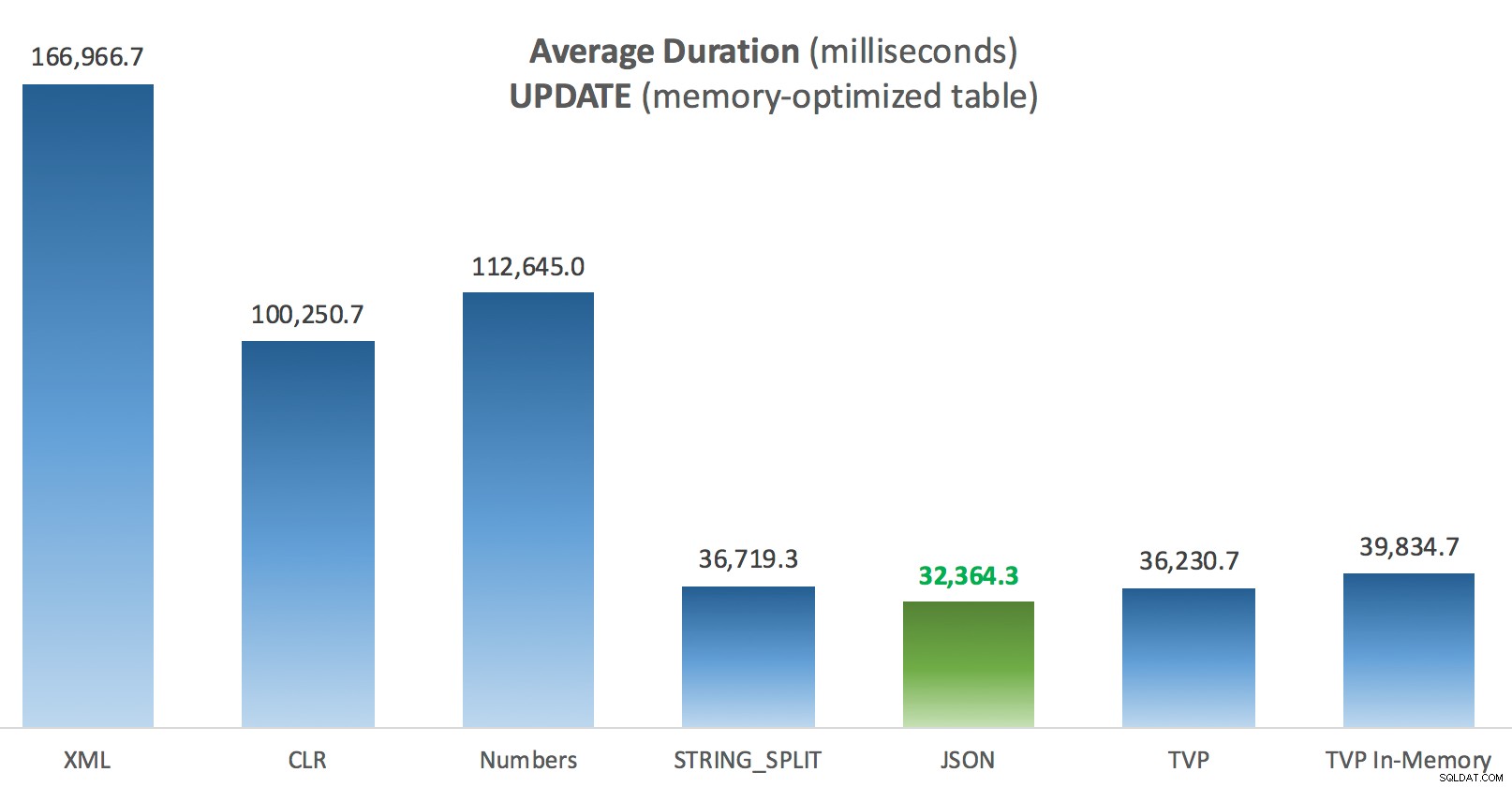 Genomsnittlig varaktighet (millisekunder) för UPPDATERINGAR mot minnesoptimerad inläggstabell
Genomsnittlig varaktighet (millisekunder) för UPPDATERINGAR mot minnesoptimerad inläggstabell
Slutsats
För detta specifika test, med en specifik datastorlek, distribution och antal parametrar, och på min speciella hårdvara, var JSON en konsekvent vinnare (men marginellt). För några av de andra testerna i tidigare inlägg klarade sig andra tillvägagångssätt bättre. Bara ett exempel på hur det du gör och var du gör det kan ha en dramatisk inverkan på den relativa effektiviteten av olika tekniker, här är de saker jag har testat i den här korta serien, med min sammanfattning av vilken teknik som ska använda i det fallet, och som ska användas som ett andra eller tredje val (till exempel om du inte kan implementera CLR på grund av företagets policy eller för att du använder Azure SQL Database, eller om du inte kan använda JSON eller STRING_SPLIT() eftersom du inte är på SQL Server 2016 ännu). Observera att jag inte gick tillbaka och testade om variabeltilldelningen och SELECT INTO skript med TVP:er – dessa tester sattes upp förutsatt att du redan hade befintliga data i CSV-format som ändå måste delas upp först. Generellt, om du kan undvika det, smutsa inte in dina set till kommaseparerade strängar i första hand, IMHO.
| Mål | Första val | Andra val (och 3:a, där så är lämpligt) |
|---|---|---|
| Enkel variabeltilldelning | STRING_SPLIT() | CLR om <2016 XML om ingen CLR och <2016 |
| VÄLJ IN | CLR | XML om ingen CLR |
| VÄLJ IN (ingen spole) | CLR | Siffertabell om ingen CLR |
| VÄLJ IN (ingen spole + MAXDOP 1) | STRING_SPLIT() | CLR if <2016 Siffertabell om ingen CLR och <2016 |
| VÄLJ ansluter till stor lista (diskbaserad) | JSON (int) | TVP om <2016 |
| VÄLJ ansluter till stor lista (minnesoptimerad) | JSON (int) | TVP om <2016 |
| UPPDATERA ansluter till stor lista (diskbaserad) | JSON (int) | TVP om <2016 |
| UPPDATERA går med i stor lista (minnesoptimerad) | JSON (int) | TVP om <2016 |
För Dougs specifika fråga:JSON, STRING_SPLIT() , och TVP:er presterade ganska lika över dessa tester i genomsnitt – tillräckligt nära för att TVP:er är det självklara valet om du inte använder SQL Server 2016. Om du har olika användningsfall kan dessa resultat skilja sig åt. Jättebra .
Vilket för oss till moralen i det här story:Jag och andra kan utföra mycket specifika prestandatester, som kretsar kring vilken funktion eller tillvägagångssätt som helst, och kommer till en slutsats om vilket tillvägagångssätt som är snabbast. Men det finns så många variabler, jag kommer aldrig att ha förtroende att säga "den här metoden är alltid den snabbaste." I det här scenariot försökte jag mycket hårt att kontrollera de flesta bidragande faktorerna, och även om JSON vann i alla fyra fallen kan du se hur de olika faktorerna påverkade körtiderna (och drastiskt så för vissa tillvägagångssätt). Så det är alltid värt det att konstruera dina egna tester, och jag hoppas att jag har hjälpt till att illustrera hur jag går tillväga för sådant.
Bilaga A:Konsolapplikationskod
Snälla, inget nit-picking om den här koden; det sammanställdes bokstavligen som ett mycket enkelt sätt att köra dessa lagrade procedurer 1 000 gånger med sanna listor och DataTables sammansatta i C#, och att logga tiden varje slinga tog till en tabell (för att vara säker på att inkludera eventuella applikationsrelaterade overhead med hanteringen antingen ett stort snöre eller en samling). Jag skulle kunna lägga till felhantering, loop annorlunda (t.ex. konstruera listorna inuti loopen istället för att återanvända en enda arbetsenhet) och så vidare.
using System;using System.Text;using System.Configuration;using System.Data;using System.Data.SqlClient; namespace SplitTesting{ class Program { static void Main(string[] args) { string operation ="Update"; if (args[0].ToString() =="-Select") { operation ="Select"; } var csv =new StringBuilder(); DataTable-element =new DataTable(); elements.Columns.Add("värde", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10 000) { csv.Append(","); } elements.Rows.Add(i*300); } string[] methods ={ "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" }; using (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primär"].ToString(); con.Open(); SqlParameter p; foreach (strängmetod i metoder) { SqlCommand cmd =new SqlCommand("dbo." + operation + "Posts_" + metod, con); cmd.CommandType =CommandType.StoredProcedure; if (metod =="TVP" || metod =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =elements; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operation =="Uppdatera") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Stäng(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds; // loggtid - loggningsproceduren lägger till klocktid och // registrerar minne/diskbaserat (bestäms via synonym) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value =operation; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value =metod; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(metod + " :" + this_time.ToString()); } } } }} Exempel på användning:
SplitTesting.exe -VäljSplitTesting.exe -Uppdatera
Bilaga B:Funktioner, procedurer och loggningstabell
Här var funktionerna redigerade för att stödja varchar(max) (CLR-funktionen har redan accepterats nvarchar(max) och jag var fortfarande ovillig att försöka ändra det):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))RETURNER TABELL MED SCHEMABINDINGAS RETURN (VÄLJ [värde] FRÅN STRING_SPLIT(@List, @Delimiter));GO CREATE FUNCTION dbo.SplitStrings ( @List varchar(max), @Delimiter char(1))RETURNERAR TABELL MED SCHEMABINDINGAS RETURN (VÄLJ [värde] =y.i.value('(./text())[1]', 'varchar(max)') FRÅN (SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) SOM en CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNERAR TABELL MED SCHEMABINDINGAS RETURN (VÄLJ [värde] =SUBSTRING (@List, Number, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) FROM dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter );GO CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))RETURNERAR TABELL MED SCH EMABINDINGAS RETURN (VÄLJ [värde] FRÅN OPENJSON(CHAR(91) + @List + CHAR(93)) MED (värde int '$'));GO Och de lagrade procedurerna såg ut så här:
SKAPA PROCEDUR dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPPDATERING p SET HitCount +=1 FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s. [value];ENDGOCREATE PROCEDUR dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s.[värde];ENDGO-- upprepa för de 4 andra varchar(max)-baserade metoderna SKAPA PROCEDUR dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- byt _Regular till _InMemoryASBEGIN SET NOCOUNT ON; UPPDATERA p SET HitCount +=1 FRÅN dbo.Inlägg SOM p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- BEGIN InSETNOCOUNT ASON; VÄLJ p.PostID, p.HitCount FRÅN dbo.Inlägg SOM p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- upprepa för in-memory
Och slutligen, loggningstabellen och proceduren:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMÄRNYCKEL, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory eller Posts_Regular Operation varchar(32) NOT NULL 'Uppdatera', -- eller välj Metod varchar(32) NOT NULL DEFAULT 'Native', -- eller TVP, JSON, etc. Timing int NOT NULL DEFAULT 0);GO CREATE PROCEDUR dbo.LogBatchTime @Operation varchar(32), @Method varchar(32), @Timing intASBEGIN STÄLL IN NOCOUNT ON; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- och frågan för att generera graferna:;WITH x AS( SELECT OperatingTable, Operation, Method, Timing, Recency =ROW_NUMBER() OVER (PARTITION BY OperatingTable, Operation, Method ORDER BY ClockTime DESC) FROM dbo.SplitLog)SELECT OperatingTable, Operation, Method, AverageDuration =AVTiming(1,0*Timing) FROM x WHERE Senaste <=3GROUP BY OperatingTable,Operation,Method;