Vad får korsapplikationsfrågan att fungera så dåligt på detta enkla XML-dokument och prestera exponentiellt långsammare när datasetet växer?
Det är användningen av den överordnade axeln för att hämta attribut-ID från artikelnoden.
Det är den här delen av frågeplanen som är problematisk.

Lägg märke till de 423 raderna som kommer ut från den lägre tabellvärderade funktionen.
Att bara lägga till ytterligare en objektnod med tre fältnoder ger dig detta.
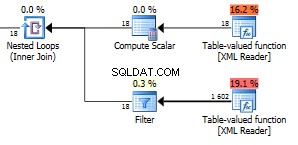
732 rader returnerade.
Vad händer om vi fördubblar noderna från den första frågan till totalt 6 objektnoder?
Vi är uppe i en jättestor 1602 rad returnerade.
Siffran 18 i toppfunktionen är alla fältnoder i din XML. Vi har här 6 artiklar med tre fält i varje objekt. De 18 noderna används i en kapslad loop förenas mot den andra funktionen så 18 exekveringar som returnerar 1602 rader ger att den returnerar 89 rader per iteration. Det råkar bara vara det exakta antalet noder i hela XML. Det är faktiskt en mer än alla synliga noder. Jag vet inte varför. Du kan använda den här frågan för att kontrollera det totala antalet noder i din XML.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Så algoritmen som används av SQL Server för att få värdet när du använder den överordnade axeln .. i en värdefunktion är att den först hittar alla noder du fragmenterar på, 18 i det sista fallet. För var och en av dessa noder strimlar den och returnerar hela XML-dokumentet och kontrollerar i filteroperatorn för den nod du faktiskt vill ha. Där har du din exponentiella tillväxt. Istället för att använda den överordnade axeln bör du använda ett extra kryss. Strimla först på föremål och sedan på fält.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Jag ändrade också hur du kommer åt textvärdet i fältet. Använder . kommer att få SQL Server att leta efter underordnade noder till field och sammanfoga dessa värden i resultatet. Du har inga underordnade värden så resultatet är detsamma men det är bra att undvika att ha den delen i frågeplanen (UDX-operatören).
Frågeplanen har inte problemet med den överordnade axeln om du använder ett XML-index, men du kommer fortfarande att dra nytta av att ändra hur du hämtar fältvärdet.