Introduktion till SQL Server-index
Microsoft SQL Server anses vara ett av relationsdatabashanteringssystemen (RDBMS ), där data är logiskt organiserade i rader och kolumner som lagras i databehållare som kallas tabeller. Fysiskt lagras tabellerna som 8 KB sidor som kan organiseras i Heap- eller B-Tree Clustered-tabeller. I högen tabell, finns det ingen sorteringsordning som styr ordningen för data inuti datasidorna och sekvensen av sidor i den tabellen, eftersom det inte finns något Clusterindex definierat i den tabellen för att genomdriva sorteringsmekanismen. Om ett Clustered index definieras i en kolumn i gruppen av tabellkolumner, kommer data att sorteras inuti datasidorna baserat på värdena för Clustered indexnyckelkolumnerna, och sidorna kommer att länkas samman baserat på dessa indexnyckelvärden. Den här sorterade tabellen kallas en klustrad tabell .
I SQL Server betraktas indexet som en viktig och effektiv nyckel i prestandajusteringsprocessen. Syftet med att skapa ett index är att påskynda åtkomsten till bastabellen och hämta den begärda informationen utan att behöva skanna alla tabellrader för att returnera den begärda informationen. Du kan tänka dig databasindexet som ett bokindex som hjälper dig att snabbt hitta orden i boken, utan att behöva läsa hela boken för att hitta det ordet. Anta till exempel att du behöver hämta information om en specifik kund med hjälp av ett kund-ID. Om det inte finns något index definierat för kolumnen Kund-ID i den här tabellen, kontrollerar SQL Server Engine alla tabellrader, en efter en, för att hämta kunden med det angivna ID:t. Om ett index är definierat för kolumnen Kund-ID i den här tabellen, kommer SQL Server Engine att leta efter de begärda kund-ID-värdena i det sorterade indexet, snarare än i bastabellen, för att hämta information om kunden, vilket minskar antalet skannade rader för att hämta data.
I SQL Server är indexet logiskt uppbyggt som 8K-sidor, eller indexnoder, i form av ett B-träd. B-Tree-strukturen innehåller tre nivåer:en Root Level som innehåller en indexsida överst i B-trädet, en Lövnivå som finns längst ner i B-trädet och innehåller datasidor och en mellannivå som inkluderar alla noder som finns mellan rot- och bladnivåerna, med indexnyckelvärden och pekare till följande sidor. Denna B-trädform ger ett snabbt sätt att navigera på datasidorna från vänster till höger och från toppen till botten, baserat på indexnyckeln.
I SQL Server finns det två huvudtyper av index, ett Clustered index, där den faktiska informationen lagras på bladnivåsidorna i indexet, med möjligheten att skapa endast ett klustrat index för varje tabell, eftersom data inuti datasidorna och ordningen på sidorna kommer att sorteras baserat på det klustrade indexet nyckel. Om du definierar en primärnyckelrestriktion i din tabell, skapas ett klustrat index automatiskt om inget klustrat index tidigare har definierats för den tabellen. Den andra typen av index är ett icke-klustrat index som inkluderar en sorterad kopia av indexnyckelkolumnerna och en pekare till resten av kolumnerna i bastabellen eller det klustrade indexet, med möjlighet att skapa upp till 999 icke-klustrade index för varje tabell.
SQL Server förser oss med andra speciella typer av index, till exempel ett Unikt index som skapas automatiskt när en unik begränsning definieras för att framtvinga unikheten hos specifika kolumnvärden, ett sammansatt index där mer än en nyckelkolumn kommer att delta i indexnyckeln, ett täckande index där alla kolumner som begärs av en specifik fråga kommer att delta i indexnyckeln, ett filtrerat index det vill säga ett optimerat icke-klustrat index med ett filterpredikat för att endast indexera en liten del av tabellraderna, ett Spatialt index som skapas på kolumnerna som lagrar rumslig data, ett XML-index som skapas på XML-binära stora objekt (BLOB) i XML-datatypkolumner, ett Columnstore-index där data är organiserade i kolumnärt dataformat, ett Fulltextindex som skapas av SQL Server Full-Text Engine och ett Hash-index som används i minnesoptimerade tabeller.
Som jag brukade kalla SQL Server-indexet är detta ett tveeggat svärd , där SQL Server Query Optimizer kan dra nytta av indexet som är väl utformat för att förbättra prestandan för dina applikationer genom att påskynda datahämtningsprocessen. Däremot kommer ett index som är designat på ett dåligt sätt inte att väljas av SQL Server Query Optimizer och det kommer att försämra prestandan för dina applikationer genom att sakta ner datamodifieringsoperationerna och förbruka din lagring utan att dra fördel av det i data hämtningsprocesser. Därför är det bättre att först följa de bästa metoderna och riktlinjerna för att skapa index, kontrollera effekten av att skapa en på utvecklingsmiljön och hitta en kompromiss mellan hastigheten för datahämtning och kostnaden för att lägga till det indexet på datamodifieringsoperationerna och utrymmeskraven för det indexet, innan det tillämpas på produktionsmiljön.
Innan du skapar ett index måste du studera de olika aspekterna som påverkar skapandet och användningen av indexet. Detta inkluderar typen av databasens arbetsbelastning, Online Transaction Processing (OLTP) eller Online Analytical Processing (OLAP), tabellens storlek , egenskaperna för tabellkolumnerna , sorteringsordningen av kolumnerna i frågan, typ av index som motsvarar frågan och lagringsegenskaperna såsom FILLFACTOR och PAD_INDEX alternativ som styr procentandelen utrymme på varje bladnivå och sidorna på mellannivå som ska fyllas med data.
SQL Server Index Fragmentering
Ditt arbete som DBA är inte begränsat till att skapa rätt index. När indexet är skapat bör du övervaka indexanvändningen och statistiken, till exempel måste du veta om detta index används dåligt eller inte används alls. Således kan du tillhandahålla den korrekta lösningen för att underhålla dessa index eller ersätta dem med mer effektiva. På detta sätt kommer du att behålla den högsta tillämpliga prestandan för ditt system. Du kan fråga dig själv:Varför använder SQL Server Query Optimizer inte längre mitt index, även om det gjorde det tidigare?
Svaret är främst relaterat till de kontinuerliga data- och schemaändringar som utförs på bastabellen som bör återspeglas i indexen. Med tiden, och med alla dessa förändringar, blir indexsidor osorterade, vilket gör att indexet blir fragmenterat. En annan anledning till fragmenteringen är ett försök att infoga ett nytt värde eller uppdatera det aktuella värdet, och det nya värdet passar inte i det lediga utrymmet för närvarande. I det här fallet kommer sidan att delas upp i två sidor, där den nya sidan skapas fysiskt efter den sista sidan. Och du kan föreställa dig att läsa från ett fragmenterat index och antalet sidor som ska skannas, och, naturligtvis, antalet I/O-operationer som utförs för att hämta flera poster på grund av avståndet mellan dessa sidor. Och på grund av denna extra kostnad för att använda detta fragmenterade index, kommer SQL Server Query Optimizer att ignorera detta index.
Olika sätt att få indexfragmentering
SQL Server ger oss olika sätt att få procentandelen av indexfragmentering. Det första sättet är att kontrollera procentandelen av indexfragmentering i Index Egenskaper fönstret under Fragmentering fliken, som visas nedan:
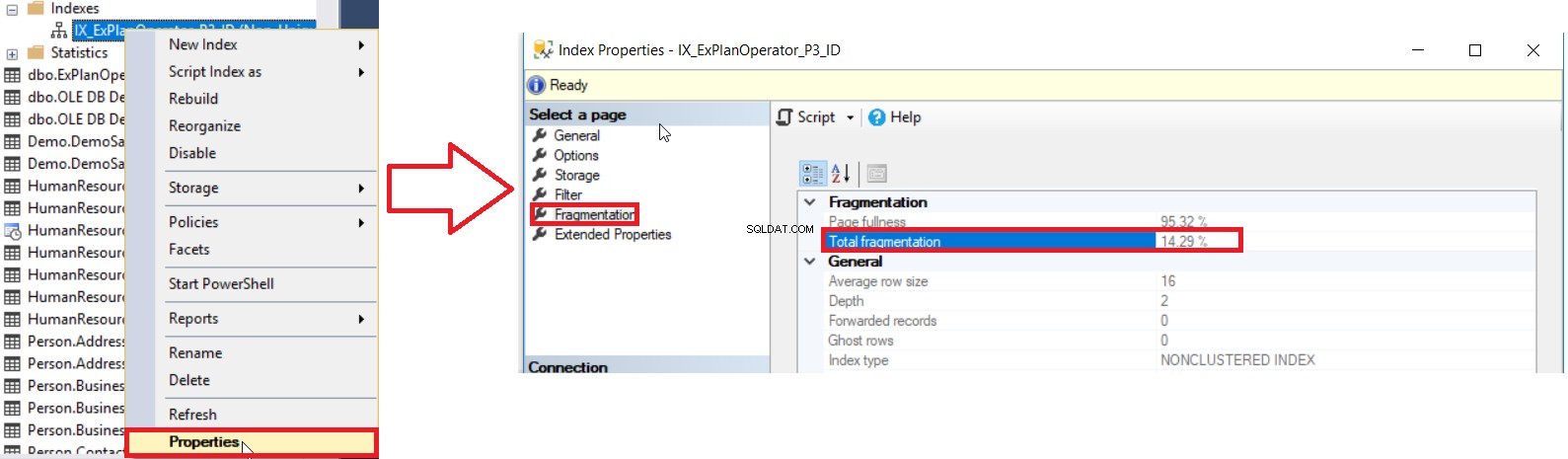
Men för att kontrollera fragmenteringsnivån för flera index måste du först utföra UI-metodkontrollen för alla index, ett efter ett, vilket är en tidsödande operation. Den andra tillgängliga metoden för att kontrollera fragmenteringsnivån för alla databasindex är att fråga sys.dm_db_index_physical_stats DMF och sammanfoga den med sys.indexes DMV för att hämta all information om dessa index, med hänsyn till att denna statistik kommer att uppdateras när SQL Server-tjänsten startas om med en fråga som liknar följande:
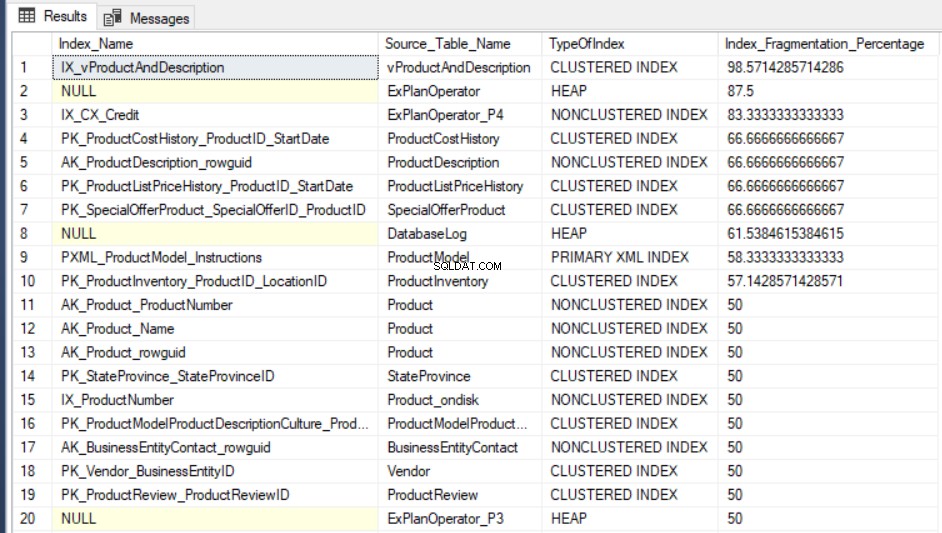
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Resultatet av att fråga AdventureWorks2016CTP3 testdatabasen kommer att likna följande:
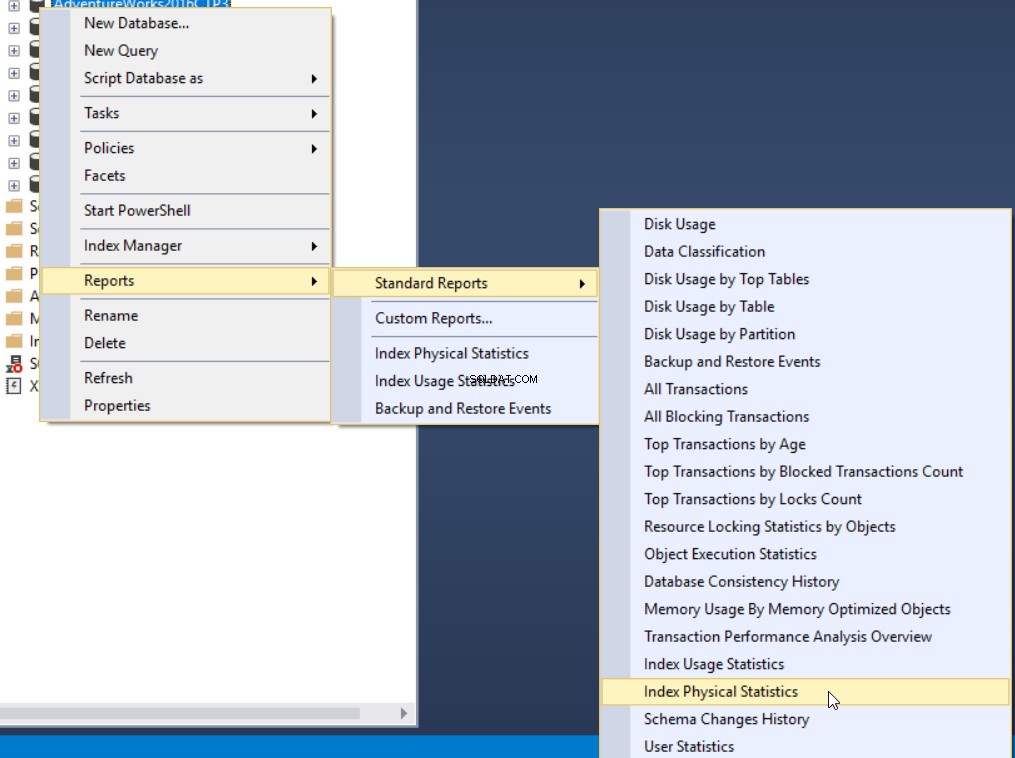
Den tredje metoden för att få fragmenteringsprocenten är att använda den inbyggda SQL Server-standardrapporten som heter Index Physical Statistics. Den här rapporten returnerar användbar information om indexpartitioner, fragmenteringsprocent, antal sidor på varje indexpartition och rekommendationer om hur du åtgärdar problemet med indexfragmentering genom att bygga om eller omorganisera indexet. För att se rapporten, högerklicka på din databas, välj alternativet Rapporter, Standardrapporter och välj Indexera fysisk statistik enligt nedan:
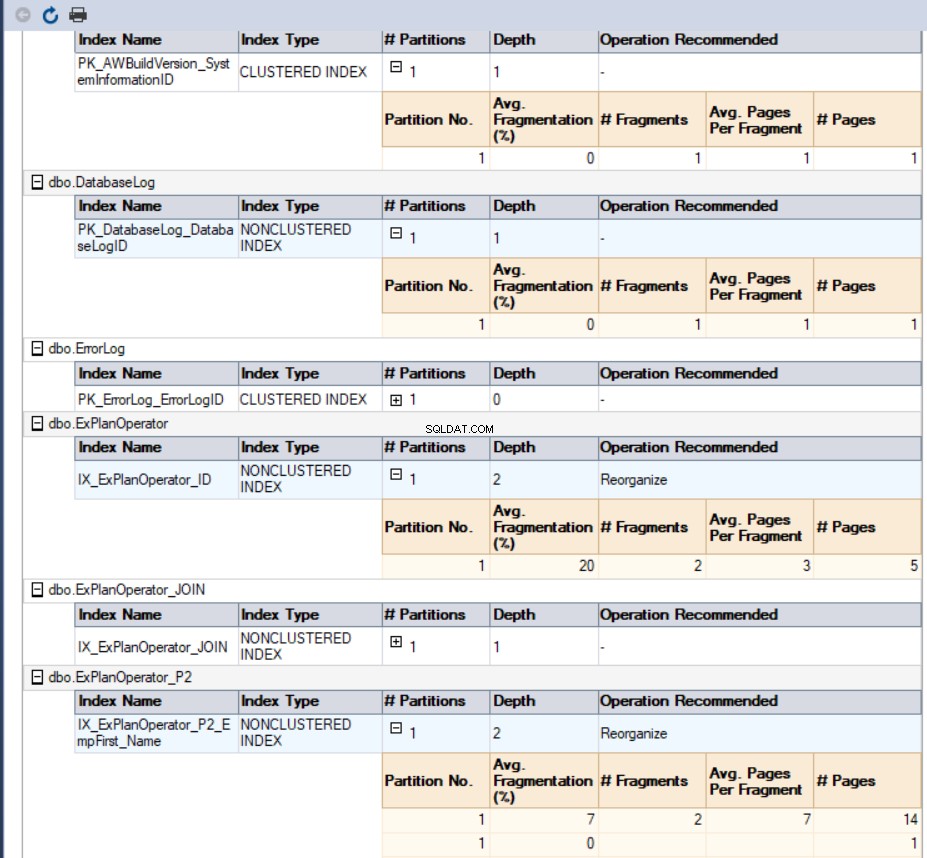
I vårt fall kommer den genererade rapporten att se ut så här:
Det sista och enklaste sättet att hämta fragmenteringsprocenten för alla databasindex är verktyget dbForge Index Manager. dbForge Index Manager verktyget är ett tillägg som kan läggas till i din SQL Server Management Studio för att analysera SQL Server-databasernas index, vilket ger dig en mycket användbar rapport med statusen för de valda databasindexen och underhållsförslag för att åtgärda dessa indexfragmenteringsproblem.
Efter att ha installerat tillägget dbForge Index Manager i ditt SSMS kan du köra det genom att högerklicka på databasen som ska skannas, välj Indexhanterare , sedan Hantera indexfragmentering som visas nedan:
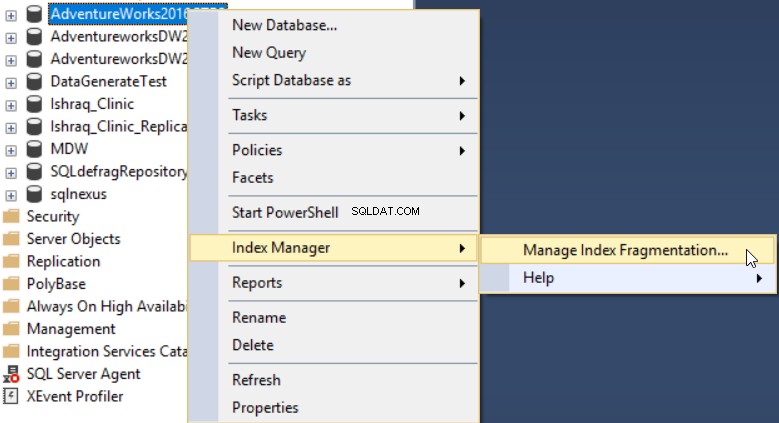
Verktyget dbForge Index Manager låter dig få en övergripande bild av fragmenteringen av de valda databasindexen, med rekommendationer för lämpliga åtgärder för att åtgärda problemet, som visas nedan:

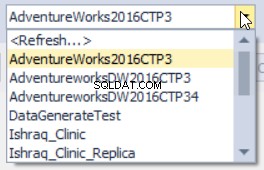
Verktyget dbForge Index Manager låter dig också växla mellan databaser, vilket ger dig en ny rapport efter att ha skannat den här databasen enligt nedan:
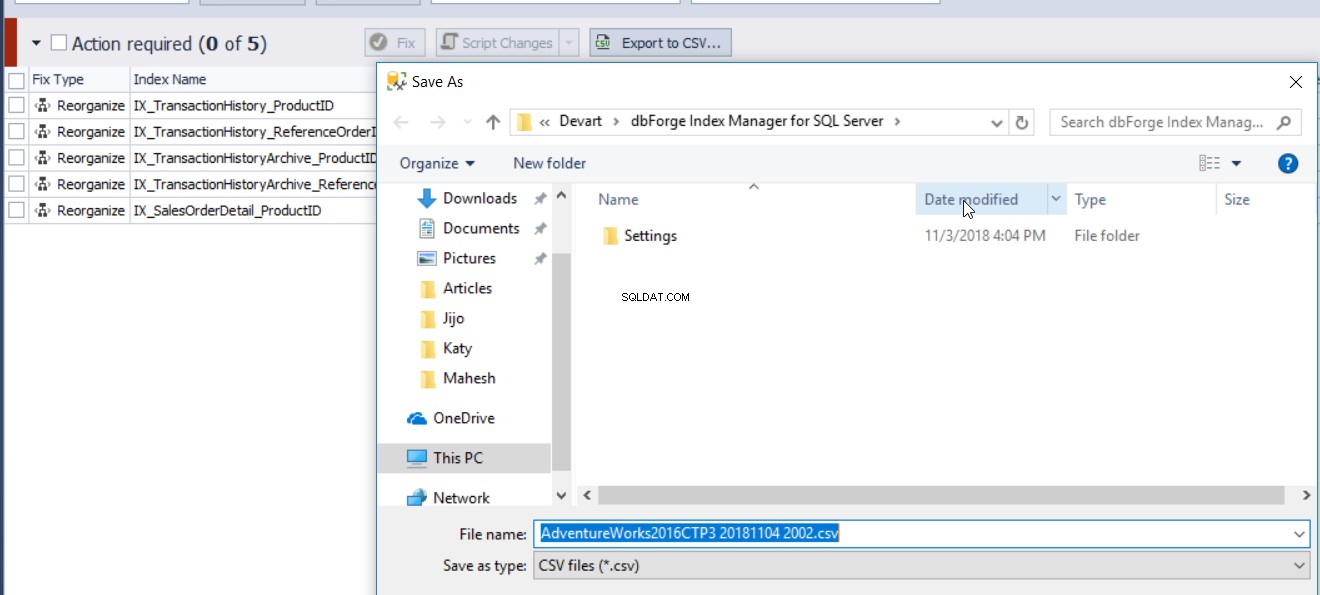
Indexfragmenteringsrapporten som genereras av verktyget dbForge Index Manager kan exporteras till en CSV-fil för att analysera indexets fragmenteringsstatus, som visas nedan:
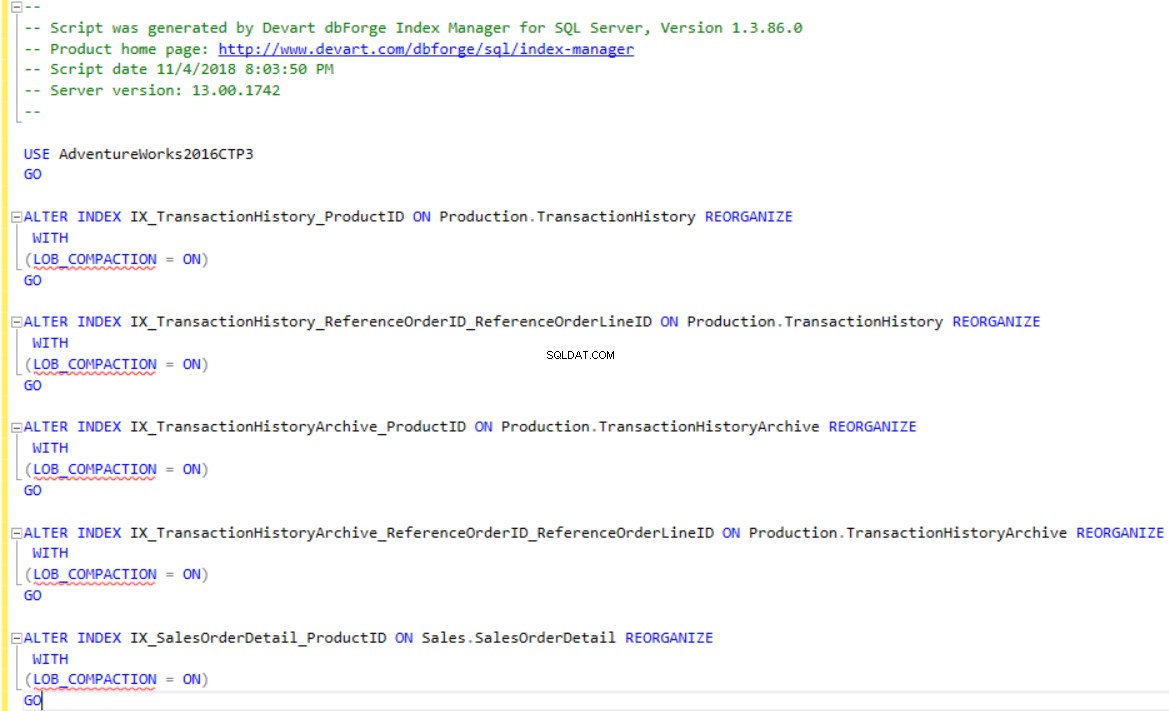
dbForge Index Manager låter dig generera T-SQL-skript för att bygga om eller omorganisera indexen enligt verktygsrekommendationen. Använd Skriptändringar alternativet för att visa eller spara skriptet för de index som är fragmenterade, som visas nedan:
Verktyget dbForge Index Manager ger dig möjlighet att åtgärda problemet med indexfragmentering direkt genom att klicka på Åtgärda knapp som kommer att utföra den rekommenderade åtgärden direkt på de valda indexen, och visar fixeringsstatusen på Resultat kolumn enligt nedan:

Om du klickar på Analysera om knappen, kommer den att skanna indexfragmenteringen på databasen igen efter att korrigeringsoperationen har utförts framgångsrikt. Det som listas här i den här artikeln är bara en introduktion till hur verktyget dbForge Index Manager hjälper oss att identifiera och åtgärda indexfragmenteringsproblem. Min rekommendation till dig är att ladda ner det och kolla vad det här verktyget kan erbjuda dig.
Användbara länkar:
- Grundläggande information om index
- Typer av index
- Klustrade och icke-klustrade index beskrivs
- Klustrerade indexstrukturer
Användbart verktyg:
dbForge Index Manager – praktiskt SSMS-tillägg för att analysera status för SQL-index och åtgärda problem med indexfragmentering.