I det här blogginlägget kommer vi att undersöka några nyckeltal och status när vi övervakar en Percona-server för MySQL för att hjälpa oss att finjustera MySQL-serverns konfiguration på lång sikt. Bara för att vara uppmärksam, Percona Server har vissa övervakningsmått som bara är tillgängliga på den här versionen. Vid jämförelse på version 8.0.20 är följande 51 statusar endast tillgängliga på Percona Server för MySQL, som inte är tillgängliga i uppströms Oracles MySQL Community Server:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Kolla in den utökade InnoDB-statussidan för mer information om var och en av övervakningsmåtten ovan. Observera att viss extra status som trådpool endast är tillgänglig i Oracles MySQL Enterprise. Kolla in Percona Server för MySQL 8.0-dokumentationen för att se alla förbättringar specifikt för denna konstruktion över Oracles MySQL Community Server 8.0.
För att hämta MySQL globala status, använd helt enkelt något av följande uttalanden:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Databastillstånd och översikt
Vi börjar med upptidsstatusen, antalet sekunder som servern har varit uppe.
Alla com_*-status är satsens räknarvariabler som anger hur många gånger varje sats har exekveras. Det finns en statusvariabel för varje typ av uttalande. Till exempel, com_delete och com_update räknar DELETE respektive UPDATE-satser. com_delete_multi och com_update_multi liknar varandra men gäller för DELETE- och UPDATE-satser som använder syntax för flera tabeller.
För att lista ut alla pågående processer av MySQL, kör bara en av följande satser:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Anslutningar och trådar
Aktuella anslutningar
Förhållandet mellan för närvarande öppna anslutningar (anslutningsgänga). Om förhållandet är högt indikerar det att det finns många samtidiga anslutningar till MySQL-servern och kan leda till felet "För många anslutningar". För att få anslutningsprocenten:
Current connections(%) = (threads_connected / max_connections) x 100Ett bra värde bör vara 80 % och lägre. Försök att öka variabeln max_connections eller inspektera anslutningarna med hjälp av VISA HELA PROCESSLISTA. När "För många anslutningar"-fel inträffar, kommer MySQL-databasservern att bli otillgänglig för icke-superanvändaren tills vissa anslutningar frigörs. Observera att en ökning av variabeln max_connections också potentiellt kan öka MySQL:s minnesavtryck.
Maximalt antal anslutningar som någonsin setts
Förhållandet mellan maximala anslutningar till MySQL-servern som någonsin har setts. En enkel beräkning skulle vara:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Det goda värdet bör vara under 80 %. Om förhållandet är högt indikerar det att MySQL en gång har nått ett högt antal anslutningar som skulle leda till "för många anslutningar"-fel. Inspektera det nuvarande anslutningsförhållandet för att se om det verkligen håller sig lågt konsekvent. Öka annars variabeln max_connections. Kontrollera max_used_connections_time-statusen för att indikera när max_used_connections-statusen nådde sitt nuvarande värde.
Träningsfrekvens för trådcache
Statusen för threads_created är antalet trådar som skapats för att hantera anslutningar. Om threads_created är stort, kanske du vill öka värdet för thread_cache_size. Cachens träff/miss-frekvens kan beräknas som:
Threads cache hit rate (%) = (threads_created / connections) x 100Det är en bråkdel som ger en indikation på trådens cacheträfffrekvens. Ju närmare mindre än 50%, desto bättre. Om din server ser hundratals anslutningar per sekund bör du normalt ställa in thread_cache_size tillräckligt högt så att de flesta nya anslutningar använder cachade trådar.
Frågeprestanda
Fullständiga tabellskanningar
Förhållandet mellan genomsökningar av hela tabellen, en operation som kräver att man läser hela innehållet i en tabell, snarare än bara valda delar med hjälp av ett index. Detta värde är högt om du gör många frågor som kräver sortering av resultat eller tabellskanningar. Generellt sett tyder detta på att tabeller inte är korrekt indexerade eller att dina frågor inte är skrivna för att dra nytta av de index du har. Så här beräknar du procentandelen av genomsökningar av hela tabellen:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Det goda värdet bör vara under 25 %. Undersök MySQL långsamma frågeloggutdata för att ta reda på de suboptimala frågorna.
Välj Fullständig koppling
Statusen för select_full_join är antalet joins som utför tabellsökningar eftersom de inte använder index. Om detta värde inte är 0, bör du noggrant kontrollera indexen för dina tabeller.
Välj Range Check
Statusen för select_range_check är antalet kopplingar utan nycklar som kontrollerar nyckelanvändning efter varje rad. Om detta inte är 0, bör du noggrant kontrollera indexen för dina tabeller.
Sortera pass
Förhållandet mellan sammanslagningar som sorteringsalgoritmen har behövt göra. Om detta värde är högt bör du överväga att öka värdet för sort_buffer_size och read_rnd_buffer_size. En enkel kvotberäkning är:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Ett förhållandevärde lägre än 3 bör vara ett bra värde. Om du vill öka sort_buffer_size eller read_rnd_buffer_size, försök att öka i små steg tills du når det acceptabla förhållandet.
InnoDB-prestanda
InnoDB Buffer Pool Hit Rate
Förhållandet mellan hur ofta dina sidor hämtas från minnet istället för från disken. Om värdet är lågt under tidig uppstart av MySQL, vänligen ge lite tid för buffertpoolen att värmas upp. För att få buffertpoolens träfffrekvens, använd SHOW ENGINE INNODB STATUS-satsen:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Det bästa värdet är 1000/10000 träfffrekvens. För ett lägre värde, till exempel, indikerar träfffrekvensen på 986/1000 att av 1000 sidläsningar kunde den läsa sidor i RAM 986 gånger. De återstående 14 gångerna var MySQL tvungen att läsa sidorna från disken. Enkelt sagt, 1000 / 1000 är det bästa värdet som vi försöker uppnå här, vilket innebär att de ofta åtkomliga data passar fullt ut i RAM.
Att öka variabeln innodb_buffer_pool_size kommer att hjälpa mycket för att rymma mer utrymme för MySQL att arbeta på. Se dock till att du har tillräckligt med RAM-resurser i förväg. Att ta bort redundanta index kan också hjälpa. Om du har flera buffertpoolsinstanser, se till att träfffrekvensen för varje instans når 1000/1000.
InnoDB Dirty Pages
Förhållandet mellan hur ofta InnoDB behöver spolas. Under den skrivtunga belastningen är det normalt att denna procentsats ökar.
En enkel beräkning skulle vara:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Ett bra värde bör vara 75 % och lägre. Om andelen smutsiga sidor förblir hög under en längre tid, kanske du vill öka buffertpoolen eller skaffa snabbare diskar för att undvika prestandaflaskhalsar.
InnoDB väntar på kontrollpunkt
Förhållandet mellan hur ofta InnoDB behöver läsa eller skapa en sida där inga rena sidor är tillgängliga. Normalt sker skrivningar till InnoDB Buffer Pool i bakgrunden. Men om det är nödvändigt att läsa eller skapa en sida och inga rena sidor finns tillgängliga, är det också nödvändigt att vänta på att sidorna rensas först. Innodb_buffer_pool_wait_free räknaren räknar hur många gånger detta har hänt. För att beräkna förhållandet mellan InnoDB-väntningar på kontroll kan vi använda följande beräkning:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsOm innodb_buffer_pool_wait_free är större än 0, är det en stark indikator på att InnoDB-buffertpoolen är för liten, och operationer fick vänta på en kontrollpunkt. Att öka innodb_buffer_pool_size kommer vanligtvis att minska innodb_buffer_pool_wait_free, såväl som detta förhållande. Ett bra förhållande bör ligga under 1.
InnoDB väntar på Redolog
Förhållandet mellan redogörelseloggpåståenden. Kontrollera innodb_log_waits och om den fortsätter att öka, öka innodb_log_buffer_size. Det kan också betyda att diskarna är för långsamma och inte kan upprätthålla diskens IO, kanske på grund av maximal skrivbelastning. Använd följande beräkning för att beräkna vänteförhållandet för omloggning:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesEtt bra förhållande bör vara under 1. Öka annars innodb_log_buffer_size.
Tabell
Användning av tabellcache
Förhållandet mellan tabellcacheanvändning för alla trådar. En enkel beräkning skulle vara:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Det goda värdet bör vara mindre än 80 %. Öka variabeln table_open_cache tills procentandelen når ett bra värde.
Träffförhållande för tabellcache
Förhållandet mellan tabellcacheträffanvändning. En enkel beräkning skulle vara:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Ett bra träffförhållande bör vara 90 % och högre. Öka annars variabeln table_open_cache tills träffförhållandet når ett bra värde.
Mätvärdesövervakning med ClusterControl
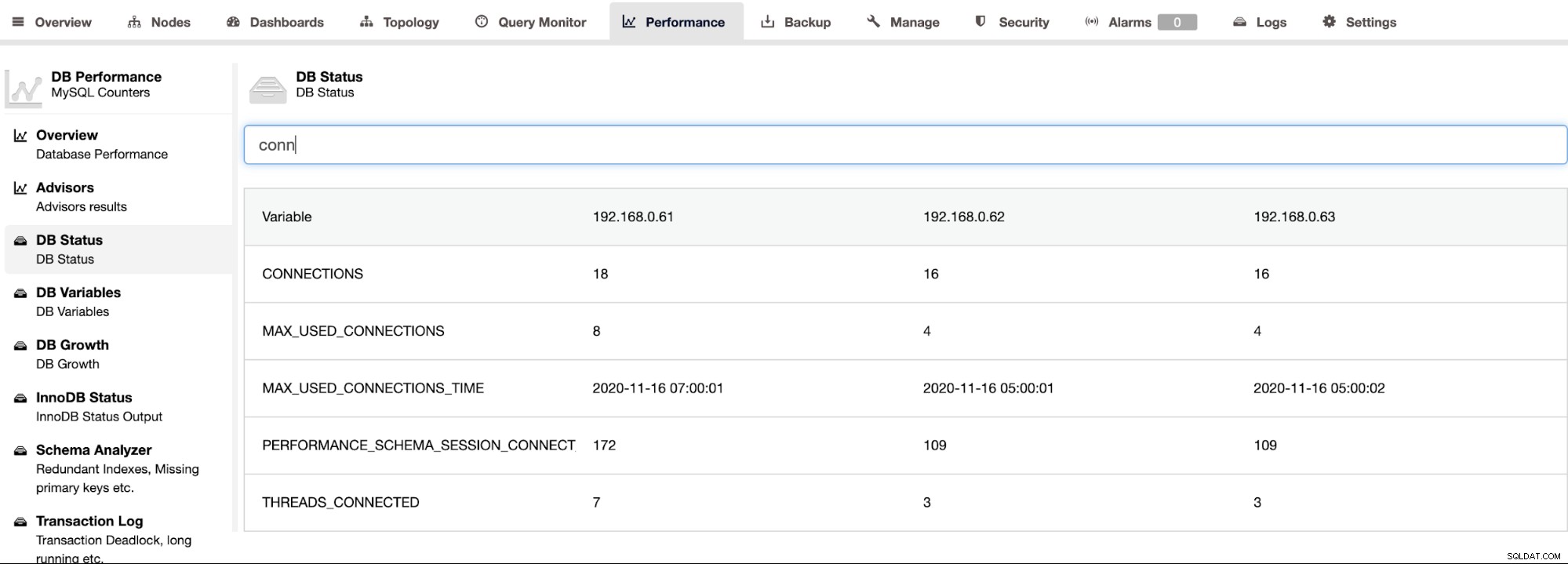
ClusterControl stöder Percona Server för MySQL och den ger en samlad vy av alla noder i ett kluster under ClusterControl -> Prestanda -> DB Status-sidan. Detta ger ett centraliserat tillvägagångssätt för att leta upp all status på alla värdar med möjligheten att filtrera statusen, som visas i följande skärmdump:
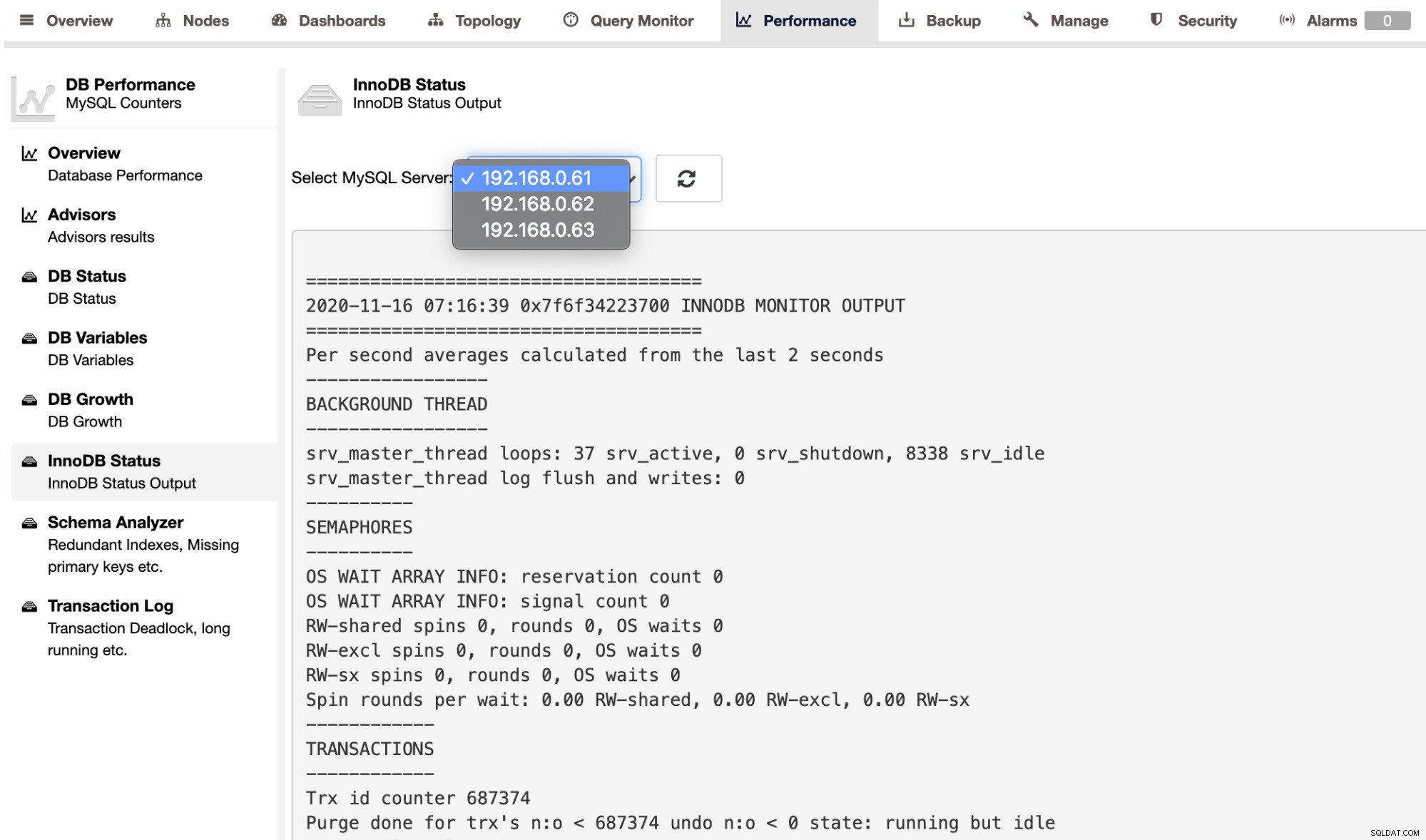
För att hämta SHOW ENGINE INNODB STATUS-utgången för en enskild server kan du använd sidan Prestanda -> InnoDB Status, som visas nedan:
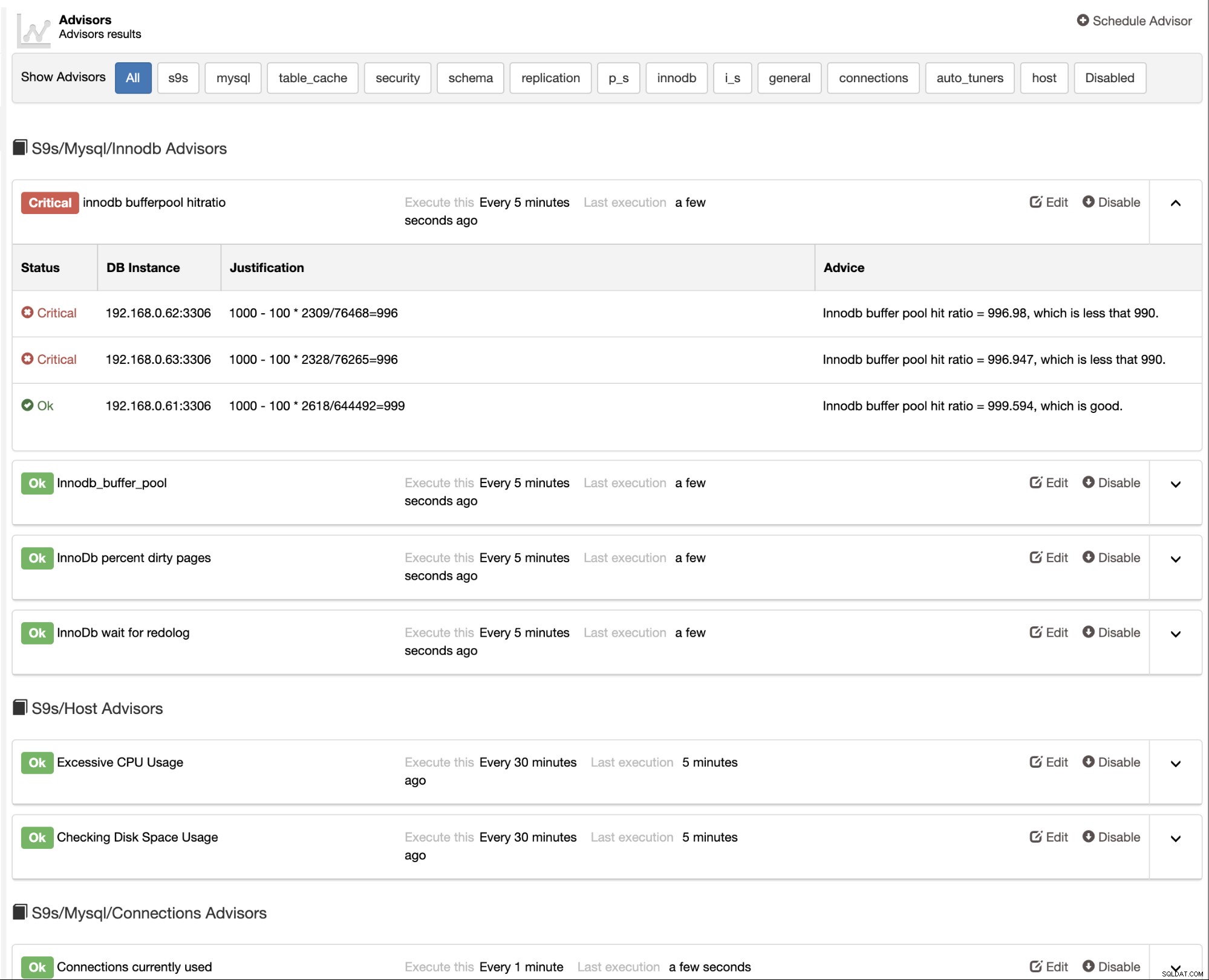
ClusterControl tillhandahåller även inbyggda rådgivare som du kan använda för att spåra din databas prestanda. Den här funktionen är tillgänglig under ClusterControl -> Prestanda -> Rådgivare:
Rådgivare är i princip miniprogram som körs av ClusterControl i en schemalagd timing som cron jobb. Du kan schemalägga en rådgivare genom att klicka på knappen "Schedule Advisor" och välja en befintlig rådgivare från Developer Studio-objektträdet:
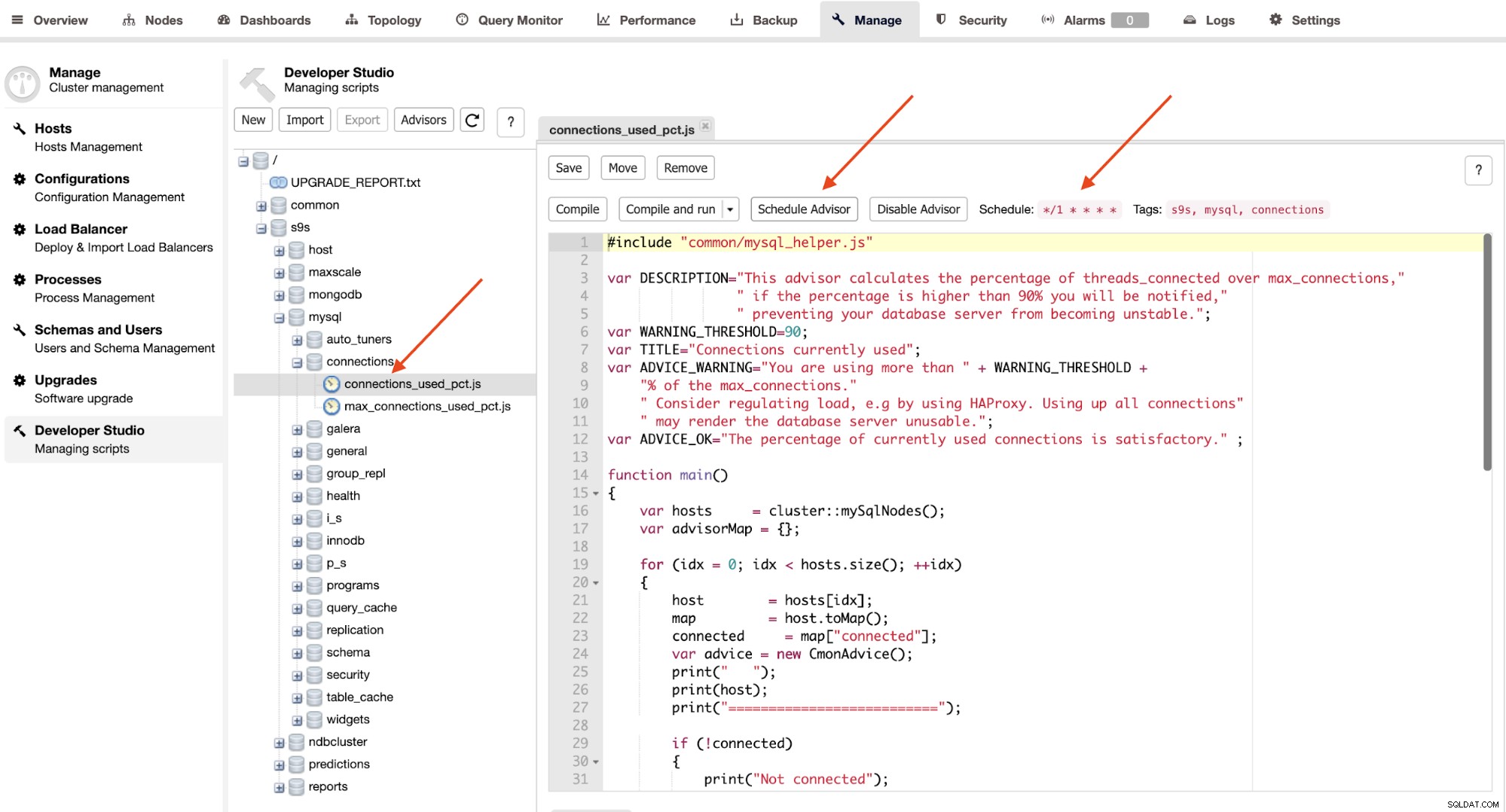
Klicka på knappen "Schedule Advisor" för att ställa in schemaläggningen, argument till pass och även rådgivarens taggar. Du kan också kompilera rådgivaren för att se utdata direkt genom att klicka på knappen "Kompilera och kör", där du bör se följande utdata under "Meddelanden" under den:

Du kan skapa din egen rådgivare genom att hänvisa till den här utvecklarguiden, skriven i ClusterControl Domain Specific Language (mycket likt Javascript), eller anpassa en befintlig rådgivare för att passa dina övervakningspolicyer. Kort sagt, ClusterControls övervakningsuppgift kan utökas med obegränsade möjligheter genom ClusterControl Advisors.