Relationsdatabaser representerar en organisations data i tabeller som använder kolumner med olika datatyper så att de kan lagra giltiga värden. Utvecklare och DBA:er behöver känna till och förstå den lämpliga datatypen för varje kolumn för bättre frågeprestanda.
Den här artikeln kommer att behandla de populära datatyperna VARCHAR() och NVARCHAR(), deras jämförelse och prestandarecensioner i SQL Server.
VARCHAR [ ( n | max ) ] i SQL
VARCHAR datatypen representerar icke-Unicode strängdatatyp med variabel längd. Du kan lagra bokstäver, siffror och specialtecken i den.
- N representerar strängstorlek i byte.
- Datatypkolumnen VARCHAR lagrar högst 8000 icke-Unicode-tecken.
- VARCHAR-datatypen tar 1 byte per tecken. Om du inte uttryckligen anger värdet för N tar det 1-byte lagring.
Obs! Förväxla inte N med ett värde som representerar antalet tecken i en sträng.
Följande fråga definierar VARCHAR-datatypen med 100 byte data.
DECLARE @text AS VARCHAR(100) ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
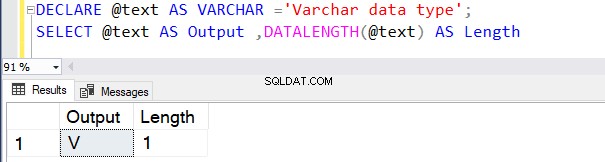
Den returnerar längden som 17 på grund av 1 byte per tecken, inklusive ett blanksteg.
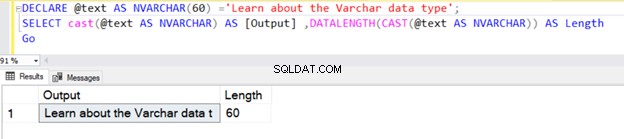
Följande fråga definierar VARCHAR-datatypen utan något värde på N . Därför betraktar SQL Server standardvärdet som 1 byte, som visas nedan.
DECLARE @text AS VARCHAR ='VARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
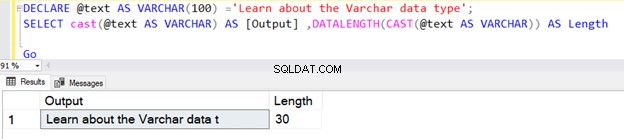
Vi kan också använda VARCHAR med funktionen CAST eller CONVERT. Till exempel, i de två exemplen nedan, deklarerade vi en variabel med 100 bytes längd och använde senare CAST-operatorn.
Den första frågan returnerar längden som 30 eftersom vi inte angav N i datatypen CAST-operatorn VARCHAR. Standardlängden är 30.
DECLARE @text AS VARCHAR(100) ='Learn about the VARCHAR data type';
SELECT cast(@text AS VARCHAR) AS [Output] ,DATALENGTH(CAST(@text AS VARCHAR)) AS Length
Go
Men om strängens längd är mindre än 30 tar den den faktiska storleken på strängen.

NVARCHAR [ ( n | max ) ] i SQL
NVARCHAR datatypen är för Unicode teckendatatyp med variabel längd. Här hänvisar N till National Language Character Set och används för att definiera Unicode-strängen. Du kan lagra både icke-Unicode- och Unicode-tecken (japansk kanji, koreansk hangul, etc.).
- N representerar strängstorlek i byte.
- Den kan lagra maximalt 4000 Unicode- och icke-Unicode-tecken.
- VARCHAR-datatypen tar 2 byte per tecken. Det tar 2 byte lagring om du inte anger något värde för N.
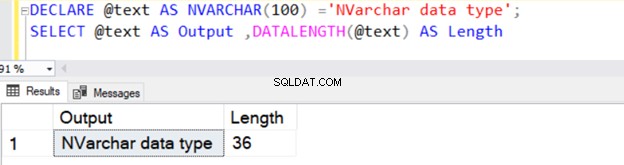
Följande fråga definierar VARCHAR-datatypen med 100 byte data.
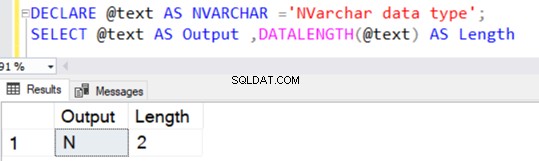
DECLARE @text AS NVARCHAR(100) ='NVARCHAR data type';
SELECT @text AS Output ,DATALENGTH(@text) AS Length
Den returnerar stränglängden på 36 eftersom NVARCHAR tar 2 byte per teckenlagring.
I likhet med VARCHAR-datatypen har NVARCHAR också ett standardvärde på 1 tecken (2 byte) utan att ange ett explicit värde för N.
Om vi använder NVARCHAR-konverteringen med CAST- eller CONVERT-funktionen utan något explicit värde på N, är standardvärdet 30 tecken, dvs. 60 byte.
Lagra Unicode- och icke-Unicode-värdena i VARCHAR-datatyp
Anta att vi har en tabell som registrerar kundfeedback från en e-shoppingportal. För detta ändamål har vi en SQL-tabell med följande fråga.
CREATE TABLE UserComments
(
ID int IDENTITY (1,1),
[Language] VARCHAR(50),
[comment] VARCHAR(200),
[NewComment] NVARCHAR(200)
)
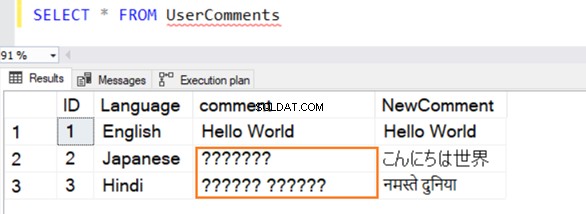
Vi infogar flera exempelposter i den här tabellen på engelska, japanska och hindi. Datatypen för [Kommentar] är VARCHAR och [Nykommentar] är NVARCHAR() .
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('English','Hello World', N'Hello World')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Japanese','こんにちは世界', N'こんにちは世界')
INSERT INTO UserComments ([Language],[Comment],[NewComment])
VALUES ('Hindi','नमस्ते दुनिया', N'नमस्ते दुनिया')
Frågan körs framgångsrikt och den ger följande rader samtidigt som man väljer ett värde från den. För raden 2 och 3 känner den inte igen data om den inte är på engelska.
VARCHAR och NVARCHAR Datatyper:Prestandajämförelse
Vi bör inte blanda användningen av datatyperna VARCHAR och NVARCHAR i predikaten JOIN eller WHERE. Det ogiltigförklarar de befintliga indexen eftersom SQL Server kräver samma datatyper på båda sidor av JOIN. SQL Server försöker göra den implicita konverteringen med funktionen CONVERT_IMPLICIT() i händelse av en missmatchning.
SQL Server använder datatypsprioritet för att avgöra vilken måldatatyp som är. NVARCHAR har högre prioritet än VARCHAR-datatypen. Därför konverterar SQL Server de befintliga VARCHAR-värdena till NVARCHAR under datatypskonverteringen.
CREATE TABLE #PerformanceTest
(
[ID] INT NOT NULL IDENTITY(1, 1) PRIMARY KEY,
[Col1] VARCHAR(50) NOT NULL,
[Col2] NVARCHAR(50) NOT NULL
)
CREATE INDEX [ix_performancetest_col] ON #PerformanceTest (col1)
CREATE INDEX [ix_performancetest_col2] ON #PerformanceTest (col2)
INSERT INTO #PerformanceTest VALUES ('A',N'C')
Låt oss nu köra två SELECT-satser som hämtar poster enligt deras datatyper.
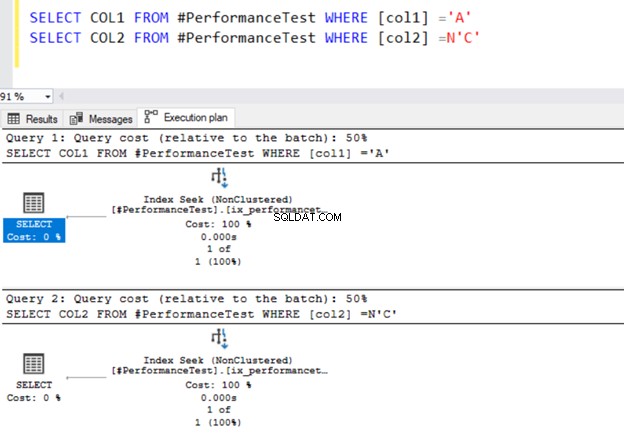
SELECT COL1 FROM #PerformanceTest WHERE [col1] ='A'
SELECT COL2 FROM #PerformanceTest WHERE [col2] =N'C'
Båda frågorna använder indexsökoperatorn och indexen vi definierade tidigare.
Nu byter vi datatypvärdena för jämförelse med WHERE-predikatet. Kolumn 1 har en VARCHAR-datatyp, men vi anger N’A’ för att uttrycka den som NVARCHAR-datatyp.
På samma sätt är col2 NVARCHAR-datatypen, och vi anger värdet 'C' som hänvisar till VARCHAR-datatypen.
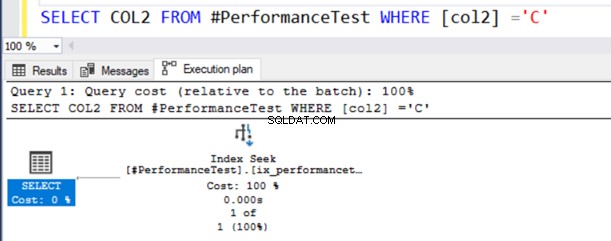
SELECT COL2 FROM #PerformanceTest WHERE [col2] ='C'I den faktiska exekveringsplanen för frågan får du en Indexskanning och SELECT-satsen har en varningssymbol.
Den här frågan fungerar bra eftersom datatypen NVARCHAR() kan ha både Unicode- och icke-Unicode-värden.
Nu använder den andra frågan en Indexskanning och utfärdar en varningssymbol på SELECT-operatorn.
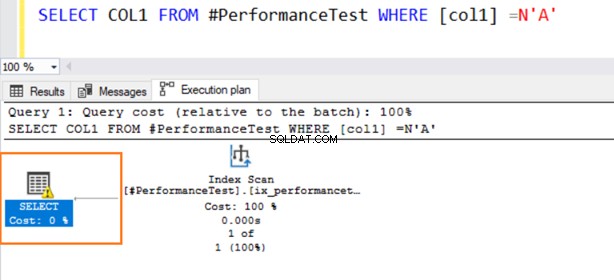
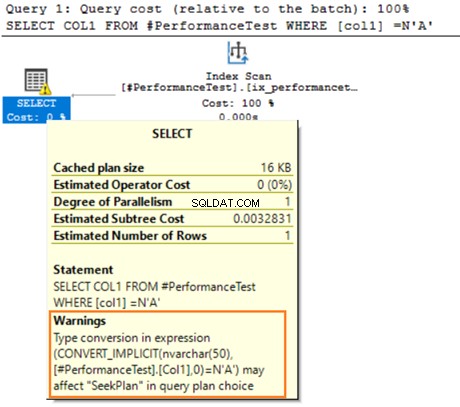
Håll muspekaren över SELECT-satsen som utfärdar en varning om den implicita konverteringen. SQL Server kunde inte använda det befintliga indexet korrekt. Det beror på de olika datasorteringsalgoritmerna för både VARCHAR och NVARCHAR datatyper.
Om tabellen har miljontals rader måste SQL Server göra ytterligare arbete och konvertera data med hjälp av datakonvertering implicit. Det kan påverka ditt sökresultat negativt. Därför bör du undvika att blanda och matcha dessa datatyper för att optimera frågorna.
Slutsats
Du bör granska dina datakrav samtidigt som du utformar databastabeller och deras kolumndatatyp på lämpligt sätt. Vanligtvis servrar VARCHAR-datatypservrarna de flesta av dina datakrav. Men om du behöver lagra både Unicode och icke-Unicode-datatyper i en kolumn, kan du överväga att använda NVARCHAR. Du bör dock granska dess prestandaimplikationer, lagringsstorlek innan du fattar det slutliga beslutet.