Introduktion
Oavsett hur mycket vi försöker designa och utveckla applikationer kommer fel alltid att uppstå. Det finns två generella kategorier – syntax eller logiska fel kan antingen vara programmatiska fel eller konsekvenser av felaktig databasdesign. Annars kan du få ett felmeddelande på grund av fel användarinmatning.
T-SQL (programmeringsspråket SQL Server) tillåter hantering av båda feltyperna. Du kan felsöka programmet och bestämma vad du behöver göra för att undvika buggar i framtiden.
De flesta applikationer kräver att du loggar fel, implementerar användarvänlig felrapportering och, när det är möjligt, hanterar fel och fortsätter applikationskörningen.
Användare hanterar fel på satsnivå. Det betyder att när du kör en sats av SQL-kommandon, och problemet inträffar i den sista satsen, kommer allt som föregår det problemet att bindas till databasen som implicita transaktioner. Det här kanske inte är vad du önskar.
Relationsdatabaser är optimerade för att köra batchsatser. Därför måste du köra en sats av satser som en enhet och misslyckas med alla satser om en sats misslyckas. Du kan åstadkomma detta genom att använda transaktioner. Den här artikeln kommer att fokusera på både felhantering och transaktioner, eftersom dessa ämnen är starkt kopplade.
SQL-felhantering
För att simulera undantag måste vi producera dem på ett repeterbart sätt. Låt oss börja med det enklaste exemplet – division med noll:
SELECT 1/0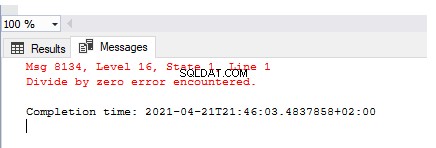
Utdatan beskriver det skapade felet – Dividera med noll fel som påträffats . Men detta fel hanterades inte, loggades eller anpassades för att skapa ett användarvänligt meddelande.
Undantagshantering börjar med att satser du vill köra i BEGIN TRY...END TRY-blocket.
SQL Server hanterar (fångar) fel i BEGIN CATCH...END CATCH-blocket, där du kan ange anpassad logik för felloggning eller bearbetning.
BEGIN CATCH-satsen måste följa omedelbart efter END TRY-satsen. Körningen skickas sedan från TRY-blocket till CATCH-blocket vid första felet.
Här kan du bestämma hur du ska hantera felen, om du vill logga data om upptagna undantag eller skapa ett användarvänligt meddelande.
SQL Server har inbyggda funktioner som kan hjälpa dig att extrahera felinformation:
- ERROR_NUMBER():Returnerar antalet SQL-fel.
- ERROR_SEVERITY():Returnerar svårighetsgraden som anger typen av problem och dess nivå. Nivåerna 11 till 16 kan hanteras av användaren.
- ERROR_STATE():Returnerar feltillståndsnumret och ger mer information om det kastade undantaget. Du använder felnumret för att söka i Microsofts kunskapsbas efter specifika feldetaljer.
- ERROR_PROCEDURE():Returnerar namnet på proceduren eller triggern där felet uppstod, eller NULL om felet inte inträffade i proceduren eller triggern.
- ERROR_LINE():Returnerar radnumret där felet inträffade. Det kan vara radnumret för procedurer eller utlösare eller radnumret i batchen.
- ERROR_MESSAGE():Returnerar texten i felmeddelandet.
Följande exempel visar hur man hanterar fel. Det första exemplet innehåller Division med noll fel, medan det andra påståendet är korrekt.
BEGIN TRY
PRINT 1/0
SELECT 'Correct text'
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH

Om den andra satsen körs utan felhantering (VÄLJ "Korrigera text"), skulle den lyckas.
Eftersom vi implementerar den anpassade felhanteringen i TRY-CATCH-blocket, skickas programexekveringen till CATCH-blocket efter felet i den första satsen, och den andra satsen kördes aldrig.
På så sätt kan du ändra texten som ges till användaren och kontrollera vad som händer om ett fel inträffar bättre. Till exempel loggar vi fel till en loggtabell för vidare analys.
Använda transaktioner
Affärslogiken kan avgöra att infogningen av den första satsen misslyckas när den andra satsen misslyckas, eller att du kan behöva upprepa ändringar av den första satsen vid den andra satsen. Genom att använda transaktioner kan du exekvera en sats av satser som en enhet som antingen misslyckas eller lyckas.
Följande exempel visar användningen av transaktioner.
Först skapar vi en tabell för att testa lagrad data. Sedan använder vi två transaktioner inuti TRY-CATCH-blocket för att simulera saker som händer om en del av transaktionen misslyckas.
Vi kommer att använda CATCH-satsen med XACT_STATE()-satsen. Funktionen XACT_STATE() används för att kontrollera om transaktionen fortfarande existerar. Om transaktionen rullar tillbaka automatiskt, skulle ROLLBACK TRANSACTION skapa ett nytt undantag.
Få en byte vid koden nedan:
-- CREATE TABLE TEST_TRAN(VALS INT)
BEGIN TRY
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(1);
COMMIT TRANSACTION
BEGIN TRANSACTION
INSERT INTO TEST_TRAN(VALS) VALUES(2);
INSERT INTO TEST_TRAN(VALS) VALUES('A');
INSERT INTO TEST_TRAN(VALS) VALUES(3);
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF XACT_STATE() > 0 ROLLBACK TRANSACTION
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
SELECT * FROM TEST_TRAN
-- DROP TABLE TEST_TRAN
Bilden visar värdena i TEST_TRAN-tabellen och felmeddelanden:
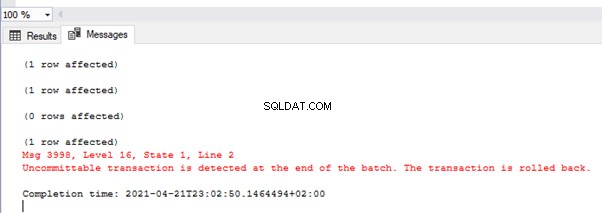
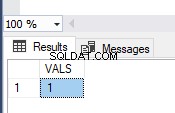
Som du ser var endast det första värdet begått. I den andra transaktionen hade vi ett typkonverteringsfel på den andra raden. Alltså rullade hela partiet tillbaka.
På så sätt kan du styra vilken data som kommer in i databasen och hur partier bearbetas.
Genererar anpassat felmeddelande i SQL
Ibland vill vi skapa anpassade felmeddelanden. Vanligtvis är de avsedda för scenarier när vi vet att ett problem kan uppstå. Vi kan producera egna anpassade meddelanden som säger att något fel har hänt utan att visa tekniska detaljer. För det använder vi nyckelordet THROW.
BEGIN TRY
IF ( SELECT COUNT(sys.all_objects) > 1 )
THROW ‘More than one object is ALL_OBJECTS system table’
END TRY
BEGIN CATCH
SELECT ERROR_NUMBER() AS ERR_NO
, ERROR_SEVERITY() AS ERR_SEV
, ERROR_STATE() AS ERR_STATE
, ERROR_LINE() AS ERR_LINE
, ERROR_MESSAGE() AS ERR_MESSAGE
END CATCH
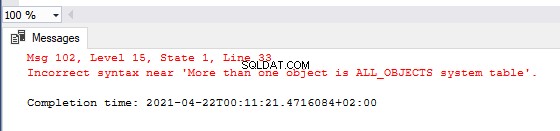
Eller så skulle vi vilja ha en katalog med anpassade felmeddelanden för kategorisering och konsekvens i felövervakning och rapportering. SQL Server tillåter oss att fördefiniera felmeddelandets kod, svårighetsgrad och tillstånd.
En lagrad procedur som kallas "sys.sp_addmessage" används för att lägga till anpassade felmeddelanden. Vi kan använda den för att anropa felmeddelandet på flera ställen.
Vi kan ringa RAISERROR och skicka meddelandenumret som en parameter istället för att hårdkoda samma feldetaljer på flera ställen i koden.
Genom att köra den valda koden underifrån lägger vi till det anpassade felet i SQL Server, höjer det och använder sedan sys.sp_dropmessage för att ta bort det angivna användardefinierade felmeddelandet:
exec sys.sp_addmessage @msgnum=55000, @severity = 11,
@msgtext = 'My custom error message'
GO
RAISERROR(55000,11,1)
GO
exec sys.sp_dropmessage @msgnum=55000
GO
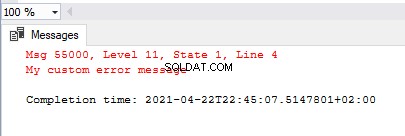
Vi kan också se alla meddelanden i SQL Server genom att köra frågeformuläret nedan. Vårt anpassade felmeddelande är synligt som det första objektet i resultatuppsättningen:
SELECT * FROM master.dbo.sysmessages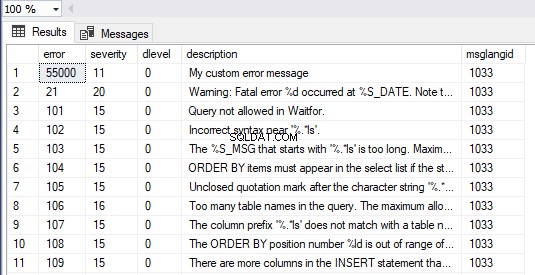
Skapa ett system för att logga fel
Det är alltid användbart att logga fel för senare felsökning och bearbetning. Du kan också sätta triggers på dessa loggade tabeller och till och med skapa ett e-postkonto och vara lite kreativ när det gäller att meddela folk när ett fel uppstår.
För att logga fel skapar vi en tabell som heter DBError_Log , som kan användas för att lagra loggdata:
CREATE TABLE DBError_Log
(
DBError_Log_ID INT IDENTITY(1, 1) PRIMARY KEY,
UserName VARCHAR(100),
ErrorNumber INT,
ErrorState INT,
ErrorSeverity INT,
ErrorLine INT,
ErrorProcedure VARCHAR(MAX),
ErrorMessage VARCHAR(MAX),
ErrorDateTime DATETIME
);
För att simulera loggningsmekanismen skapar vi GenError lagrad procedur som genererar Division med noll fel och loggar felet till DBError_Log tabell:
CREATE PROCEDURE dbo.GenError
AS
BEGIN TRY
SELECT 1/0
END TRY
BEGIN CATCH
INSERT INTO dbo.DBError_Log
VALUES
(SUSER_SNAME(),
ERROR_NUMBER(),
ERROR_STATE(),
ERROR_SEVERITY(),
ERROR_LINE(),
ERROR_PROCEDURE(),
ERROR_MESSAGE(),
GETDATE()
);
END CATCH
GO
EXEC dbo.GenError
SELECT * FROM dbo.DBError_Log
DBError_Log Tabellen innehåller all information vi behöver för att felsöka felet. Det ger också ytterligare information om proceduren som orsakade felet. Även om detta kan verka som ett trivialt exempel, kan du utöka den här tabellen med ytterligare fält eller använda den för att fylla den med specialskapade undantag.
Slutsats
Om vi vill underhålla och felsöka applikationer vill vi åtminstone rapportera att något gick fel och även logga det under huven. När vi har en applikation på produktionsnivå som används av miljontals användare, är konsekvent och rapporterbar felhantering nyckeln för att felsöka problem under körning.
Även om vi kunde logga det ursprungliga felet till databasens fellogg, bör användarna se ett mer vänligt meddelande. Därför skulle det vara en bra idé att implementera anpassade felmeddelanden som skickas till anropande applikationer.
Vilken design du än implementerar måste du logga och hantera användar- och systemundantag. Denna uppgift är inte svår med SQL Server, men du måste planera den från början.
Att lägga till felhanteringsoperationer på databaser som redan körs i produktionen kan innebära allvarlig kodrefaktorering och svåra att hitta prestandaproblem.