Vilka problem kommer vi att överväga?
Om servern meddelar "det finns inget mer utrymme på E-enheten" - behövs ingen djup analys. Vi tar inte hänsyn till fel, vars lösning är uppenbar från texten i meddelandet och för vilka Google omedelbart skickar en länk till MSDN med lösningen.
Låt oss undersöka de problem som inte är uppenbara för Google, som till exempel en plötslig nedgång i prestanda eller frånvaro av anslutning. Tänk på de viktigaste verktygen för anpassning och analys. Låt oss se var loggarna och annan användbar information finns. Jag ska faktiskt försöka samla all nödvändig information i en artikel för en snabbstart.
Först av allt
Vi kommer att börja med de vanligaste frågorna och överväga dem separat.
Om din databas plötsligt, utan uppenbar anledning, började fungera långsamt, men du inte hade ändrat någonting – uppdatera först och främst statistiken och bygg om indexen.
På Internet finns det massor av metoder som denna, exempel på skript tillhandahålls. Jag kommer att anta att alla dessa metoder är för proffs. Tja, jag ska beskriva det enklaste sättet:du behöver bara en mus för att implementera det.
Förkortningar
- SSMS är en applikation av Microsoft SQL Server Management Studio. Från och med 2016-versionen är den tillgänglig gratis på MS-webbplatsen som en fristående applikation. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler är en applikation av "SQL Server Profiler" installerad med SSMS.
- Performance Monitor är en snap-in till kontrollpanelen som låter dig övervaka prestandaräknare, logga och se historik över mätningar.
Statistikuppdatering med hjälp av en "serviceplan":
- kör SSMS;
- anslut till en nödvändig server;
- expandera trädet i Object Inspector:Management\Maintenance Plans (Service Plans);
- högerklicka på noden och välj "Maintenance Plan Wizard";
- markera de nödvändiga uppgifterna i guiden:bygga om index och uppdatera statistik
- du kan markera båda uppgifterna samtidigt eller göra två underhållsplaner med en uppgift i varje (se "viktiga anteckningar" nedan);
- Vidare kontrollerar en obligatorisk DB (eller flera databaser). Vi gör detta för varje uppgift (om två uppgifter väljs kommer det att finnas två dialogrutor med valet av en databas);
- Nästa, Nästa, Slutför.
Efter dessa åtgärder kommer en "underhållsplan" att skapas (ej exekverad). Du kan köra det manuellt genom att högerklicka på det och välja "Execute". Alternativt kan du konfigurera lanseringen via SQL Agent.
Viktiga anmärkningar:
- Att uppdatera statistik är en icke-blockerande operation. Du kan utföra det i ett arbetsläge.
- Återuppbyggnad av index är en blockerande operation. Du kan bara köra den utanför arbetstid. Det finns ett undantag - Enterprise-utgåvan av servern tillåter exekvering av en "online-ombyggnad". Det här alternativet kan aktiveras i uppgiftsinställningarna. Observera att det finns en bock i alla utgåvor, men det fungerar bara i Enterprise.
- Självklart måste dessa uppgifter utföras regelbundet. Jag föreslår ett enkelt sätt att avgöra hur ofta du gör detta:
– Med de första problemen, verkställ underhållsplanen;
– Om det hjälpte, vänta tills problemen uppstår igen (vanligtvis till nästa månadsavslutning/löneberäkning/ etc. av bulktransaktioner);
– Den resulterande perioden för en normal operation kommer att vara din referenspunkt;
– Konfigurera till exempel genomförandet av underhållsplanen dubbelt så ofta.
Servern är långsam – vad ska du göra?
Resurserna som används av servern
Som alla andra program behöver servern processortid, data på disken, mängden RAM och nätverksbandbredd.
Task Manager hjälper dig att bedöma bristen på en given resurs i den första uppskattningen, oavsett hur hemskt det kan låta.
CPU Ladda
Även en skolpojke kan kontrollera användningen i Manager. Vi behöver bara se till att om processorn är laddad så är det sqlserver.exe-processen.
Om detta är ditt fall måste du gå till analysen av användaraktivitet för att förstå exakt vad som orsakade belastningen (se nedan).
Skiva Loa d
Många tittar bara på CPU-belastningen men glömmer att DBMS är ett datalager. Datavolymerna växer, processorns prestanda ökar samtidigt som hårddiskens hastighet är i stort sett densamma. Med SSD:er är situationen bättre, men att lagra terabyte på dem är dyrt.
Det visar sig att jag ofta stöter på situationer där disksystemet blir flaskhalsen, snarare än processorn.
För diskar är följande mätvärden viktiga:
- genomsnittlig kölängd (utestående I/O-operationer, antal);
- läs-skrivhastighet (i Mb/s).
Serverversionen av Task Manager, som regel (beroende på systemversion), visar båda. Om inte, kör snapin-modulen Performance Monitor (systemmonitor). Vi är intresserade av följande räknare:
- Fysisk (logisk) disk/Genomsnittlig läs- (skriv)tid
- Fysisk (logisk) disk/Genomsnittlig diskkölängd
- Fysisk (logisk) disk/diskhastighet
För mer information kan du läsa tillverkarens manualer, till exempel här:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
Kort sagt:
- Kön bör inte överstiga 1. Korta skurar är tillåtna om de snabbt avtar. Burstarna kan vara olika beroende på ditt system. För en enkel RAID-spegel av två hårddiskar – är kön på mer än 10-20 ett problem. För ett coolt bibliotek med supercaching såg jag skurar på upp till 600-800 som omedelbart löstes utan att orsaka förseningar.
- Den normala växelkursen beror också på typen av disksystem. Den vanliga (stationära) hårddisken sänder i 50-100 MB/s. Ett bra diskbibliotek – med 500 MB/s och mer. För små slumpmässiga operationer är hastigheten lägre. Detta kan vara din referenspunkt.
- Dessa parametrar måste betraktas som en helhet. Om ditt bibliotek sänder 50MB/s och en kö med 50 operationer ställer upp — uppenbarligen är något fel med hårdvaran. Om kön ställs upp när överföringen är nära ett maximum – med största sannolikhet är det inte skivorna att skylla på – de kan bara inte göra mer – måste vi leta efter ett sätt att minska belastningen.
- Lastningen bör kontrolleras separat på diskar (om det finns flera av dem) och jämföras med platsen för serverfiler. Aktivitetshanteraren kan visa de mest aktivt använda filerna. Detta kan användas för att säkerställa att belastningen orsakas av DBMS.
Vad kan orsaka problem med disksystemet:
- problem med hårdvara
- cachen brändes ut, prestandan sjönk dramatiskt;
- disksystemet används av något annat;
- RAM-brist. Byte. Сaching försämrades, prestanda sjönk (se avsnittet om RAM nedan).
- Användarbelastningen ökade. Det är nödvändigt att utvärdera användarnas arbete (problematisk fråga/ny funktionalitet/ökning av antalet användare/ökning av mängden data/etc).
- Databasdatafragmentering (se indexombyggnaden ovan), systemfilfragmentering.
- Disksystemet har nått sin maximala kapacitet.
När det gäller det sista alternativet – kasta inte ut hårdvaran på en gång. Ibland kan du få ut lite mer av systemet om du närmar dig problemet på ett klokt sätt. Kontrollera platsen för systemfilerna för att uppfylla de rekommenderade kraven:
- Blanda inte OS-filer med databasdatafiler. Lagra dem på olika fysiska medier så att systemet inte konkurrerar med DBMS för I/O.
- Databasen består av två filtyper:data (*.mdf, *.ndf) och loggar (*.ldf).
Datafiler, som regel, används mest för läsning. Loggar tjänar till skrivning (där skrivningen sker i följd). Det rekommenderas därför att lagra loggar och data på olika fysiska medier så att loggningen inte avbryter dataläsningen (som regel har skrivoperationen företräde framför läsning). - MS SQL kan använda "temporära tabeller" för frågebehandling. De lagras i tempdb-systemets databas. Om du har en hög belastning på filerna i den här databasen kan du försöka rendera den på fysiskt separata media.
För att sammanfatta problemet med filplacering, använd principen om "dela och erövra". Utvärdera vilka filer som nås och försök distribuera dem till olika media. Använd också funktionerna i RAID-system. Till exempel är RAID-5-läsningar snabbare än skrivningar – vilket är bra för datafiler.
Låt oss utforska hur man hämtar information om användarprestanda:vem gör vad och hur mycket resurser som förbrukas
Jag delade upp uppgifterna att granska användaraktivitet i följande grupper:
- Uppgifter att analysera en viss begäran.
- Uppgifter att analysera belastning från applikationen under specifika förhållanden (till exempel när en användare klickar på en knapp i ett tredjepartsprogram som är kompatibelt med databasen).
- Uppgifter att analysera den nuvarande situationen.
Låt oss överväga var och en av dem i detalj.
Varning
Prestandaanalysen kräver en djup förståelse av strukturen och principerna för driften av databasservern och operativsystemet. Det är därför du inte blir proffs av att bara läsa dessa artiklar.
De övervägda kriterierna och räknarna i verkliga system beror mycket på varandra. Till exempel orsakas en hög hårddiskbelastning ofta av brist på RAM. Även om du gör några mätningar räcker inte detta för att bedöma problemen rimligt.
Syftet med artiklarna är att introducera det väsentliga om enkla exempel. Du bör inte betrakta mina rekommendationer som en guide. Jag rekommenderar att du använder dem som träningsuppgifter som kan förklara tankeflödet.
Jag hoppas att du kommer att lära dig hur du rationaliserar dina slutsatser om serverns prestanda i siffror.
Istället för att säga "servern saktar ner", kommer du att ange specifika värden för specifika indikatorer.
Analysera ett P artikulär R equest
Den första punkten är ganska enkel, låt oss uppehålla oss kort. Vi kommer att överväga några mindre uppenbara frågor.
Utöver frågeresultat, tillåter SSMS att hämta ytterligare information om frågekörningen:
- Du kan erhålla frågeplanen genom att klicka på knapparna "Visa beräknad exekveringsplan" och "Inkludera faktisk exekveringsplan". Skillnaden mellan dem är att uppskattningsplanen är uppbyggd utan att en fråga körs. Således kommer informationen om antalet behandlade rader att uppskattas. I själva planen kommer det att finnas både uppskattade och faktiska data. Starka skillnader mellan dessa värden tyder på att statistiken inte är relevant. Analysen av planen är dock ett ämne för en annan artikel – än så länge kommer vi inte att gå djupare.
- Vi kan få mått på processorkostnader och diskdrift på servern. För att göra detta är det nödvändigt att aktivera alternativet SET. Du kan göra det antingen i dialogrutan "Frågealternativ" så här:
Eller med de direkta SET-kommandona i frågan:
SET STATISTICS IO ON
SET STATISTICS TIME ON
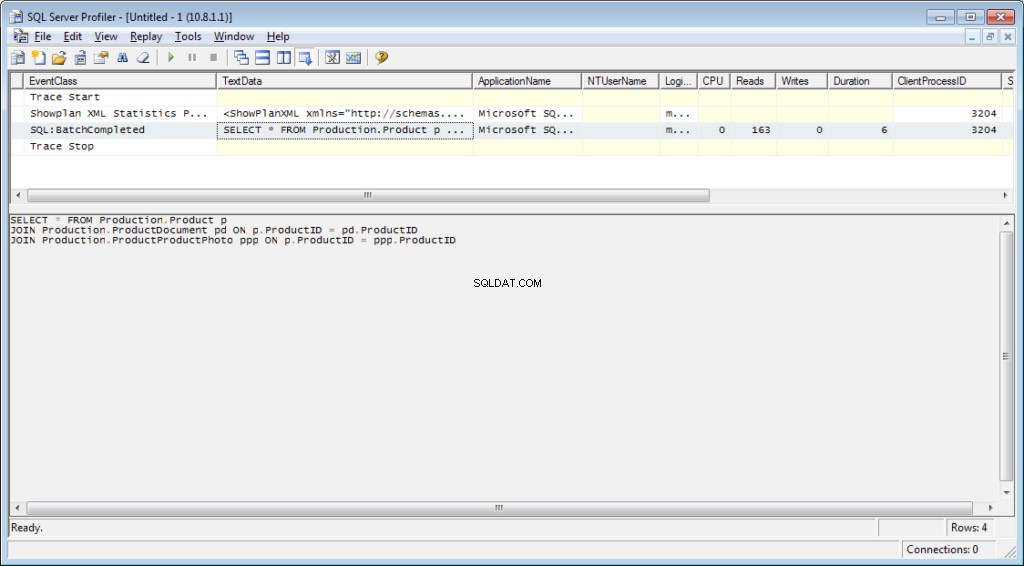
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDSom ett resultat kommer vi att få data om den tid som spenderas på kompilering och exekvering, såväl som antalet diskoperationer.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Jag skulle vilja göra dig uppmärksam på kompileringstiden, logiska läsningar 96 och fysiska läsningar 5. När du kör samma fråga för andra gången och senare kan fysiska läsningar minska och omkompilering kanske inte krävs. På grund av detta händer det ofta att frågan exekveras snabbare under andra och efterföljande gånger än för första gången. Anledningen, som du förstår, ligger i cachelagring av data och kompilerade frågeplaner.
- Knappen «Inkludera klientstatistik» visar information om nätverksutbyte, mängden utförda operationer och total exekveringstid, inklusive kostnaderna för nätverksutbyte och bearbetning av en klient. Exemplet visar att det tar längre tid att köra frågan för första gången:
- I SSMS 2016 finns knappen "Inkludera Live Query Statistics". Den visar bilden som i fallet med frågeplanen men innehåller de icke-slumpmässiga siffrorna i de bearbetade raderna, som ändras på skärmen medan frågan utförs. Bilden är mycket tydlig – blinkande pilar och löpande siffror kan du direkt se var tiden är bortkastad. Knappen fungerar även för SQL Server 2014 och senare.
För att sammanfatta:
- Kontrollera CPU-kostnaderna med SET STATISTICS TIME ON.
- Diskoperationer:SÄTT PÅ STATISTIK IO. Glöm inte att logisk läsning är en läsoperation som slutförs i diskcachen utan att fysiskt komma åt disksystemet. "Fysisk läsning" tar mycket mer tid.
- Utvärdera volymen nätverkstrafik med hjälp av «Inkludera klientstatistik».
- Analysera algoritmen för exekvering av frågan genom exekveringsplanen med hjälp av «Inkludera faktisk exekveringsplan» och «Inkludera statistik för direkt fråga».
Analysera applikationsbelastningen
Här kommer vi att använda SQL Server Profiler. Efter att ha startat och anslutit till servern är det nödvändigt att välja logghändelser. För att göra detta, kör profilering med en standard spårningsmall. På Allmänt fliken i Använd mallen väljer du Standard (standard) och klicka på Kör .
Det mer komplicerade sättet är att lägga till/släppa filter eller händelser till/från den valda mallen. Dessa alternativ kan hittas på den andra fliken i dialogmenyn. För att se hela utbudet av möjliga händelser och kolumner att välja, välj Visa alla händelser och Visa alla kolumner kryssrutor.

Vi kommer att behöva följande händelser:
- Lagrade procedurer \ RPC:Completed
- TSQL \ SQL:BatchCompleted
Dessa händelser övervakar alla externa SQL-anrop till servern. De visas efter att frågebehandlingen är klar. Det finns liknande händelser som håller reda på SQL Server-starten:
- Lagrade procedurer \ RPC:Startar
- TSQL \ SQL:BatchStarting
Vi behöver dock inte dessa procedurer eftersom de inte innehåller information om serverresurserna som spenderas på frågekörningen. Det är uppenbart att sådan information är tillgänglig först efter att exekveringsprocessen har slutförts. Således kommer kolumner med data om CPU, Läser, Skriver i *Starthändelser att vara tomma.
Följande händelser kan också intressera oss, men vi kommer inte att aktivera dem än så länge:
- Lagrade procedurer \ SP:Starting (*Completed) övervakar det interna anropet till den lagrade proceduren inte från klienten, utan inom den aktuella begäran eller annan procedur.
- Lagrade procedurer \ SP:StmtStarting (*Completed) spårar början av varje sats inom den lagrade proceduren. Om det finns en cykel i proceduren kommer antalet händelser för kommandona i cykeln att vara lika med antalet iterationer i cykeln.
- TSQL \ SQL:StmtStarting (*Completed) övervakar starten av varje sats inom SQL-batchen. Om det finns flera kommandon i din fråga kommer vart och ett av dem att innehålla en händelse. Det fungerar alltså för kommandona som finns i frågan.
Dessa händelser är praktiska för att övervaka exekveringsprocessen.
Av C olumner
Vilka kolumner som ska väljas framgår av knappens namn. Vi kommer att behöva följande:
- TextData, BinaryData innehåller frågetexten.
- CPU, läser, skriver, varaktighet visar resursförbrukningsdata.
- StartTime, EndTime är tiden för att starta och avsluta exekveringsprocessen. De är bekväma att sortera.
Lägg till andra kolumner baserat på dina preferenser.
Kolumnfiltren... knappen öppnar dialogrutan för att konfigurera händelsefilter. Om du är intresserad av den specifika användarens aktivitet kan du ställa in filtret med SID-nummer eller användarnamn. Tyvärr, i fallet med att ansluta appen via app-servern med hjälp av anslutningar, blir övervakningen av den specifika användaren mer komplicerad.
Du kan använda filter för att endast välja komplicerade frågor (Duration>X), frågor som orsakar intensiv skrivning (Writes>Y), såväl som urval av frågeinnehåll, etc.
Vad mer behöver vi av profileraren? Självklart utförandeplanen!
Det är nödvändigt att lägga till händelsen «Performance \ Showplan XML Statistics Profile» i spårningen. När vi kör vår fråga får vi följande bild:
Frågetexten:
Utförandeplanen:
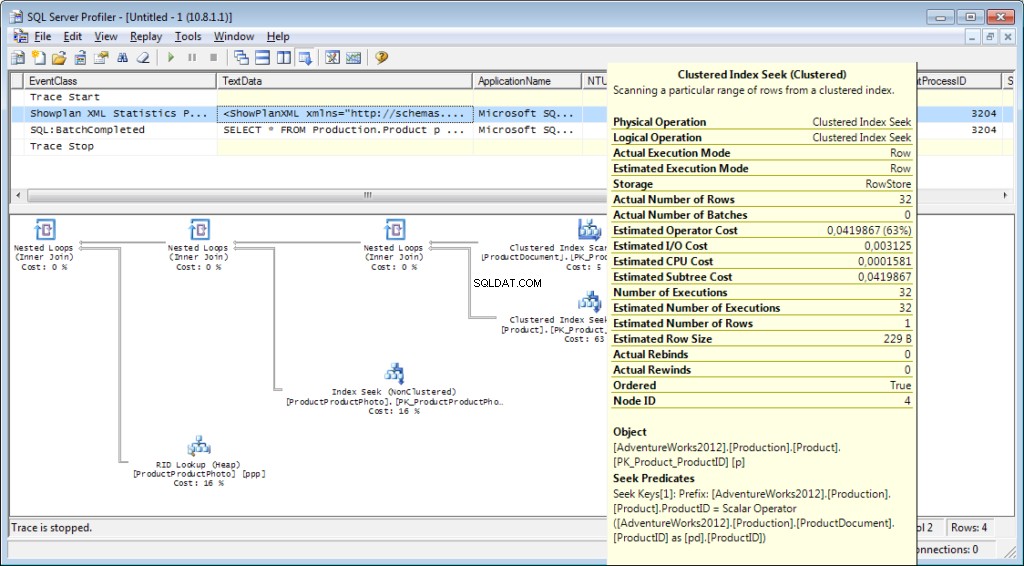
Och det är inte allt
Det är möjligt att spara ett spår till en fil eller en databastabell. Spårningsinställningar kan lagras som en personlig mall för en snabb löpning. Du kan köra spårningen utan en profilerare genom att helt enkelt använda en T-SQL-kod och procedurerna sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Du kan hitta ett exempel här. Detta tillvägagångssätt kan till exempel vara användbart för att automatiskt börja lagra en spårning till en fil enligt ett schema. Du kan ha en smygande titt på profileraren för att se hur du använder dessa kommandon. Du kan köra två spår och i en av dem spåra vad som händer när den andra startar. Kontrollera att det inte finns något filter i kolumnen "ApplicationName" på själva profileraren.
Listan över händelser som övervakas av profileraren är mycket stor och är inte begränsad till att ta emot frågetexter. Det finns evenemang som spårar fullskanning, omkompilering, autogrow, dödläge och mycket mer.
Analysera användaraktivitet på servern
Det finns olika situationer. En fråga kan hänga på "exekvering" under lång tid och det är oklart om den kommer att slutföras eller inte. Jag skulle vilja analysera den problematiska frågan separat; Vi måste dock först bestämma vad frågan är. Det är meningslöst att fånga det med en profilerare – vi har redan missat startevenemanget och det är inte klart hur länge vi ska vänta på att processen ska slutföras.
Låt oss reda ut det
Du kanske har hört talas om "Activity Monitor". Dess högre utgåvor har riktigt rik funktionalitet. Hur kan det hjälpa oss? Activity Monitor innehåller många användbara och intressanta funktioner. Vi kommer att få allt vi behöver från systemvyer och funktioner. Monitorn i sig är användbar eftersom du kan ställa in profileraren på den och se vilka frågor den utför.
Vi behöver:
- dm_exec_sessions tillhandahåller information om anslutna användares sessioner. I vår artikel är de användbara fälten de som identifierar en användare (login_name, login_time, host_name, program_name, …) och fält med information om förbrukade resurser (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests tillhandahåller information om frågor som körs för tillfället.
- session_id är en identifierare för sessionen för att länka till föregående vy.
- starttid är tiden för visningskörningen.
- kommando är ett fält som innehåller en typ av det körda kommandot. För användarfrågor är det välj/uppdatera/ta bort/
- sql_handle, statement_start_offset, statement_end_offset ger information för att hämta frågetext:handle, samt start- och slutpositionen i texten för frågan, vilket betyder den del som för närvarande körs (för det fall din fråga innehåller flera kommandon).
- plan_handle är ett handtag för den genererade planen.
- blocking_session_id anger numret på sessionen som orsakade blockering om det finns block som förhindrar exekvering av frågan
- wait_type, wait_time, wait_resource är fält med information om orsaken till och varaktigheten av väntan. För vissa typer av väntetider, till exempel datalås, är det nödvändigt att ange ytterligare en kod för den blockerade resursen.
- percent_complete är procentandelen av slutförandet. Tyvärr är det bara tillgängligt för kommandon med ett klart förutsägbart förlopp (till exempel säkerhetskopiering eller återställning).
- cpu_time, reads, writes, logical_reads, granted_query_memory är resurskostnader.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) är funktioner för att hämta texten och exekveringsplanen. Nedan kommer vi att överväga ett exempel på dess användning.
- dm_exec_query_stats är en sammanfattande statistik över exekverande av frågor. Den visar frågan, antalet exekveringar och volymen av använda resurser.
Viktiga anmärkningar
Listan ovan är bara en liten del. En komplett lista över alla systemvyer och funktioner beskrivs i dokumentationen. Det finns också en vacker bild som visar ett diagram över länkar mellan huvudobjekten.
Frågetexten, dess plan och exekveringsstatistik är data som lagras i procedurens cache. De är tillgängliga under utförandet. Då är tillgänglighet inte garanterad och beror på cachebelastningen. Ja, cachen kan rengöras manuellt. Ibland rekommenderas det när genomförandeplanerna "flippade ut". Ändå finns det många nyanser.
"Kommando"-fältet är meningslöst för användarförfrågningar, eftersom vi kan få hela texten. Det är dock mycket viktigt för att få information om systemprocesser. Som regel utför de vissa interna uppgifter och har inte SQL-texten. För sådana processer är informationen om kommandot den enda antydan om aktivitetstypen.
I kommentarerna till förra artikeln var det en fråga om vad servern är inblandad i när den inte borde fungera. Svaret kommer förmodligen att ligga i innebörden av detta fält. I min praktik gav "kommando"-fältet alltid något ganska förståeligt för aktiva systemprocesser:autoshrink / autogrow / checkpoint / logwriter / etc.
Hur man använder det
Vi går till den praktiska delen. Jag kommer att ge flera exempel på dess användning. Servermöjligheterna är inte begränsade – du kan tänka på dina egna exempel.
Exempel 1. Vilken process förbrukar CPU/läser/skriver/minne
Ta först en titt på de sessioner som förbrukar mer resurser, till exempel CPU. Du kan hitta denna information i sys.dm_exec_sessions. Data om CPU, inklusive läsning och skrivning, är dock kumulativ. Det betyder att numret innehåller summan för hela anslutningstiden. Det är klart att användaren som kopplade upp för en månad sedan och inte kopplades bort kommer att ha ett högre värde. Det betyder inte att de överbelastas systemet.
En kod med följande algoritm kan lösa detta problem:
- Gör ett val och lagra det i en tillfällig tabell
- Vänta ett tag
- Gör ett val för andra gången
- Jämför dessa resultat. Deras skillnad kommer att indikera kostnader som spenderas vid steg 2.
- För enkelhetens skull kan skillnaden delas med varaktigheten av steg 2 för att få de genomsnittliga "kostnaderna per sekund".
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Jag använder två tabeller i koden:#tmp – för det första urvalet och #tmp1 – för det andra. Under den första körningen skapar och fyller skriptet #tmp och #tmp1 med ett intervall på en sekund och utför sedan andra uppgifter. Med nästa körningar använder skriptet resultaten från föregående körning som en jämförelsebas. Således kommer varaktigheten av steg 2 att vara lika med längden på din väntetid mellan skriptkörningarna.
Försök att köra det, även på produktionsservern. Skriptet kommer endast att skapa "tillfälliga tabeller" (tillgängliga inom den aktuella sessionen och raderas när det är inaktiverat) och har ingen tråd.
De som inte gillar att köra en fråga i MS SSMS kan slå in den i en applikation skriven på deras favoritprogrammeringsspråk. Jag ska visa dig hur du gör detta i MS Excel utan en enda kodrad.
Anslut till servern i menyn Data. Om du uppmanas att välja en tabell, välj en slumpmässig. Klicka på Nästa och Slutför tills du ser dialogrutan Dataimport. I det fönstret måste du klicka på Egenskaper. I egenskaper är det nödvändigt att ersätta en kommandotyp med SQL-värdet och infoga vår modifierade fråga i kommandotextfältet.
Du måste ändra frågan lite:
- Lägg till «SET NOCOUNT ON»
- Ersätt tillfälliga tabeller med variabla tabeller
- Fördröjningen varar inom 1 sek. Fält med medelvärden krävs inte
Den modifierade frågan för Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Resultat:
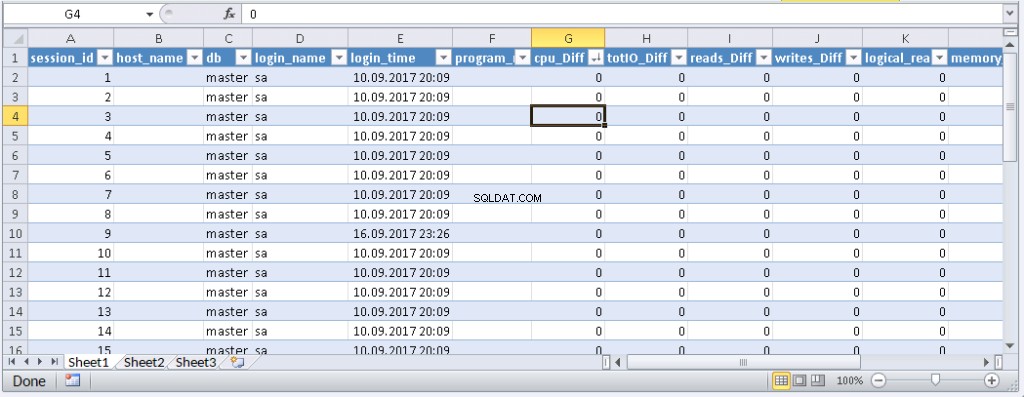
När data visas i Excel kan du sortera dem efter behov. För att uppdatera informationen, klicka på "Uppdatera". I arbetsbokens inställningar kan du sätta "automatisk uppdatering" under en viss tidsperiod och "uppdatera i början". Du kan spara filen och skicka den till dina kollegor. Därför skapade vi ett bekvämt och enkelt verktyg.
Exempel 2. Vad spenderar en session resurser på?
Nu ska vi avgöra vad problemsessionerna faktiskt gör. För att göra detta, använd sys.dm_exec_requests och funktioner för att ta emot frågetext och frågeplan.
Frågan och exekveringsplanen efter sessionsnummer
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Infoga sessionsnumret i frågan och kör den. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Conclusion
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.