När du testar din applikations funktionalitet eller prestandan för en specifik lagrad procedur eller en ad-hoc-fråga i utvecklingsmiljön behöver du ha data lagrad i dina utvecklingsdatabaser som är typiska eller liknande data som lagras i produktionsdatabaserna. Detta beror på att prestandan för en fråga som bearbetar 50 poster kommer att skilja sig från prestandan för samma fråga som bearbetar 50 miljoner rader. Att återställa en kopia av produktionsdatabasen till utvecklingsdatabasservern för teständamål är inte alltid ett giltigt alternativ, på grund av den kritiska data som lagras i dessa databaser och bör inte vara öppen för alla anställda att se, såvida du inte utvecklar en ny applikation och det finns ingen produktionsdatabas ännu.
Det bästa och säkraste alternativet är att fylla utvecklingsdatabastabellerna med testdata. Generering av testdata är användbart för att testa applikationens prestanda eller en ny funktionalitet utan att ändra produktionsdata. Det finns inget enkelt och enkelt sätt att generera testdata som passar alla scenarier, särskilt när du behöver generera stora mängder data för att testa prestandan för komplexa frågor och transaktioner där du bör täcka alla möjliga kombinationer av testfall.
För att fylla en tabell med en stor mängd data är det enklaste sättet att skriva ett enkelt skript som fortsätter att infoga identiska poster i databastabellen med det antal dubbletter du behöver. Men problemet är att SQL Server Query Optimizer kommer att bygga en annan plan på utvecklingsdatabasen än den som är byggd på produktionsdatabasen på grund av skillnaden i datadistributionen. Till exempel kommer skriptet nedan att fylla Studenttabellen med 100 000 redundanta testposter med GO-numret uttalande:
INSERT INTO Students (FirstName, AfterName, BirthDate, STDAddress) VÄRDEN ('John','Horold','2005-10-01','London, St15')GO 25000INSERT INTO Students (Förnamn, Efternamn, Födelsedatum, STDAddress) VÄRDEN ('Mike','Zikle','2005-06-08','London, St18')GO 25000INSERT INTO Students (FirstName, LastName, BirthDate, STDAddress) VALUES ('Faruk','Cedrik',' 2005-03-15','London, St24')GO 25000INSERT INTO Students (Förnamn, Efternamn, Födelsedatum, STDAdress) VÄRDEN ('Faisal','Ali','2005-12-05','London, St41') GO 25000 Ett annat alternativ är att generera slumpmässiga data beroende på datatypen för varje kolumn. ID-kolumnen med IDENTITY-egenskapen genererar automatiskt sekvensnummer utan att du behöver någon kodningsansträngning från din sida. Men om du planerar att generera slumpmässiga betyg för eleverna kan du dra nytta av RAND() T-SQL-funktionen och cast resultatet som den nödvändiga numeriska datatypen. Till exempel kommer skriptet nedan att generera 100 000 slumpmässiga betyg för eleven mellan 1 och 100 med tre olika datatyper:INTEGER-betyg, REAL-betyg och DECIMAL-betyg, med möjligheten att kontrollera intervallen för dessa värden beroende på dina matematiska och programmeringsfärdigheter , som visas nedan:
INSERT INTO StudentsGrades (STDGrade) VALUES (CAST(RAND(CHECKSUM(NEWID()))*100 as int)) AS INT_GrageGO 100000INSERT INTO StudentsGrades (STDGrade) VALUES (CAST(RAND(CHECKSUM(NEWID()) 100 som verklig)) AS Real_GrageGO 100000INSERT INTO StudentsGrades (STDGrade) VALUES (CAST(RAND(CHECKSUM(NEWID()))*100 som decimal(6,2))) AS Decimal_GrageGO 100000
Generering av slumpmässiga namn kan också uppnås med AdventureWorks och Northwinds Microsofts testdatabaser . Du måste ladda ner dessa databaser från Microsofts webbplats, koppla dessa databaser till din SQL Server-instans och dra nytta av data som lagras i dessa databaser för att generera slumpmässiga namn i din utvecklingsdatabas. DimCustomer-tabellen från AdventureworksDW2016CTP3-databasen innehåller till exempel cirka 18K förnamn, mellannamn och efternamn som du kan använda. Du kan också använda en CROSS JOIN-sats för att generera ett stort antal kombinationer av dessa namn för att överskrida 18K-värdet. Följande skript kan användas för att generera 100K förnamn och efternamn:
INSERT INTO StudentsGrades (First_Name, Last_Name)SELECT TOP 100000 N.[FirstName],cN.[LastName]FRÅN AdventureworksDW2016CTP3.[dbo].[DimCustomer] NCROSS JOIN AdventureworksDW2016]CTP3.[DimCustomer]>Slumpmässiga e-postadresser och datum kan också genereras från Microsofts testdatabaser. Till exempel kan kolumnen BirthDate och EmailAddress från samma DimCustomer-tabell ge oss slumpmässiga datum och e-postadresser. Skriptet nedan kan användas för att generera 100 000 kombinationer av födelsedatum och e-postadresser:
INSERT INTO StudentsGrades (Födelsedatum, EmailAddress)SELECT TOP 100000 N.BirthDate,cN.EmailAddressFROM AdventureworksDW2016CTP3.[dbo].[DimCustomer] NCROSS JOIN AdventureworksDW2016]CTP3.[imCbous.[imCbous.Slumpmässiga värden i kolumnen Land kan också genereras med hjälp av tabellen Person.CountryRegion från testdatabasen AdventureWorks2016CTP3. Den kan ge dig mer än 200 landsnamn och koder som du kan dra nytta av i din utvecklingsdatabas. Du kan till exempel ta det som en uppslagstabell för att mappa mellan landsnamn och kod, som i skriptet nedan:
INSERT INTO MappedConutries (CountryRegionCode, Name)VÄLJ [CountryRegionCode],[Name]FRÅN [AdventureWorks2016CTP3].[Person].[CountryRegion]Sätt sedan in ett slumpmässigt namn eller landskod från dessa länder som har ID som är lika med ett slumpmässigt ID genereras mellan 1 och 238, som skriptet nedan:INSERT INTO StudentsGrades (Country_Name) values( (SELECT NAME FROM MappedConutries WHERE ID=CAST(RAND(CHECKSUM(NEWID()))*238 as int)))GO 10000För att generera slumpmässiga adressvärden kan du dra nytta av data som lagras i Personen. Adresstabell från testdatabasen AdventureWorks2016CTP3. Den innehåller mer än 19K olika adresser med sin rumsliga plats, som du enkelt kan använda i din utvecklingsdatabas och ta en slumpmässig kombination från dessa värden, på samma sätt som vi gjorde i föregående exempel. Skriptet nedan kan enkelt användas för att generera slumpmässiga 100K adresser från tabellen Person.Address:
INSERT INTO StudentsGrades (STD_Address) värden( (VÄLJ NAMN FRÅN [AdventureWorks2016CTP3].[Person].[Address] WHERE [AddressID]=CAST(RAND(CHECKSUM(NEWID()))*19614 som int)))GO 100 000För att generera slumpmässiga lösenord för specifika systemanvändare kan vi dra nytta av CRYPT_GEN_RANDOM T-SQL-funktion. Denna funktion returnerar ett kryptografiskt, slumpmässigt genererat hexadecimalt tal med en längd av ett specificerat antal byte, genererat av Crypto API (CAPI). Värdet som returneras från den funktionen kan konverteras till en VARCHAR-datatyp för att få mer meningsfulla lösenord, som i skriptet nedan, som genererar 100K slumpmässigt lösenord:
INSERT INTO SystemUsers (User_Password) SELECT CONVERT(varchar(20), CRYPT_GEN_RANDOM(20))GO 100000Generering av testdata för att fylla utvecklingsdatabasens tabeller kan också utföras enkelt och utan att slösa tid på att skriva skript för varje datatyp eller använda tredjepartsverktyg. Du kan hitta olika verktyg på marknaden som kan användas för att generera testdata. Ett av dessa underbara verktyg är dbForge Data Generator för SQL Server . Det är ett kraftfullt GUI-verktyg för en snabb generering av meningsfulla testdata för utvecklingsdatabaserna. dbForge datagenereringsverktyg inkluderar 200+ fördefinierade datageneratorer med vettiga konfigurationsalternativ som låter dig emulera kolumnintelligenta slumpmässiga data. Verktyget gör det också möjligt att generera demodata för SQL Server-databaser som redan är fyllda med data och skapa dina egna anpassade testdatageneratorer. dbForge Data Generator för SQL Server kan spara tid och ansträngning för att generera demodata genom att fylla SQL Server-tabeller med miljontals rader med exempeldata som ser ut precis som riktiga data. dbForge Data Generator för SQL Server hjälper till att fylla tabeller med de vanligaste datatyperna som Basic, Business, Health, IT, Plats, Betalning och Persondatatyper. Bilden nedan visar hur enkelt det här verktyget fungerar:
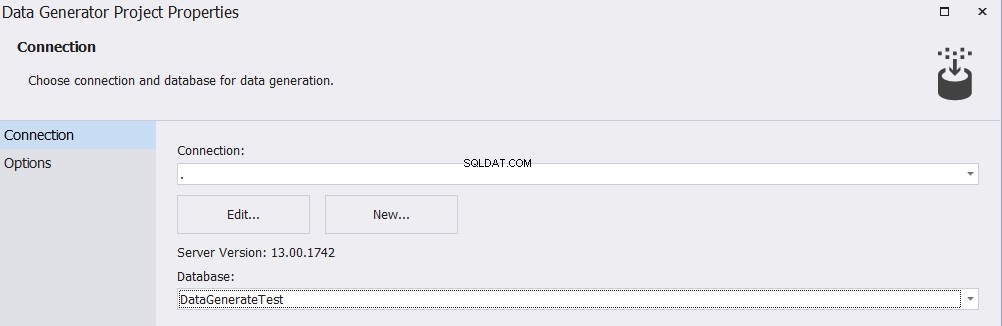
När du har installerat verktyget dbForge Data Generator for SQL Server och kört verktyget måste du ange målserverns namn och databasnamn i anslutningsfönstret enligt nedan:
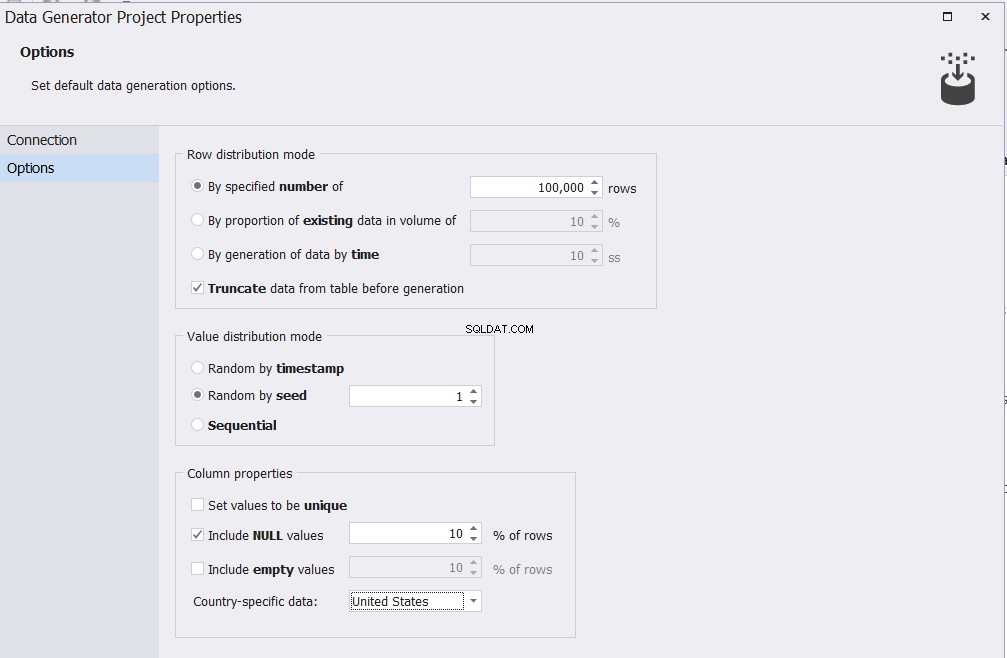
I fönstret Alternativ kan du ange antalet rader som ska infogas i din tabell och andra olika alternativ som styr de genererade testdatakriterierna, som visas nedan:
Efter att ha anpassat alternativen för att passa dina testdatakrav, klicka på
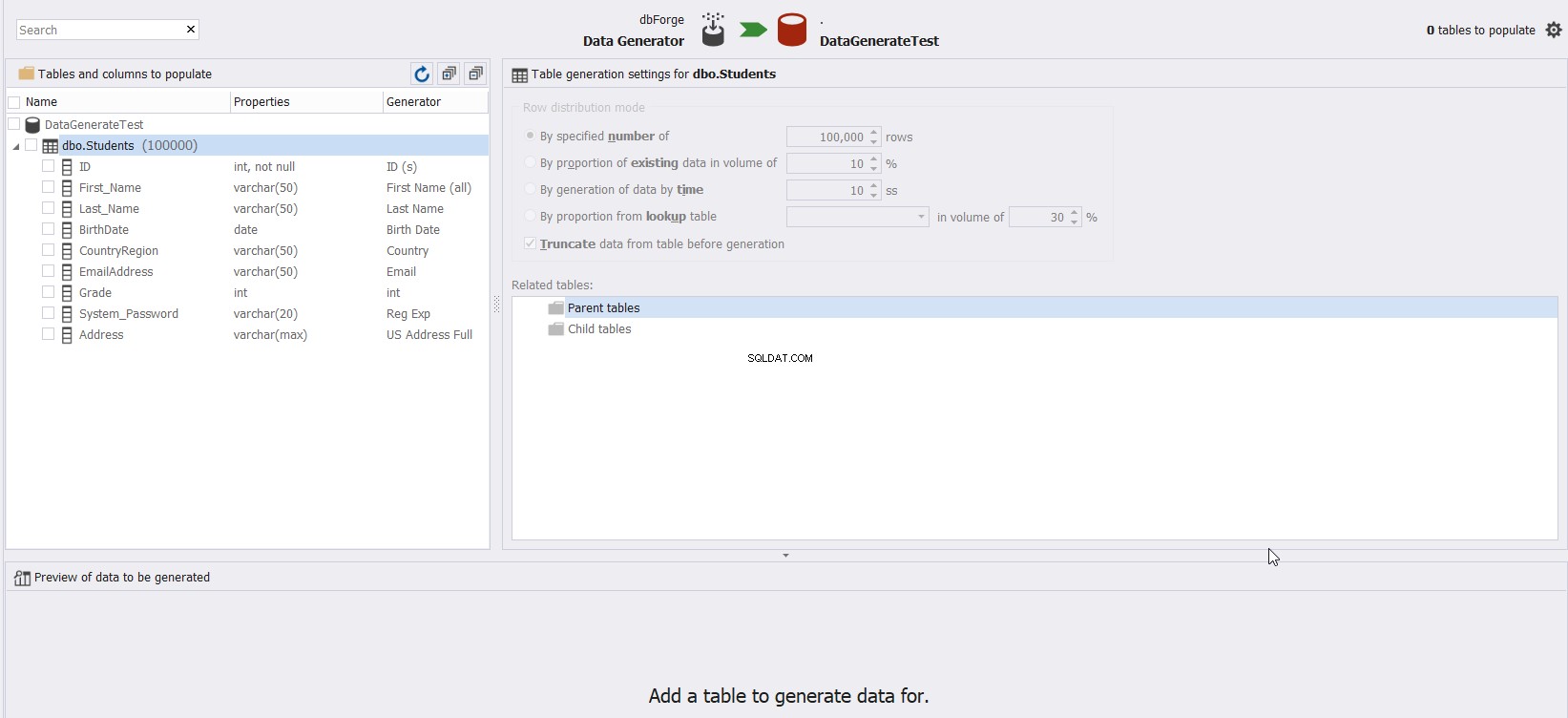
-knappen, och ett nytt fönster med en lista över alla tabeller och kolumner under den valda databasen kommer att visas och frågar du kan välja vilken tabell som ska fyllas med testdata, som visas nedan:
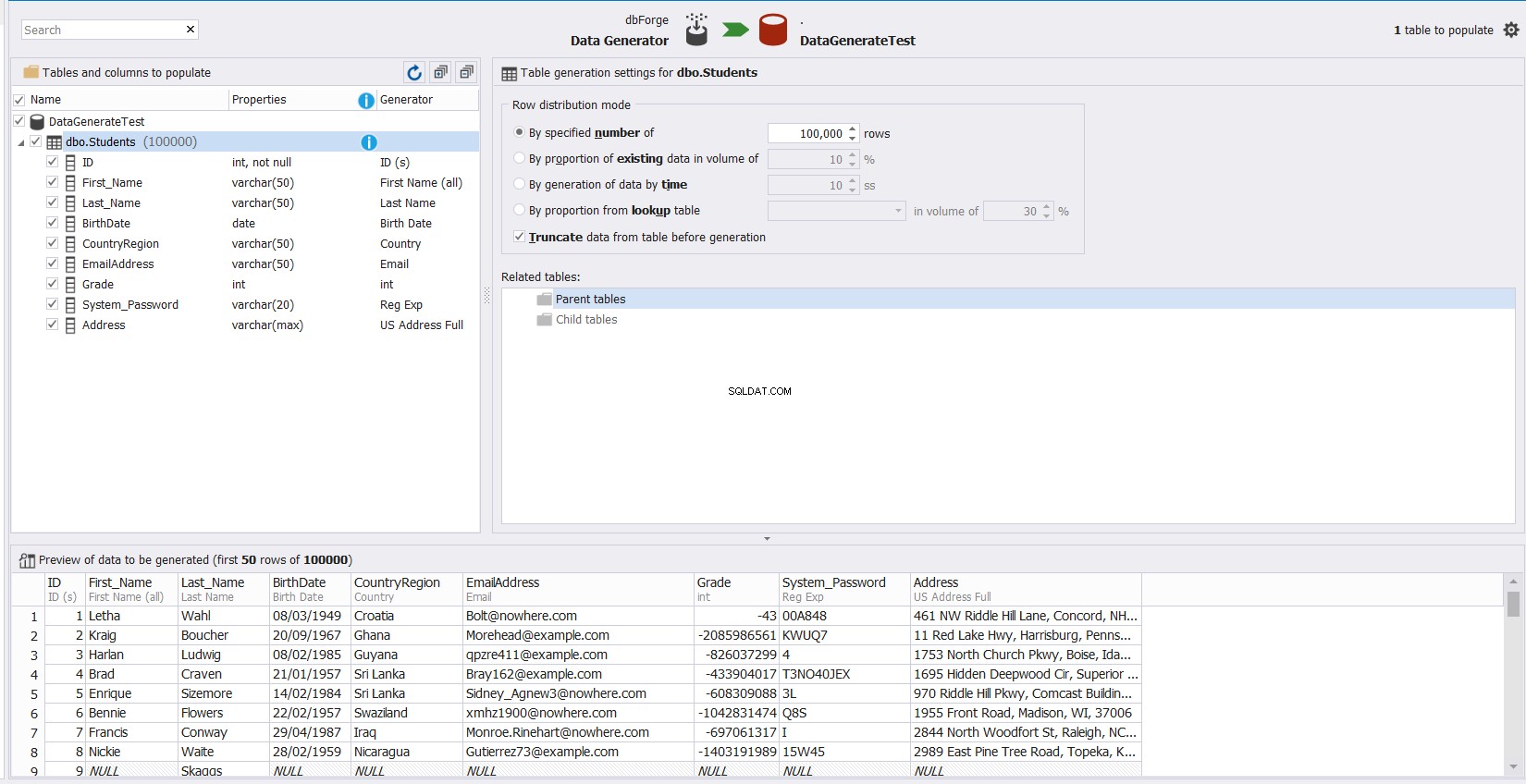
Välj bara den tabell som du behöver fylla med data, så kommer verktyget automatiskt att förse dig med föreslagna data i avsnittet Förhandsgranskning längst ner i fönstret och anpassningsbara alternativ för varje kolumn i den tabellen som du enkelt kan anpassa, som visas nedan:
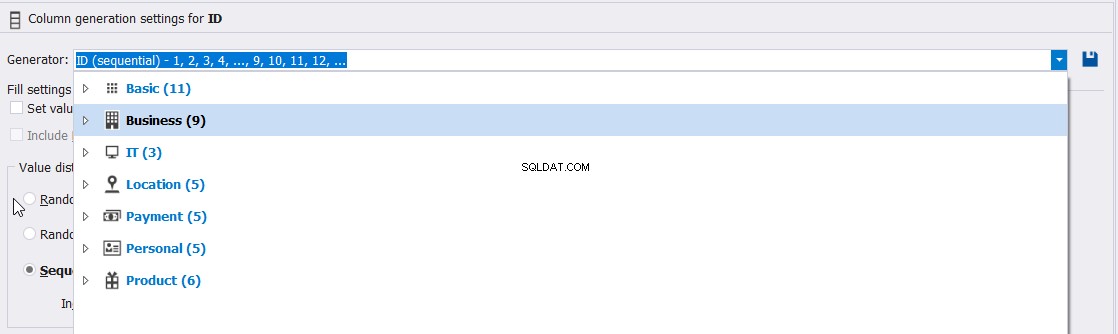
Du kan till exempel välja bland de inbyggda generatorernas datatyper som kan användas för att generera ID-kolumnvärdena som beskrivits tidigare:
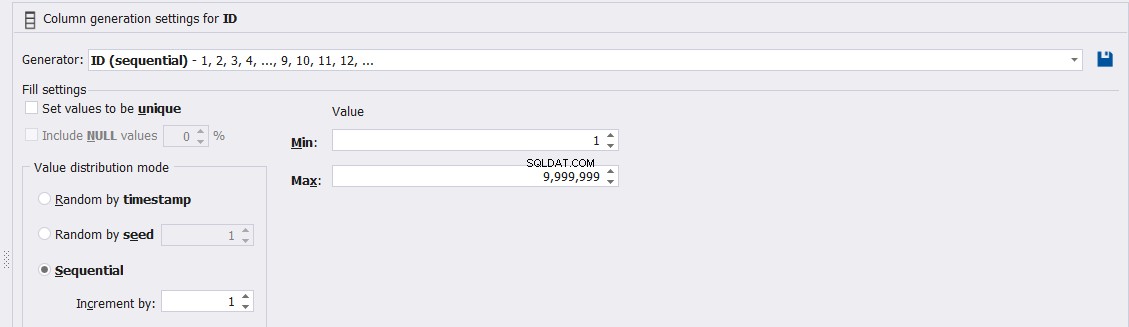
Eller anpassa egenskaperna för dessa ID-kolumnvärden, såsom Uniqueness, Min, Max och ökningen av de genererade värdena, enligt nedan:
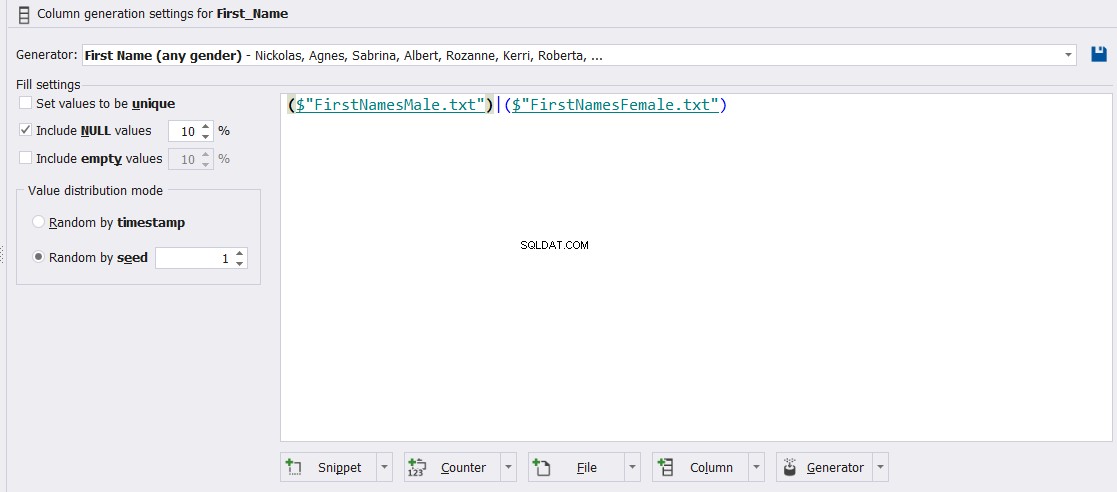
Dessutom kan kolumnen Förnamn begränsas till att vara man eller kvinna eller en kombination av dessa två typer. Du kan också kontrollera procentandelen NULL eller tomma värden i den kolumnen, som visas nedan:
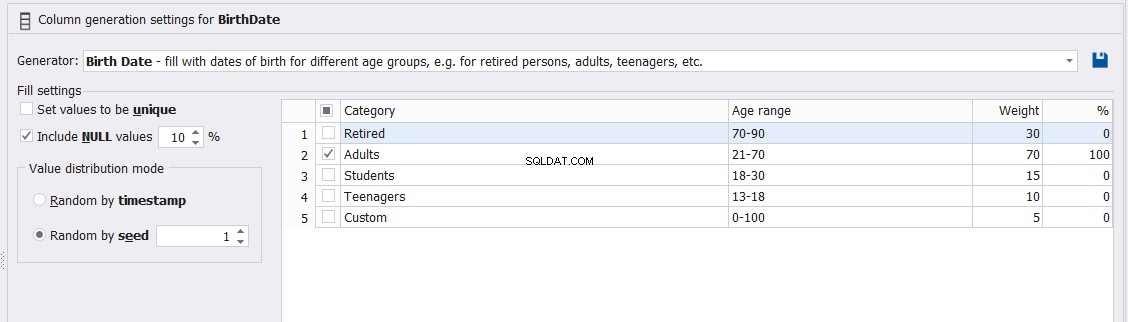
Kolumnen Födelsedatum kan också styras genom att ange kategorin som dessa elever kommer att falla under, till exempel Studenter, Tonåringar, Vuxna eller Pensionerade som visas nedan:
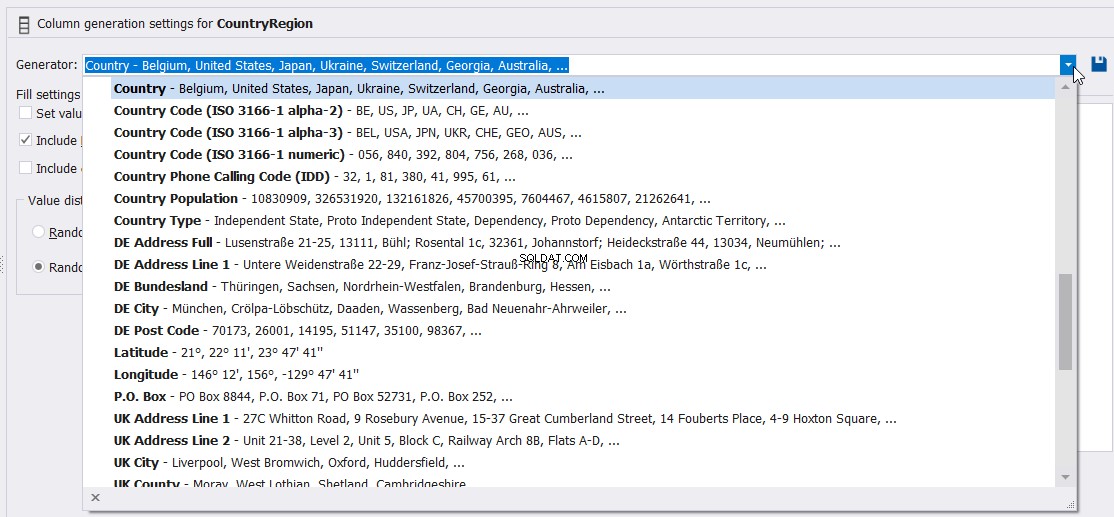
Du kan också ange den fullständigt beskrivna generatorn som kan användas för att generera kolumnvärdena för Land enligt nedan:
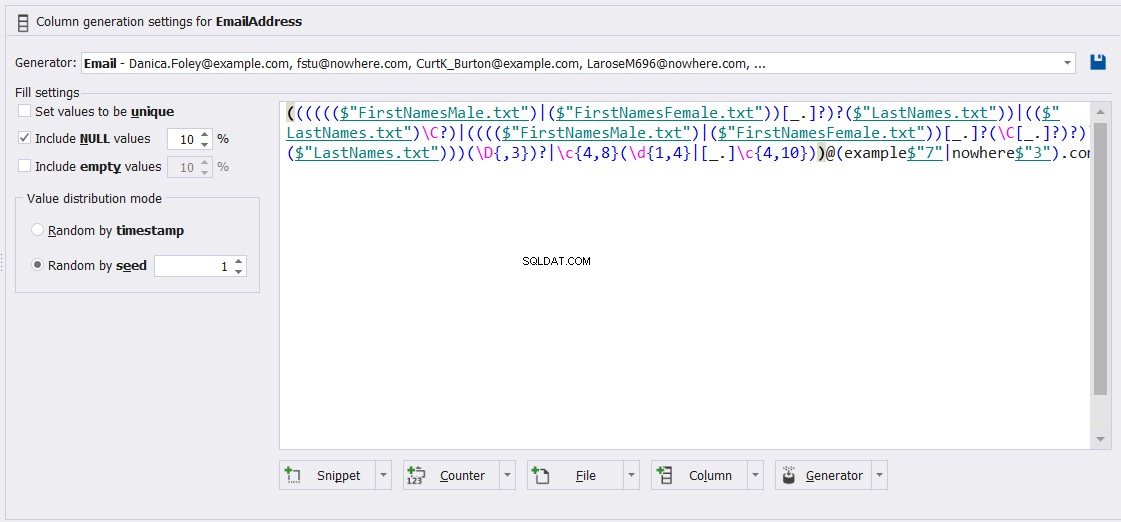
Och anpassa ekvationen som kommer att användas för att generera e-postadresskolumnvärdena enligt följande:
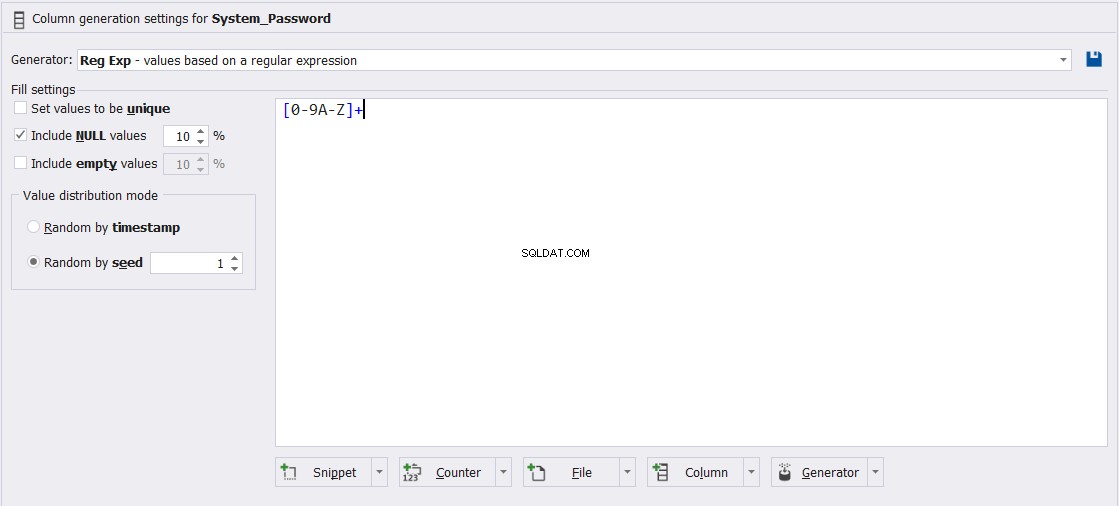
Förutom komplexiteten i den anpassningsbara ekvationen genererar vi lösenordskolumnvärdena, som visas nedan:
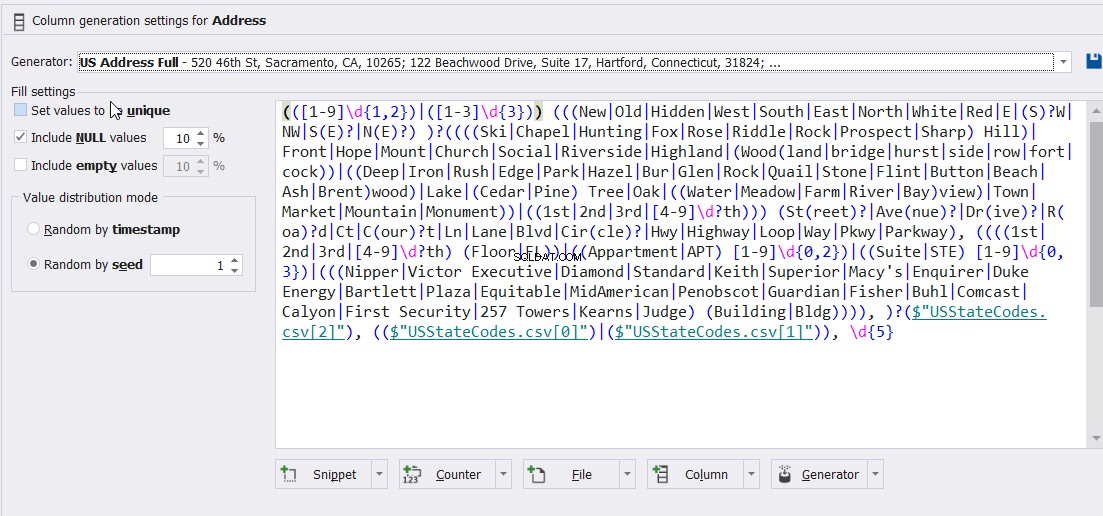
Och slutligen, för mitt exempel och inte för detta magiska verktyg, generatorerna och ekvationerna som används för att generera adresskolumnvärdena nedan:
Efter den här rundturen kan du föreställa dig hur detta magiska verktyg hjälper dig att generera data och simulera realtidsscenarier för att testa din applikations funktionalitet. Installera det och njut av att dra nytta av alla tillgängliga funktioner och alternativ.
Användbart verktyg:
dbForge Data Generator för SQL Server – kraftfullt GUI-verktyg för en snabb generering av meningsfulla testdata för SQL Server-databaser.