Fokus i den här artikeln kommer att ligga på att använda JOINs. Vi kommer att börja med att prata lite om hur JOINs kommer att ske och varför du behöver JOIN-data. Sedan kommer vi att ta en titt på JOIN-typerna som vi har tillgängliga för oss och hur man använder dem.
GÅ MED BASIS
JOINs i TSQL kommer vanligtvis att göras på FROM-raden.
Innan vi kommer till något annat blir den verkliga stora frågan - "Varför måste vi göra JOINs, och hur ska vi faktiskt utföra våra JOINs?"
Som det visar sig kommer varje databas som vi någonsin arbetar med att få sin data uppdelad i flera tabeller. Det finns många olika anledningar till detta:
- Upprätthålla dataintegritet
- Spara lagrat utrymme
- Redigera data snabbare
- Göra frågor mer flexibla
Därför kommer varje databas som du kommer att arbeta med att behöva att data kopplas samman för att det verkligen ska vara vettigt.
Du har till exempel separata tabeller för beställningar och för kunder. Frågan som blir - "Hur kopplar vi ihop all data egentligen?" Det är precis vad JOINs kommer att göra.
HUR ANSLUTNINGAR FUNGERAR
Föreställ dig fallet när vi har två separata bord och dessa tabeller kommer att sammanföras genom att skapa en söm.
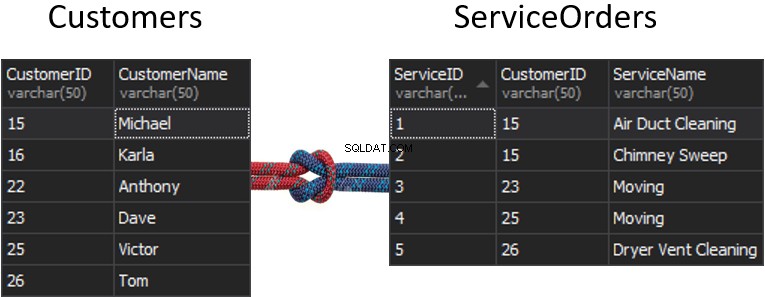
Vad kommer att hända med sömmen, om vi får en kolumn från varje tabell som kommer att användas för matchning, och som kommer att avgöra vilka rader som ska returneras eller inte? Vi har till exempel Kunder till vänster och ServiceOrder till höger. Om vi vill få alla kunder och deras beställningar, måste vi FOGA ihop dessa två bord. För detta måste vi välja en kolumn som fungerar som en söm, och självklart är kolumnen vi ska använda kund-ID.
Kund-ID är förresten känt som en Primärnyckel för den vänstra tabellen, som unikt identifierar varje enskild rad i tabellen Kunder.
I tabellen ServiceOrders har vi också kolumnen CustomerID, som är känd som en Förländsk nyckel . En främmande nyckel är helt enkelt en kolumn som är utformad för att peka på en annan tabell. I vårt fall pekar det tillbaka till tabellen Kunder. Därför är det så vi kommer att sammanföra all denna data genom att tillhandahålla den sömmen.
I dessa tabeller har vi följande matchningar:2 beställningar för 15 och 1 beställning för 23, 25 och 26. 16 och 22 utelämnas.
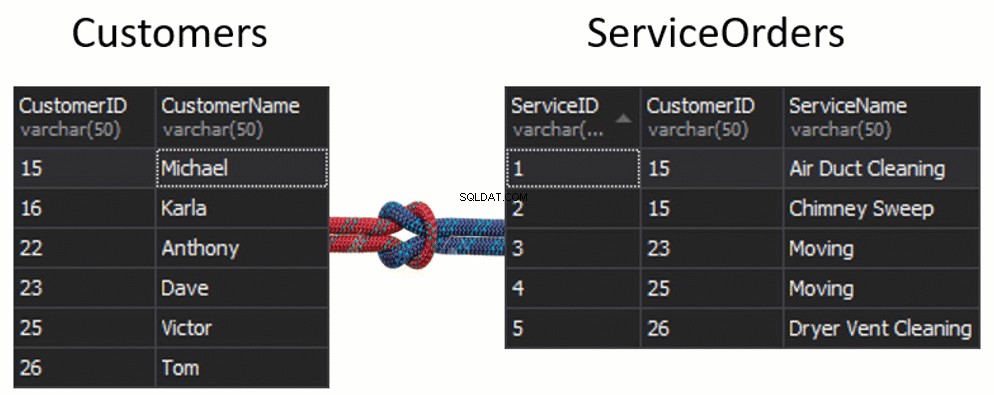
En stor sak att notera här är att vi kan gå med i flera bord . Faktum är att det är ganska vanligt att JOINAR flera tabeller tillsammans, för att få någon form av information. Om du tar en titt på den vanligaste databasen, kan du behöva SLÅ ihop fyra, fem, sex och fler tabeller bara för att få den information du letar efter. Att ha ett databasdiagram kommer att vara till hjälp.
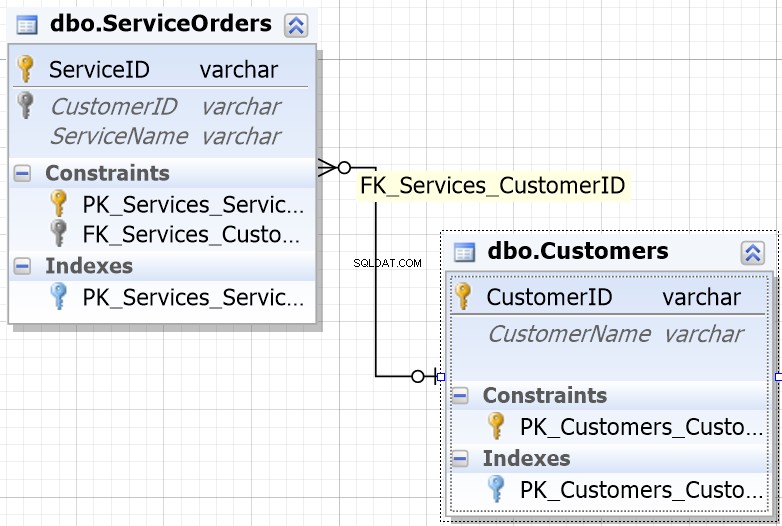
För att hjälpa dig i de flesta databasmiljöer kommer du att märka att kolumnerna som är designade för att anslutas har samma namn.
GÅ MED SYNTAX
Den tredje revisionen av SQL-databasens frågespråk (SQL-92) reglerar JOIN-syntaxen:
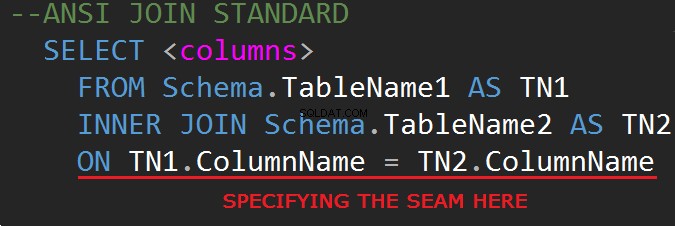
Det är möjligt att göra JOINs på WHERE-linjen:
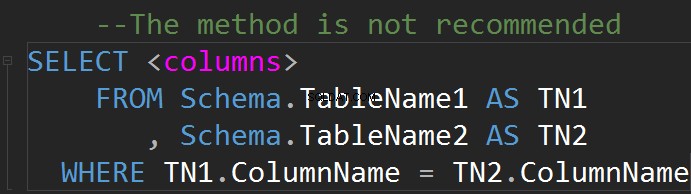
En relation har vanligtvis en enkel grafisk tolkning i form av en tabell.
Bästa praxis och konventioner
- Alias tabellnamn.
- Använd tvådelad namngivning för kolumner
- Placera varje JOIN på en separat rad
- Placera tabeller i en logisk ordning
GÅ MED TYPER
SQL Server tillhandahåller följande typer av JOIN:
- INRE JOIN
- YTTRE JOIN
- GÅ MED SJÄLV
- KORS-GÅ MED
För mer information om ämnet, kolla gärna den här artikeln om typerna av anslutningar i SQL Server och lär dig hur enkelt det är att skriva sådana frågor med hjälp av SQL Complete.
INRE JOIN
Den första typen av JOINs som vi kanske vill utföra är INNER JOIN. Vanligtvis hänvisar författare till denna typ av SQL Server JOINs som en vanlig eller enkel JOIN. De utelämnar bara INNER-prefixet. Denna typ av JOIN kombinerar två tabeller tillsammans och returerar bara rader från båda sidor som matchar .
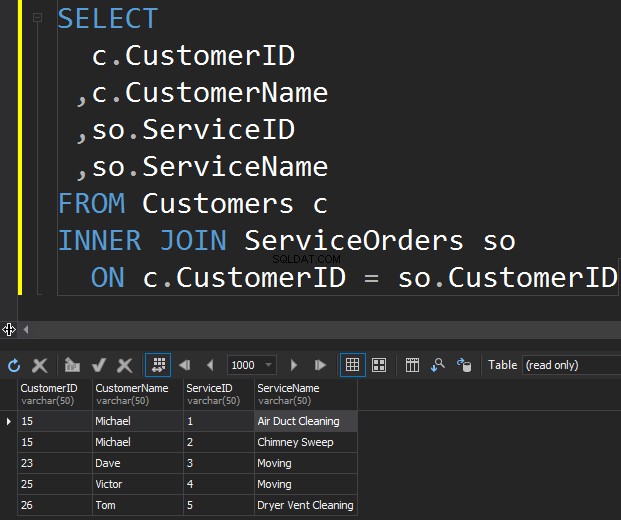
Vi ser inte Klara och Anthony här eftersom deras Kund-ID inte matchar i båda tabellerna. Jag vill också lyfta fram det faktum att JOIN-operationen returnerar en kund varje gång den matchar beställningen . Det finns två beställningar till Michael och en beställning till Dave, Victor och Tom vardera.
Sammanfattning:
- INNER JOIN returnerar endast rader när det finns minst en rad i båda tabellerna som matchar JOIN-villkoret.
- INNER JOIN eliminerar raderna som inte matchar en rad från den andra tabellen
YTTRE JOIN
Outer JOINs är olika eftersom de returnerar rader från tabeller eller vyer även om de inte matchar. Denna typ av JOIN är användbar om du behöver hämta alla kunder som aldrig har lagt en beställning. Eller till exempel om du letar efter en produkt som aldrig har beställts.
Sättet som vi gör våra OUTER JOINs är genom att ange VÄNSTER eller HÖGER, eller FULL.
Det finns inga skillnader mellan följande klausuler:
- LEFT OUTER JOIN =LEFT JOIN
- RIGHT OUTER JOIN =RIGHT JOIN
- FULL OUTER JOIN =FULL JOIN
Jag skulle dock rekommendera att skriva hela klausulen eftersom det gör koden mer läsbar.
Med LEFT OUTER JOIN
Det är ingen skillnad mellan VÄNSTER eller HÖGER förutom det faktum att vi bara pekar på tabellen som vi vill få de extra raderna från. I följande exempel listade vi kunder och deras beställningar. Vi använder VÄNSTER för att få alla kunder som aldrig har lagt beställningar. Vi ber SQL Server att få oss extra rader från den vänstra tabellen.
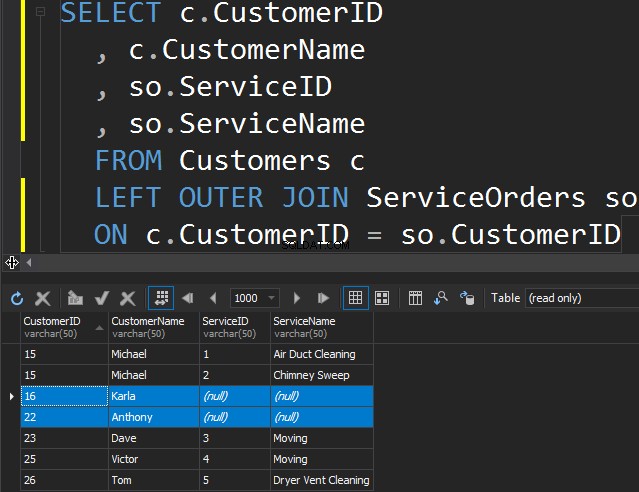
Observera att Karla och Anthony inte har lagt några beställningar och som ett resultat får vi NULL-värden för ServiceName och ServiceID. SQL Server vet inte vad den ska placera där, och den placerar NULLs.
Med RIGHT OUTER JOIN
För att få den mindre populära tjänsten från ServiceOrders-tabellen måste vi använda RÄTT riktning.
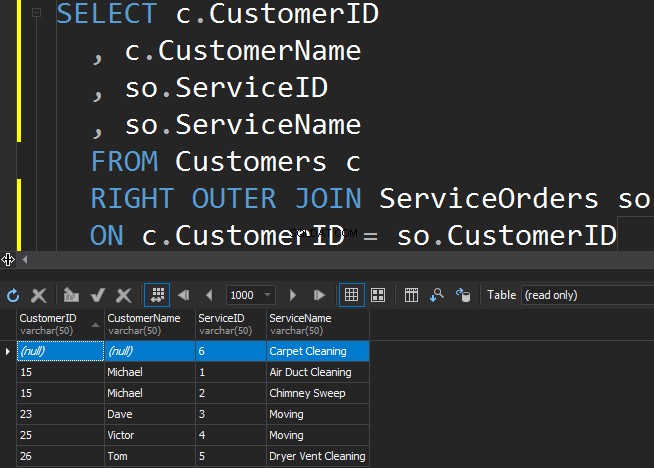
Vi ser att i det här fallet returnerade SQL Server extra rader från den högra tabellen, och mattrengöringstjänsten har aldrig beställts.
Använder FULL OUTER JOIN
Den här typen av JOIN låter dig få information som inte matchar genom att inkludera rader som inte matchar båda tabellerna.
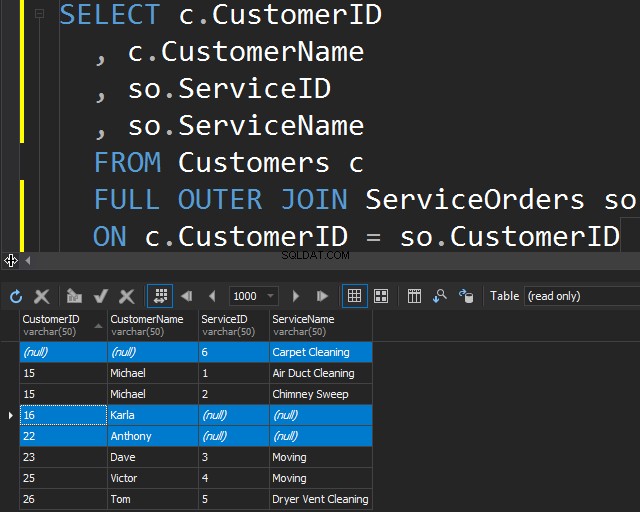
Detta kan också vara användbart om du behöver göra en datarensning.
Sammanfattning:
FULLSTÄNDIG YTTRE JOIN
- Returnerar rader från båda tabellerna även om de inte matchar JOIN-satsen
VÄNSTER eller HÖGER
- Ingen skillnad förutom i tabellordningen i FROM-satsen
- Riktning pekar på ett bord att hämta icke-matchande rader från
SJÄLV GÅ MED
Nästa typ av JOINs som vi har är SELF JOIN. Detta är förmodligen den näst minst vanliga typen av JOIN som du någonsin kommer att utföra. EN SELF JOIN är när du går med i ett bord på sig själv. Generellt sett är detta ett tecken på dålig design. För att använda samma tabell två gånger i en enda fråga måste tabellen vara alias. Aliaset hjälper frågeprocessorn att identifiera om kolumner ska presentera data från höger eller vänster sida. Dessutom måste du eliminera rader som marscherar sig själva. Detta görs vanligtvis med en icke-equi-join.
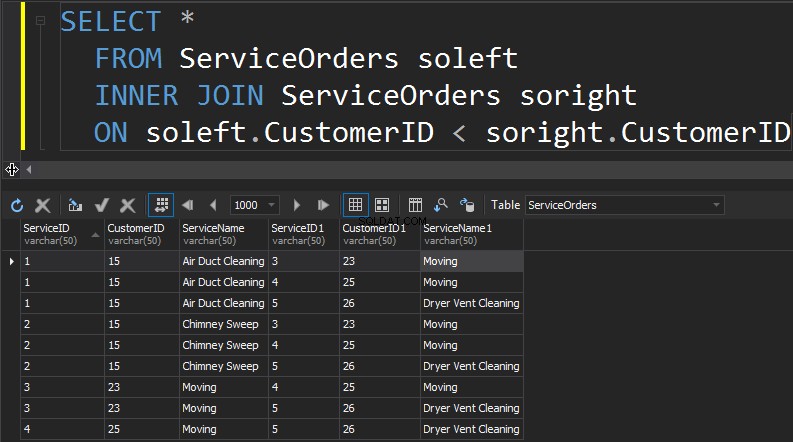
Sammanfattning:
- GÅR MED ett bord för sig själv
- Generellt ett tecken på dålig design och normalisering
- Tabeller måste ha alias
- Behöver filtrera rader som matchar dem själva
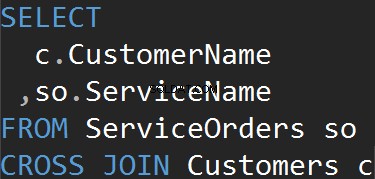
KORS ANSLUTERAR
Den här typen av JOINs har inte ON påstående. Varje enskild rad från varje bord kommer att matcha. Detta är också känt som Cartesian Product (om en CROSS JOIN inte har en WHERE-klausul). Du kommer knappast att använda denna JOIN-typ i verkliga scenarier, men det är ett bra sätt att generera testdata.
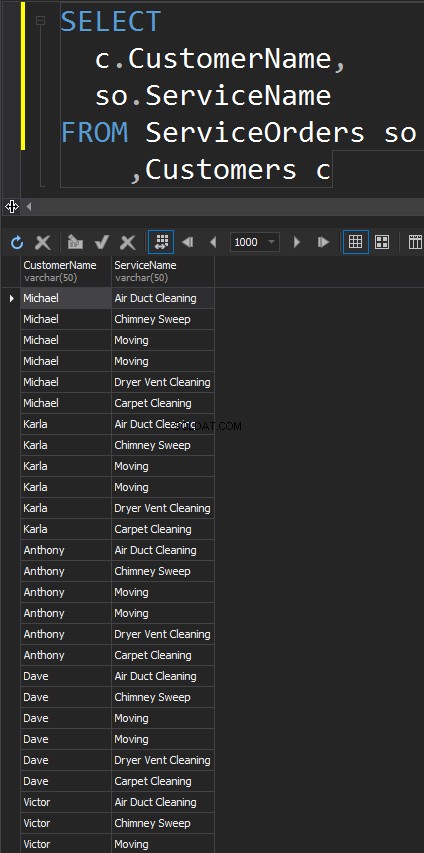
Resultatet är en datauppsättning, där antalet rader i den vänstra tabellen multiplicerat med antalet rader i den högra tabellen. Så småningom ser vi att varje enskild kund matchar varje enskild tjänst.
Vi får samma resultat när vi explicit använder CROSS JOIN-satsen.
Sammanfattning:
- Alla rader matchar från varje tabell
- Inget ON-uttalande
- Kan användas för att generera testdata
GÅ MED ALGORITIMER
I den första delen av artikeln har vi diskuterat logiskt JOIN-operatörer som SQL Server använder vid frågeanalys och bindning. De är:
- INRE JOIN
- YTTRE JOIN
- KORS-GÅ MED
De logiska operatorerna är konceptuella och de skiljer sig från de fysiska GÅR MED. Annars går logiska JOINs inte faktiskt med särskilda tabellkolumner. En enda logisk JOIN kan motsvara många fysiska JOIN. SQL Server ersätter logiska JOINs till fysiska JOINs under optimering. SQL Server har följande fysiska JOIN-operatorer:
- Inkapslad LOOP
- SAMMANSLUT
- HASH
En användare skriver eller använder inte dessa typer av JOINS. De är en del av SQL Server-motorn och SQL Server använder dem internt för att implementera logiska JOINs. När du utforskar exekveringsplanen kan du notera att SQL Server ersätter logiska JOIN-operatorer med en av tre fysiska operatorer.
Nested Loop Join
Låt oss börja från den enklaste operatören, som är Nested Loop. Algoritmen jämför varje enskild rad i en tabell (yttre tabell) med varje rad i den andra tabellen (inre tabellen) och letar efter rader som uppfyller JOIN-predikatet.
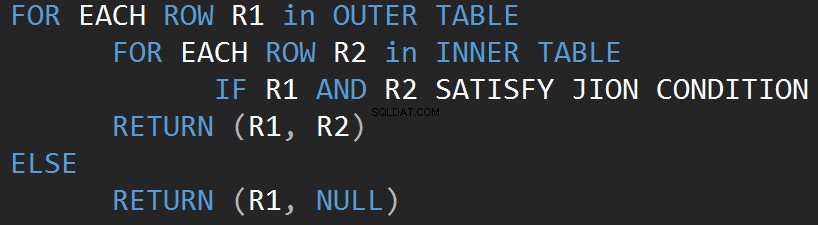
Följande pseudokod beskriver den inre kapslade join-loopalgoritmen:

Följande pseudokod beskriver den yttre kapslade join-loopalgoritmen:
Storleken på inmatningen påverkar direkt algoritmkostnaden. Insatsen växer, kostnaden ökar också. Den här typen av JOIN-algoritm är effektiv vid små input. SQL Server uppskattar ett JOIN-predikat för varje rad i båda ingångarna.
Betrakta följande fråga som ett exempel, som får kunder och deras beställningar.
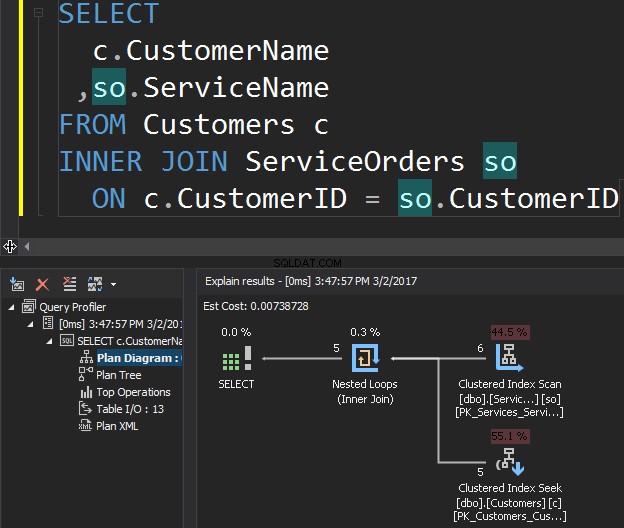
Operatorn Clustered Index Scan är den yttre ingången och Clustered Index Seek är den inre ingången . Operatören Nested Loop hittar faktiskt matchning. Operatören letar efter varje post i den yttre ingången och hittar matchande rader i den inre ingången. SQL Server kör Clustered Index Scan-operationen (yttre ingång) endast en gång för att få alla relevanta poster. Clustered Index Seek exekveras för varje post från den yttre ingången. För att bekräfta detta, navigera markören till operatörsikonen och granska verktygstipset.
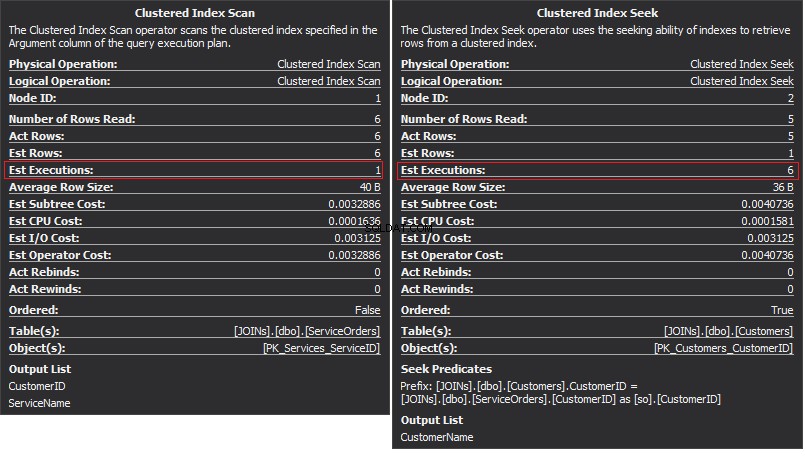
Låt oss prata om komplexiteten. Antag att N är radnumret för den yttre utgången. M är det totala radnumret i försäljningsorder tabell. Därför är frågans komplexitet O(NLogM) där LogM är komplexiteten för varje sökning i den inre ingången. Optimeraren kommer att välja denna operatör varje gång när den yttre ingången är liten och den inre ingången innehåller ett index i kolumnen som fungerar som sömmen. Därför är index och statistik väsentliga för denna JOIN-typ, annars kan SQL Server av misstag tro att det inte finns så många rader i en av ingångarna. Det är bättre att utföra en tabellsökning istället för att utföra indexsökning 100 000 gånger. Speciellt när den inre ingångsstorleken är mer än 100K.
Sammanfattning:
Kapslade loopar
- Komplexitet:O(NlogM)
- Tillämpas vanligtvis när ett bord är litet
- Den större tabellen innehåller ett index som gör det möjligt att söka efter den med hjälp av join-nyckeln
Slå samman gå med
Vissa utvecklare förstår inte helt Hash och Merge JOINs och associerar dem ofta med dåliga resultat.
Till skillnad från Nested Loop som accepterar vilket JOIN-predikat som helst, kräver Merge Join minst en equi-join. Dessutom måste båda ingångarna sorteras på JOIN-knapparna.
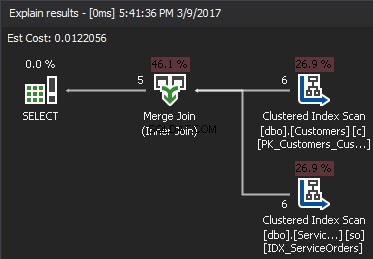
Pseudokoden för MERGE JOIN-algoritmen:
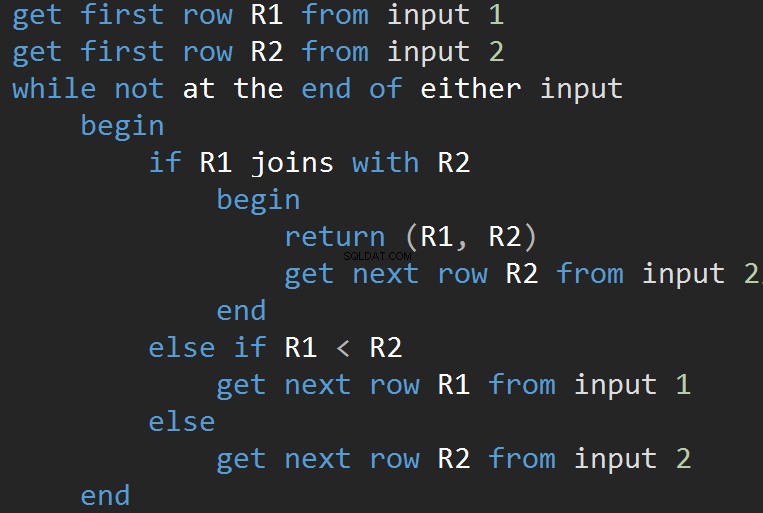
Algoritmen jämför två sorterade ingångar. En rad i taget. Om det finns en likhet mellan två rader, sammanfogar algoritmutgångarna rader och fortsätter. Om inte, kasserar algoritmen den minsta av de två ingångarna och fortsätter. Till skillnad från den kapslade slingan är kostnaden här proportionell mot summan av antalet inmatningsrader. När det gäller komplexitet – O(N+M). Därför är denna typ av JOIN ofta bättre för stora ingångar.
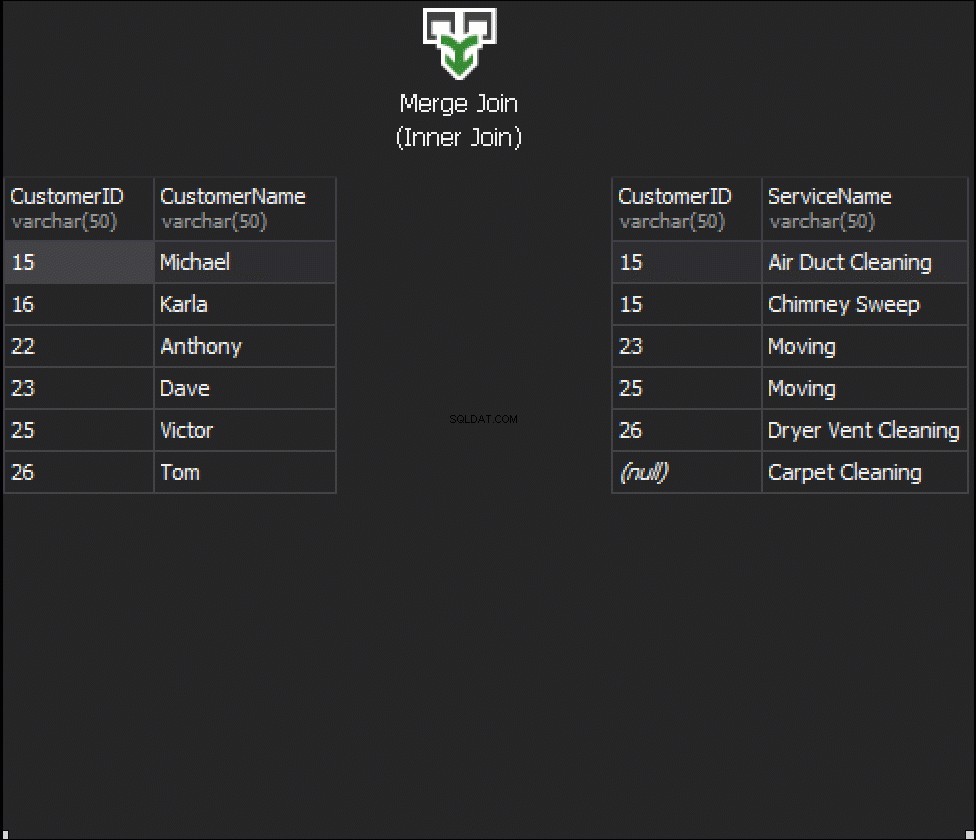
Följande animation visar hur MERGE JOIN-algoritmen faktiskt sammanfogar tabellrader.
Sammanfattning
- Komplexitet:O(N+M)
- Båda ingångarna måste sorteras på anslutningsnyckeln
- En jämställdhetsoperatör används
- Utmärkt för stora bord
Hash Join
Hash Join lämpar sig väl för stora bord utan användbart index. På det första steget – byggfasen Algoritmen skapar ett hashindex i minnet på den vänstra ingången. Det andra steget kallas probfasen . Algoritmen går igenom ingången på höger sida och hittar matchningar med hjälp av indexet som skapades under byggfasen. Om det är sant är det inte ett gott tecken när optimeraren väljer den här typen av JOIN-algoritm.
Det finns två viktiga begrepp som ligger bakom denna typ av JOINs:Hash-funktion och Hash-tabell.
En hash-funktion är vilken funktion som helst som kan användas för att mappa data av variabel storlek till data med fast storlek.
En hashtabell är en datastruktur som används för att implementera en associativ array, en struktur som kan mappa nycklar till värden. En hashtabell använder en hashfunktion för att beräkna ett index i en array av hinkar eller luckor, från vilka det önskade värdet kan hittas.
Baserat på tillgänglig statistik väljer SQL Server den minsta indata som byggindata och använder den för att bygga en hashtabell i minnet. Om det inte finns tillräckligt med minne använder SQL Server fysiskt diskutrymme i TempDB. När hashtabellen väl har skapats hämtar SQL Server data från sondens indata (större tabell) och jämför den med hashtabellen med hjälp av en hashmatchningsfunktion. Som ett resultat returnerar den matchade rader.
Om vi tittar på utförandeplanen är det högra översta elementet bygginsatsen , och det nedre högra elementet är probingången . Om båda insatserna är extremt stora är kostnaden för hög.
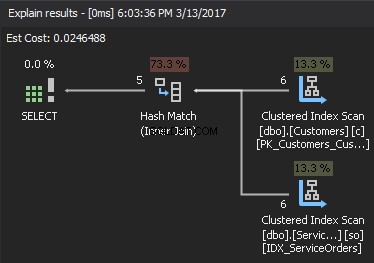
För att uppskatta komplexiteten, anta följande:
hc – komplexiteten i att skapa hashtabeller
hm – komplexiteten hos hashmatchningsfunktionen
N – mindre bord
M – större bord
J – komplexitetstillägg för dynamisk beräkning och skapande av hashfunktionen
Komplexiteten blir:O(N*hc + M*hm + J)
Optimeraren använder statistik för att bestämma värdekardinalitet. Sedan skapar den dynamiskt en hashfunktion som delar upp data i många hinkar med lika stora storlekar. Det är ofta svårt att uppskatta komplexiteten i processen för att skapa hashtabeller, liksom komplexiteten för varje hashmatchning på grund av dynamisk karaktär. Exekveringsplanen kan till och med visa felaktiga uppskattningar eftersom optimeraren utför alla dessa dynamiska operationer under exekveringstiden. I vissa fall kan exekveringsplanen visa att Nested Loop är dyrare än Hash Join, men i själva verket körs Hash Join långsammare på grund av den felaktiga kostnadsuppskattningen.
Sammanfattning
- Komplexitet:O(N*hc +M*hm +J)
- Sista utväg anslutningstyp
- Använder en hashtabell och en dynamisk hashmatchningsfunktion för att matcha rader
Användbara produkter:
SQL Complete – skriv, försköna, omstrukturera din kod enkelt och öka din produktivitet.