Du använder MongoDB för att lagra ID:t. Det är en stat. Generering av ID är en funktion. Du använder Mongodb för att generera ID:t när mongodb-processen tar argument för funktionen och returnerar det genererade ID:t. Det är inte vad du gör. Du använder nodejs för att generera ID:t.
Antalet trådar, eller snarare händelseslingor, är avgörande eftersom det definierar arkitekturen men på båda sätten behöver du inte transaktioner. Transaktioner i mongodb kallas "flerdokumenttransaktioner" exakt för att markera att de är avsedda för konsekvent uppdatering av flera dokument samtidigt. Det allra första stycket i https://docs.mongodb.com/manual/core/transactions / varnar dig för att om du uppdaterar ett enda dokument finns det inget utrymme för transaktioner.
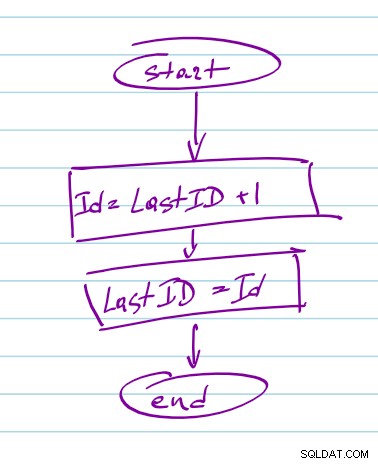
En enda gängad applikation kräver ingen synkronisering. Du kan på ett tillförlitligt sätt läsa det senast genererade ID:t vid start och garantera att ID:t är unikt inom nodejs-processen. Om du utesluter mongodb och annan I/O från genereringsfunktionen kommer du att göra den synkron så att du kan bibehålla tillståndet för ID:t inom nodejs process och garantera dess unikhet. När den väl har skapats kan du stanna kvar i db asynkront. I värsta fall kan du ha en lucka i de sekventiella numren men inga dubbletter.
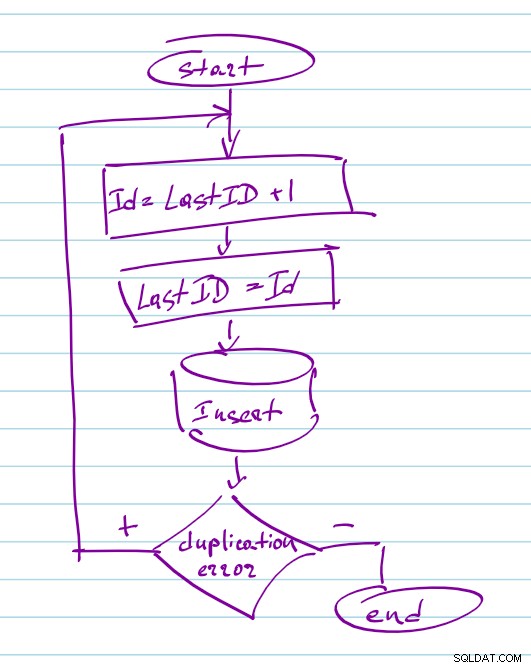
Om det finns en minsta chans att du kan behöva skala upp till mer än 1 nodejs-process för att hantera fler samtidiga förfrågningar eller lägga till ytterligare en värd för redundans i framtiden kommer du att behöva synkronisera genereringen av ID:t och du kan använda Mongodb unika index för den där. Funktionen i sig ändrar inte mycket du genererar fortfarande ID som i en enkeltrådig arkitektur men lägger till ett extra steg för att spara ID till mongo. Dokumentet bör ha ett unikt index på ID-fältet, så vid samtidiga uppdateringar kommer en av frågorna att lägga till dokumentet och en annan kommer att misslyckas med "E11000 duplicate key error". Du fångar sådana fel på nodejs sida och upprepar funktionen igen och väljer nästa nummer: