Eftersom du använder våren. Du kan använda MultipartFile för att hämta filen i din styrenhet och använd sedan Binary av org.bson för att lagra fil till MongoDB , Om din bildstorlek <16 MB (om bildstorlek> 16 MB kan du använda GridFs
).
Du behöver bara lägga till ett beroende till ditt projekt - spring-data-mongoDB
Låt oss ta ett exempel på en användarsamling som ser ut så här:
@Document
public class User {
@Id
private String id;
private String name;
private Binary image;
// getters and setters
}
Här kan du se Binary image som representerar din bildfil.
Skapa nu ett arkiv för denna användarsamling med MongoRepository
public interface UserRepository extends MongoRepository<User, String>{
}
Skapa en Controller för demoändamål. Använd @RequestParam MultipartFile file för att hämta filen till din styrenhet, hämta bytes från filen och ställ in den till användarobjektet user.setImage(new Binary(file.getBytes())); komplett exempel är nedan:
@RestController
public class UserController {
@Autowired
private UserRepository userRepository;
@PostMapping("/users")
User createUser(@RequestParam String name, @RequestParam MultipartFile file) throws IOException {
User user = new User();
user.setName(name);
user.setImage(new Binary(file.getBytes()));
return userRepository.save(user);
}
@GetMapping("/users")
String getImage(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
Encoder encoder = Base64.getEncoder();
return encoder.encodeToString(user.get().getImage().getData());
}
}
Starta servern och träffa slutpunkten som visas i postman-skärmbilden nedan
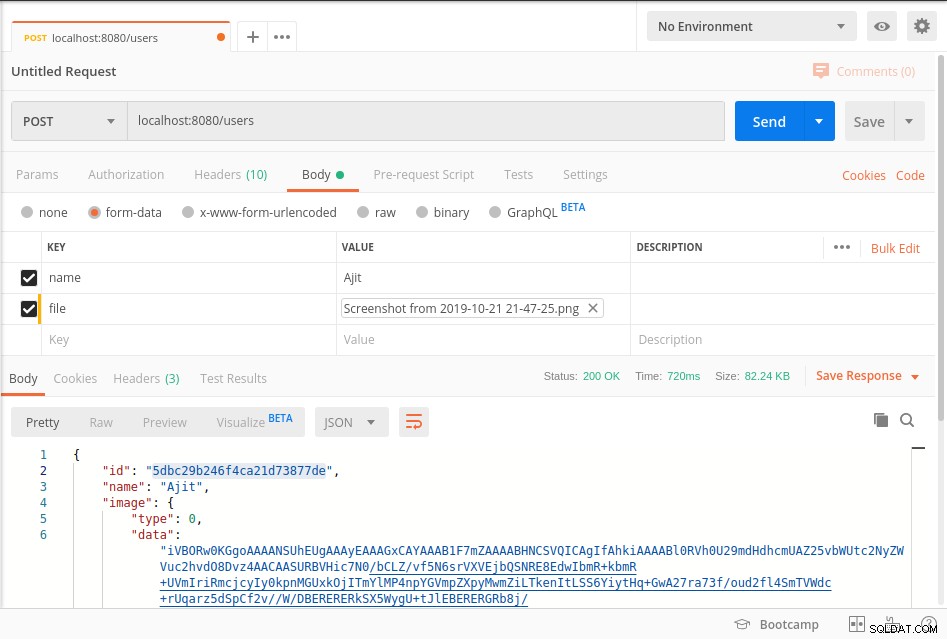
Din data lagras i mongoDb i BinData format och för att hämta data från databasen, se getImage metod för ovanstående kod.
EDIT:
Frågeställaren använder tess4j bibliotek för att extrahera text från bild och doOCR är en metod i detta bibliotek. Jag har följt dessa steg för att extrahera text från bild i min vårstartapplikation.
-
Installera
tesseract-ocrin i ditt system:sudo apt-get install tesseract-ocr -
Ladda ner
eng.traineddataträningsdata från https://github.com/tesseract-ocr/tessdata och flytta den till projektets rotmapp. -
Lägg till nedanstående beroende till ditt projekt:
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.2.1</version>
</dependency>
- Lägg till koden nedan i befintligt projekt:
@GetMapping("/image-text")
String getImageText(@RequestParam String id) {
Optional<User> user = userRepository.findById(id);
ITesseract instance = new Tesseract();
try {
ByteArrayInputStream bais = new ByteArrayInputStream(user.get().getImage().getData());
BufferedImage bufferImg = ImageIO.read(bais);
String imgText = instance.doOCR(bufferImg);
return imgText;
} catch (Exception e) {
return "Error while reading image";
}
}