MongoDB accepterar och ger åtkomst till data i Javascript Object Notation-formatet (JSON), vilket gör det till en perfekt passform när de hanterar JavaScript-baserade REST-tjänster (Representational State Transfer). I det här inlägget tar vi en titt på paginering med MongoDB och bygger en enkel Express/Mongojs-applikation med slush-mongo. Sedan använder vi skip() och limit() för att hämta de nödvändiga posterna från en uppsättning data.
Paginering är ett av de enklaste sätten att öka användarupplevelsen när man hanterar genomsnittliga till enorma datamängder.
- Dela upp hela data i x poster per sida för att få (totalt antal poster/x) sidor.
- Närnäst visar vi en sidnumrering med antalet sidor.
- När användaren klickar på sidnumret söker och hämtar vi uppsättningen poster endast för den specifika vyn.
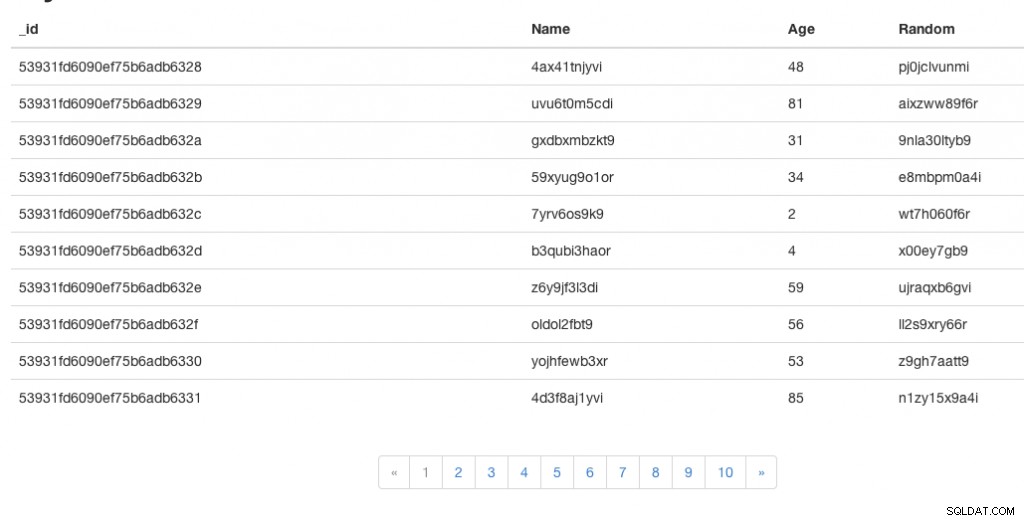
Du kan hitta en livedemo av appen här och den fullständiga koden för den här appen här.
Ställ in pagineringsprojektet
Skapa en ny mapp med namnet mongoDBPagination. Öppna terminal/prompt här. Därefter installerar vi gulp , slask och slush-mongo moduler. Kör:
$ [sudo] npm i -g gulp slush slush-mongo
När detta är gjort, kör:
$ slush mongo
Du kommer att ställas några frågor och du kan svara på dem enligt följande:
[?] Which MongoDB project would you like to generate? Mongojs/Express [?] What is the name of your app? mongoDBPagination [?] Database Name: myDb [?] Database Host: localhost [?] Database User: [?] Database Password: [?] Database Port: 27017 [?] Will you be using heroku? (Y/n) n
Detta kommer att skapa en enkel Express/Mongojs-app åt oss. När installationen är klar, kör:
$ gulp
Öppna sedan https://localhost:3000 i din favoritwebbläsare och du bör se en tabell med en lista över rutter som konfigurerats i appen. Detta bekräftar att du har installerat allt korrekt.
Konfigurera en testdatabas
Därefter skapar vi en ny samling som heter "testData och fyll sedan i lite testdata i den. Sedan visar vi dessa data i en sidnumrerad tabell. Öppna en ny terminal/prompt och kör:
$ mongo
Välj sedan din databas genom att köra:
use myDb
Kopiera sedan kodavsnittet nedan och klistra in det i mongoskalet och tryck på retur:
for(var i = 1; i <= 999; i++) {
db.testData.insert({
name: Math.random()
.toString(36)
.substring(7),
age: Math.floor(Math.random() * 99),
random: Math.random()
.toString(36)
.substring(7)
});
}
Detta genererar 999 exempelposter med vissa slumpmässiga data. En exempelpost kommer att se ut så här:
{
"_id":"5392a63c90ad2574612b953b",
"name": "j3oasl40a4i",
"age": 73,
"random": "vm2pk1sv2t9"
}
Dessa data kommer att pagineras i vår applikation.
Konfigurera databasen
Eftersom vi har lagt till en ny samling måste vi uppdatera vår Mongojs DB-konfiguration för att läsa från "testData ’.
Öppna mongoDBPagination/config/db.js och uppdatera rad 17 från:
var db = mongojs(uristring, ['posts']);
till:
var db = mongojs(uristring, ['posts', 'testData']);
Bygg slutpunkten för paginering
Nu kommer vi att bygga vår serverkod genom att skapa en REST-slutpunkt, där klienten låter oss veta vilken data den vill ha.
Sökningslogik
Logiken för paginering är ganska enkel. Vår databassamling består av poster och vi vill hämta och visa endast ett fåtal vid ett givet tillfälle. Det här är mer en UX-sak för att hålla sidans laddningstid till ett minimum. Nyckelparametrarna för alla pagineringskoder skulle vara:
-
Totalt antal rekord
Det totala antalet poster i DB.
-
Storlek
Storleken på varje uppsättning poster som klienten vill visa.
-
Sida
Sidan för vilken data måste hämtas.
Låt oss säga att klienten vill ha 10 poster från första sidan, den kommer att begära:
{
page : 1,
size : 10
}
Servern tolkar detta som – klienten behöver 10 poster som börjar från index 0 (sida :1).
För att hämta data från tredje sidan skulle klienten begära:
{
page : 3,
size : 10
}
Nu kommer servern att tolka som – klienten behöver 10 poster som börjar från index 20 (sida – 1 * storlek).
Så om vi tittar på mönstret ovan kan vi dra slutsatsen att om sidvärdet är 1 börjar vi hämta data från post 0, och om sidvärdet är större än 1 börjar vi hämta data från sidans storlek ( sida*storlek).
Stöd för MongoDB
Vi har nu en förståelse för sidnumreringslogiken, men hur förmedlar vi samma sak till MongoDB?
MongoDB ger oss två metoder för att uppnå detta
-
hoppa över
När frågan är klar kommer MongoDB att flytta markören till värdet hoppa över.
-
gräns
När MongoDB börjar fylla i poster kommer den bara att samla in gränsen antal poster.
Enkelt eller hur? Vi kommer att använda dessa två metoder tillsammans med find() för att hämta posterna.
Fortsätt utveckling
Låt oss nu skapa en ny fil med namnet paginator.js inuti mongoDBPagination/rutter mapp där vi konfigurerar vår sideringsslutpunkt. Öppna paginator.js och lägg till koden nedan:
module.exports = function (app) {
var db = require('../config/db')
api = {};
api.testData = function (req, res) {
var page = parseInt(req.query.page),
size = parseInt(req.query.size),
skip = page > 0 ? ((page - 1) * size) : 0;
db.testData.find(null, null, {
skip: skip,
limit: size
}, function (err, data) {
if(err) {
res.json(500, err);
}
else {
res.json({
data: data
});
}
});
};
app.get('/api/testData', api.testData);
};
- Rad 6-7: Vi får sidnumret och sidstorleken från förfrågningsparametrarna.
- Rad 8: Vi konfigurerar hoppa över värde.
- Rad 10: Vi frågar databasen med sökmetoden och skickar null som de två första argumenten för att uppfylla metodsignaturen för find() .
I det tredje argumentet för sökmetoden kommer vi att klara filterkriteriet, och när resultaten kommer tillbaka svarar vi med en JSON.
För att testa detta, se till att din server är igång och navigera till:
https://localhost:3000/api/testdata?page=1&size=2
Du bör se de två första posterna i samlingen och du kan ändra värdena för sida och storlek för att se olika resultat.
Bygg klienten
Vi kommer nu att bygga klienten som ska implementera sideringen med hjälp av Bootstrap-tabeller för att visa data och bootpag-plugin för att hantera personsökaren.
Först installerar vi Bootstrap. Kör:
$ bower install bootstrap
Därefter kommer vi att ladda ner jquery.bootpag.min.js härifrån till public/js mapp. Uppdatera views/index.html som:
<!DOCTYPE html>
<html>
<head>
<title><%= siteName %></title>
<link rel="stylesheet" href="/css/style.css">
<link rel="stylesheet" href="/bower_components/bootstrap/dist/css/bootstrap.min.css">
</head>
<body>
<div class="navbar navbar-inverse navbar-fixed-top" role="navigation">
<div class="container">
<div class="navbar-header">
<a class="navbar-brand" href="javascript:"><%= siteName %></a>
</div>
</div>
</div>
<div class="container">
<h1>My Data</h1>
<table class="table">
<thead>
<tr>
<th>_id</th>
<th>Name</th>
<th>Age</th>
<th>Random</th>
</tr>
</thead>
<tbody>
<!-- we will populate this dyanmically -->
</tbody>
</table>
<div id="pager" class="text-center"></div>
<input type="hidden" value="<%= totalRecords %>" id="totalRecords">
<input type="hidden" value="<%= size %>" id="size">
</div>
<script type="text/javascript" src="bower_components/jquery/dist/jquery.min.js"></script>
<script type="text/javascript" src="/js/jquery.bootpag.min.js"></script>
<script type="text/javascript" src="/js/script.js"></script>
</body>
</html>
Och slutligen kommer vi att skriva logiken för att fylla tabellen. Öppna js/script.js och fyll den som:
// init bootpag
$('#pager').bootpag({
total: Math.ceil($("#totalRecords").val()/$("#size").val()),
page : 1,
maxVisible : 10,
href: "#page-{{number}}",
}).on("page", function(event, /* page number here */ num) {
populateTable(num);
});
var template = "<tr><td>_id</td><td>name</td><td>age</td><td>random</td>";
var populateTable = function (page) {
var html = '';
$.getJSON('/api/testdata?page='+page+'&size='+ $("#size").val(), function(data){
data = data.data;
for (var i = 0; i < data.length; i++) {
var d = data[i];
html += template.replace('_id', d._id)
.replace('name', d.name)
.replace('age', d.age)
.replace('random', d.random);
};
$('table tbody').html(html);
});
};
// load first page data
populateTable(1);
Navigera nu till:
https://localhost:3000
Du bör nu se tabellen och personsökarkomponenten. Du kan klicka dig igenom sidnumren för att bläddra igenom data.
Enkelt och lätt! Hoppas du fick en idé om hur man implementerar paginering med MongoDB.
Du hittar koden för den här appen här.
För mer information om prestanda för personsökning, se vårt andra blogginlägg - Fast Paging with MongoDB
Tack för att du läser. Kommentera.
@arvindr21