Databasbelastningsbalansering distribuerar samtidiga klientförfrågningar till flera databasservrar för att minska belastningen på en enskild server. Detta kan förbättra prestandan för din databas drastiskt. Lyckligtvis kan MongoDB hantera flera klienters förfrågningar om att läsa och skriva samma data samtidigt som standard. Den använder vissa samtidighetskontrollmekanismer och låsningsprotokoll för att säkerställa datakonsistens hela tiden.
På detta sätt säkerställer MongoDB också att alla klienter får en konsekvent bild av data när som helst. På grund av denna inbyggda funktion för att hantera förfrågningar från flera klienter, behöver du inte oroa dig för att lägga till en extern lastbalanserare ovanpå dina MongoDB-servrar. Men om du fortfarande vill förbättra prestandan för din databas med hjälp av lastbalansering finns här några sätt att uppnå det.
MongoDB Vertical Scaling
I enkla termer betyder vertikal skalning att du lägger till fler resurser till din server att hantera för att ladda. Liksom alla databassystem föredrar MongoDB mer RAM- och IO-kapacitet. Detta är det enklaste sättet att öka MongoDB-prestanda utan att sprida belastningen över flera servrar. Vertikal skalning av MongoDB-databasen inkluderar vanligtvis ökad CPU-kapacitet eller diskkapacitet och ökad genomströmning (I/O-operationer). Genom att lägga till fler resurser blir din mongo-server mer kapabel att hantera flera klienters förfrågningar. Bättre lastbalansering för din databas.
Nackdelen med att använda detta tillvägagångssätt är den tekniska begränsningen av att lägga till resurser till ett enskilt system. Alla molnleverantörer har också begränsningarna när det gäller att lägga till nya hårdvarukonfigurationer. Den andra nackdelen med detta tillvägagångssätt är en enda punkt av misslyckande. I detta tillvägagångssätt lagras all din data i ett enda system, vilket kan leda till permanent förlust av dina data.
MongoDB horisontell skalning
Horisontell skalning avser att dela upp din databas i bitar och lagra dem på flera servrar. Den största fördelen med detta tillvägagångssätt är att du kan lägga till ytterligare servrar i farten för att öka din databasprestanda utan stilleståndstid. MongoDB tillhandahåller horisontell skalning genom skärning. MongoDB-skärning ger ytterligare kapacitet för att fördela skrivbelastningen över flera servrar(shards). Här kan varje skärva ses som en oberoende databas och samlingen av alla skärvor kan ses som en stor logisk databas. Sharing gör det möjligt för din MongoDB att distribuera data över flera servrar för att hantera samtidiga klientförfrågningar effektivt. Därför ökar det din databas läs- och skrivkapacitet.
MongoDB Sharding
En shard kan vara en enskild mongod-instans eller en replikuppsättning som innehåller delmängden av mongo sharded-databasen. Du kan konvertera shard i replikuppsättning för att säkerställa hög tillgänglighet för data och redundans.
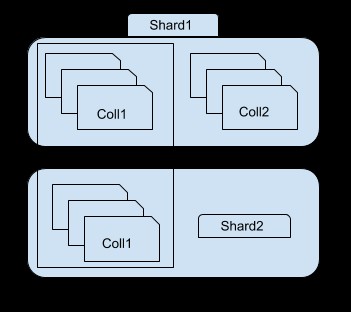
Som du kan se i bilden ovan innehåller skärva 1 en delmängd av samling 1 och hela samling2, medan skärv 2 endast innehåller annan delmängd av samling1. Du kan komma åt varje skärva med mongos-instansen. Om du till exempel ansluter till shard1-instansen kommer du bara att kunna se/åtkomst till en delmängd av collection1.
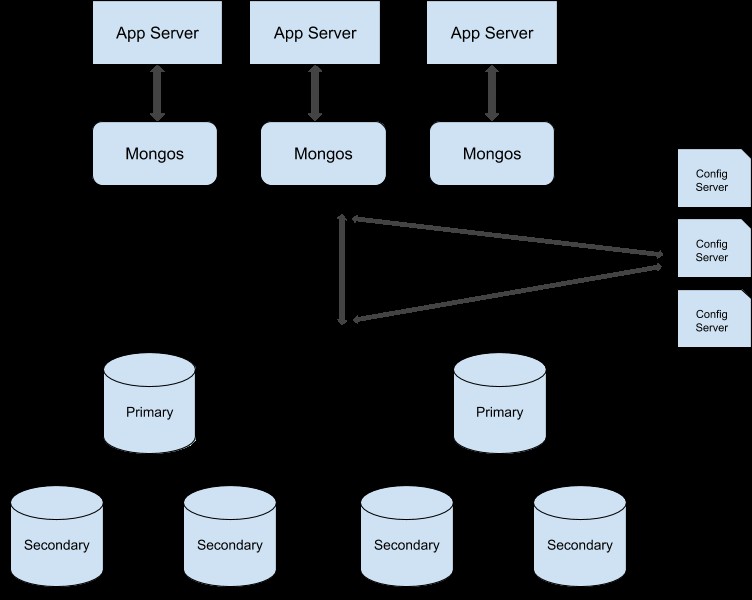
Mongos
Mongos är frågeroutern som ger åtkomst till fragmenterade kluster för klientapplikationer. Du kan ha flera mongos-instanser för bättre lastbalansering. Till exempel, i ditt produktionskluster kan du ha en mongos-instans för varje applikationsserver. Nu här kan du använda en extern lastbalanserare, som omdirigerar din applikationsservers begäran till lämplig mongos-instans. När du lägger till sådana konfigurationer till din produktionsserver, se till att anslutningen från vilken klient som helst alltid ansluter till samma mongo-instans varje gång eftersom vissa mongo-resurser som markörer är specifika för mongos-instanser.
Konfigurationsservrar
Konfigurationsservrar lagrar konfigurationsinställningarna och metadata om ditt kluster. Från MongoDB version 3.4 måste du distribuera konfigurationsservrar som en replikuppsättning. Om du aktiverar sharding i en produktionsmiljö är det obligatoriskt att använda tre separata konfigurationsservrar, var och en på olika maskiner.
Du kan följa den här guiden för att konvertera ditt replikuppsättningskluster till ett fragmenterat kluster. Här är exempelillustrationen av ett fragmenterat produktionskluster:
MongoDB lastbalansering med replikering
Ibland kan MongoDB-replikering användas för att hantera mer trafik från klienter och för att minska belastningen på den primära servern. För att göra det kan du instruera klienter att läsa från sekundärer istället för den primära servern. Detta kan minska mängden belastning på den primära servern eftersom alla läsbegäranden som kommer från klienter kommer att hanteras av sekundära servrar, och den primära servern tar endast hand om skrivbegäranden.
Följande är kommandot för att ställa in läspreferensen till sekundär:
db.getMongo().setReadPref('secondary')Du kan också ange några taggar för att rikta in sig på specifika sekundärer medan du hanterar läsfrågorna.
db.getMongo().setReadPref(
"secondary", [
{ "datacenter": "APAC" },
{ "region": "East"},
{}
])Här kommer MongoDB att försöka hitta den sekundära noden med datacentertaggen som APAC. Om den hittas kommer Mongo att leverera läsbegäranden från alla sekundärer med taggdatacenter:"APAC". Om den inte hittas, kommer Mongo att försöka hitta sekundärer med taggregion:"East". Om det fortfarande inte finns några sekundärer, kommer {} att fungera som standardfallet, och Mongo kommer att betjäna förfrågningarna från alla kvalificerade sekundärer.
Denna metod för lastbalansering är dock inte tillrådlig att använda för att öka läskapaciteten. Eftersom alla läspreferenslägen annat än primärt kan returnera gamla data i händelse av senaste skrivuppdateringar på den primära servern. Vanligtvis tar den primära servern lite tid att hantera skrivförfrågningarna och sprider ändringarna till sekundära servrar. Under denna tid, om någon begär läsoperation på samma data, kommer den sekundära servern att returnera inaktuella data eftersom den inte är synkroniserad med den primära servern. Du kan använda detta tillvägagångssätt om din applikation är tung i läsoperationer jämfört med skrivoperationer.
Slutsats
Eftersom MongoDB kan hantera samtidiga förfrågningar av sig själv, finns det inget behov av att lägga till en lastbalanserare i ditt MongoDB-kluster. För belastningsbalansering av klientens önskemål kan du välja antingen vertikal skalning eller horisontell skalning eftersom det inte är tillrådligt att använda sekundärer för att skala ut dina läs- och skrivoperationer. Vertikal skalning kan nå de tekniska gränserna, som diskuterats ovan. Därför är den lämplig för småskaliga applikationer. För stora applikationer är horisontell skalning genom skärning den bästa metoden för lastbalansering av läs- och skrivoperationer.